
Прим. перев.: адаптацию Kubernetes в GitLab считают одним из двух главных факторов, способствующих росту компании. Тем не менее, до недавнего времени инфраструктура онлайн-сервиса GitLab.com была построена на виртуальных машинах, и только около года назад началась её миграция в K8s, которая до сих пор не завершена. Рады представить перевод недавней статьи SRE-инженера GitLab о том, как это происходит и какие выводы делают инженеры, участвующие в проекте.
Вот уже около года наше инфраструктурное подразделение занимается миграцией всех сервисов, работающих на GitLab.com, в Kubernetes. За это время мы столкнулись с проблемами, связанными не только с перемещением сервисов в Kubernetes, но и с управлением гибридным deployment'ом во время перехода. О ценных уроках, полученных нами, и пойдет речь в этой статье.
С самого начала GitLab.com его серверы работали в облаке на виртуальных машинах. Этими виртуальными машинами управляет Chef, а их установка происходит с помощью нашего официального Linux-пакета. Стратегия развертывания на случай, если нужно обновить приложение, состоит в простом обновлении парка серверов скоординированным последовательным образом с помощью CI-пайплайна. Этот метод — пусть медленный и чуточку скучный — гарантирует, что GitLab.com применяет те же способы установки и конфигурирования, что и пользователи автономных (self-managed) инсталляций GitLab, применяющие для этого наши Linux-пакеты.
Мы используем такой метод, поскольку исключительно важно ощутить на себе все печали и радости, которые испытывают рядовые представители сообщества, когда устанавливают и настраивают свои копии GitLab. Этот подход хорошо работал в течение некоторого времени, однако когда число проектов на GitLab перевалило за 10 млн, мы поняли, что он больше не удовлетворяет нашим потребностям в масштабировании и развертывании.
В 2017-м был создан проект GitLab Charts для подготовки GitLab к развертыванию в облаке, а также для того, чтобы дать пользователям возможность устанавливать GitLab в кластеры Kubernetes. Тогда мы знали, что перенос GitLab в Kubernetes увеличит возможности масштабирования SaaS-платформы, упростит развертывания и повысит эффективность использования вычислительных ресурсов. В то же время многие функции нашего приложения зависели от примонтированных NFS-разделов, что замедляло переход с виртуальных машин.
Стремление к cloud native и Kubernetes позволило нашим инженерам планировать постепенный переход, в ходе которого мы отказались от некоторых зависимостей приложения от сетевых хранилищ, попутно продолжая разрабатывать новые функции. С тех пор, как мы начали планировать миграцию летом 2019-го, многие из этих ограничений были устранены, и процесс перевода GitLab.com на Kubernetes теперь идет полным ходом!
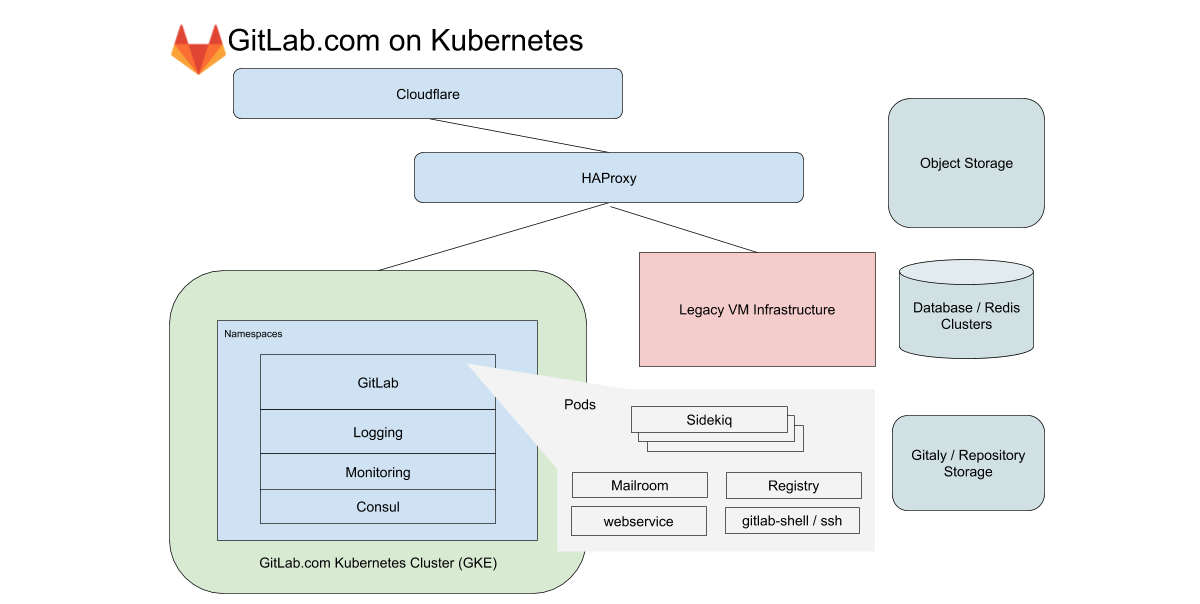
Для GitLab.com мы используем единый региональный кластер GKE, обрабатывающий весь трафик приложения. Чтобы минимизировать сложность (без того мудреной) миграции, мы концентрируемся на сервисах, которые не зависят от локального хранилища или NFS. GitLab.com использует преимущественно монолитную кодовую базу на Rails, и мы направляем трафик в зависимости от характеристик рабочей нагрузки на различные endpoint'ы, изолированные в свои собственные пулы узлов.
В случае фронтенда эти типы делятся на запросы к web, API, Git SSH/HTTPS и Registry. В случае бэкенда мы разбиваем job'ы в очереди по различным характеристикам в зависимости от предопределенных границ ресурсов, которые позволяют нам устанавливать целевые показатели уровня обслуживания (Service-Level Objectives, SLOs) для различных нагрузок.
Все эти сервисы GitLab.com настроены с помощью немодифицированного Helm-чарта GitLab. Конфигурация проводится в субчартах, которые могут быть выборочно включены по мере того, как мы постепенно переносим сервисы в кластер. Даже с учетом того, что было решено не включать в миграцию некоторые из наших stateful-сервисов, такие как Redis, Postgres, GitLab Pages и Gitaly, использование Kubernetes позволяет радикально сократить число VM, которыми управляет Chef в настоящее время.
Все настройки управляются самим GitLab'ом. Для этого используются три конфигурационных проекта на основе Terraform и Helm. Мы стараемся везде по возможности использовать сам GitLab для запуска GitLab'а, но для эксплуатационных задач у нас функционирует отдельная инсталляция GitLab. Она нужна для того, чтобы не зависеть от доступности GitLab.com при проведении развертываний и обновлений GitLab.com.
Хотя наши пайплайны для кластера Kubernetes работают на отдельной инсталляции GitLab, есть у репозиториев кода есть зеркала, публично доступные по следующим адресам:

При внесении изменений показывается общедоступное краткое резюме со ссылкой на подробный diff, который SRE анализирует перед внесением изменений в кластер.
Для SRE ссылка ведет на подробный diff в инсталляции GitLab, которая используется для эксплуатации и доступ к которой ограничен. Это позволяет сотрудникам и сообществу без доступа к эксплуатационному проекту (он открыт только для SRE) просматривать предлагаемые изменения в конфигурации. Сочетая общедоступный экземпляр GitLab'а для кода с закрытым экземпляром для CI-пайплайнов, мы сохраняем единый рабочий процесс, в то же время гарантируя независимость от GitLab.com при обновлениях конфигурации.
В процессе переезда был накоплен опыт, который мы применяем к новым миграциям и deployment’ам в Kubernetes.

Ежедневная egress-статистика (байт в сутки) по парку Git-хранилищ на GitLab.com
Google делит свою сеть на регионы. Те, в свою очередь, разбиваются на зоны доступности (AZ). Git-хостинг связан с большими объемами данных, поэтому нам важно контролировать сетевой egress. В случае внутреннего трафика egress бесплатен только в том случае, если он остается в границах одной зоны доступности. На момент написания этой статьи мы отдаем примерно 100 Тб данных в обычный рабочий день (и это только для Git-репозиториев). Сервисы, которые в нашей старой топологии, основанной на VM, находились на одних и тех же виртуальных машинах, теперь работают в разных pod'ах Kubernetes. Это означает, что некоторая часть трафика, которая раньше была локальной для VM, может потенциально выходить за пределы зон доступности.
Региональные кластеры GKE позволяют охватывать несколько зон доступности для резервирования. Мы рассматриваем возможность разделить региональный кластер GKE на однозонные кластеры для сервисов, которые генерируют большие объемы трафика. Это позволит сократить расходы на egress при сохранении резервирования на уровне кластера.

Число реплик, обрабатывающих production-трафик на registry.gitlab.com. Трафик достигает своего пика в ~15:00 UTC.
Наша история с миграцией началась в августе 2019-го, когда мы перенесли первый сервис — реестр контейнеров GitLab (GitLab Container Registry) — в Kubernetes. Этот критически важный сервис с высоким трафиком хорошо подошел для первой миграции, поскольку представляет собой stateless-приложение с малым числом внешних зависимостей. Первой проблемой, с которой мы столкнулись, стало большое число вытесненных pod'ов из-за нехватки памяти на узлах. Из-за этого нам пришлось менять request'ы и limit'ы.
Было обнаружено, что в случае приложения, у которого потребление памяти растет со временем, низкие значения для request'ов (резервирующих память для каждого pod'а) вкупе с «щедрым» жестким limit'ом на использование приводили к насыщению (saturation) узлов и высокому уровню вытеснений. Чтобы справиться с этой проблемой, было решено увеличить request'ы и снизить limit'ы. Это сняло давление с узлов и обеспечило жизненный цикл pod'ов, который не оказывал слишком высокого давления на узел. Теперь мы начинаем миграции с щедрыми (и почти одинаковыми) значениями request'ов и limit'ов, корректируя их по необходимости.

Инфраструктурное подразделение фокусируется на задержках, проценте ошибок и сатурации с установленными целями по уровню обслуживания (SLO), привязанными к общей доступности нашей системы.
За прошедший год одним из ключевых событий в инфраструктурном подразделении стали улучшения в мониторинге и работе с SLO. SLO позволили нам устанавливать цели по отдельным сервисам, за которыми мы пристально следили во время миграции. Но даже с такой улучшенной наблюдаемостью не всегда можно сразу увидеть проблемы, используя метрики и алерты. Например, сосредоточившись на задержках и проценте ошибок, мы не полностью охватываем все сценарии использования сервиса, проходящего миграцию.
Эта проблема была обнаружена почти сразу после переноса части рабочих нагрузок в кластер. Особенно остро она заявила о себе, когда пришлось проверять функции, число запросов к которым невелико, но у которых очень специфические конфигурационные зависимости. Одним из ключевых уроков по итогам миграции стала необходимость учитывать при мониторинге не только метрики, но также логи и «длинный хвост» (речь идёт о таком их распределении на графике — прим. перев.) ошибок. Теперь для каждой миграции мы включаем детальный список запросов к логам (log queries) и планируем четкие процедуры отката, которые в случае возникновения проблем можно передавать от одной смены к другой.
Параллельное обслуживание одних и тех же запросов на старой VM-инфраструктуре и новой, основанной на Kubernetes, представляло собой уникальную задачу. В отличие от миграции типа lift-and-shift (быстрый перенос приложений «как есть» в новую инфраструктуру; подробнее можно прочитать, например, здесь — прим. перев.), параллельная работа на «старых» VM и Kubernetes требует, чтобы инструменты для мониторинга были совместимы с обеими средами и умели объединять метрики в один вид. Важно, что мы используем одни и те же dashboard’ы и запросы к логам, чтобы добиться согласованной наблюдаемости во время переходного периода.
Для GitLab.com часть серверов выделяется под канареечную (canary) стадию. Канареечный парк обслуживает наши внутренние проекты, а также может включаться пользователями. Но в первую очередь он предназначен для проверки изменений, вносимых в инфраструктуру и приложение. Первый перенесенный сервис начал с приема ограниченного объема внутреннего трафика, и мы продолжаем использовать этот метод, чтобы убедиться в соблюдении SLO перед тем, как направить весь трафик в кластер.
В случае миграции это означает, что сначала в Kubernetes направляются запросы к внутренним проектам, а затем мы постепенно переключаем на кластер остальной трафик путем изменения веса для бэкенда через HAProxy. В процессе перехода с VM на Kubernetes стало понятно, что очень выгодно иметь в запасе простой способ перенаправления трафика между старой и новой инфраструктурой и, соответственно, держать старую инфраструктуру наготове для отката в первые несколько дней после миграции.
Почти сразу была выявлена следующая проблема: pod'ы для сервиса Registry стартовали быстро, однако запуск pod'ов для Sidekiq занимал до двух минут. Продолжительный запуск pod'ов для Sidekiq стал проблемой, когда мы приступили к миграции в Kubernetes рабочих нагрузок для worker'ов, которым нужно быстро обрабатывать job'ы и быстро масштабироваться.
В данном случае урок заключался в том, что, хотя Horizontal Pod Autoscaler (HPA) в Kubernetes хорошо справляется с ростом трафика, важно принимать во внимание характеристики рабочих нагрузок и выделять резервные мощности pod'ов (особенно в условиях неравномерного распределения спроса). В нашем случае наблюдался внезапный всплеск job'ов, влекущий за собой стремительное масштабирование, что приводило к насыщению ресурсов CPU до того, как мы успевали масштабировать пул узлов.
Всегда есть соблазн как можно больше «выжать» из кластера, однако мы, изначально столкнувшись с проблемами с производительностью, теперь начинаем с щедрого pod budget'а и уменьшаем его впоследствии, пристально следя за SLO. Запуск pod'ов для сервиса Sidekiq значительно ускорился и теперь в среднем занимает около 40 секунд. От сокращения времени запуска pod'ов выиграл как GitLab.com, так и наши пользователи инсталляций self-managed, работающие с официальным Helm-чартом GitLab.
После переноса каждого сервиса мы радовались преимуществам использования Kubernetes в production: более быстрому и безопасному деплою приложения, масштабированию и более эффективному распределению ресурсов. Причем плюсы миграции выходят за рамки сервиса GitLab.com. От каждого улучшения официального Helm-чарта выигрывают и его пользователи.
Надеюсь, вам понравилась история о наших приключениях с миграцией в Kubernetes. Мы продолжаем переносить все новые сервисы в кластер. Дополнительную информацию можно почерпнуть из следующих публикаций:
Читайте также в нашем блоге:
Вот уже около года наше инфраструктурное подразделение занимается миграцией всех сервисов, работающих на GitLab.com, в Kubernetes. За это время мы столкнулись с проблемами, связанными не только с перемещением сервисов в Kubernetes, но и с управлением гибридным deployment'ом во время перехода. О ценных уроках, полученных нами, и пойдет речь в этой статье.
С самого начала GitLab.com его серверы работали в облаке на виртуальных машинах. Этими виртуальными машинами управляет Chef, а их установка происходит с помощью нашего официального Linux-пакета. Стратегия развертывания на случай, если нужно обновить приложение, состоит в простом обновлении парка серверов скоординированным последовательным образом с помощью CI-пайплайна. Этот метод — пусть медленный и чуточку скучный — гарантирует, что GitLab.com применяет те же способы установки и конфигурирования, что и пользователи автономных (self-managed) инсталляций GitLab, применяющие для этого наши Linux-пакеты.
Мы используем такой метод, поскольку исключительно важно ощутить на себе все печали и радости, которые испытывают рядовые представители сообщества, когда устанавливают и настраивают свои копии GitLab. Этот подход хорошо работал в течение некоторого времени, однако когда число проектов на GitLab перевалило за 10 млн, мы поняли, что он больше не удовлетворяет нашим потребностям в масштабировании и развертывании.
Первые шаги к Kubernetes и cloud-native GitLab
В 2017-м был создан проект GitLab Charts для подготовки GitLab к развертыванию в облаке, а также для того, чтобы дать пользователям возможность устанавливать GitLab в кластеры Kubernetes. Тогда мы знали, что перенос GitLab в Kubernetes увеличит возможности масштабирования SaaS-платформы, упростит развертывания и повысит эффективность использования вычислительных ресурсов. В то же время многие функции нашего приложения зависели от примонтированных NFS-разделов, что замедляло переход с виртуальных машин.
Стремление к cloud native и Kubernetes позволило нашим инженерам планировать постепенный переход, в ходе которого мы отказались от некоторых зависимостей приложения от сетевых хранилищ, попутно продолжая разрабатывать новые функции. С тех пор, как мы начали планировать миграцию летом 2019-го, многие из этих ограничений были устранены, и процесс перевода GitLab.com на Kubernetes теперь идет полным ходом!
Особенности работы GitLab.com в Kubernetes
Для GitLab.com мы используем единый региональный кластер GKE, обрабатывающий весь трафик приложения. Чтобы минимизировать сложность (без того мудреной) миграции, мы концентрируемся на сервисах, которые не зависят от локального хранилища или NFS. GitLab.com использует преимущественно монолитную кодовую базу на Rails, и мы направляем трафик в зависимости от характеристик рабочей нагрузки на различные endpoint'ы, изолированные в свои собственные пулы узлов.
В случае фронтенда эти типы делятся на запросы к web, API, Git SSH/HTTPS и Registry. В случае бэкенда мы разбиваем job'ы в очереди по различным характеристикам в зависимости от предопределенных границ ресурсов, которые позволяют нам устанавливать целевые показатели уровня обслуживания (Service-Level Objectives, SLOs) для различных нагрузок.
Все эти сервисы GitLab.com настроены с помощью немодифицированного Helm-чарта GitLab. Конфигурация проводится в субчартах, которые могут быть выборочно включены по мере того, как мы постепенно переносим сервисы в кластер. Даже с учетом того, что было решено не включать в миграцию некоторые из наших stateful-сервисов, такие как Redis, Postgres, GitLab Pages и Gitaly, использование Kubernetes позволяет радикально сократить число VM, которыми управляет Chef в настоящее время.
Прозрачность и управление конфигурацией Kubernetes
Все настройки управляются самим GitLab'ом. Для этого используются три конфигурационных проекта на основе Terraform и Helm. Мы стараемся везде по возможности использовать сам GitLab для запуска GitLab'а, но для эксплуатационных задач у нас функционирует отдельная инсталляция GitLab. Она нужна для того, чтобы не зависеть от доступности GitLab.com при проведении развертываний и обновлений GitLab.com.
Хотя наши пайплайны для кластера Kubernetes работают на отдельной инсталляции GitLab, есть у репозиториев кода есть зеркала, публично доступные по следующим адресам:
- k8s-workloads/gitlab-com — конфигурационная обвязка GitLab.com для Helm-чарта GitLab;
- k8s-workloads/gitlab-helmfiles — содержит конфигурации для сервисов, которые не связаны с приложением GitLab непосредственно. В их число входят конфигурации для ведения логов и мониторинга кластера, а также для интегрированных инструментов вроде PlantUML;
- Gitlab-com-infrastructure — конфигурация Terraform для Kubernetes и старой (legacy) VM-инфраструктуры. Здесь настраиваются все ресурсы, необходимые для запуска кластера, включая сам кластер, пулы узлов, учетные записи служб, резервирование IP-адресов.
При внесении изменений показывается общедоступное краткое резюме со ссылкой на подробный diff, который SRE анализирует перед внесением изменений в кластер.
Для SRE ссылка ведет на подробный diff в инсталляции GitLab, которая используется для эксплуатации и доступ к которой ограничен. Это позволяет сотрудникам и сообществу без доступа к эксплуатационному проекту (он открыт только для SRE) просматривать предлагаемые изменения в конфигурации. Сочетая общедоступный экземпляр GitLab'а для кода с закрытым экземпляром для CI-пайплайнов, мы сохраняем единый рабочий процесс, в то же время гарантируя независимость от GitLab.com при обновлениях конфигурации.
Что мы выяснили за время миграции
В процессе переезда был накоплен опыт, который мы применяем к новым миграциям и deployment’ам в Kubernetes.
1. Рост расходов из-за трафика между зонами доступности
Ежедневная egress-статистика (байт в сутки) по парку Git-хранилищ на GitLab.com
Google делит свою сеть на регионы. Те, в свою очередь, разбиваются на зоны доступности (AZ). Git-хостинг связан с большими объемами данных, поэтому нам важно контролировать сетевой egress. В случае внутреннего трафика egress бесплатен только в том случае, если он остается в границах одной зоны доступности. На момент написания этой статьи мы отдаем примерно 100 Тб данных в обычный рабочий день (и это только для Git-репозиториев). Сервисы, которые в нашей старой топологии, основанной на VM, находились на одних и тех же виртуальных машинах, теперь работают в разных pod'ах Kubernetes. Это означает, что некоторая часть трафика, которая раньше была локальной для VM, может потенциально выходить за пределы зон доступности.
Региональные кластеры GKE позволяют охватывать несколько зон доступности для резервирования. Мы рассматриваем возможность разделить региональный кластер GKE на однозонные кластеры для сервисов, которые генерируют большие объемы трафика. Это позволит сократить расходы на egress при сохранении резервирования на уровне кластера.
2. Limit'ы, request'ы ресурсов и масштабирование
Число реплик, обрабатывающих production-трафик на registry.gitlab.com. Трафик достигает своего пика в ~15:00 UTC.
Наша история с миграцией началась в августе 2019-го, когда мы перенесли первый сервис — реестр контейнеров GitLab (GitLab Container Registry) — в Kubernetes. Этот критически важный сервис с высоким трафиком хорошо подошел для первой миграции, поскольку представляет собой stateless-приложение с малым числом внешних зависимостей. Первой проблемой, с которой мы столкнулись, стало большое число вытесненных pod'ов из-за нехватки памяти на узлах. Из-за этого нам пришлось менять request'ы и limit'ы.
Было обнаружено, что в случае приложения, у которого потребление памяти растет со временем, низкие значения для request'ов (резервирующих память для каждого pod'а) вкупе с «щедрым» жестким limit'ом на использование приводили к насыщению (saturation) узлов и высокому уровню вытеснений. Чтобы справиться с этой проблемой, было решено увеличить request'ы и снизить limit'ы. Это сняло давление с узлов и обеспечило жизненный цикл pod'ов, который не оказывал слишком высокого давления на узел. Теперь мы начинаем миграции с щедрыми (и почти одинаковыми) значениями request'ов и limit'ов, корректируя их по необходимости.
3. Метрики и логи
Инфраструктурное подразделение фокусируется на задержках, проценте ошибок и сатурации с установленными целями по уровню обслуживания (SLO), привязанными к общей доступности нашей системы.
За прошедший год одним из ключевых событий в инфраструктурном подразделении стали улучшения в мониторинге и работе с SLO. SLO позволили нам устанавливать цели по отдельным сервисам, за которыми мы пристально следили во время миграции. Но даже с такой улучшенной наблюдаемостью не всегда можно сразу увидеть проблемы, используя метрики и алерты. Например, сосредоточившись на задержках и проценте ошибок, мы не полностью охватываем все сценарии использования сервиса, проходящего миграцию.
Эта проблема была обнаружена почти сразу после переноса части рабочих нагрузок в кластер. Особенно остро она заявила о себе, когда пришлось проверять функции, число запросов к которым невелико, но у которых очень специфические конфигурационные зависимости. Одним из ключевых уроков по итогам миграции стала необходимость учитывать при мониторинге не только метрики, но также логи и «длинный хвост» (речь идёт о таком их распределении на графике — прим. перев.) ошибок. Теперь для каждой миграции мы включаем детальный список запросов к логам (log queries) и планируем четкие процедуры отката, которые в случае возникновения проблем можно передавать от одной смены к другой.
Параллельное обслуживание одних и тех же запросов на старой VM-инфраструктуре и новой, основанной на Kubernetes, представляло собой уникальную задачу. В отличие от миграции типа lift-and-shift (быстрый перенос приложений «как есть» в новую инфраструктуру; подробнее можно прочитать, например, здесь — прим. перев.), параллельная работа на «старых» VM и Kubernetes требует, чтобы инструменты для мониторинга были совместимы с обеими средами и умели объединять метрики в один вид. Важно, что мы используем одни и те же dashboard’ы и запросы к логам, чтобы добиться согласованной наблюдаемости во время переходного периода.
4. Переключение трафика на новый кластер
Для GitLab.com часть серверов выделяется под канареечную (canary) стадию. Канареечный парк обслуживает наши внутренние проекты, а также может включаться пользователями. Но в первую очередь он предназначен для проверки изменений, вносимых в инфраструктуру и приложение. Первый перенесенный сервис начал с приема ограниченного объема внутреннего трафика, и мы продолжаем использовать этот метод, чтобы убедиться в соблюдении SLO перед тем, как направить весь трафик в кластер.
В случае миграции это означает, что сначала в Kubernetes направляются запросы к внутренним проектам, а затем мы постепенно переключаем на кластер остальной трафик путем изменения веса для бэкенда через HAProxy. В процессе перехода с VM на Kubernetes стало понятно, что очень выгодно иметь в запасе простой способ перенаправления трафика между старой и новой инфраструктурой и, соответственно, держать старую инфраструктуру наготове для отката в первые несколько дней после миграции.
5. Резервные мощности pod'ов и их использование
Почти сразу была выявлена следующая проблема: pod'ы для сервиса Registry стартовали быстро, однако запуск pod'ов для Sidekiq занимал до двух минут. Продолжительный запуск pod'ов для Sidekiq стал проблемой, когда мы приступили к миграции в Kubernetes рабочих нагрузок для worker'ов, которым нужно быстро обрабатывать job'ы и быстро масштабироваться.
В данном случае урок заключался в том, что, хотя Horizontal Pod Autoscaler (HPA) в Kubernetes хорошо справляется с ростом трафика, важно принимать во внимание характеристики рабочих нагрузок и выделять резервные мощности pod'ов (особенно в условиях неравномерного распределения спроса). В нашем случае наблюдался внезапный всплеск job'ов, влекущий за собой стремительное масштабирование, что приводило к насыщению ресурсов CPU до того, как мы успевали масштабировать пул узлов.
Всегда есть соблазн как можно больше «выжать» из кластера, однако мы, изначально столкнувшись с проблемами с производительностью, теперь начинаем с щедрого pod budget'а и уменьшаем его впоследствии, пристально следя за SLO. Запуск pod'ов для сервиса Sidekiq значительно ускорился и теперь в среднем занимает около 40 секунд. От сокращения времени запуска pod'ов выиграл как GitLab.com, так и наши пользователи инсталляций self-managed, работающие с официальным Helm-чартом GitLab.
Заключение
После переноса каждого сервиса мы радовались преимуществам использования Kubernetes в production: более быстрому и безопасному деплою приложения, масштабированию и более эффективному распределению ресурсов. Причем плюсы миграции выходят за рамки сервиса GitLab.com. От каждого улучшения официального Helm-чарта выигрывают и его пользователи.
Надеюсь, вам понравилась история о наших приключениях с миграцией в Kubernetes. Мы продолжаем переносить все новые сервисы в кластер. Дополнительную информацию можно почерпнуть из следующих публикаций:
- «Why are we migrating to Kubernetes?»;
- «GitLab.com on Kubernetes»;
- Epic по миграции GitLab.com на Kubernetes.
P.S. от переводчика
Читайте также в нашем блоге: