
Месяц назад я попытался сосчитать, сколько разных инструкций поддерживается современными процессорами, и насчитал 945 в Ice Lake. Комментаторы затронули интересный вопрос: какая часть всего этого разнообразия реально используется компиляторами? Например, некто Pepijn de Vos в 2016 подсчитал, сколько разных инструкций задействовано в бинарниках у него в /usr/bin, и насчитал 411 — т.е. примерно треть всех инструкций x86_64, существовавших на тот момент, не использовались ни в одной из стандартных программ в его ОС. Другая любопытная его находка — что код для x86_64 на треть состоит из инструкций
Я решил развить исследование de Vos, взяв в качестве «эталонного кода» компилятор LLVM/Clang. У него сразу несколько преимуществ перед содержимым /usr/bin неназванной версии неназванной ОС:
Начну со статистики по мартовскому релизу LLVM 10.0:
В прошлом топике комментаторы упомянули, что самый компактный код у них получается для SPARC. Здесь же видим, что бинарник для AArch64 оказывается на треть меньше что по размеру, что по общему числу инструкций.
А вот распределение по числу инструкций:
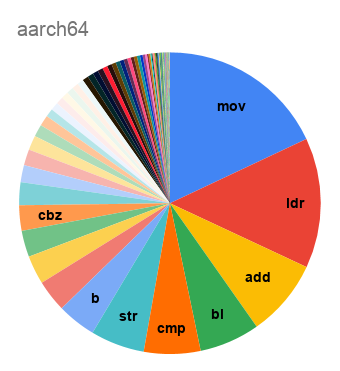

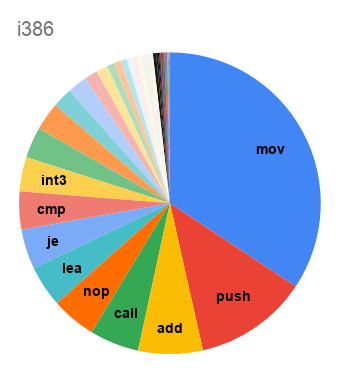
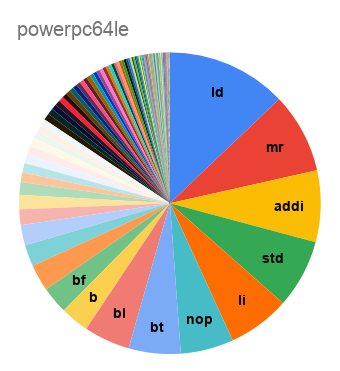
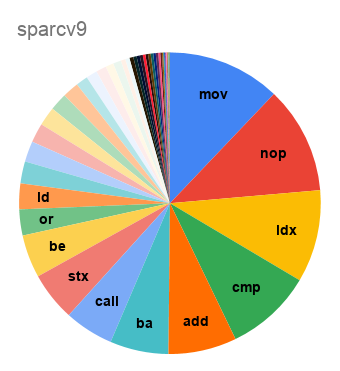
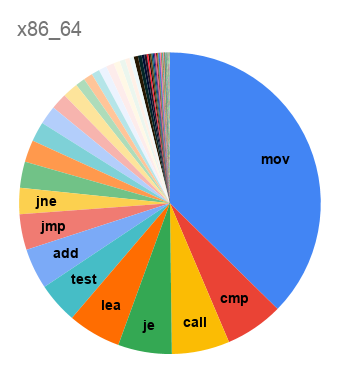
Неожиданно, что код для SPARC на 11% состоит из
А как набор используемых инструкций менялся со временем?
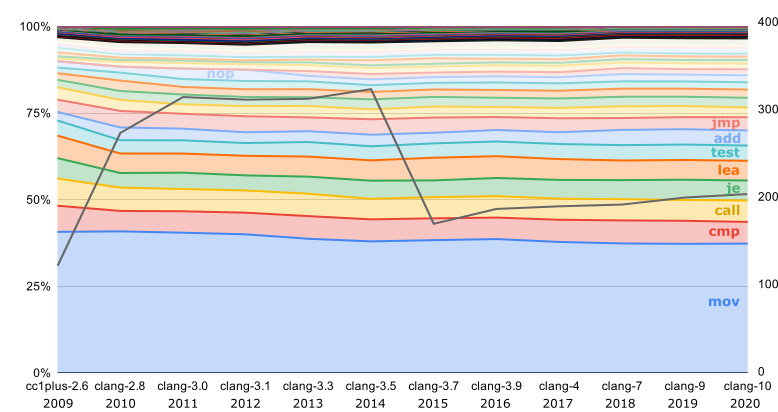
Единственная ISA, для которой в каждом релизе есть официальный бинарник — это i386:
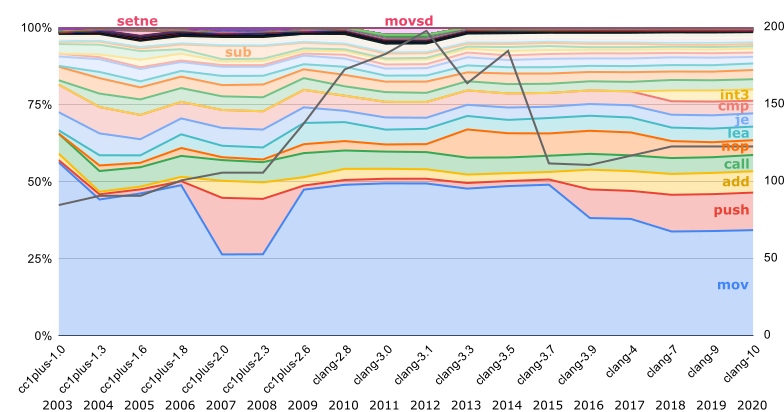
Серая линия, отложенная на правой оси — это число разных инструкций, использованных в компиляторе. Как мы видим, некоторое время назад компилятор компилировался гораздо разнообразнее.
Самые первые версии LLVM, до появления clang, выпускались ещё и с бинарниками для SPARC. Потом поддержка SPARC утратила актуальность, и вновь она появилась лишь через 14 лет — с на порядок увеличившимся числом
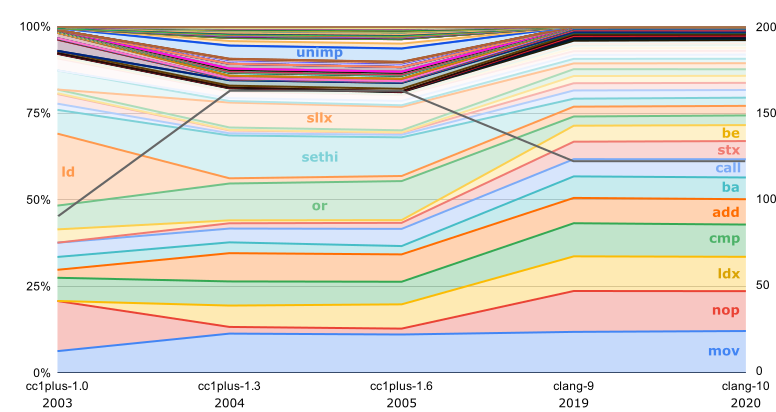
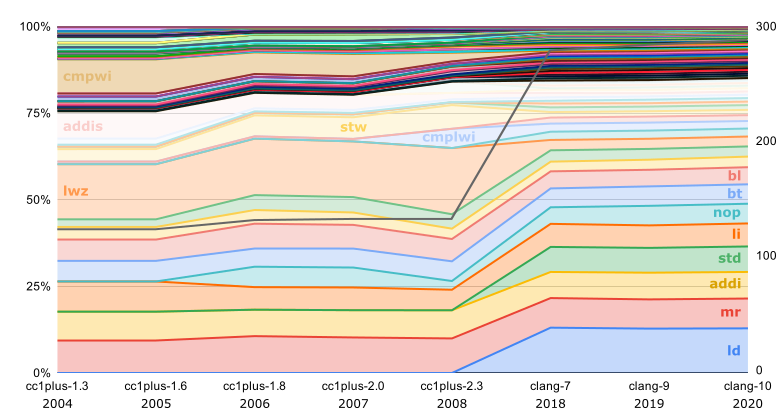
Исторически следующая ISA, для которой выпускались бинарники LLVM — это PowerPC: сначала для Mac OS X и затем, после десятилетнего перерыва, для RHEL. Как видно из графика, переход после этого перерыва к 64-битному варианту ISA сопровождался заменой большинства
В бинарниках для x86_64 и ARM частота использования разных инструкций почти не изменялась:

При подсчёте инструкций ARM я отсекал суффиксы условий — вместе с ними получалось около тысячи разных инструкций, но даже и без них ARM сильно опережает другие ISA по разнообразию генерируемых инструкций. Таким образом, слой
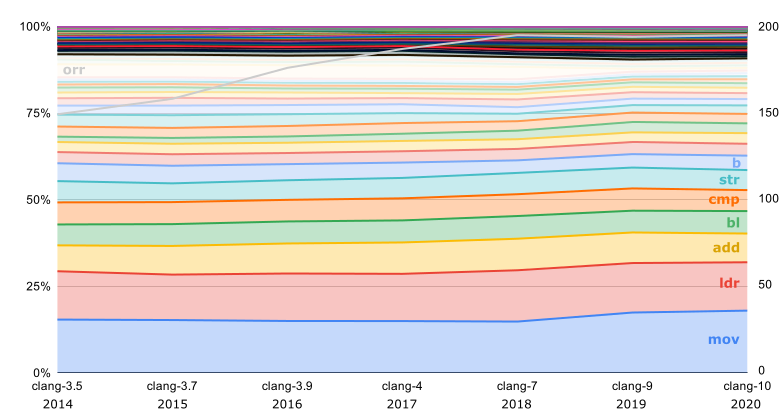
Наконец, самая недавняя ISA, для которой публикуются официальные бинарники — это AArch64. Здесь интересно то, что
PowerPC и AArch64 оказались единственными ISA, для которых число разных используемых инструкций всё растёт и растёт.
mov. (В общем-то известно, что одних инструкций mov достаточно, чтобы написать любую программу.)Я решил развить исследование de Vos, взяв в качестве «эталонного кода» компилятор LLVM/Clang. У него сразу несколько преимуществ перед содержимым /usr/bin неназванной версии неназванной ОС:
- С ним удобно работать: это один огромный бинарник, по размеру сопоставимый со всем содержимым /usr/bin среднестатистического линукса;
- Он позволяет сравнить разные ISA: на releases.llvm.org/download.html доступны официальные бинарники для x86, ARM, SPARC, MIPS и PowerPC;
- Он позволяет отследить исторические тренды: официальные бинарники доступны для всех релизов начиная с 2003;
- Наконец, в исследовании компиляторов логично использовать компилятор и в качестве подопытного объекта :-)
Начну со статистики по мартовскому релизу LLVM 10.0:
| ISA | Размер бинарника | Размер секции .text | Общее число инструкций | Число разных инструкций |
|---|---|---|---|---|
| AArch64 | 97 МБ | 74 МБ | 13,814,975 | 195 |
| ARMv7A | 101 МБ | 80 МБ | 15,621,010 | 308 |
| i386 | 106 МБ | 88 МБ | 20,138,657 | 122 |
| PowerPC64LE | 108 МБ | 89 МБ | 17,208,502 | 288 |
| SPARCv9 | 129 МБ | 105 МБ | 19,993,362 | 122 |
| x86_64 | 107 МБ | 87 МБ | 15,281,299 | 203 |
А вот распределение по числу инструкций:
Неожиданно, что код для SPARC на 11% состоит из
nop-ов, заполняющих branch delay slots. Для i386 среди самых частых инструкций видим и int3, заполняющую промежутки между функциями, и nop, используемую для выравнивания циклов на строки кэша. Наблюдение de Vos о том, что код на треть состоит из mov, подтверждается на обоих вариантах x86; но даже и на load-store-архитектурах mov оказывается если не самой частой инструкцией, то второй после load.А как набор используемых инструкций менялся со временем?
Единственная ISA, для которой в каждом релизе есть официальный бинарник — это i386:
Серая линия, отложенная на правой оси — это число разных инструкций, использованных в компиляторе. Как мы видим, некоторое время назад компилятор компилировался гораздо разнообразнее.
int3 стала использоваться для заполнения промежутков только с 2018; до этого использовались такие же nop, как и для выравнивания внутри функций. Здесь же видно, что выравнивание внутри функций стало использоваться с 2013; до этого nop-ов было гораздо меньше. Ещё интересно, что до 2016 mov-ы составляли почти половину компилятора.Самые первые версии LLVM, до появления clang, выпускались ещё и с бинарниками для SPARC. Потом поддержка SPARC утратила актуальность, и вновь она появилась лишь через 14 лет — с на порядок увеличившимся числом
nop-ов:Исторически следующая ISA, для которой выпускались бинарники LLVM — это PowerPC: сначала для Mac OS X и затем, после десятилетнего перерыва, для RHEL. Как видно из графика, переход после этого перерыва к 64-битному варианту ISA сопровождался заменой большинства
lwz на ld, и вдобавок удвоением разнообразия инструкций:В бинарниках для x86_64 и ARM частота использования разных инструкций почти не изменялась:
При подсчёте инструкций ARM я отсекал суффиксы условий — вместе с ними получалось около тысячи разных инструкций, но даже и без них ARM сильно опережает другие ISA по разнообразию генерируемых инструкций. Таким образом, слой
b на этом графике включает и все условные переходы тоже. Для остальных ISA, где условными могут быть только переходы и немногие другие инструкции, суффиксы условий при подсчёте не отсекались.Наконец, самая недавняя ISA, для которой публикуются официальные бинарники — это AArch64. Здесь интересно то, что
orr с прошлого года почти перестала использоваться:PowerPC и AArch64 оказались единственными ISA, для которых число разных используемых инструкций всё растёт и растёт.





















sinc
В конце концов ничего удивительного. Компиляторы тоже пишут люди — зачем им влезать в дебри и разбираться с экзотическими командами, когда двух десятков хватает для всего.
tyomitch Автор
Удивительным может быть то, что с десяток лет назад экзотические инструкции генерировались, а сейчас уже не генерируются.
voidnugget
Если вникнуть — есть острый недостаток в SSA формах и их проекциях (array SSA, mem SSA) для решения задач Data-Computational Locality Projection. Для этого приходится часть логики работы с mSSA/aSSA/tSSA выносить на фронт LLVM'a, и плодить mir/mlir'ы, как это было с тем же Rust'ом, и как теперь будет с СLang'ом ...
Есть проблемы с типизацией в самих языках программирования — уже лет 10 изучаю этот вопрос, и пришёл в выводу что языки надо дизайнить что бы не создавали сложностей трансляции, правда по синтаксису получается лиспо-образное веселье с привкусом питонщины и эрланга.
beskaravaev
Не могли вы рассказать подробнее о проблемах типизации в ЯП?
voidnugget
Если очень поверхностно, и если не вникать в логику (Constrainted Bunch/Separation logic и прочие расширения логики Хоара если точно), то получается что интерпретацию программ в автоматах Тьюринга надо рассматривать как "многоленточный" автомат — с командами переменной длинны и данными переменной длинны, когда длинна данных зависит от результата выполнения предыдущих команд, а длинна команд от позиций соседних лент.
Так в языке
uncle_goga
Я так понимаю вы собираетесь в перспективе написать ЯП? Если это так, то было бы здорово услышать все размышления на эту тему
voidnugget
Скорее сам ЯП уже давно написан и решаются сугубо политические и бумажные вопросы.
0xd34df00d
Интересно. Как вы это формализуете? Условно, какие query вы генерируете к пруверу?
Так-то обычно этим заморачиваются сами программисты, когда пишут сигнатуры функций, в которых нет условного IO, и отсутствие сайд-эффектов следует из well-typedness.
И я бы посмотрел на полноценные завтипы (а не как в ATS) для императивного языка (иначе к чему бы вспоминать про сепарационную логику).
voidnugget
Используется система типов посложнее чем обычно… зависимые типы хранят в себе ещё и диапазоны, или зависимые функции диапазонов принимаемых значений.
Пруверы на решётках в общем… точка в решётке — диапазон значений строгий/не строгий или функция диапазона. Прувер должен доказывать что решётки не перескутся между собой и исследовать соответствующие зависимые функции диапазонов. Потом поверх этого есть ещё пару проходов полиэдральных трансформаций для реализации свёрток типов.
Сама система типов реализует referential transparency т.к. есть transactional-SSA проекция с mem-SSA. Само блокировки/ожидания короч может расставить, выбрать где лучше скопировать, а где лучше указатель… и как потом Сompare-and-Swap делать etc. Много разных задач решается.
О них и речь… и это довольно комплексная проблема.
0xd34df00d
Ну это вполне формализуется в рамках обычного CoC, но как отсюда получается отсутствие эффектов (если мы эффектами одно и то же называем, конечно), мне сходу неочевидно.
Да, весьма интересно. Ждём статью (хоть здесь, хоть на условном arxiv).
voidnugget
Все эффекты лифтятся аргументами функции при вызовах… да и сам вызов функции рассматривается как "возникновение события" с timeout'ом и cancelation'ом — т.е. можно "отменить" каскадно при возникновении ошибок когда не совпадает range в runtime'e… под "побочкой" подразумевается гарантированная невозможность возникновения "непредвиденных" эффектов i.e. lifelock'ов / deadlock'ов / race condition'ов и т.д. и верификация именно во время компиляции. Можно представить как rust где не нужны Boxed Types, RefCells / Rc, Mutex'ы и ARC вообщe. Так как это решается системой типов.
Наличие диапазонов принимаемых значений также позволяет значительно упростить модель памяти и сделать её абсолютно детерминированной на этапе компиляции.
p.s. у меня есть HDL таргеты...
qw1
Некоторые инструкции существовали для удобства программистов на ассемблере (типа rep cmpsw), потребность в них падает.
С другой стороны, «обычные», часто используемые инструкции оптимизируются производителями процессоров так, что можно оставаться на обычных и отказаться от экзотических без потери скорости (типа leave/enter для пролога/эпилога функций)
khim
Тольво вы путаете «можно» и «нужно». Гляньте в табличку. Если LEAVE просто тормозит (3 тика на Ryzen для того, что она делает — это много), то ENTER сегодня — это «гроб с музыкой»: 16 тактов, за это время можно штук 20-30 обычных MOV исполнить!
Исселование, подобное тому, что делает автор разработчики процессоров тоже делают… и в результате на современных процессорах разные экзотические инструкции не то, что бессмысленно использовать — их вредно использовать! Даже руками на ассмеблере! Скорость будет никакая!
Calc
может модуль предсказания ветвления не дружит с экзотикой, вот больше их и не используют?
khim
Там не всё так просто. Поскольку компиляторы «экзотику» не используют, то на неё «подзабили»: инструкции есть, но поддерживаются «на отвяжись».
Одно время «забили» даже на
MOVSи разработчики упражнялись в подборе оптимального набора SSE инструкций. А в Ivy Bridge «случилось чудо»: внезапно старая добраяMOVSBбыла оптимизирована и стала работать быстрее любых SSE (для больших объёмов: 256 байт и больше). Интересно — умеет это использовать LLVM или нет…Tiriet
странно. По Вашей ссылке p11-55^
khim
А моё замечание в скобочках вы проигнорировали?
Tiriet
наверно, я просто неправильно понял «few hundred bytes»- мне казалось, что «несколько сотен»- это больше, чем три сотни (256), а для больших объемов- вроде и так понятно, что раз оно не ложится в один запрос к памяти- то как ни оптимизируй эту инструкцию, скорость ее все равно упрется в ПСП, которой все равно, как оно там в процессоре реализовано, хоть через SSE, хоть через IA-32.
На числодробилке я не вижу особой разницы между movdqa, movapd, movupd и movsd, когда надо больше, чем «few hundred bytes» прожевать: все выдают ~12GB/s.
CoolCmd
а я помню, что movsb быстро работала уже в sandy bridge
khim
Она там работала гораздо быстрее, чем у AMD, но медленнее, чем SSE-мувы.
CoolCmd
не в курсе, как сейчас с этим у рязани?
khim
Нет, не в курсе. Но это не так важно: процессоры, которые такое умеют должны выставлять специальный CPUID бит.
Так что бенчмарки при запуске программы устраивать не нужно. Либо Ryzen так умеет и выставляет бит, либо не умеет и тогда нужно использовать SSE.
CoolCmd
что умеет? movsb была еще в 8086.
thealfest
Есть такой флаг в CPUID:
Enhanced REP MOVSB/STOSB
khim
«Умеет в MOVSB, который быстрее SSE».
Maccimo
… либо это описано в ERRATRA
MooNDeaR
Тоже можно понять. Сейчас поколений процессоров накопилось просто охренеть сколько и выбор некоторого "базового" безопасного набора в качестве "швейцарского ножа" вроде как даже и логично. Уверен, если поиграться с флагам компилятора заточив бинарь только под одно конкретное семейство процессоров, можно получить более разнообразный набор инструкций в бинаре.
Psionic
И пополнить багтрекер разработчиков компилятора, так как чето меня терзают сомнения что все эти оптимизации под конкретные процы хорошо реализованы.
tbl
Обычно так и собирается под конкретный проц при деплое на железные сервера или в облако, т.к. проц уже заранее известен. Это для десктопных приложений, или проприетарных бинарников с закрытым кодом генерится общий код, а-ля Generic x86-64 с SSE2.
khim
-march=native, например.Psionic
А как обвязка зависимостями сторонними зависимостями на этот подход влияет? Одно дело скомпилить один пакет, а другое дело скомпилить все древо заисимостей, что вообще не всегда возможно, а когда возможно то может занять пару/тройку десятков часов чистого времени.
0xd34df00d
Нормально влияет. Опять же, гентушники не видят проблем, а (по крайней мере, в моей практике) рабочий вычислительный код имеет не так много зависимостей, чтобы их было проблематично собрать руками под железо.
tbl
Да и крупные компании с монорепами (включающими в себя все внешние зависимости) могут позволить себе собирать варианты исполняемых файлов со статической линковкой зависимостей под конкретный набор процов, используемых в их датацентрах. С использованием сборочных ферм и кэширования это проходит за считанные минуты.
vvmtutby
Было бы интересно сравнить подходы с:
«A Superscalar Out-of-Order x86 Soft Processor for FPGA» Henry Wong, Ph.D. Thesis, University of Toronto, 2017
kdmitrii
Как раз затем что разработчики компиляторов должны использовать все что только можно чтоб ускорить полученный код.
sinc
Тогда придется перекомпилировать код под каждый процессор. Вы не забывайте, что в процессорах тоже бывают ошибки.
Srgun
Потому и стали так популярны виртуальные среды исполнения, т.к. на лету могут давать более оптимальный код для конкретного современного процессора, по сравнению с заранее компилированным универсальным вариантом.
khim
Могут… но не дают. C++ всё ещё быстрее — даже без использования экзотики.
Другое дело, что когда выбором заведуют маркетологи реальные цифры никого не волнуют, главное — красивые лозунги.
sergegers
Интеловский компилятор может делать бинарь, который загрузившись, смотрит, какие расширения поддерживаются процессором, и загружает наиболее оптимальный вариант.
khim
Ага. А перед этим он смотрит, чтобы процессор был от Intel, не AMD, да.
sergegers
Ну да, есть такое, расширенные инструкции у AMD он не использует.
VolCh
Даже те, которые полностью совместимы с Intel?
Srgun
+- да
типичный пример — LinPack: если на AMD-ом проце запустить стандартную версию, собранную Intel-ским компилятором, то результаты в разы ниже аналогичных Intel-процессоров и версии, собранной не Intel-компилятором.
khim
Никакие. Проверка на производителя процессора идёт в самом начале.
И её можно вырезать из бинарника, кстати — есть умельцы. Тогла скорость работы на AMD'шных процах резко возрастает.
sergegers
Да. Игнорируется поддержка SSE2, SSE3.
0xd34df00d
В этом нет ничего страшного. Говорю как гентушник дома и компиляющий вычислительный код с
-march=nativeна работе.fougasse
Значит, оставшиеся инструкции не настолько ускоряют/уменьшают код, чтобы инвестиции в их использование окупились.
Gryphon88
Возможно, интеловский или иной коммерческий компилятор использует больше инструкций.