

В рекомендательных системах нет доминирующего класса моделей. Матричные разложения, графовые и контентные рекомендеры активно развиваются: про них пишут научные статьи, их используют в продакшене. Пять лет назад на волне интереса к нейронным сетям стали популярны нейросетевые рекомендеры, но довольно быстро наступило разочарование. На RecSys 2019 лучшей выбрали статью с критикой нейросетевого подхода (в этом году его тоже пинают). Стоит ли практикам забыть о нейронных сетях в рекомендациях? Я уверен, что нет. Мой рекомендер уже год работает в продакшене и помогает пользователям Одноклассников заказывать интересные товары. Я расскажу, почему построил рекомендер на основе нейронной сети. После прочтения статьи у вас не останется причин не сделать также в вашем сервисе.
В научных статьях по рекомендательным системам главная мера успеха – точность модели рекомендера. Модель, которая улучшает SOTA на стандартных данных, имеет больше шансов на публикацию, чем просто научная идея. Применимость на практике желательна, но не обязательна. Поэтому в качестве SOTA выступают монстры вроде “Deep Variational Autoencoder with Gated Linear Units and VampPriors” [kim] (Шишков, прости: не знаю, как перевести). Авторы вышеупомянутой статьи с RecSys 2019 выяснили, что большинство подобных работ невозможно повторить [dacrema]. А значит, их результатам нельзя доверять. Это бросило тень на репутацию целого класса рекомендеров – нейросетевые модели.
Рекомендер, работающий в продакшене, – сложная инженерная система. Инженер не станет добавлять еще больше сложности ради едва заметного улучшения метрик. Поэтому в индустриальных рекомендерах простота выходит на первый план вместе с точностью. Пять лет назад я был уверен, что нейронные сети слишком сложные, чтобы работать в продакшене. В 2019 я разработал нейросетевой рекомендер товаров в Одноклассниках и продолжаю поддерживать и улучшать его. У меня нет сомнений в практичности этого подхода и со мной согласны инженеры Google [chen,covington] и Airbnb [haldar].
Я приведу аргументы в пользу нейросетевых рекомендеров. Сначала обсудим, как нейронные сети помогают улучшить архитектуру сервисов. Потом поговорим о том, как удобно добавлять новые данные в нейросетевую модель. После этого разберемся, как архитектура нейронных сетей дает исследователю возможность экспериментировать с различными предположениями. Наконец, заглянем в будущее рекомендательных систем. Я расскажу про идеи, которые применимы в любой задаче рекомендаций. А иллюстрировать их буду такими вставками про рекомендер товаров в Одноклассниках.
Сервис Товары – это интернет-магазин внутри Одноклассников. Пользователи ежедневно делают 8000 заказов из каталога AliExpress, не выходя из социальной сети. Чтобы пользователям было проще ориентироваться в стомиллионом каталоге, сервис показывает им персонализированные рекомендации. Алгоритм анализирует активность пользователя в Товарах и Одноклассниках в целом и строит витрину рекомендаций наподобие этой:
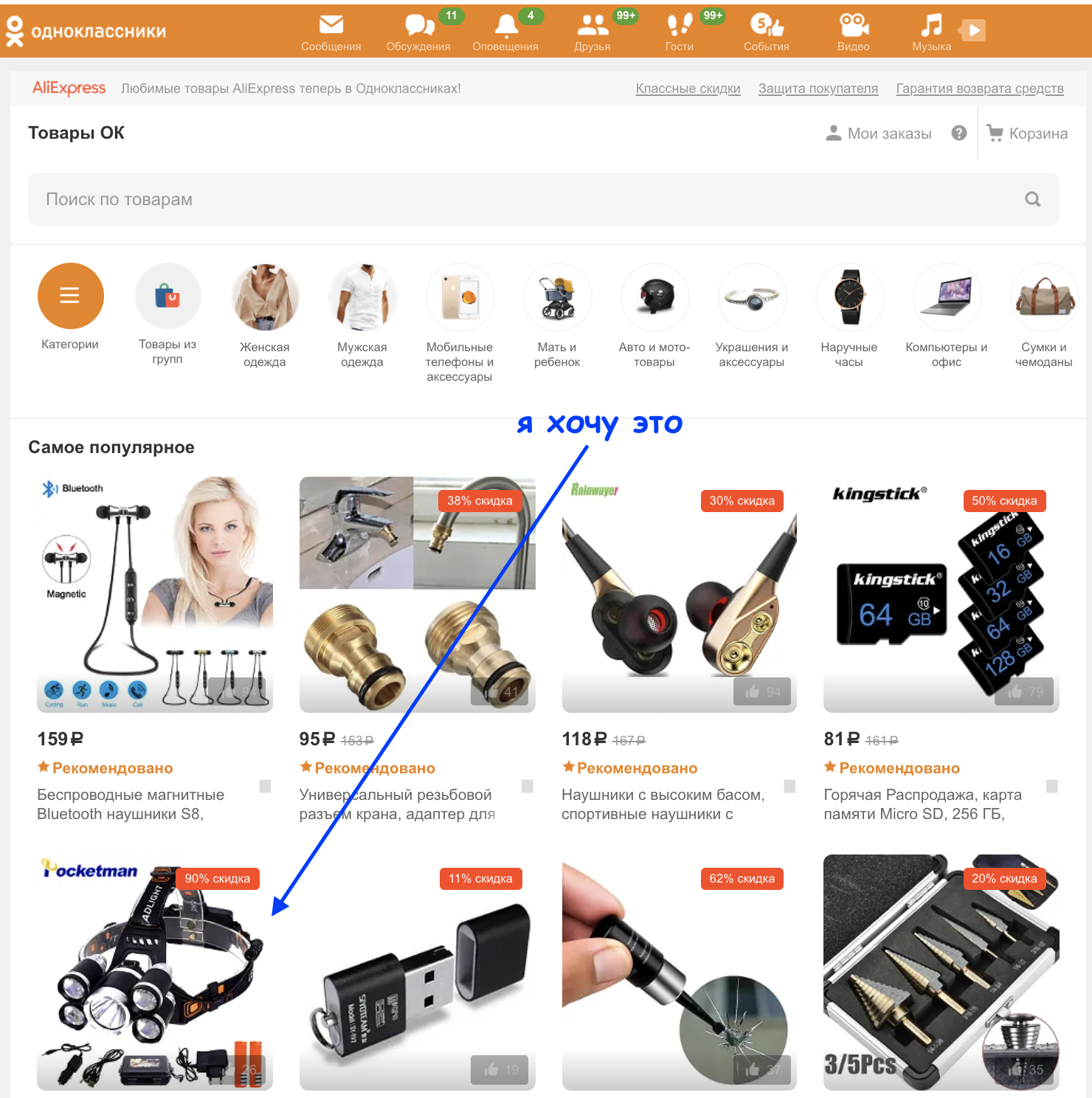
Сервис постоянно улучшается. За последний год я провел 33 A/B эксперимента по улучшению рекомендера. 23 эксперимента были успешными, 8 – неуспешными и 2 техническими.
Нейросетевой рекомендер помогает упростить архитектуру сервиса
Рассмотрим задачу коллаборативной фильтрации: на основании данных о прошлых покупках предложить пользователям товары, которые они захотят купить в будущем. Допустим, мы решили применить стандартный рекомендательный подход: собираем датасет с покупками пользователей, тренируем на этих данных модель и доставляем ее в прод. Периодически повторяем эти шаги, чтобы поддерживать актуальность модели.
У такого подхода есть недостаток: модель может предложить рекомендации только тем пользователям, которые что-то покупали. А показывать рекомендации нужно всем. Возникает идея добавить модель холодного старта, которой не нужны данные о предыдущих покупках. Качество рекомендаций у модели холодного старта будет хуже, чем у модели теплого старта, но зато она будет выбирать товары на основании информации, которая известна про всех пользователей. Обучаем модель холодного старта по той же схеме, что модель теплого старта.
В Товарах ОК проблема холодного старта реальна. Только 6% аудитории Одноклассников регулярно пользуются сервисом Товаров – оставшиеся 94% могут о нем вообще ничего не знать. Им коллаборативная модель не может ничего предложить. Но именно их важно привлечь – для этого мы показываем им персонализированные рекомендации товаров в ленте. За это отвечает модель холодного старта. Она строит рекомендации на основе пола и возраста пользователей и списка групп, на которые они подписаны. В A/B эксперименте персонализация холодного старта добавила +8% к нажатиям кнопки “купить” и +3% к пользователям сервиса.
После добавления модели холодного старта получилась схема с двумя моделями: если у пользователя достаточно данных о предыдущих покупках – используется модель теплого старта; иначе – модель холодного старта. Кроме того, имеет смысл добавить предсказания модели холодного старта как признак в модель теплого старта, чтобы улучшить ее качество.
Из картинки выше видно, как сложно будет поддерживать два связанных пайплайна:
Готовить две зависимые обучающие выборки.
Обучать модель теплого старта после модели холодного старта.
Одновременно заводить модели в продакшен.
Добавление новых моделей усложняет архитектуру сервиса. Чтобы контролировать количество моделей, можно упаковать как можно больше логики в одну модель. Это позволяют сделать нейронные сети.
Нейронная сеть – это функция, дифференцируемая по обучаемым параметрам. В примере с рекомендациями выбор между моделью холодного и теплого старта выражается дифференцируемой операцией. И если сами модели тоже дифференцируются, то все компоненты можно упаковать в одну нейронную сеть. С помощью современных deep learning фреймворков эту нейронную сеть можно обучить end-to-end и завести в продакшен.
Проблемы с воспроизводимостью – один из основных аргументов против нейросетевых рекомендеров. Мои коллеги разработали ML платформу, которая обеспечивает воспроизводимость экспериментов. Она построена на фреймворках Airflow, DVC и MLflow. С помощью ML платформы мы обучаем нейросетевые (и не только) модели, следим за их метриками и выкатываем их в продакшен. До переезда на платформу, чтобы обновить модель товаров, я вручную запускал сложный пайплайн из Spark-джоб и скриптов. Сейчас я делаю это в несколько кликов. Подробности об ML платформе в докладе @mikhail_mar.
У упаковки нескольких моделей в одну нейронную сеть есть ограничения:
Сложно совместить модели, которые получают на вход разные типы объектов. Например, персонализированный рекомендер, у которого на входе пользователь, не упакуешь вместе с item-to-item рекомендером, у которого на входе товар.
Логику модели придется писать руками: скорее всего, понадобится нейронная сеть, состоящая из нескольких компонентов с отдельными выходами и собственной функцией потерь. Использовать готовое решение не получится.
Усложняется подготовка обучающих данных по сравнению с одиночным рекомендером. Теперь в один датасет нужно будет складывать данные для обучения всех компонентов модели.
Когда эти ограничения можно принять, подойдет нейросетевой рекомендер. С одной стороны, он будет работать как коробка, внутри которой можно экспериментировать с любым количеством взаимосвязанных идей. С другой стороны, для внешнего мира эта коробка будет монолитной моделью. В следующем разделе положим в нее самое ценное, что у нас есть – данные.
В нейросетевой рекомендер легко добавлять новые признаки
Один из способов улучшить модель – добавить в нее новые признаки. Не во всех данных есть полезный сигнал, поэтому при создании модели важно быстро экспериментировать с признаками. Нейросетевой рекомендер это позволяет: в него легко добавить любые виды данных. Посмотрим, как это делается, на примере категориальных, числовых признаков и последовательностей.
Нейросетевые рекомендеры не оправдали ожиданий академии: оказалось, что они не гарантируют выигрыша в точности по сравнению "классикой”. Но это верно, если сравнивать на одних и тех же простых user-item данных. Как только данные становятся разнообразнее, нейронные сети обходят классических конкурентов. Вот какие гипотезы я проверял при работе над рекомендером товаров: “стоит ли учитывать в модели покупки друзей пользователя?”, “будет ли модель точнее, если дать ей информацию о городе, в котором живет пользователь?”, “имеет ли значение последовательность, в которой пользователь просматривал товары?”. Попробуйте проверить эти идеи, если ваша модель – SLIM [ning]. В лучшем случае вы обрастете пайплайнами Spark-джоб и кучей эвристик. В худшем – уволитесь и откроете кофейню.
Из тридцати трех A/B экспериментов, которые я провел с рекомендером товаров, семь измеряли эффект от добавления новых признаков. Пять из них показали значимый прирост в ключевых метриках. Подготовка эксперимента с добавлением новых признаков всегда занимала меньше недели. В том числе из-за того, что добавлять новые признаки в нейросетевой рекомендер очень просто. Самым успешным экспериментом с признаками был эксперимент по добавлению в рекомендер товаров друзей. Он увеличил выручку сервиса на +7%.
Категориальные признаки кодируются эмбедингами. Пример такого признака – ID товара. В каталоге восемь миллионов товаров, но по большинству из них нет коллаборативных данных. Поэтому собственный эмбединг получают только самые частотные. Остальные можно закодировать значением out-of-vocabulary.
Числовые признаки кодируем их значением. Числовые признаки могут быть одномерными (поставил ли пользователь “класс” товару), либо многомерными (посчитанный заранее эмбединг фотографии товара).
Модели нужны представления товаров и пользователей, собранные из признаков. Например, представление товара, с которым взаимодействовал конкретный пользователь, может состоять из:
идентификатора товара (категориальный признак),
идентификатора категории товара (категориальный признак),
места товара в последовательности товаров, с которыми взаимодействовал пользователь (категориальный признак)
наличия “класса” (числовой признак)
факта покупки товара пользователем (числовой признак).
Чтобы получить представление для товара, кодируем и конкатенируем его признаки. Похожим образом получаем представление пользователя.
Пользователь может взаимодействовать с неограниченным количеством товаров: выбирать из различных вариантов, совершать несколько покупок. Поэтому недостаточно иметь представление единичного товара – нужно уметь представить последовательность товаров. Зная всю историю взаимодействий, модель сможет выучить краткосрочные и долгосрочные интересы пользователя.
Итак, из последовательности векторов-представлений нужно получить один вектор. Проще всего усреднить векторы из последовательности. А можно добавить немного интерпретируемости [pruthi] и использовать усреднение с весами. Веса будем вычислять механизмом query-key-value attention [uzay].
В рекомендере товаров я использовал признаки пользователя в качестве query и представления товаров в качестве key и value. Модель выучила понятные человеку закономерности:
- Купленный товар имеет больший вес, чем товар, который пользователь просто посмотрел.
- Чем дальше в прошлом пользователь взаимодействовал с товаром, тем меньше модель обращает на него внимания.
- Модель не обращает внимания на технические товары-падинги, которые добавлены, чтобы выровнять длины последовательностей в батчах.
Кроме товаров пользователя в модели используются и другие последовательности: последовательность групп, на которые пользователь подписан и последовательность товаров друзей. Эти последовательности важны для компонента холодного старта.
В этом разделе мы научились укладывать в модель-коробку любые виды данных. Выбрав простой механический подход к добавлению признаков, мы в какой-то степени отказались от feature engineering, который называют искусством [duboue]. Но за это получили скорость экспериментирования. В следующем разделе добавим креатива.
В архитектуру нейронной сети можно заложить представления исследователя о задаче
Теперь, когда у рекомендера есть данные, нужно дать ему возможность их использовать. Мы представили признаки просто, поэтому модель должна быть достаточно экспрессивной, чтобы выучить сложные зависимости. Можно придумать собственную архитектуру, но проще оттолкнуться от проверенной. Например, от первых двух уровней SVD++ [koren] (третий уровень не используем, потому что он требует O(Nitems2) параметров).

SVD++ моделирует скор rui – насколько товар i подходит пользователю u – как линейную комбинацию обучаемых параметров:
Пользователь u представлен эмбедингом pu и смещением bu. Смещение показывает, насколько пользователю характерны высокие скоры “в общем”. Кроме того, используются эмбединги yj множества товаров N(u), с которыми взаимодействовал пользователь. Они полезны для пользователей, у которых недостаточно данных, чтобы получить точный эмбединг pu.
Товар представлен аналогично пользователю – эмбедингом qi и смещением bi.
Общее смещение ? отражает базовый уровень скоров в системе безотносительно пользователя и товара.
Такие архитектуры хорошо себя показывают в рекомендациях: кроме семейства SVD на похожих идеях основана библиотека LightFM [kula]. Выразим SVD++ с помощью нейронной сети.
Эта модель не будет идентична оригинальной. Например, потому что для классических рекомендеров разработаны специально заточенные под них алгоритмы оптимизации. Нейронные сети же оптимизируют алгоритмами общего назначения, например Adam. Но все-таки у модели есть возможность выучить те же закономерности, что выучивает классическая модель. Чтобы дать модели больше возможностей, можно усложнить архитектуру.
Изменения архитектуры отражают представления исследователя о связи между входными данными и целью предсказания. Эти представления, реализованные в модели, называют inductive bias (пример сверхуспешного inductive bias – свертки в computer vision [ulyanov]). Воспользуемся инструментами которые мы обсудили в предыдущих разделах, чтобы добавить полезный inductive bias к SVD++.
Изменение | Inductive bias | Реализация |
Добавление признаков товаров и пользователей | Модели легче выучить хорошие представления о товарах и пользователях, если она знает о них дополнительную информацию. Например, представления товаров из одной категории должны быть близки. Используя признаки, механизм attention может выбрать важные товары в данном контексте. | SVD++ представляет товары эмбедингами ID. В разделе о представлении признаков мы обсудили, как расширить это представление категориальными и числовыми признаками. |
Добавление нелинейных преобразований | Избавимся от предположения о линейной зависимости между данными и целью предсказания. | Нелинейные преобразования реализованы с помощью feed-forward сетей с полносвязными и residual блоками. С их помощью можно не только добавить нелинейность, но и “подогнать” размерности данных, где это необходимо. |
Добавление компонента холодного старта | Компонент холодного старта обеспечивает хорошие рекомендации пользователям, у которых мало коллаборативных данных. | В разделе про архитектуру сервиса мы обсудили, как компонент холодного старта помогает управлять сложностью системы. |
Минутная анимация показывает, как можно применить эти идеи для улучшения SVD++:

Финальная архитектура, которую я показал на анимации, отражает состояние рекомендера Товаров на февраль 2020. Я постоянно экспериментирую с моделью и с тех пор архитектура ушла вперед. Четыре A/B эксперимента дали статистически значимые улучшения метрик.
1. Нелинейное преобразование предобученных эмбедингов товаров: +7% к выручке.
2. Замена полносвязных слоев residual-блоками: +4.3% к покупающим пользователям.
3. Добавление переранжирующего компонента после отбора товаров-кандидатов: +4% к пользователям, нажимающим кнопку “купить”.
4. Добавление модели новых выходов, предсказывающих клики на карточки товаров: +2.4% к кликам.
Эксперимент с архитектурой сети – мой любимый вид эксперимента: он показывает мощь машинного обучения в чистом виде.
Расширяемость – преимущество нейросетевой архитектуры над классическими рекомендерами. Можно начать с простой модели и показать ее эффективность. А потом планомерно экспериментировать с улучшениями и проверять, что именно окажется эффективным в конкретной задаче. Вдохновение легко черпать в научных статьях. Предполагаем, что некоторые признаки работают по-разному для разных категорий пользователя? Используем deep & cross network [wang]. Хотим использовать информацию о товарах друзей? Добавляем нужный компонент [fan]. Считаем, что одно и то же внутреннее представление может предсказать “классы” и покупки? Заводим модель с несколькими экспертами [zhao]. За гибкость мы заплатим добавлением гиперпараметров, но эксперименты показывают, что рекомендеры не очень чувствительны к их выбору [haldar]. Мы обсудили, как с помощью нейронных сетей можно решить задачу рекомендаций в классической постановке. Настало время копнуть глубже.
Нейрорекомендеры изменят постановку задачи рекомендаций
Мы наполнили нашу коробку-модель: умеем подавать в нее данные и получать предсказания. Но в ней еще осталось место для новых перспективных идей. Пофантазируем о том, какие возможности открывают нейросетевые рекомендеры.
Выбор и ранжирование end-to-end. В индустрии устоялся подход, в котором рекомендации строятся с помощью двух моделей: первая отбирает небольшой топ товаров-кандидатов, а вторая перемешивает их, подстраиваясь под интересы пользователя [covington]. Модель для выбора кандидатов имеет дело с миллионами товаров и оптимизирует полноту. А модель-ранкер учится оценивать конкретный товар для конкретного пользователя в конкретном контексте. Эти модели можно совместить в одну архитектуру, но тогда применять ранкер придется к миллионам кандидатов, а не к небольшому топу. В Google эту проблему решили end-to-end для задачи обработки текстов с использованием attention и алгоритма поиска приближенных соседей [guu]. Этот подход применим и в задаче рекомендаций.
В предыдущем разделе я упоминал эксперимент с добавлением переранжирующего компонента. Идея в том, чтобы модифицировать скор товара, полученный скалярным произведением представления пользователя на представление товара. За это отвечает отдельный компонент – ранкер. Он приклеивается к выходу модели и обучается вместе с ней. У ранкера свой набор признаков. Этот эксперимент – мой первый шаг в направлении выбора товаров-кандидатов и их ранжирования end-to-end. Я планирую идти дальше в этом направлении.
Разнообразие рекомендаций. Современные сервисы показывают рекомендации списком. Это не учитывается при обучении модели. В результате рекомендации в списке могут оказаться однообразными. Разнообразия рекомендаций добиваются хитрым пост-процессингом предсказаний [bridge]. И снова кажется, что эту логику можно упаковать внутрь модели. Команда поиска из Airbnb уже показала такой результат [abdool].
В Товарах ОК пользователи видят целую витрину рекомендаций. В каталоге миллионы доступных товаров, среди которых много похожих. Если выбирать товары по релевантности, предсказанной рекомендером, то топ рекомендаций будет очень однообразным. Например пользователь, который интересовался удочкой, увидит в топе несколько видов лески подряд. Сейчас эта проблема решена смешиванием нескольких рекомендеров, но в будущем я добавлю компонент разнообразия напрямую в нейросетевую модель.
Обучение с подкреплением. Задача коллаборативной фильтрации, с которой я начал эту статью, поставлена как задача обучения с учителем: дана обучающая выборка – хотим выучить, как по признакам получить значения целевой переменной. Эта постановка не включает в себя многие проблемы индустриальных рекомендательных систем, например exploration-exploitation tradeoff, filter bubbles, selection bias. Эти проблемы хорошо ложатся на постановку обучения с подкреплением [munemasa], в которой агент (рекомендер) взаимодействует со средой (пользователями) и получает награду (клики, покупки). Развитие нейронных сетей привело к возрождению обучения с подкреплением. Но использование этого подхода в рекомендациях – отдельная большая тема за рамками этой статьи.
Обучение с подкреплением в рекомендациях лежит скорее в области исследований, чем практического применения. В ОК нет отдельного исследовательского подразделения, но для работы над интересными и перспективными задачами мы приглашаем стажеров. Попасть к нам на стажировку можно через образовательные проекты.
Пора задуматься о применении нейросетевого подхода в рекомендациях
Как видите, нейрорекомендеры можно не только ругать в научных статьях, но и использовать в продакшене. Я старался раскрыть практические стороны этого подхода и теперь рискну дать практический совет. В какой ситуации нейронные сети оправдают время и труд, которые вы в них инвестируете? Вот мой список критериев.
В задаче возникает несколько связанных рекомендеров с похожими постановками, например холодный и теплый старт.
В одном рекомендере нужно учитывать разные виды данных: коллаборативные, признаковые, социальные и так далее.
Есть возможность вкладывать время в инфраструктуру и обеспечение воспроизводимости в начале проекта. Впоследствие это упростит жизнь: будет удобно экспериментировать с архитектурой сети и признаками.
Нужно выйти за рамки постановки коллаборативной фильтрации, чтобы решать внутри модели дополнительные задачи, например, проблемы ранжирования кандидатов, разнообразия рекомендаций или долгосрочного планирования.
Если в вашей задаче эти критерии выполнены, то есть смысл строить рекомендер на основе нейронной сети. Пять лет назад я скептически относился к этой идее, но попробовал – и не разочаровался.
Литература
[abdool] Managing Diversity in Airbnb Search
[bridge] A comparison of calibrated and intent-aware recommendations
[chen] Improving Recommendation Quality in Google Drive
[covington] Deep Neural Networks for YouTube Recommendations
[dacrema] Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches
[duboue] The Art of Feature Engineering Essentials for Machine Learning
[fan] Deep Social Collaborative Filtering
[guu] REALM: Retrieval-Augmented Language Model Pre-Training
[haldar] Applying Deep Learning To Airbnb Search
[kim] Enhancing VAEs for Collaborative Filtering: Flexible Priors & Gating Mechanisms
[koren] Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model
[kula] Metadata Embeddings for User and Item Cold-start Recommendations
[liu] Related Pins at Pinterest: The Evolution of a Real-World Recommender System
[maryufich] Воспроизведение - это не мучение!
[munemasa] Deep reinforcement learning for recommender systems
[ning] SLIM: Sparse Linear Methods for Top-N Recommender Systems
[pruthi] Learning to Deceive with Attention-Based Explanations
[ulyanov] Deep Image Prior
[uzay] https://github.com/uzaymacar/attention-mechanisms
[wang] Deep & Cross Network for Ad Click Predictions
[zhao] Recommending what video to watch next: a multitask ranking system
Благодарности
Спасибо коллегам, которые помогали готовить эту статью: @gltrinix, @netcitizen, @m0nstermind, @lvoursl, @AndreySklyarevskiy, @mikhail_mar, @fanatique, Саша Белоусова. Без ваших советов и комментариев получилось бы намного хуже. Автор титульной картинки – Richard Galpin.
excoder
Заметно, что вы очень глубоко прониклись темой. Благодарю за статью!