
Представим, что вам нужно настроить мониторинг распределённой базы данных, такой как GridGain. Метрики положим в Prometheus. Графики нарисуем в Grafana. Про систему оповещения не забудем – для этого настроим Zabbix. Для анализа трейсов воспользуемся Jaeger. Для управления состоянием и CLI хорош. А для SQL запросов воспользуемся бесплатным JDBC клиентом вроде DBeaver.
Теперь настраиваем для каждого из инструментов систему аутентификации, чтобы никакая информация не просочилась, и мы у цели. В итоге получили связку инструментов, которая сложнее самой распределённой системы, ради которой всё затевалось.
А теперь наймем для поддержки и настройки всего этого зверинца команду специалистов и будем жить долго и счастливо. Или нет, потому что столько ресурсов мы на эту задачу просто не получим. Придется искать способы удешевить обслуживание. В GridGain моя команда для этого написала собственный инструмент, закрывающий все потребности распределенной In-Memory платформы Apache Ignite или ее корпоративной версии GridGain.
Control Center умеет работать с GridGain начиная с версии 8.7.23 любой редакции, а также с Apache Ignite версии не младше 2.8.1.
Что умеет наш велосипед (и почему нам не подошли готовые)
Control Center предоставляет единый интерфейс, интегрированный и разработанный специально для GridGain и максимально учитывающий его особенности. Методы визуализации подобраны под данные, поступающие из кластера. Управлять состоянием узлов, делать снимки данных, запускать SQL можно прямо из пользовательского интерфейса. Если что-то настроено неправильно, то сообщения об ошибках подскажут, какие шаги нужно предпринять.
Инструменты общего назначения, такие как Grafana, Prometheus, Zabbix и прочие, потребуют от вас долгих часов и дней чтения документации и испытания разных методов интеграции. Это гораздо более сложный путь, требующий терпения. При этом недостаточно разобраться лишь в одном продукте – для реализации тех же возможностей нужно уметь пользоваться целой коллекцией инструментов. Даже при идеальной настройке эти инструменты не будут согласованы между собой, а команды управления придётся по-прежнему выполнять в терминале.
Давайте взглянем подробнее на то, с чем Control Center хорошо справляется.
Настройка
Перед командой разработки Control Center стояла задача сделать настройку кластера для мониторинга максимально простой. Для старта нужно скопировать модуль control-center-agent из директории libs/optional в libs в дистрибутиве GridGain. После старта узла в логах можно будет найти ссылку, пройдя по которой, вы попадёте на экран мониторинга на сайте control.gridgain.com. На этом настройка завершена.
Также Control Center можно запустить в собственном окружении и настроить кластер для мониторинга через него при помощи команды bin/management.sh --uri <URI>.
Для Apache Ignite первый шаг процедуры несколько отличается, так как агент не поставляется в дистрибутиве, но его можно скачать на сайте GridGain.
Процесс настройки подробно описан в документации.
Отображение метрик
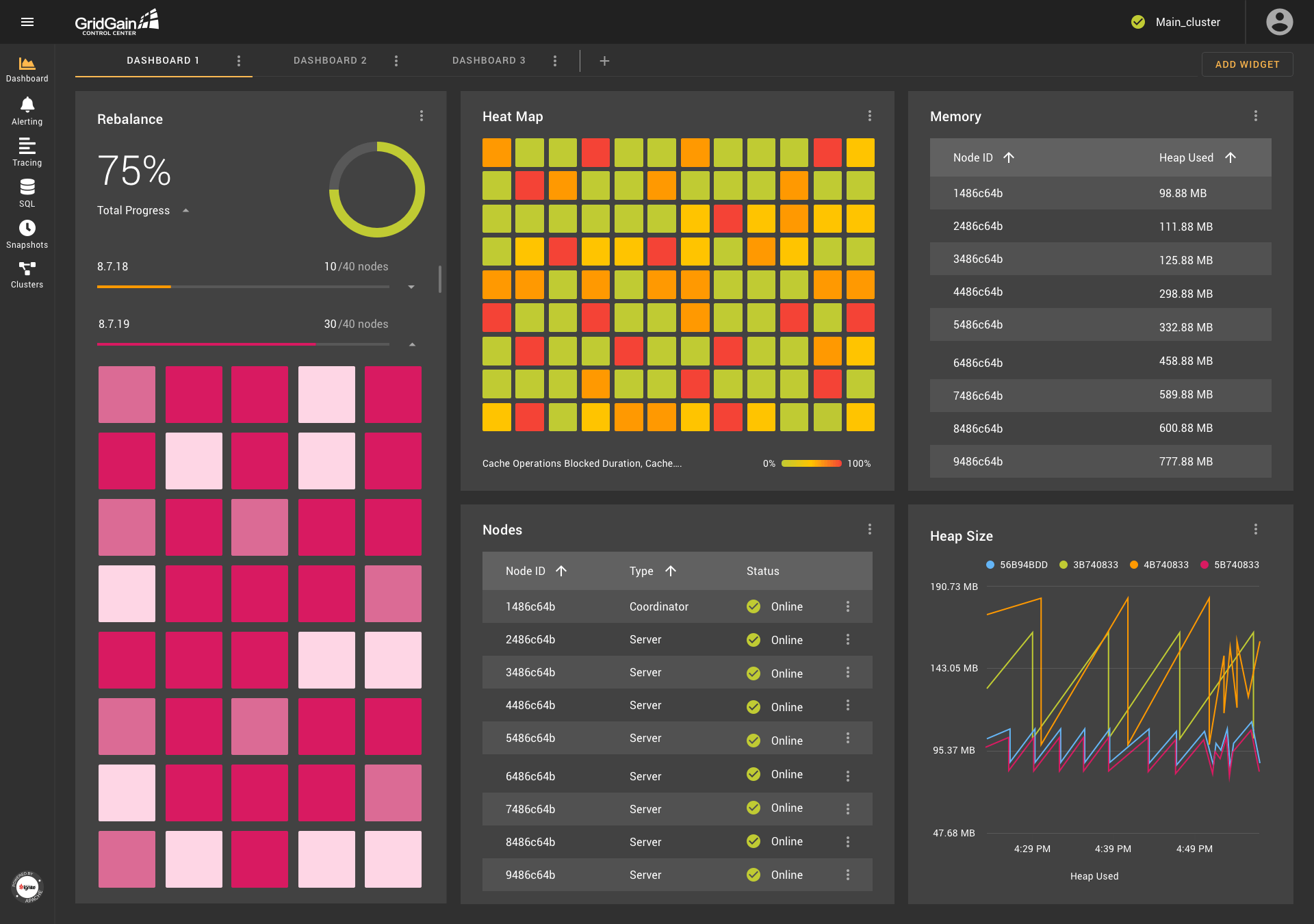
Основой любой системы мониторинга является возможность работы с метриками. В Control Center этой функциональности уделено особое внимание. Экран Dashboard предлагает возможность настройки виджетов на основе метрик, поступающих из кластера. Среди доступных способов визуализации на данный момент есть график, гистограмма, таблица и тепловая карта (heat map). Также есть специфичные для GridGain виджеты, такие как список узлов или визуализация ребаланса.
Dashboard может содержать набор данных виджетов в любом удобном расположении друг относительно друга. Dashboard-ов может быть несколько, что позволяет создавать специализированные экраны мониторинга определённых подсистем GridGain. Например, экран мониторинга состояния региона данных может выглядеть следующим образом:

Настройка уведомлений
Метрики могут служить не только для визуального отображения информации. На основе них также можно настроить уведомления, которые будут срабатывать при удовлетворении указанных условий. Если вы волнуетесь, что память на одном из серверов переполнится, беспокойство можно облегчить, настроив уведомление по SMS или Email. Если соответствующая метрика пересечёт указанный порог и продержится на таком уровне достаточное время, то вам придёт об этом сообщение:

Трейсинг
Многие операции в кластере требуют взаимодействия между разными узлами. В случае неполадок или задержек бывает сложно определить, какой узел является виновником и на какой стадии возникла проблема.
Трейсинг – одно из нововведений в GridGain и Apache Ignite, упрощающее анализ таких ситуаций. Это фреймворк, позволяющий отслеживать исполнение операций, даже если они имеют распределённый характер. Каждый этап исполнения (span) логируется и привязывается к операции, для которой данное отслеживание (trace) было запущено. Все транзакции в кластере могут быть отслежены, и для самых долгих из них есть возможность найти этап, занявший наибольшее количество времени. Хоть трейсинг и появился в GridGain совсем недавно, его поддержка уже реализована в Control Center.
Самая важная информация, относящаяся к трейсам, находится на видном месте, чтобы не было необходимости долго её искать:

Подробные детали для каждого спана также доступны:

Запуск SQL
У GridGain есть возможность работы с данными при помощи SQL. Для выполнения задач, связанных с SQL запросами, в Control Center есть отдельная секция. Там вы найдёте редактор кода с базовыми возможностями подсветки синтаксиса и автоподстановкой. Можно создать несколько вкладок с запросами, которые сохраняются между запусками:

Запросы, выполняющиеся в текущий момент, можно найти на отдельной вкладке:

Также здесь можно найти статистику по запросам с информацией о числе запусков, падений и времени исполнения:

Создание снимков данных
GridGain Ultimate Edition предлагает функционал снятия снимков данных (snapshots), позволяющий зафиксировать набор записей, присутствующий в кластере на момент начала создания снимка. При этом останавливать кластер не требуется. Для работы со снимками в Control Center есть отдельная секция, где вы можете создать новый снимок, а также применить, проверить или переместить существующий. Поддерживается работа с полными и инкрементальными снимками, со сжатием и без:

Управление кластерами
Такие административные действия, как активация и деактивация, изменение набора узлов в базовой топологии, настройка новых кластеров для мониторинга, собраны на отдельном экране Control Center. Здесь можно посмотреть на список своих кластеров или выполнить действия по настройке, для которых обычно требуется CLI. Это весьма полезный экран для администраторов, производящих работу над кластером, требующую ввода или вывода узлов из топологии:

Архитектура
Теперь рассмотрим, как Control Center устроен. Посмотрим на то, как происходит взаимодействие с кластером, как хранится служебная информация, и какие внутренние возможности GridGain используются в реализации Control Center.
Агент
Связующим звеном между Control Center и кластером выступает агент, функционирующий как часть каждого узла. Control Center Agent интегрирован с GridGain посредством API для плагинов. Если в classpath узла имеется соответствующий модуль, плагин инициализируется и устанавливает связь с Control Center. Взаимодействие между агентом и Control Center происходит по протоколу STOMP поверх Web Socket.
Одновременно только один агент работает в активном режиме и имеет соединение с Control Center. Остальные агенты в это время находятся в режиме ожидания. Если узел с активным агентом выходит из топологии, происходит выбор нового ответственного узла. Тот факт, что агент запускается в том же процессе, что и сам узел, упрощает установку и поддержку инфраструктуры мониторинга. Также в такой схеме у агента есть возможность пользоваться Java API узла напрямую вместо отправки запросов в кластер снаружи через внешнее API.
Альтернативный вариант связи с кластером был реализован в другом инструменте мониторинга от GridGain – Web Console, на смену которого пришёл Control Center. В Web Console агент работает в отдельном процессе и связывается с кластером посредством REST API. Такая схема несёт в себе трудности при настройке и поддержке дополнительного компонента, сложности с обеспечением его отказоустойчивости и безопасности проходящего через него трафика. В ответ на множественные отзывы пользователей, эта схема была заменена на более простую.
Добавление кластера к учётной записи
Как было продемонстрировано ранее, для начала мониторинга кластера необходимо воспользоваться специальным временным токеном. В такой схеме участвуют три идентификатора:
Cluster ID – значение, генерируемое один раз за всё время работы кластера. Оно служит как уникальный идентификатор кластера во внутренних структурах Control Center. Каждый запрос в кластер или информация, поступающая из него, сопровождается данным идентификатором. Он является внутренней деталью реализации, но может быть замечен пользователем, например как часть URL в адресной строке браузера.
Cluster Secret – значение, парное Cluster ID. Оно служит для подтверждения аутентичности кластера. Если злоумышленник каким-то образом получит доступ к чужому Cluster ID, то он не сможет подключить свой кластер с тем же идентификатором, так как у него не получится пройти проверку на соответствие Cluster ID и Cluster Secret.
Connection Token – временный токен, который может быть использован один раз для подключения кластера к учётной записи пользователя.
При подключении кластера к Control Center происходит проверка соответствия его Cluster ID и Cluster Secret. Если проверка прошла успешно, то генерируется Connection Token. Информация о соответствии между Cluster ID и Cluster Secret, а также между Cluster ID и Connection Token хранится на стороне бэк-энда Control Center.
Ссылка, отображаемая в логах узлов кластера, содержит в себе Cluster ID и Connection Token. Кластер привязывается к учётной записи, которая была активна на момент открытия ссылки. Если пользователь не был аутентифицирован в Control Center, то будет создана временная учётная запись. Её можно превратить в постоянную, задав пароль и указав недостающие данные в настройках. Также токеном можно воспользоваться напрямую через пользовательский интерфейс без использования ссылки.
Метрики
В Apache Ignite и GridGain активно разрабатывается фреймворк для упрощения работы с метриками. Все метрики в системе регистрируются в единый реестр, из которого их можно экспортировать в удобном для конкретной цели формате. Подробности можно узнать в соответствующем IEP.
Интересной для Control Center является возможность реализации exporter-а метрик, который может быть использован для пересылки метрик из GridGain в стороннюю систему мониторинга. Control Center активно пользуется этим фреймворком и имеет свою реализацию exporter-а. Раз в установленный период времени агент собирает с кластера необходимые метрики и отправляет их в Control Center. Там они обрабатываются, сохраняются в базу и отправляются пользователям при наличии соответствующих браузерных сессий.
Трейсы
В GridGain и Apache Ignite находится в активной разработке функционал по сбору трейсов – структурированной истории выполнения операций с указанием длительности каждого из этапов. На данный момент есть возможность сбора информации о работе следующих компонентов: Discovery SPI, Partition Map Exchange, Transactions, Communication. В будущем планируется покрытие и остальных компонентов.
Трейсинг GridGain совместим с OpenCensus API. Все трейсы и спаны регистрируются в фреймворке OpenCensus, после чего поступают в специальный компонент для экспорта информации о спанах – SpanExporter. Как и в случае с метриками, Control Center имеет свою реализацию exporter-а, которая находится в агенте.
Спаны в рамках одного трейса могут быть записаны на разных узлах кластера. Это даёт возможность анализа распределённых операций. Каждый спан имеет ссылку на своего родителя – операцию, которая породила текущую операцию. Собрав все спаны в рамках одного трейса воедино, можно представить пошаговую древовидную историю исполнения. Для этого каждый из узлов периодически отправляет информацию о спанах, зарегистрированных локально, на узел, имеющий активное соединение с Control Center. Когда все спаны в рамках одного трейса собраны на backend-е Control Center, такой трейс готов к отображению пользователю.
Хранение данных
Выбор базы данных для хранения системной информации оказался не слишком сложной задачей. GridGain отлично справляется с хранением информации о пользователях и настройках, а также с большим потоком поступающих метрик и трейсов. В целях отказоустойчивости данные о пользователях, трейсах и метриках хранятся раздельно. Таким образом выход из строя хранилища трейсов никак не влияет на функционал отображения графиков, основанных на метриках. Каждый из данных кластеров можно настраивать и оптимизировать отдельно, изучив и учитывая специфику нагрузки.
Под капотом Control Center использует как интеграцию GridGain со Spring Data, так и Cache API напрямую. Инициализация состояния базы, генерация запросов и миграции реализованы при помощи механизмов Spring Data. В некоторых случаях базовых возможностей Spring Data оказалось недостаточно, поэтому интеграция была улучшена. Так, например, была добавлена поддержка Querydsl. Соответствующее улучшение в Apache Ignite на данный момент находится на этапе code review.
История метрик и трейсов хранится в GridGain только ограниченное время – один день в случае метрик и неделю в случае трейсов. После этого данная информация удаляется согласно expiry policy, настроенной в GridGain.
Что будет дальше?
Несмотря на имеющиеся широкие возможности Control Center, активная разработка не останавливается. Всё ещё имеется ряд мест, которые предстоит разработать или улучшить.
Вот список самых значимых планируемых доработок:
- Переработка механизма взаимодействия с фреймворком метрик. В скором будущем появится возможность задания шаблонов, по которым метрики будут отображаться на графиках. Сейчас для выбора доступен только преднастроенный набор шаблонов.
- Интеграция отображения метрик и уведомлений о неполадках. Если для метрики настроено уведомление, это должно быть отражено на соответствующем графике.
- Расширение набора поддерживаемых компонентов, доступных для трейсинга. Данная работа ведётся на стороне Core GridGain и Apache Ignite.
- Интеграция с OpenID Connect и LDAP. Сейчас в Control Center доступна только нативная аутентификация, но в скором будущем появится возможность аутентификации через сторонние сервисы, такие как Google, Microsoft, Okta и т.д. Также планируется реализация механизма Single-Sign-On через OpenID Connect. Так, если в кластере настроена аутентификация через тот же сторонний сервис, что и для Control Center, повторная аутентификация в кластере не потребуется.
- Поддержка GridGain Data Center Replication. Будут добавлены возможности по управлению и мониторингу процесса репликации между разными кластерами GridGain.
Стоило ли оно того?
Разработка собственного инструмента мониторинга – серьёзная задача. В нашем случае это потребовало года интенсивной работы целой команды. Чего же мы этим добились? Повышения удобства использования GridGain – нашего основного продукта. Разработав Control Center, мы решили задачу настройки инфраструктуры мониторинга для каждого нашего нового пользователя. Стоит ли делать такую систему мониторинга самому? У вас должны быть на это очень серьёзные причины. Для нас это была инвестиция, которая сделала весь наш продукт более удобным.
Ссылки и дополнительные материалы
- Сайт GridGain Control Center: https://control.gridgain.com/
- On-premises версия Control Center: https://www.gridgain.com/resources/download#controlcenter
- Документация Control Center: https://www.gridgain.com/docs/control-center/latest/overview
- Видео обзор возможностей Control Center (на английском): https://www.youtube.com/watch?v=6Ra_5agkeY4
- Пример подключения кластера Apache Ignite к Control Center (на русском): https://www.youtube.com/watch?v=5Dcn_8TWQuU
- Вебинар 11 ноября 2020 про аутентификацию пользователей в Control Center (на русском): https://intl.gridgain.com/ru/resources/webinars/openid-connect-in-CC