

Spyglass by Shorai-san
Структурированные пространства имен метрик важны для быстрого доступа к информации во время инцидентов. Нужно тщательно планировать имена и измерения метрик для поддержки широкого спектра запросов и расширений. Один из способов, который эффективен при создании гибкой модели метрик, — думать о них как о дереве.
Это дает ряд преимуществ: просмотр определенных подмножеств данных, определение метрики с точки зрения ее дочерних элементов и установление соотношений между метриками.
Команда Mail.ru Cloud Solutions перевела статью, в которой рассматриваются свойства пространств имен метрик, позволяющие постепенно увеличивать детализацию запросов и переходить к подмножествам данных, а также просматривать метрику с точки зрения метрик, из которых она состоит. Многие из этих концепций вам знакомы, так как они реализованы в нативных решениях для облачного мониторинга, таких как Prometheus и DogStatsD.
Пространства имен метрик и их структура
Пространства имен метрик — это концептуальные пространства, в которых живут метрики. Они часто ограничены базой данных или учетной записью:

Пространство имен метрик — это также и структура метрик внутри пространства имен. Правильное наименование и структура открывают ряд огромных преимуществ.
У пространства имен на диаграмме выше нет явной структуры. Каждая метрика является отдельной и независимой. У метрик нет ничего общего, кроме факта, что они существуют в одном пространстве имен. В этой несвязанной структуре каждая метрика будет использоваться индивидуально. Чтобы увидеть частоту запросов http на сервис, к метрике сервиса нужно обратиться напрямую — service_N_http_requests_total.
Допустим, мы хотим видеть общее количество запросов ко всем сервисам. Что произойдет в приведенном выше примере, если мы создадим новый сервис?
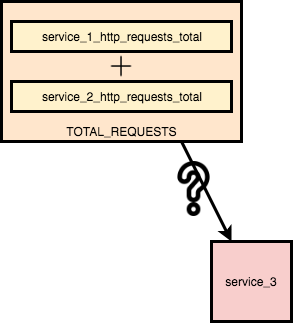
Если общее количество запросов вычисляется суммированием запросов к service_1 и service_2, то при добавлении service_3 общее количество запросов не поменяется. Чтобы вычислить правильное общее количество запросов, нужно менять правило подсчета, добавив service_3_http_requests_total. Посмотрите на график количества запросов ниже:

Дерево метрик
Альтернативой бесструктурному пространству имен является принятие явной структуры с использованием имени метрики в качестве пространства имен. На диаграмме ниже вы видите эту структуру в виде дерева:

В Prometheus и Datadog структура метрик создается при помощи меток и тегов. Теги позволяют строить дерево динамически: всякий раз, когда добавляется новый сервис, он ссылается на корневую метрику.
В Prometheus количество запросов в секунду для всех служб можно посмотреть, построив запрос, как на картинке ниже:
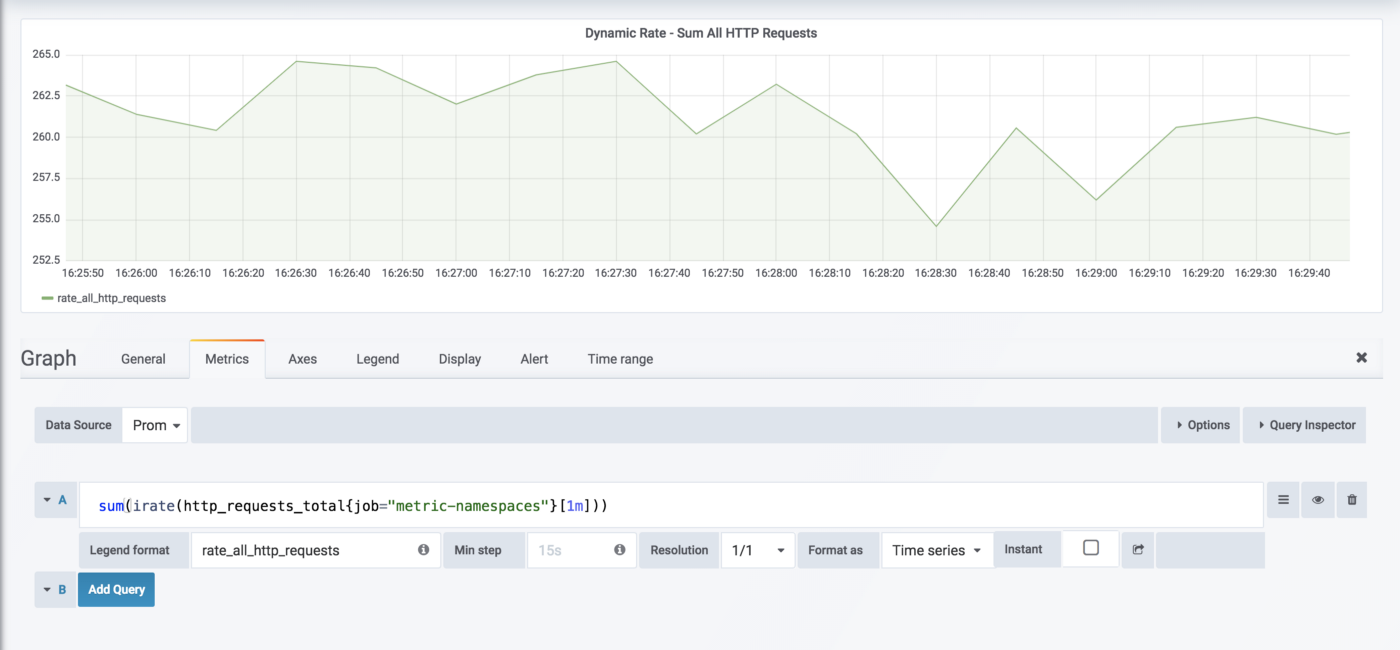
Со структурированным пространством имен можно динамически вычислять сумму запросов по всему узлу. В этом случае Prometheus рассчитывает количество запросов в секунду по каждому сервису как отдельную метрику.
Определение метрик по наследованию
При использовании дерева метрик каждое измерение метрики (по метке «service») содержит индивидуальную частоту запросов конкретного сервиса. Используя пространство имен метрик, можно получить не только общую частоту запросов, но и частоту запросов для каждого сервиса:

Пользуясь пространством имен, можно выбрать и визуализировать не только общие данные метрики, но и данные части общей метрики, сгруппированные по какому-либо признаку. Так, на картинке выше видна частота запросов к отдельным сервисам, их сумма дает частоту запросов к ноде.
Сужаем выборку — подмножества данных
Пространства имен также поддерживают сужение запросов для получения определенных подмножеств данных. Например, давайте поставим вопрос: «Какова задержка p99 (99% запросов быстрее, чем указанная задержка) во всех успешных HTTP-запросах для серверов с канареечным развертыванием?».
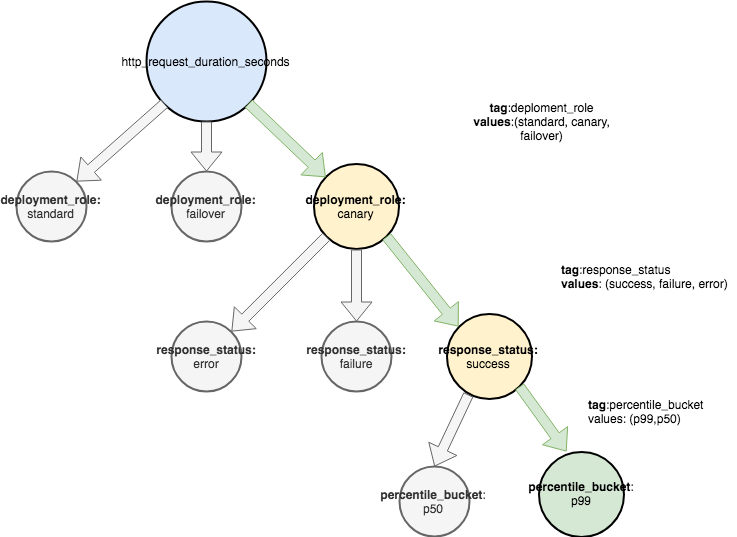
Дерево выше моделирует концепцию пространства имен и необязательно моделирует, как метрики хранятся на диске. Использование четко определенного пространства имен метрик позволяет расширять метрики по любому параметру.
На картинке ниже показан график p99 и p50 из дерева метрик выше:

Если составить более специфический запрос, то можно, например, ответить на такой вопрос: «Какова задержка p99 во всех успешных HTTP-запросах для серверов с канареечным развертыванием в разрезе каждого сервера»?

Ниже показана визуализация метрики с выборкой по machine_id:

Поскольку у метрики есть четко определенная структура, мы можем выбрать нужные данные из метрики верхнего уровня, указав нужные критерии выбора — в нашем случае machine_id.
Правило коэффициентов
Коэффициенты — еще один способ структурирования данных (корреляции). Это очень мощный механизм и основа для расчета доступности и частоты ошибок SLO (эти показатели были популяризованы специалистами SRE Google).
Коэффициенты позволяют конечному пользователю явно связывать метрики, устанавливая структуру метрик. Эти связи чаще всего выражаются в процентах, то есть доступность может быть рассчитана как соотношение «успешные запросы/общее количество запросов», а частота ошибок — как «количество ошибок/общее количество запросов». Другой пример коэффициента — как часто возникает одно состояние из нескольких состояний.
Давайте проиллюстрируем это и предположим, что есть приложение, которое выполнило запрос, и запрос мог привести к одному из двух состояний: данные взяты из кеша (cache_hit: true) или данные взяты из основного источника (cache_hit: false). Чтобы увидеть коэффициент попадания в кэш, данные должны быть структурированы следующим образом:
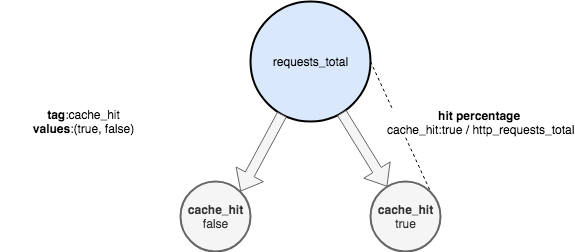
График ниже показывает частоту попадания и непопадания в кэш. Каждый запрос либо попадает, либо не попадает в кэш. Всего происходит около 160 запросов в секунду:

Следующий график показывает коэффициент попадания в кэш относительно общего числа запросов. Коэффициент попадания равен 0.5 (50%):

Так можно связать любые две метрики. В Datadog и Prometheus эта связь выражается простой арифметической операцией.
Вопросы, на которые отвечают данные
Важно правильно продумать вопросы, на которые должны давать ответ данные. В самом первом примере выборка данных не может точно ответить на вопрос: «Сколько запросов в секунду обрабатывают все инстансы?», но дерево пространства имен помогло бы получить ответ.
Другой часто встречающийся случай — пространство имен клиентских метрик с именем службы, а не с именем клиентской библиотеки. Добавление в пространство имен имени клиентской библиотеки даст ответ на вопрос: «Общее число запросов от всех клиентов?».
Общие полезные вопросы отвечают четырем «золотым» сигналам Google. Каждый вопрос ставится в общем виде, а затем уточняется:
- Сколько запросов делают все клиенты в целом?
- Сколько запросов делает каждый клиент?
- Сколько запросов каждый клиент делает к каждому узлу?
- Каков процент успешных запросов по серверу к каждой RPC?
Та же стратегия применяется к задержкам, частоте появления ошибок и сатурации ресурсов.
Общие метрики, дополненные тегами
Вот что я прочитал в лучших практиках по оптимизации запросов и хранения данных для Datadog и Prometheus.
Чтобы получить глобальное представление, поддерживающее детализацию до определенных сегментов, начните с общего верхнего пространства имен и добавьте теги и метки (начните с общих, потом добавляйте более специфичные). При этом стоит учитывать рекомендацию ниже.
Остерегайтесь кардинальности
И Datadog, и Prometheus рекомендуют ограничивать количество меток. Процитируем руководство Prometheus:
Не злоупотребляйте ярлыками
Каждый набор меток представляет собой дополнительный временной ряд, который вызывает дополнительные затраты на ОЗУ, ЦП, диск и сеть. Обычно издержки незначительны, но в сценариях с большим количеством метрик и сотнями наборов меток на сотнях серверов издержки могут быть значительными.
В качестве общего ориентира старайтесь, чтобы кардинальность вашей метрики было ниже 10. Метрик, у которых этот показатель больше, должно быть не больше нескольких штук по всей вашей системе. Подавляющее большинство ваших метрик не должно иметь меток.
Если у вас есть показатель, у которого кардинальность больше 100 или существует вероятность ее увеличения до этих пределов, изучите альтернативные решения, такие как сокращение числа измерений или вынос анализа из мониторинга в систему обработки общего назначения.
Чтобы дать вам лучшее представление об основных цифрах, давайте посмотрим на node_exporter. Он предоставляет метрики для каждой смонтированной файловой системы. Каждый узел будет иметь десятки временных рядов, скажем, для node_filesystem_avail. Если есть 10 000 узлов, вы получите примерно 100 000 временных рядов для node_filesystem_avail, что нормально для Prometheus.
Если вы добавите квоты ФС на пользователя, то быстро достигнете десятков миллионов временных рядов с 10 000 пользователей на 10 000 узлов. Это слишком много для текущей реализации Prometheus. Даже при меньших цифрах у вас уже больше не будет других, потенциально более полезных, показателей в этом мониторинге.
Начните без меток и добавляйте больше меток со временем по мере необходимости.
Удобное наблюдение на уровне пользователя часто лучше достигается с помощью распределенной трассировки. Распределенная трассировка имеет свое пространство метрик и лучшие практики.
Заключение
Важно понимать, на какие вопросы можно получить ответы, структурировав метрики. Неправильная структура ведет к сложностям в получении ответов. Хотя структурирование пространства метрик не является сложным, оно требует предварительного планирования для получения максимальной отдачи от данных.
Когда возникают проблемы, решающее значение имеет возможность вручную расширить метрику, чтобы увидеть все состояния, и важно, чтобы пространство имен не мешало этому.
Успехов!
Что еще почитать: