
Всем привет! Думаю, у многих сразу возник другой вопрос — а зачем вообще нужна ещё одна статья про LLVM, ведь на хабре их и так больше сотни? Моей задачей было написать "введение в тему" for the rest of us — профессиональных разработчиков, не планирующих создавать компиляторы и совершенно не интересующихся особенностями устройства LLVM IR. Насколько я знаю, подобного ещё не было.
Главное, что интересует практически всех — и о чём я планирую рассказать — вынесено в заголовок статьи. Зачем нужен LLVM, когда есть GCC и Visual C++? А если вы не программируете на C++, вам стоит беспокоиться? И вообще, LLVM это Clang? Или нет? И что эти четыре буквы на самом деле означают?
Что в имени тебе моём?
Начнём с последнего вопроса. Что скрывается за буквами L-L-V-M? Когда-то давно они были акронимом для "Low Level Virtual Machine", а в наше время означают… ровным счётом ничего.
LLVM родился как исследовательский проект Криса Латнера (тогда ещё студента-магистра в Университете штата Иллинойс в Урбана-Шампейн) и Викрама Адве (тогда и по сию пору профессора в том же университете). Целью проекта было создание промежуточного представления (intermediate representation, IR) программ, позволяющего проводить "агрессивную оптимизацию в течение всего времени жизни приложения" — что-то вроде Java байт-кода, только круче. Основная идея — сделать представление, одинаково хорошо подходящее как для статической компиляции (когда компилятор получает на вход программу, написанную на языке высокого уровня, например C++, переводит её в LLVM IR, оптимизирует, и получает на выходе быстрый машинный код), так и динамической (когда runtime система получает на вход машинный код вместе с LLVM IR, сохранённым в объектном файле во время статической компиляции, оптимизирует его — с учётом собранного к этому времени динамического профиля — и получает на выходе ещё более быстрый машинный код, для которого можно продолжать собирать профиль, оптимизировать, и так до бесконечности).
Интересно? Хотите узнать подробности? Диссертация Криса Латнера доступна онлайн.
Вот картинка из неё, иллюстрирующая принципы работы "оптимизации в течение всего времени жизни приложения":
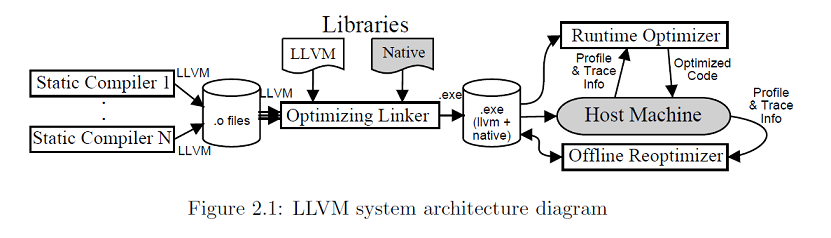
Эта картинка, конечно же, про LLVM — но совершенно не про то, что под словом "LLVM" понимается сейчас. Больше того! — на сайте llvm.org написано, что LLVM это не о виртуальных машинах, и вовсе даже не акроним, а просто такое вот название проекта.
Как так получилось? В 2005 году Крис защитил кандидатскую диссертацию и переехал из Иллинойса в Кремниевую долину...
Apple, Google и все-все-все
Примерно в то же время Apple начала задумываться о создании своего собственного компилятора Objective-C и решила сделать ставку на Криса Латнера и его (в то время по сути ещё академический) проект LLVM. Зачем Apple понадобился собственный компилятор? Прежде всего, Apple хорошо известна как компания, стремящаяся контролировать весь технологический стек. Кроме того, у Apple были большие проблемы с инструментами разработки для ранних Маков на основе PowerPC, когда выбранный партнёр (Symantec) не сумел выпустить хороший компилятор вовремя, что поставило под риск будущее всей компании.
В 2005 году Apple уже достаточно долгое время инвестировала в разработку GCC, но как и многие другие, была сильно недовольна лицензией GPL. Особенно GPLv3, на которую перешёл GCC начиная с версии GCC 4.3. Недовольство Apple было так велико, что последней версией GCC, поставляемой в составе XCode, так и осталась GCC 4.2. Главная проблема GPL для компаний, выпускающих секретное "железо": если бинарии для этого железа генерируются с помощью GCC, то исходный код компилятора, в том числе и секретную часть, надо открыть — и ваше секретное железо теперь совсем не секретное! Проект LLVM всегда был под "либеральной" лицензией (вначале UIUC, потом Apache 2.0), которая не накладывает столь жёстких ограничений, и позволяет свободно комбинировать в одном продукте открытый и закрытый код.
Apple был нужен обычный статический компилятор, а не система для "оптимизации в течение всего времени жизни приложения", и поэтому Крис Латтнер переделал LLVM в бэк-энд для GCC. "Бэк-эндом" называется та часть компилятора, что выполняет оптимизации и генерирует машинный код; есть ещё "фронт-энд" — принимающая на вход пользовательскую программу на языке высокого уровня и переводящая её в промежуточное представление, например LLVM IR. Комбинация GCC-фронт-энда и LLVM-бэк-энда работала неплохо, но не без проблем — соединение двух больших и независимых проектов, преследующих разные цели, всегда чревато появлением лишних ошибок и обрекает на вечную игру в "догонялки". Вот почему уже в 2006 году Крис начал работать над новым проектом, получившим название "Clang".
Происхождение имени "clang" интуитивно понятно — это комбинация слов "C" и "language". "C" указывает на семейство C-образных языков, куда кроме самого C входят также C++ и Objective-C. Кстати говоря, "clang" произносится как "к-ланг", а не как "си-ланг"! — не повторяйте популярную ошибку!
Комбинация фронт-энда Clang и бэк-энда LLVM называется Clang/LLVM или просто Clang. Сейчас это один из самых популярных (если не самый популярный!) компилятор C++ в мире.
Большую роль в развитии и росте популярности LLVM и Clang сыграла компания Google. В отличие от Apple, Google выбрала LLVM в основном по техническим причинам — GCC очень старый проект, который сложно модифицировать и расширять. Для Google всегда были важны надёжность и безопасность программ — например, одно из правил компании требует обязательного добавления статической проверки в компилятор для каждой новой ошибки, обнаруженной в продакшене. Добавить подобного рода проверку в Clang гораздо проще. Ещё один аргумент в пользу Clang — поддержка Windows. GCC органически не подходит для Windows, и хотя есть версия GCC и для этой операционной системы, серьёзную разработку с её помощью вести нельзя. Некоторые вещи, например поддержку отладочной информации в формате PDB, в GCC в принципе невозможно добавить — всё из-за тех же лицензионных ограничений.
Внутренние команды Google всегда были вольны в праве выбора компилятора, и большая часть из них использовала GCC; кто-то применял коммерческие компиляторы от Intel и Microsoft. Постепенно практически весь Google всё-таки перешёл на Clang. Большими вехами стали появление полнокровной поддержки Windows (которую сделала сама Google, причём для компиляции всего-навсего двух программ: Chromium и Google Earth) и переход на LLVM в качестве основного компилятора операционной системы Android. Причину перехода лучше всего объяснили сами разработчики Android: "Пришло время перейти на единый компилятор для Android. Компилятор, способный помочь найти (и устранить) проблемы безопасности."
После того, как переход сделала Google, рост популярности LLVM было уже не остановить. Всё больше и больше компаний и академических организаций начали делать ставку на LLVM: ARM, IBM, Sony, Samsung, NXP, Facebook, Argonne National Lab… это именно тот случай, когда "всех не перечесть". Некоторые компании продолжают поддерживать GCC, но в значительно большей степени инвестируют именно в LLVM — например, так поступают Intel и Qualcomm. Наплыв инвестиций создал "восходящую спираль роста" — когда новые улучшения LLVM привлекают новых пользователей, те инвестируют в дополнительные улучшения, те в свою очередь приводят ещё больше новых пользователей и инвестиций, и так далее.
LLVM против GCC
Возможно, к этому моменту вы уже начали задаваться вопросом: "ну хорошо, причины, побудившие к переходу Apple и Google, понятны… но мне-то что за дело? Почему лично я должен переходить на LLVM? Чем GCC плох?"
Ответ — абсолютно ничем! GCC продолжает быть отличным компилятором, в который вложены многие годы труда. Да, его сложно расширять, и да, над его развитием работает не так много людей, и да, лицензия GPL серьёзно сужает круг проектов, которые можно сделать на основе кодовой базы GCC — но всё это проблемы разработчиков GCC, а не ваши, ведь так?
К сожалению, проблемы развития проекта GCC в итоге замечают и конечные пользователи — ведь постепенно GCC начинает отставать от LLVM. Все основные "игроки" мира ARM (Google, Samsung, Qualcomm и собственно компания ARM) сфокусированы на развитии прежде всего LLVM — а значит, поддержка новых процессоров на основе архитектуры ARM появляется в LLVM раньше и включает больше оптимизаций и более тщательный "тюнинг" производительности, чем в GCC.
То же самое касается поддержки языка C++. Ричард Смит, инженер компании Google, выступающий секретарём комитета ISO по стандартизации C++ — иными словами, тот человек, кто собственно пишет текст всех дополнений стандарта своими руками — является маинтейнером фронт-энда Clang. Многие другие заметные участники комитета также являются активными разработчиками Clang / LLVM. Сложите эти два факта, и вывод очевиден: поддержка новых дополнений в языке C++ раньше всего появляется именно в Clang'е.
Ещё одно важное преимущество Clang — и как мы знаем, главная причина перехода команды Android на LLVM — развитая поддержка статической верификации. Говоря простыми словами, Clang находит больше warning'ов, чем GCC, и делает это лучше. Кроме того, есть специальный написанный на основе Clang'а инструмент, под названием Clang Static Analyzer, включающий в себя богатую коллекцию сложных проверок, анализирующих больше чем одну строку кода, и выявляющих проблемы использования языка С++, работы с нулевыми указателями и нарушения безопасности.
В проект LLVM входит много разных инструментов, являющихся лидерами в своей области: коллекция динамических верификаторов под названием "санитайзеры", рантайм-библиотека OpenMP (лучшая на рынке), lld (сверх-быстрый линковщик), libc++ (наиболее полная реализация стандартной библиотеки C++). Все они могут использоваться независимо от LLVM — в том числе и с GCC тоже, как минимум в теории. На практике же у каждого компилятора есть множество небольших отличий и особенностей, и потому все эти инструменты лучше всего работают именно с LLVM — ведь они разрабатываются, тестируются и выпускаются все вместе.
Clang разрабатывался как полностью совместимая замена GCC, так что в стандартном проекте для перехода достаточно просто поменять имя компилятора. На практике возможны сюрпризы — от новых ошибок на этапе компиляции до неожиданных падений при тестировании. Обычно это означает, что в проекте есть код, полагающийся на аспекты стандартов C и C++ с "неопределённым поведением" — которое может трактоваться компиляторами GCC и Clang по-разному.
Например, бесконечные циклы. Как вы думаете, что должно случиться после компиляции и выполнения такой программы?
#include <stdio.h>
static void die() {
while(1)
;
}
int main() {
printf("begin\n");
die();
printf("unreachable\n");
}Попробуйте откомпилировать её с помощью "gcc -O2" и "clang -O2" — результат может вас удивить. Причина в "неопределённом поведении" для бесконечных циклов в стандарте языка C (есть лишний час в запасе? — можете узнать подробности). Раз поведение "неопределено", компилятор волен делать с бесконечными циклами вообще всё, что угодно — даже "выпускать из ноздрей летающих демонов"! (это выражение стало мемом в сообществе C разработчиков). Как можно убедиться, Clang и GCC просто поступают по разному. Конечно же, основывать логику программы на неопределённом поведении не лучшая практика (кто захочет испускать демонов из носа?) и такой код должен исправляться, как и любая другая ошибка.
Я рекомендую попробовать заменить "gcc" на "clang" (или "g++" на "clang++" в случае C++) в каком-то из ваших проектов. Кто знает? — может вам удастся увидеть летающих демонов?
Если с демонами не повезёт, вы точно заметите быструю скорость компиляции и линковки, улучшения в производительности, оптимальное использование новых инструкций ARM — а возможно, мощные статические и динамические верификаторы помогут поймать неочевидные ошибки и "дыры" в безопасности ваших программ.
"Зонтик" LLVM
Проект LLVM вырос за рамки компилятора C++. Один из важных принципов разработки LLVM — написание кода как набора переиспользуемых библиотек, которые можно соединять разным образом и для разных целей — привёл к появлению множества интересных новых инструментов. Часть из них была добавлена к проекту, так что LLVM со временем превратился в "зонтик" для нескольких совершенно разных подпроектов. Ещё больше инструментов развиваются за пределами проекта LLVM, но полагаются на библиотеки LLVM для анализа и оптимизации программ, а также генерации кода.
Я уже упоминал Clang Static Analyzer, санитайзеры, OpenMP, libc++ и lld — это инструменты, более всего интересные C++ разработчикам. Компилятор языка Rust также основан на LLVM — решение, позволившее Rust задействовать всю мощь LLVM оптимизатора для генерации быстрого кода для множества аппаратных платформ с самого начала существования языка! Помимо C++ и Rust, LLVM используется в компиляторах (как статических, так и динамических) для таких разных языков как D, Fortran, Haskell, Julia, Kotlin, Lua, PHP, Python. Создателю нового языка достаточно написать фронт-энд, переводящий программы в формат LLVM IR, чтобы воспользоваться оптимизатором и генератором кода мирового уровня! Лёгкость использования LLVM в этом качестве дала толчок появлению новых разработок в области языков программирования.
Одна из важных областей применения LLVM — это тензорные компиляторы, многократно ускоряющие задачи машинного обучения. Два из самых популярных ML фреймворков — TensorFlow компании Google и PyTorch от Facebook — полагаются именно на LLVM для генерации быстрого кода.
Сейчас LLVM стал настолько популярен, что он встречается практически повсюду. Если вы запускаете приложение или ML модель (на телефоне, десктопе или серверной ферме), то почти наверняка ваше приложение или модель каким-то образом прошло через один из инструментов, использующих LLVM.
Всё это сделало LLVM критически важным проектом для основных игроков в индустрии — ведь каждый новый патч в "core" библиотеки LLVM влияет на сотни инструментов! Список спонсоров LLVM Developers' Meeting читается как справочник "кто есть кто" мира IT. Компания, в которой я работаю, Huawei, также является спонсором — ведь как любая большая и разносторонняя организация, мы используем LLVM в большом числе своих продуктов.
Надеюсь, эта небольшая статья справилась со своей задачей, и вы стали лучше понимать что такое LLVM и почему этот проект так важен. Возможно даже решили попробовать один из LLVM-инструментов в своём проекте?
Я был и остаюсь вовлечён в разработку LLVM в течение многих лет (сначала в Intel, затем в NXP и теперь в Huawei), так что этот проект очень близок моему сердцу. Раскрою карты! — у статьи была и вторая, секретная цель: заразить энтузиазмом и верой в LLVM всех читателей. Что скажете? — удалось? :)






















yleo
Ну что сказать, реклама LLVM удалась ;)
lovefst
Согласен, хоть и плюсануть не могу.
По мне, так clang тормознее в компиляции, чем gcc.
С другой стороны — в статье отмечено важное преимущество перед обычными компиллерами(или правильнее сказать линковщиками под конкретную платформу?) — байткод реально переносим, но только в том случае, если байт реально 8бит, а не к-то вывернутый DISP-проц с 10-битным байтом и нормальной Си-IDE
Опять же — речь идёт только о высокоуровневых языках, в то время как на Си или Rust(когда же он заржавеет) шланг сливает, так же как и любому алгоритму, заточенному под платформу — посмотрите на код ffmpeg — там если его компилить по дефолту — то туча «вариативно», то туча объектников собирается полчаса под каждый вариант набора комманд проца…
yleo
У вас несколько неверное представление, поэтому вы пару раз перемешали мух с котлетами:
tyomitch
Более переносима, чем машинный код; но намного менее переносима, чем исходник на ЯВУ. Цель переносимости между целевыми архитектурами перед LLVM-IR и не ставилась.
yleo
В контексте удобно рассказать о знатной бага-фиче с
[[gnu::pure]]в C++ и__attribute((pure))__в C:на злодля совместимости с gcc поддерживается фронтендом и обрабатывается бэкендом, а также честно виден через__has_attribute(pure).[[gnu::pure]]clang насильно включаетnoexcept(true), т.е. задним числом меняет тип функции (начиная с C++17).noexcept(false).Теперь представьте, что у вас проект с использованием десятка продвинутых C++ библиотек, в одной из которых есть трех-этажные шаблонны с абсолютно обоснованным использованием
[[gnu::pure]]в паре-тройке функций, т.е. с втихую добавленнымиnoexcept(true).Этот
noexcept(true)неплохо "протекает" через инлайнинг и IPO. При этом clang много чего оптимизирует/совмещает кадры стека и т.д. Соответственно, в каких-то случаях появление исключения приведет к вызовуstd::terminate(), а в других нет.При каких-нибудь жалких 10-20К строк кода отлаживать сплошное удовольствие. Я провозился несколько часов, пока не дошел до "поштучного" анализа unwind-таблиц. Что характерно, эта бага-фича гуглится элементарно, как только понимаешь связь между
[[pure]]и проблемами с исключениями. Но никак не раньше ;)