
Израильские ученые Шимон Ивэн (Shimon Even) и Ишай Мансур (Yishay Mansour) еще в 1997 году задались вопросом: насколько минимальной конструкцией может обладать стойкий блочный шифр? Под минимальностью они подразумевали число конструктивных элементов в схеме шифра, а под стойкостью — любую (формально верную) оценку снизу сложностей атак на этот шифр. Как говорится, под катом — описание минимального (и по сей день) блочного шифра с доказуемой стойкостью.
Лирическое отступление
А все потому, что мы пока не умеем получать оценок снизу. Друзья, в математике (и особенно в криптографии) не так много красивых идей и изящных решений, а доказанных оценок снизу — еще меньше. Рассмотренный здесь шифр, на мой взгляд, попадает в пересечение: он максимально прост, и в то же время формально стоек.
Предупреждаю сразу, что эта публикация — не художественное произведение для неподготовленных читателей, хотя и не содержит ничего более сложного, чем формулу условной вероятности Байеса и элементарную арифметику дробей. Неискушенный читатель останется удовлетворенным и описанием конструкции шифра, а строгое доказательство его стойкости приведено здесь для специалистов и истинных ценителей математики.
Израильские ученые Шиман Ивэн (Shimon Even) и Ишэй Мансур (Yishay Mansour) в [EM97] предложили способ построить блочный шифр, обладающий доказуемой стойкостью, на основе единственной случайно выбранной подстановки из
Прежде, чем я познакомлю вас непосредственно с этим блочным шифром, позволю себе указать список введенных условных обозначений и базовых определений. Впрочем, вы всегда сможете к нему вернуться, поэтому, в том случае, если мне удалось пробудить в вас нешуточный интерес увидеть все «здесь и сейчас», переходите непосредственно к описанию шифра.
Множества, наборы
— неупорядоченное множество элементов
— упорядоченное множество элементов
Начертания
— пространства, используемые криптосистемами
— алгоритмы, модели вычислений
— оракулы
— множества, выработанные алгоритмами
— подстановки
— задачи
Обозначения
— множество открытых текстов (сообщений)
— открытые тексты
— множество шифртекстов (криптограмм)
— шифртексты
— множество ключей
— ключи
— истинный ключ
— функция шифрования
— функция расшифрования
— оракулы, реализующие подстановки
— оракулы, реализующие функции
на ключе
— вероятность успеха алгоритма
— время выполнения алгоритма
Определения
Криптосистемой
— (инъективная) функция шифрования (encipher):
— функция расшифрования (decipher):
Классическая схема Even–Mansour
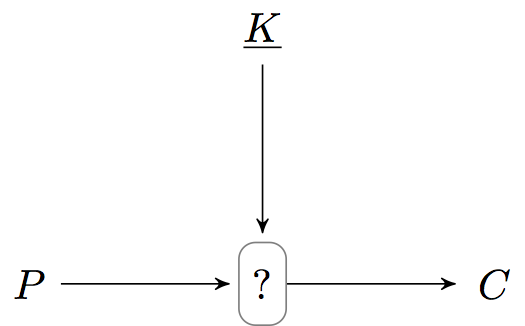
Израильские ученые Шимон Ивэн (Shimon Even) и Ишай Мансур (Yishay Mansour) в своей работе предложили блочный шифр c доказуемой криптостойкостью, для которого требуется всего одна подстановка
При этом предполагается, что выбранная подстановка не является частью ключа, и доступна любому атакающему в виде некоторого «черного ящика».
Утверждается, что, с точки зрения атакующего, предложенный шифр практически неотличим от идеального случайного шифра, и вероятность успешного вскрытия системы (восстановления секретного ключа
Утверждается также, что использование псевдослучайной подстановки вместо истинно случайной подстановки не изменяет показанной стойкости шифра.
Описание
Пусть
Предполагается, что для любых элементов
Пространства открытых и шифртекстов являются пространствами двоичных
Секретный ключ
Предполагается также, что выбранный секретный ключ

Шифрование открытого текста
а расшифрование шифртекста
Действительно, просто? Взяли сообщение, поксорили с первой половиной ключа, по открытой и доступной всем табличке заменили, поксорили со второй половиной ключа, и получилась криптограмма. Здорово, правда? Почему же никто не использует эту схему на практике? Ведь она намного проще AES, да и DES. Самый простой блочный шифр. Где здесь подвох?
О минимальности схемы
Следует отметить, что классическая схема минимальна в том смысле, что удаление любого из элементов этой схемы приводит к значительному ослаблению ее стойкости. Легко показать, что удаление любого из сложений с подключами, либо подстановки
- Отсутствует сложение с первым подключом.
Функция шифрования имеет вид:
Злоумышленник может легко вычислить секретный ключ, зная подстановку
:
- Отсутствует сложение со вторым подключом.
Функция шифрования имеет вид:
Злоумышленник может легко вычислить секретный ключ:
- Отсутствует
–блок (подстановка
Функция шифрования имеет вид:
Злоумышленник может легко вычислить секретный ключ
О стойкости схемы
Предположения стойкости, определения
Стойкость предложенной схемы обусловлена следующими предположениями:
- злоумышленнику не известен истинный ключ
- злоумышленник имеет возможность шифровать открытые тексты (сообщения) и расшифровывать шифртексты (криптограммы) на секретном ключе
- злоумышленник имеет возможность вычислять значения перестановки
Всякий алгоритм, вскрывающий систему, может обращаться к следующим четырем оракулам
- оракул
вычисляет значение перестановки
на
–мерном двоичном входном наборе
:
- оракул
вычисляет значение перестановки
на
:
- оракул
зашифровывает
на
–мерном ключе
- оракул
расшифровывает
на
Далее, если подстановка, значение которой вычисляет оракул
Обращаясь к оракулам
Таким образом, общение всякого алгоритма с оракулами
Назовем такие пары
Обращаясь к оракулам
Так, общение всякого алгоритма с оракулами
Назовем такие пары
Определение
Аналогичное определение можно сформулировать и для
Определение
Утверждение 1 (Overlapping pairs are identical)
Ввиду того, что все оракулы
- пересекающиеся
- пересекающиеся
По модулю утверждения 1 можно полагать, что все пары множеств
Вероятностью успеха
Под временем выполнения
Определение
Функция
Определение
Задачу
Описание формальной модели
В предложенной в [EM97] модели злоумышленник в полном объеме обладает знаниями об устройстве шифра и выбранной подстановке
Задача дешифрования ( )
)
Под задачей дешифрования (
- (ограниченный по
) оракул
расшифровывает всякий
Алгоритм
Задача построения новой пары открытый текст / шифртекст ( )
)
Под задачей построения новой пары текстов (
Успехом алгоритма
Сведение задачи построения пары текст / шифртекст к задаче вскрытия ( )
)
Теорема 1 (EFP to CP reduction)
Пусть
Без ограничения общности можно полагать, что, если алгоритм
На основании алгоритма
- Зафиксируем шифртекст
;
- Начнем выполнение алгоритма
;
- Выберем случайное
, распределенное равномерно на отрезке
;
- Остановим выполнение алгоритма
запросов к оракулам;
- Если в запросе
, то выполнение алгоритма прекращается, и исходная пара —
.
Легко видеть, что алгоритм
что и требовалось доказать.
Следствие 1.1
Пусть задача
Следует заметить, что обратное утверждение (сводимость
Стойкость системы при использовании случайной подстановки
Основные идеи доказательства стойкости заключаются в следующем:
- показать, что на любом этапе полиномиально ограниченной атаки, множество «хороших» ключей (ключей, истинность которых злоумышленник ни подтвердить, ни опровергнуть на основе имеющихся у него данных) экспоненциально велико (Лемма 1);
- показать, что злоумышленник может «угадать» истинный ключ
- показать, что злоумышленник собрать достаточно данных для выявления истинного ключа
Определение
Первый подключ
Другими словами, подключ
Очевидно, такой ключ
С помощью других собранных
Аналогичное определение можно сформулировать и для вторых подключей
Определение
Второй подключ
Определение
Ключ
Утверждение 2 (True subkeys share goodness)
При секретном ключе
Лемма 1 (The fraction of bad keys)
Пусть алгоритм
В крайнем случае, последнее равенство может выполниться для всех наборов
Аналогичные рассуждения приводят к тому, что наибольшее число плохих подключей
Оба подключа выбираются из
и доли плохих ключей в ключевом пространстве
что и требовалось доказать.
Определение
Пусть
Будем говорить, что пара
- подстановка
неотличима от истинной подстановки
- подстановка
Следующая лемма показывает, что все хорошие ключи являются, в некотором смысле, равными кандидатами на роль истинного ключа шифрования
Лемма 2 (Distribution of true key candidates)
Пусть
и подстановка
получаем, что искомая вероятность является условной вероятностью
Воспользуемся формулой Байеса:
Легко видеть, что доказательство леммы сводится к доказательству утверждения
Покажем, что для любого ключа
Очевидно, что, при фиксированной подстановке
Так, выражение для вероятности
Если при этом ключ
В этом случае искомая вероятность
Так, все вероятности в выражении для вероятности постоянны и не зависят от ключа
Теорема 2 (Boundary for success probability of any
где
Обозначим через
Обозначим через
Без ограничения общности можно предположить, что истинный ключ
Рассмотрим все возможные типы запросов, которые могут быть отправлены алгоритмом
- запрос к оракулу
:
Пусть
- пара
, в таком случае выработанные алгоритмом множества не изменятся, и ключ
- пара
, в таком случае имеют место следующие равенства:
- пара
Подсчитаем число ключей
Число
Учитывая полученные выше равенства для
По аналогичным соображениям, число плохих подключей
Тогда число
и искомая разность равна:
Вероятность того, что (случайно выбраный) ключ
- запрос к оракулу
По аналогии с запросом к оракулу
- запрос к оракулу
Пусть
- пара
, в таком случае выработанные алгоритмом множества не изменятся, и ключ
- пара
, в таком случае имеют место следующие равенства:
- пара
Подсчитаем число ключей
Число
Учитывая равенства для
По аналогичным соображениям, число плохих подключей
Тогда число
и искомая разность:
Вероятность того, что (случайно выбраный) ключ
- запрос к оракулу
.
По аналогии с запросом к оракулу
Делаем выводы:
Аналогично, ключ
В другом случае алгоритм
по истечении
Заметим, что значение подстановки
Тогда вероятность успеха
что и требовалось доказать.
Следствие 2.1
Пусть подстановка
Стойкость системы при использовании псевдослучайной подстановки
Предложенный в [EM97] шифр сохраняет показанное свойство криптостойкости и в том случае, если подстановка
Для доказательства этого утверждения достаточно пояснить понятие псевдослучайной подстановки.
Определение
Пусть
Другими словами, в представленной модели вычисления с оракулами, псевдослучайная подстановка неотличима от случайной. Поэтому имеет место следующая теорема.
Теорема 3
Пусть подстановка
В продолжение
Да, есть еще порох в пороховницах. Если на Хабре найдутся заинтересованные, то в следующей части могу рассмотреть модификации этой классической схемы, и различные криптографические атаки на нее (которые, кстати, показывают, что полученная оценка снизу точна, и не может быть улучшена).
Список литературы
Для тех, кто очень заинтересовался:
- Eli Biham, Yaniv Carmeli, Itai Dinur, Orr Dunkelman, Nathan Keller, and Adi Shamir. Cryptanalysis of iterated Even-Mansour schemes with two keys. IACR Cryptology ePrint Archive, 2013:674, 2013.
- Andrey Bogdanov, Lars R Knudsen, Gregor Leander, Francois-Xavier Standaert, John Steinberger, and Elmar Tischhauser. Key-alternating ciphers in a provable setting: Encryption using a small number of public permutations. In Advances in Cryptology–EUROCRYPT 2012, pages 45–62. Springer, 2012.
- Alex Biryukov and David Wagner. Advanced slide attacks. In Advances in Cryptology—EUROCRYPT 2000, pages 589–606. Springer, 2000.
- Shan Chen, Rodolphe Lampe, Jooyoung Lee, Yannick Seurin, and John Steinberger. Minimizing the two-round Even-Mansour cipher. In Advances in Cryptology–CRYPTO 2014, pages 39–56. Springer, 2014.
- Joan Daemen. Limitations of the Even-Mansour construction. In Advances in Cryptology—ASIACRYPT’91, pages 495–498. Springer, 1993.
- Itai Dinur, Orr Dunkelman, Nathan Keller, and Adi Shamir. Key recovery attacks on 3-round Even-Mansour, 8-step LED-128, and full AES2. In Advances in Cryptology-ASIACRYPT 2013, pages 337–356. Springer, 2013.
- Orr Dunkelman, Nathan Keller, and Adi Shamir. Minimalism in cryptography: The Even-Mansour scheme revisited. In Advances in Cryptology–EUROCRYPT 2012, pages 336–354. Springer, 2012.
- [EM97] Shimon Even and Yishay Mansour. A construction of a cipher from a single pseudorandom permutation. Journal of Cryptology, 10(3):151– 161, 1997.
- Shoni Gilboa and Shay Gueron. Balanced permutations even-mansour ciphers. arXiv preprint arXiv:1409.0421, 2014.
- Philip Hawkes and Luke O’Connor. Xor and non-xor differential probabilities. In Advances in Cryptology—EUROCRYPT’99, pages 272–285. Springer, 1999.
- Nicky Mouha and Atul Luykx. Multi-key security: The Even-Mansour construction revisited. Technical report, Cryptology ePrint Archive, Report 2015/101, 2015.
- Ivica Nikolic, Lei Wang, and Shuang Wu. Cryptanalysis of round-reduced LED. In Shiho Moriai, editor, Fast Software Encryption, volume 8424 of Lecture Notes in Computer Science, pages 112–129. Springer Berlin Heidelberg, 2014.
P.S. Часть этой публикации была сверстана в TeX, при верстке на Хабре могли появиться косяки, в основном в формулах. Если заметите — обращайтесь, исправлю.
EDIT 1. Исправил имена ученых, спасибо alexyr.
Комментарии (21)

hellman
28.08.2015 13:58А где-нибудь 1-раундовый Even-Mansour все-таки используется? Я слышал только про Chaskey MAC.

aaprelev
28.08.2015 15:24+1Честно отвечу, что классическая конструкция Even–Mansour (единственная итерация, и в качестве операции смешивания используется
), — чисто теоретический результат.
Эта конструкция часто используется в качестве одного из раундов большого количества более сложных шифров, в том числе в LED и AES (Rijndael).
MichaelBorisov
29.08.2015 12:05Я думаю, что увеличение количества раундов — это компенсация слабости функции подстановки, которая, хоть и сложна, но все же не является истинно случайной или доказуемо неотличимой от таковой.
Если иметь стойкую функцию подстановки (не хуже, чем случайную подстановку) — то думаю, вполне достаточно и одного раунда.
soniq
28.08.2015 22:51Остался вопрос, какая подстановка хорошая, а какая не очень
soniq
28.08.2015 22:53+1Я так понял, доказательство стойкости шифра свели к доказательству «хорошести» подстановки, про которую ничего не известно.
aaprelev
29.08.2015 00:01+1soniq, невнимательно читали) Стойкость шифра доказана для тех случаев, в которых
- подстановка
(читайте, является истинно случайной биекцией множества в себя), либо
- подстановка
Шифр считаем стойким, если вероятность осуществить успешную атаку за полиномиальное время полиномиально мала (извините за каламбур):
soniq
29.08.2015 08:47Ах, security by obscurity, оракула же украдут за О(1).
aaprelev
29.08.2015 09:57+1Не очень понимаю, что имеете в виду под кражей оракула)
Дело в том, что подстановка доступна всем, она не является частью секретного ключа. Даже если в качестве
Никакой неясности в схеме нет, все прозрачно для злоумышленника. Есть четыре оракула, к которым он может обращаться, все оракулы для него — черные ящики. Схема шифра ему тоже известна, неизвестен только ключ шифрования.MichaelBorisov
29.08.2015 12:09ведь убедиться, что подстановка действительно тождественна, имея только оракула
А почему, собственно, мы имеем только оракула? Я считаю, что злоумышленнику доступен не только оракул для функции подстановки, но и полное математическое описание этой функции, т.е. таблица либо формула.
Ведь для применяемых на практике шифров (AES и т.д.) функция подстановки (со всеми ее потрохами) является публичной, секретен только ключ.aaprelev
29.08.2015 13:17А почему, собственно, мы имеем только оракула?
Такая модель вычисления предложена авторами, и только в рамках этой модели стойкость шифра доказана.
Я считаю, что злоумышленнику доступен не только оракул для функции подстановки, но и полное математическое описание этой функции, т.е. таблица либо формула.
Если подстановка случайная, то никакого математического (алгоритмического) описания у нее нет, а что касается таблицы замены — таблица вычислительно эквивалентна оракулу относительно временной сложности атаки, только занимает в памятибит, что совершенно неудобно.
Если же подстановка псевдослучайна (например, задана суперпозицией преобразований, как в современных шифрах), то, даже если злоумышленнику известно ее устройство, это все равно ему не поможет, потому что иначе эта подстановка не была бы псевдослучайной согласно определению авторов. Другими словами, если существует полиномиальная атака на этот шифр, использующая особенности устройства выбранной подстановки, то такая подстановка не является псевдослучайной.
Приведу пример: если злоумышленнику заранее известно, что подстановка является инволюцией (обратна сама себе), то шифр уже не является стойким.
MichaelBorisov
29.08.2015 12:04В принципе, даже это большой прогресс по отношению к одноразовому блокноту, где длина случайного блока данных должна быть равна длине шифруемого текста, и повторное использование ключа невозможно.
Для случайных подстановок длиной 32 бита уже можно реализовать шифрование на современной элементной базе. Интересно, не дает ли малая длина блока в 32 бит каких-то специфических слабостей шифра сама по себе?
Большое спасибо за статью, жду продолжения, тема очень интересна!
icoz
29.08.2015 12:46Либо я что-то недопонял, либо на текст длиной n символов нужен будет ключ длиной 2n символов. Это прорыв от одноразового блокнота! Здесь нужно в два раза больше ключей.
aaprelev
29.08.2015 13:26+1MichaelBorisov Я бы не стал сравнивать криптостойкость одноразового блокнота со стойкостью предложенной схемы, а дело вот в чем:
- Одноразовый блокнот является абсолютно криптостойким (по Шеннону), это означает, что, даже имея неограниченные ресурсы (память, и время), Вам не удасться дешифровать шифртекст. Такая криптостойкость безотносительна, она не зависит ни от ресурсов злоумышленника, ни от величины параметра
- Схема Even–Mansour гарантирует лишь стойкость от любых полиномиальных атак. При отсутствии ограничений по времени выполнения атаки, либо по памяти, доступной атакующему, шифр легко ломается. Конкретнее об этом расскажу тогда в следующей публикации.
Обобщая вышесказанное: при одних и тех же условиях (неограниченные ресурсы) одноразовый блокнот стоек, а схема Even–Mansour легко вскрывается.MichaelBorisov
29.08.2015 14:03Поскольку схема Even-Mansour (поправьте меня, если ошибаюсь) является наиболее общим выражением концепции «блочный шифр» — то получается, что нельзя в принципе создать невзламываемых (эквивалентно концепции «одноразового блокнота») блочных шифров?
А что если применить не конкретно схему Even-Mansour, а более общую схему — ключезависимую подстановку на блоке? Например, чтобы подстановка была истинно случайной и сама являлась ключом? Сводится ли такая схема к Even-Mansour? Если нет — то ломается ли она теми же методами, что Even-Mansour?
- Одноразовый блокнот является абсолютно криптостойким (по Шеннону), это означает, что, даже имея неограниченные ресурсы (память, и время), Вам не удасться дешифровать шифртекст. Такая криптостойкость безотносительна, она не зависит ни от ресурсов злоумышленника, ни от величины параметра
aaprelev
29.08.2015 13:42+132 бита — это просто смешно, а не криптостойкость (с, А. Е. Жуков). Любой сможет взломать такой шифр на домашнем компьютере. Приемлимой длиной ключа сейчас считается 128 бит (поправьте меня, если ошибаюсь). Проблема практического применения этой схемы в том и заключается, что подстановки на таких больших множествах
хрен задашьзанимают много места в памяти.MichaelBorisov
29.08.2015 14:08Длина блока и длина ключа — это разные вещи. Например, AES имеет длину блока 128 бит, а длина ключа может составлять 128, 192 или 256 бит. То же касается шифра ГОСТ: блок длиной 64 бит, ключ — 256 бит. Я спрашивал о том, дает ли малая длина блока (в частности, 32 бит) преимущества взломщику? Ключ при этом может иметь длину вплоть до 32*2^32 бит (если это будет истинно случайная таблица подстановки).
aaprelev
29.08.2015 20:19+1Нет, про 32 бита — это я в ответ на Ваш пост писал:
В принципе, даже это большой прогресс по отношению к одноразовому блокноту, где длина случайного блока данных должна быть равна длине шифруемого текста, и повторное использование ключа невозможно.
Для случайных подстановок длиной 32 бита уже можно реализовать шифрование на современной элементной базе. Интересно, не дает ли малая длина блока в 32 бит каких-то специфических слабостей шифра сама по себе?
А в схеме Even-Mansour длина блока совпадает с фактической длиной ключа.
А что если применить не конкретно схему Even-Mansour, а более общую схему — ключезависимую подстановку на блоке? Например, чтобы подстановка была истинно случайной и сама являлась ключом? Сводится ли такая схема к Even-Mansour? Если нет — то ломается ли она теми же методами, что Even-Mansour?
Вот как раз такой шифр — в котором каждому ключу соответствует своя истинно случайная подстановка на алфавите блоков — и называется идеальным шифром (не смогу сейчас по памяти сказать, кто ввел такое определение). Суть заключается в том, что именно таким должен быть идеальный шифр, да и был бы, если бы не проблема нехватки памяти. Можно ли атаковать такую криптосистему? Несомненно, с помощью общих методов криптоанализа. Но ни один из них существенно полный перебор не сократит.MichaelBorisov
30.08.2015 11:34Ясно, спасибо. Действительно, похоже, Even-Mansour к «идеальному блочному шифру» скорее всего не сводится. Но зато он значительно проще и имеет доказанную криптостойкость. Жду продолжения ваших статей о шифрах!
- подстановка
hellman
К недостаткам логично отнести то что ключ 2n бит даёт стойкость всего n бит. За 2^n ломается очевидным mitm'ом. Соответственно, логично либо использовать один и тот же ключ два раза, либо использовать KDF (чтобы получить из одного ключа два). Есть ли у этих способов слабости, или, наоборот, доказательства стойкости?
aaprelev
Мог бы раскрыть интригу в следующей публикации, но поскольку желающих нет, а вопрос есть, отвечу: да, действительно, стойкость в n бит. И да, есть модификация этой схемы, в которой подключи совпадают: . Показано, что криптографическая стойкость схемы при этом существенно не меняется.
. Показано, что криптографическая стойкость схемы при этом существенно не меняется.
Что касается алгоритма выработки подключей (KDF), то им, конечно, можно пользоваться, но в рассмотренной авторами вычислительной модели подключи все равно будут считаться независимыми (а хороший алгоритм выработки ключей к этому и стремится).