
Вкратце
Я создал новый проект Интерактивные эксперименты с машинным обучением на GitHub. Каждый эксперимент состоит из Jupyter/Colab ноутбука, показывающего как модель тренировалась, и Демо странички, показывающей модель в действии прямо в вашем браузере.
Несмотря на то, что машинные модели в репозитории могут быть немного "туповатенькими" (помните, это всего-лишь эксперименты, а не вылизанный код, готовый к "заливке на продакшн" и дальнейшему управлению новыми Tesla), они будут стараться как могут чтобы:
- Распознать цифры и прочие эскизы, которые вы нарисуете в браузере
- Определить и распознать объекты на видео из вашей камеры
- Классифицировать изображения, загруженные вами
- Написать с вами поэму в стиле Шекспира
- И даже поиграть с вами в камень-ножницы-бумагу
- и пр.
Я тренировал модели на Python с использованием TensorFlow 2 с поддержкой Keras. Для демо-приложения я использовал React и JavaScript версию Tensorflow.

Производительность моделей
Для начала, давайте определимся с нашими ожиданиями.? Репозиторий содержит эксперименты с машинным обучением, а не готовые к "заливке на продакшн", оптимизированные и тонко настроенные модели. Этот проект скорее похож на песочницу, в которой можно учиться и тренироваться работе с алгоритмами машинного обучения и разными наборами данных. Обученные модели могут быть недостаточно точными (например, иметь 60% точности вместо ожидаемых, пускай, 97%), а также могу быть переученными и недоученными (overfitting vs underfitting).
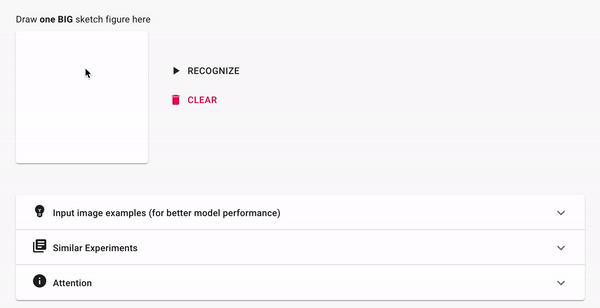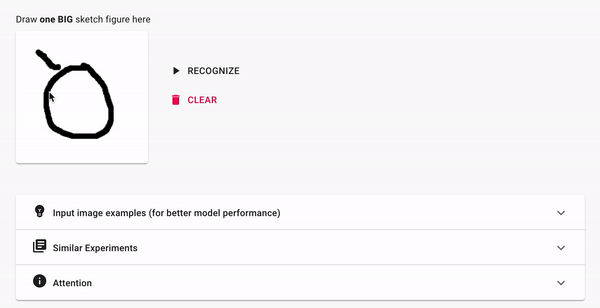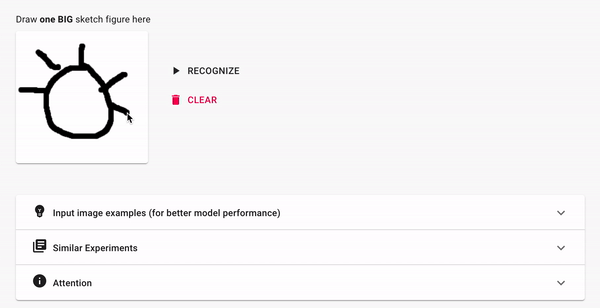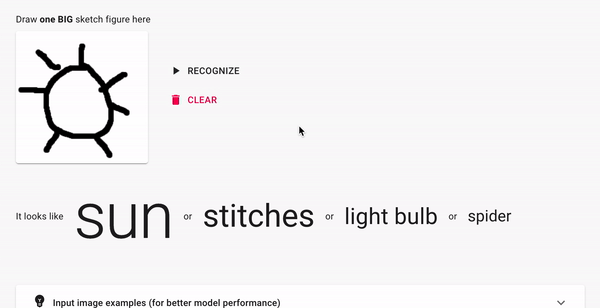
Поэтому иногда вы можете увидеть что-то вроде:
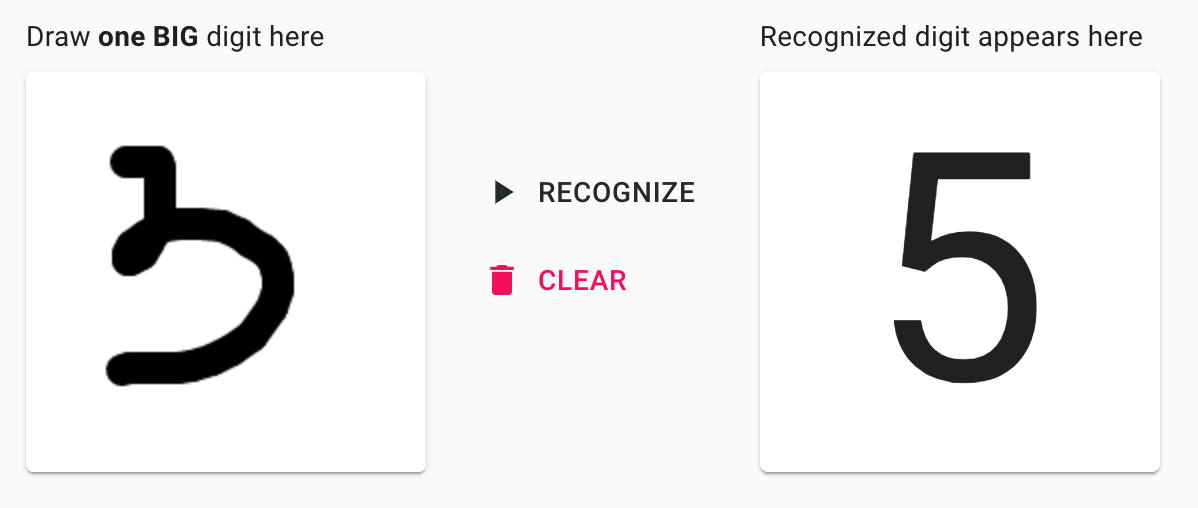
Но будьте терпеливы, иногда эта же модель может выдавать что-то более "умное":
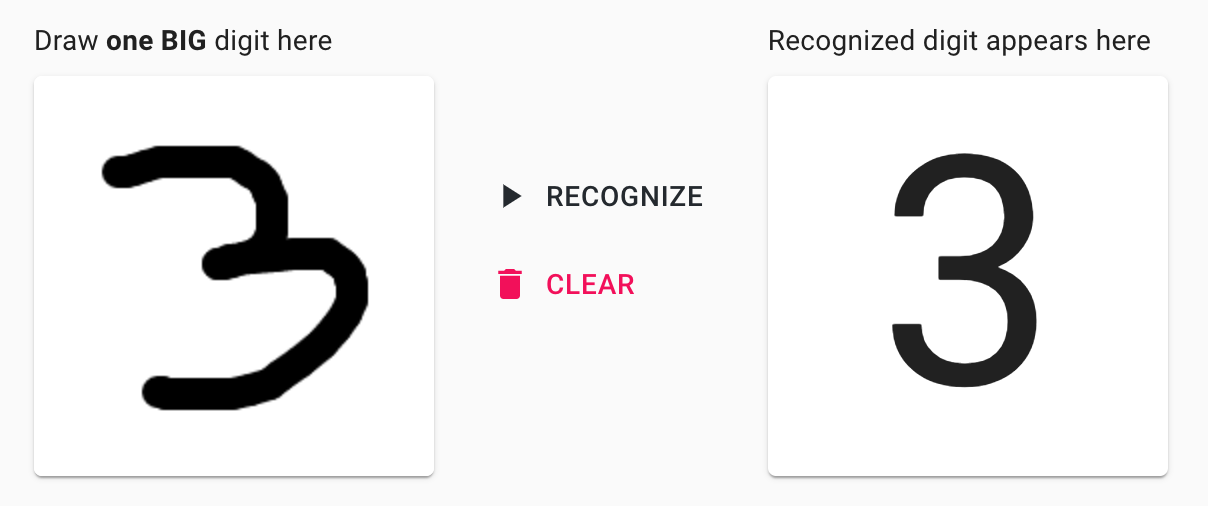
Предыстория
Я инженер-программист и последние несколько лет занимаюсь в основном full-stack программированием (веб-проекты). В свободное от работы время, в качестве хобби, я решил углубиться в тему машинного обучения, чтобы в первую очередь для себя-же сделать эту тему менее магической и более математической.
- Поскольку Python мог быть хорошим выбором для того, чтобы начать экспериментировать с машинным обучением я решил изучить его базовый синтаксис. В результате появился проект Playground and Cheatsheet for Learning Python. Он был создан с одной стороны для того, чтобы практиковаться в написании кода на Python, а также в качестве "шпаргалки" с базовым синтаксисом, чтобы в нужный момент можно было быстро подсмотреть вещи наподобие
dict_via_comprehension = {x: x**2 for x in (2, 4, 6)}. - После ознакомления с Python-ом я хотел чуть больше углубиться в математическую часть машинного обучения. В итоге после прохождения замечательного курса от Andrew Ng на Coursera я создал проект Homemade Machine Learning. Это была очередная "шпаргалка для себя-же" с базовыми алгоритмами машинного обучения, такими как линейная регрессия, логистическая регрессия, алгоритм k-средних, многослойный перцептрон (или персептрон?) и прочие.
- Моей следующей попыткой "поиграться в машинное обучение" стал NanoNeuron. Это были 7 простых JavaScript функций, которые должны были дать понимание читателю о том, как же машина все-таки может "учиться".
- После окончания очередного прекрасного курса по Deep Learning от все того-же Andrew Ng на Coursera я решил больше попрактиковаться с многослойными перцептронами (multilayer perceptrons), сверточными и рекуррентными нейронными сетями (convolutional and recurrent neural networks). На этот раз, вместо того, чтобы реализовывать их с нуля я решил воспользоваться уже готовым фреймворком. В итоге я начал с TensorFlow 2 с поддержкой Keras. Я так же не хотел фокусироваться на математике (позволив фреймворку сделать свое дело), вместо этого хотелось написать что-то более практичное и интерактивное, что-то, что можно было бы протестировать прямо в браузере телефона. В результате появился новый проект Interactive Machine Learning Experiments, на котором я и хочу остановиться более детально в этой статье.
Технологический стек
Тренировка моделей
- Для тренировки моделей я использовал Keras, как часть TensorFlow 2. Поскольку до этого у меня не было опыта с фреймворками для машинного обучения мне нужно было с какого-то из них начать. Один из ключевых факторов, который мне понравился в TensorFlow было наличие сразу двух его версий: версии на Python и версии на JavaScript, у которых был схожий API. В итоге я использовал Python версия для тренировки, а JavaScript версию библиотека для демо-приложения.
- Я тренировал модели на Python внутри Jupyter ноутбуков локально. Иногда использовал Colab, чтобы воспользоваться GPU и тем самым ускорить тренировку.
- Большинство моделей были натренированы на CPU старого доброго MacBook Pro (2,9 GHz Dual-Core Intel Core i5).
- И конечно же было никак не обойтись без NumPy для матричных (тензорных) операций.
Демонстрация моделей
- Я использовал TensorFlow.js для того, чтобы воспользоваться в браузере заранее натренированными на предыдущем шаге (в Jupyter ноутбуке) моделями.
- Для конвертирования моделей из формата HDF5 в формат TensorFlow.js Layers я использовал TensorFlow.js converter. Это конечно же может быть неэффективно загружать всю модель в браузер целиком (речь ведь идет о мегабайтах данных) вместо того, чтобы делать предсказания вызывая модель удаленно через HTTP запросы, но, снова-таки, вспомним, что речь идет об экспериментах, а не о зрелой и оптимизированной архитектуре, которую можно брать и сразу же использовать для "продакшна". С точки зрения простоты подхода я также хотел избежать развертывания отдельного сервера с HTTP API для предсказаний моделей.
- Демонстрационное приложение было создано на React с использованием create-react-app стартера с поддержкой Flow по умолчания для проверки типов.
- Для стайлинга я воспользовался библиотекой Material UI. Я хотел, как говориться, "убить двух зайцев сразу" и заодно попробовать новый для себя фреймворк для пользовательских интерфейсов (прости, Bootstrap).
Эксперименты
Демо-страничка с экспериментами, а также Jupyter ноутбуки с деталями тренировки доступны по следующим ссылкам:
Эксперименты с многослойным перцептроном (Multilayer Perceptron, MLP)
Распознавание цифр
Вы рисуете цифру, а модель пытается ее распознать.

Распознавание эскизов
Вы рисуете эскиз, а модель пытается его распознать.
Эксперименты со сверточными нейронными сетями (Convolutional Neural Network, CNN)
Распознавание цифр (CNN)
Вы рисуете цифру, а модель пытается ее распознать. Этот эксперимент похож на предыдущий из раздела MLP, но на этот раз модель использует CNN.
Распознавание эскизов (CNN)
Вы рисуете эскиз, а модель пытается его распознать. Этот эксперимент похож на предыдущий из раздела MLP, но на этот раз модель использует CNN.
Камень-Ножницы-Бумага (CNN)
Вы играете в камень-ножницы-бумагу с моделью. Этот эксперимент использует CNN, натренированную с нуля.

Rock Paper Scissors (MobilenetV2)
Вы играете в камень-ножницы-бумагу с моделью. Эта модель использует трансферное обучение, основанное на сети MobilenetV2.

Распознавание объектов (MobileNetV2)
Вы показываете модели ваше окружение (используя камеру ноутбука или телефона), а модель пытается определить предметы на видео и распознать их. Эта модель использует сеть MobilenetV2.

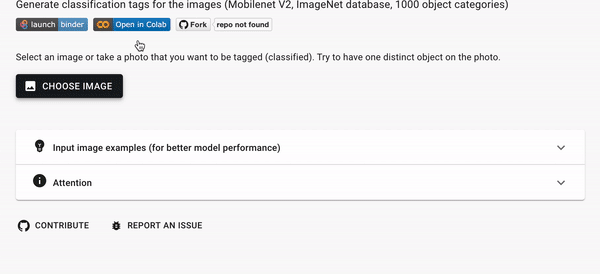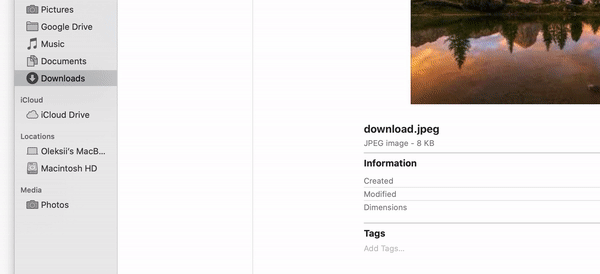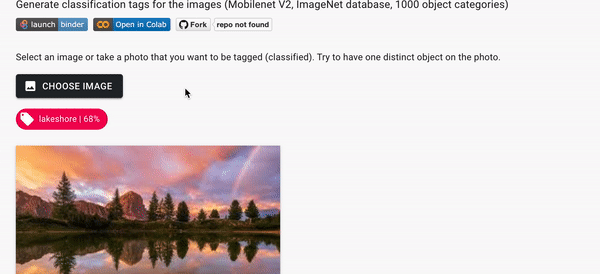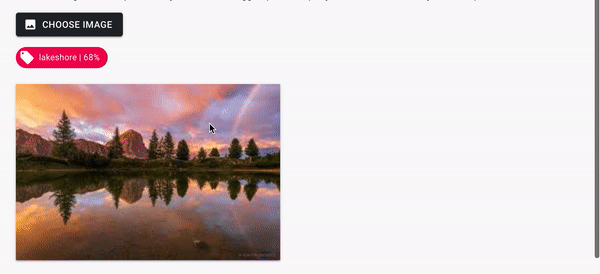
Классификация изображений (MobileNetV2)
Вы загружаете изображение, а модель пытается его классифицировать в зависимости от того, что она "видит" на картинке. Модель использует сеть MobilenetV2.
Эксперименты с рекуррентными нейронными сетями (Recurrent Neural Networks, RNN)
Суммирование чисел
Вы набираете выражение (например, 17+38) и модель предсказывает результат (например 55). Интересность этой модели заключается в том, что она воспринимает выражение на входе, как последовательность символов (как текст). Модель учится "переводить" последовательность 1 > 17 > 17+ > 17+3 > 17+38 на входе в другую текстовую последовательность 55 на выходе. Считайте, что модель скорее делает перевод испанского Hola в английское Hello, чем оперирует математическими сущностями.

Генерация текста в стиле Шекспира
Вы начинаете поэму как Шекспир, а модель пытается ее продолжить как Шекспир. Ключевое слово "пытается" .

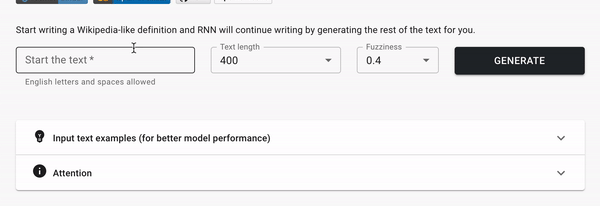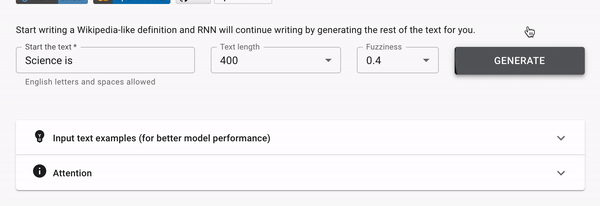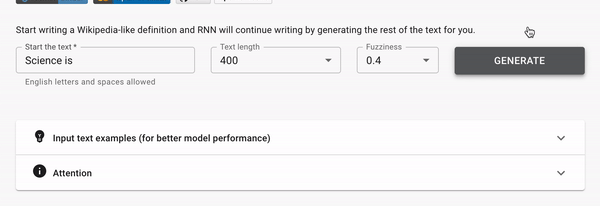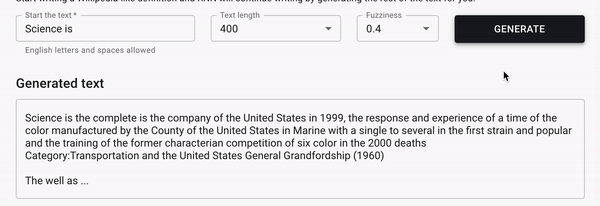
Генерация текста в стиле Wikipedia
Вы начинаете печатать Wiki статью, а модель продолжает.
Планы
Как я упомянул выше, главная задача репозитория — быть тренировочной площадкой, песочницей для обучения машинному обучению (привет, каламбур ). Поэтому в планах — продолжать учиться и экспериментировать с различными задачами в области Deep Learning. Такими интересным задачами могут быть:
- Определение эмоций
- Перенос стиля
- Машинный перевод
- Генерация изображения (например тех-же написанных цифр)
- и пр.
Другой интересной возможностью является более тонкая настройка уже имеющихся моделей, чтобы сделать их более точными. Мне кажется это может дать более глубокое понимание того, как преодолевать переученность/недоученность моделей и как поступать в случаях, когда точность модели застревает на 60% для тренировочных и валидационных данных и не хочет больше улучшаться.
В любом случае, я надеюсь, что вы найдете что-то полезное и интересное в репозитории в контексте обучения машинных моделей, ну или по крайней мере обыграете компьютер в камень-ножницы-бумагу.
Успешного обучения!
NeoCode
Никогда нейросетями не занимался, но недавно меня посетила одна забавная мысль.
А что если попробовать научить нейросеть… математике?
Допустим умножение чисел, или квадратный корень. Числа подаем в виде двоичного кода, на выходе тоже двоичный код.
Или определение простых чисел (здесь на выходе всего один бит — «простое/непростое» ну и вероятность). Научить сеть, а затем посмотреть как она справляется с неизвестными ранее числами. Какой процент правильных определений будет?
Ну и еще интересно посмотреть как такая сеть устроена, т.е. сами весовые коэффициенты (если это возможно).
Nihiroz
Все уже придумано до нас https://habr.com/ru/company/yandex/blog/493950/
NeoCode
Там задача преобразуется в изображение:)
Я конечно понимаю, что одна из тех задач, с которыми современные нейросети справляются лучше всего — распознавание изображений, но интересен именно чистый эксперимент с абстрактными знаниями, т.е. числами в чистом виде.
Сможет ли нейросеть распознать саму природу чисел?
Сможет ли она случайно открыть новые зависимости (по крайней мере гипотезы) в математике?
А еще было бы интересно подать на нейросеть абстрактные символьные знания. По сути это было бы слияние двух независимых ветвей Искусственного Интеллекта, и весьма любопытно что получилось бы. Например, научить нейросеть брать производные известных функций (в символьном виде), и затем подать неизвестную функцию.
Реально ли это? Пробовал ли это кто нибудь сделать? Может на Хабре есть опытные люди, которым понравится и которых заинтересует эта идея?
EzikBro
Опять же, идея очень не нова, но даже если машина что-то там откроет для себя, мы этого понять не сможем, к сожалению.
Тут главная не проблема не в том, чтобы научить машину, а в том, чтобы понять, чему же мы научили машину и как же она на самом деле этому научилась.
Иначе говоря — интерпретация работы обученной нейросети остается очень большой проблемой машинного обучения и останется таковой еще кучу лет.
Ну а пример нейросети-калькулятора вам дали выше. Если подобными методами обучать нейросеть не на картинках, а на абстрактных числах, то результат особо измениться не должен.
atxnsk
в основе любой нейронной сети лежит алгоритм, т.е. сеть не умеет «думать», она предсказывает результат работы алгоритма