

В этой статье я расскажу про свое решение текстовой части задачи SNA Hackathon 2019. Какие-то из предложенных идей будут полезны участникам очной части хакатона, которая пройдет в московском офисе Mail.ru Group с 30 марта по 1 апреля. Кроме того, этот рассказ может быть интересен и читателям, решающим практические задачи машинного обучения. Так как я не могу претендовать на призы (я работаю в Одноклассниках), я постарался предложить наиболее простое, но при этом эффективное и интересное решение.
Читая про новые модели машинного обучения, я хочу понять, как рассуждал автор, работая над задачей. Поэтому в этой статье я попробую подробно обосновать все компоненты своего решения. В первой части я расскажу про постановку задачи и ограничения. Во второй — про эволюцию модели. Третья часть посвящена результатам и анализу модели. Наконец, в комментариях я постараюсь ответить на любые возникшие вопросы. Нетерпеливые читатели могут сразу посмотреть на финальную архитектуру.
Задача
Организаторы хакатона предложили нам решить задачу формирования умной ленты. Для каждого пользователя необходимо отсортировать набор постов так, чтобы максимальное количество постов, которым пользователь поставил «класс», оказались в начале списка. Для настройки алгоритма ранжирования предполагалось использовать исторические данные вида (пользователь, пост, обратная связь). В таблице дано краткое описание данных из текстовой части и обозначения, которыми я буду пользоваться в этой статье.
| Источник |
Обозначение |
Тип |
Описание |
|---|---|---|---|
| пользователь |
user_id |
категориальный |
идентификатор пользователя |
| пост |
post_id |
категориальный |
идентификатор поста |
| пост |
text |
список, категориальный |
список из нормализованных слов |
| пост |
features |
категориальные |
группа характеристик поста (автор, язык и т.д.) |
| обратная связь |
feedback |
список, бинарный |
различные действия, которые пользователь мог провести с постом (просмотр, класс, комментарий и т.д.) |
Перед тем как начать строить модель, я ввел несколько ограничений на будущее решение. Это нужно было, чтобы удовлетворить требованиям простоты и практичности, моим интересам и уменьшить количество возможных вариантов. Вот самые важные из этих ограничений.
Предсказание вероятности «класса». Я сразу определился, что буду решать эту задачу, как задачу классификации. Можно было бы применить методы, используемые в ранжировании, например, предсказывать порядок в парах постов. Но я остановился на более простой формулировке, в которой посты сортируются в соответствии с предсказанной вероятностью получить «класс». Стоит заметить, что описанный ниже подход возможно расширить и для формулировки ранжирования.
Монолитная модель. Несмотря на то что ансамбли моделей имеют тенденцию побеждать в соревнованиях, поддерживать ансамбль на боевой системе сложнее, чем единственную модель. Кроме того мне хотелось иметь хоть какие-то не black box возможности интерпретации.
Дифференцируемый вычислительный граф. Во-первых, модели этого класса (нейронные сети) определяют state-of-the-art во многих задачах, в том числе связанных с анализом текстовых данных. Во-вторых, современные фреймворки, в моем случае Apache MXNet, позволяют реализовывать очень разнообразные архитектуры. Поэтому экспериментировать с разными моделями можно, меняя буквально несколько строк кода.
Минимум работы с признаками. Мне хотелось, чтобы модель можно было легко расширять новыми данными. Это может понадобиться в очной части, где времени на подготовку признаков будет мало. Поэтому я остановился на простейшем подходе к выделению признаков:
- бинарные данные представляются признаком со значением 1 или 0;
- числовые данные либо остаются как есть, либо дискретизируются в категории;
- категориальные данные представляются эмбеддингами.
Определившись с общей стратегией, я начал пробовать разные модели.
Эволюция модели
Отправной точкой стал подход матричной факторизации, часто используемый в задачах рекомендации:
На языке вычислительных графов это значит, что оценка вероятности того, что пользователь i поставит «класс» посту j — это сигмоид от скалярного произведения эмбеддингов идентификатора пользователя и идентификатора поста. То же самое можно выразить диаграммой:

Такая модель не очень интересная: она не использует все признаки, не слишком полезна для низкочастотных идентификаторов и страдает от проблемы холодного старта. Но, сформулировав задачу в виде вычислительного графа, мы «развязали себе руки» и можем теперь решать проблемы поэтапно. Первым делом для значений низкой частоты заведем единственный эмбеддинг Out-Of-Vocabulary. Далее избавимся от необходимости иметь эмбеддинги одной размерности. Для этого заменим скалярное произведение на неглубокий перцептрон, принимающий на вход конкатенированные признаки. Результат представлен на диаграмме:

Как только мы избавились от фиксированной размерности, ничего не мешает нам начать добавлять новые признаки. Представляя пост всевозможными характеристиками (языком, автором, текстом, ...), мы решим проблему холодного старта постов. Модель выучит, например, что пользователь с user_id = 42 ставит «классы» постам на русском языке, содержащим слово «ковёр». В будущем мы сможем рекомендовать этому пользователю все русскоязычные посты про ковры, даже если они не появлялись в тренировочных данных. Для эмбеддинга текстов пока будем просто усреднять эмбеддинги входящих в него слов. В результате модель выглядит так:
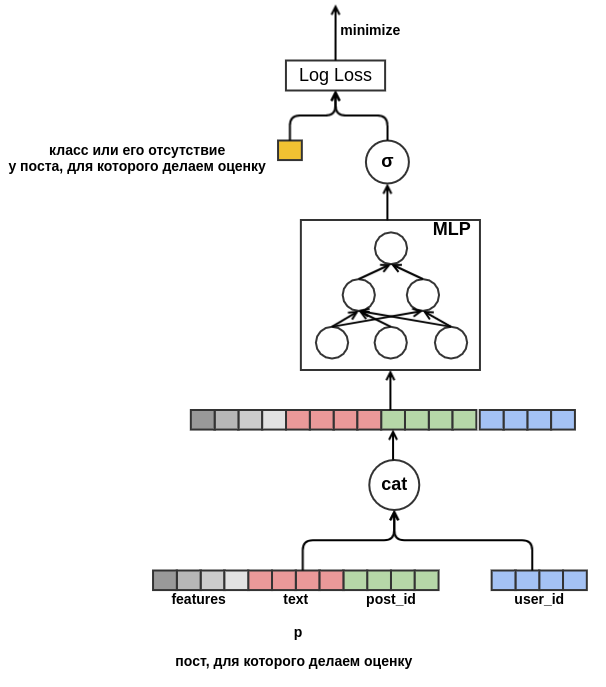
Наконец хотелось бы разобраться с холодным стартом пользователей. Можно было бы сконструировать признаки из исторических данных о просмотрах пользователем постов. Этот подход не удовлетворяет выбранной стратегии: мы решили минимизировать ручное создание признаков. Поэтому я предоставил модели возможность самостоятельно выучить представление пользователя из последовательности постов, просмотренных перед тем постом, для которого проводится оценка вероятности «класса». В отличии от оцениваемого поста, для каждого из постов последовательности известен весь feedback. Это значит, что модели будет доступна информация о том, поставил ли пользователь предыдущим постам «класс» или наоборот удалил их из ленты.

Осталось определиться, как скомбинировать последовательности постов разной длины в представление фиксированной ширины. В качестве такой комбинации я использовал взвешенную сумму представлений каждого из постов. На диаграмме вес поста j обозначен ?_j. Веса вычислялись с помощью механизма query-key-value attention, похожего на тот, который используется в трансформере или NMT. Таким образом выученное представление пользователя настраивается еще и на пост, для которого проводится оценка. Вот такой кусок графа отвечает за вычисление ?_j:
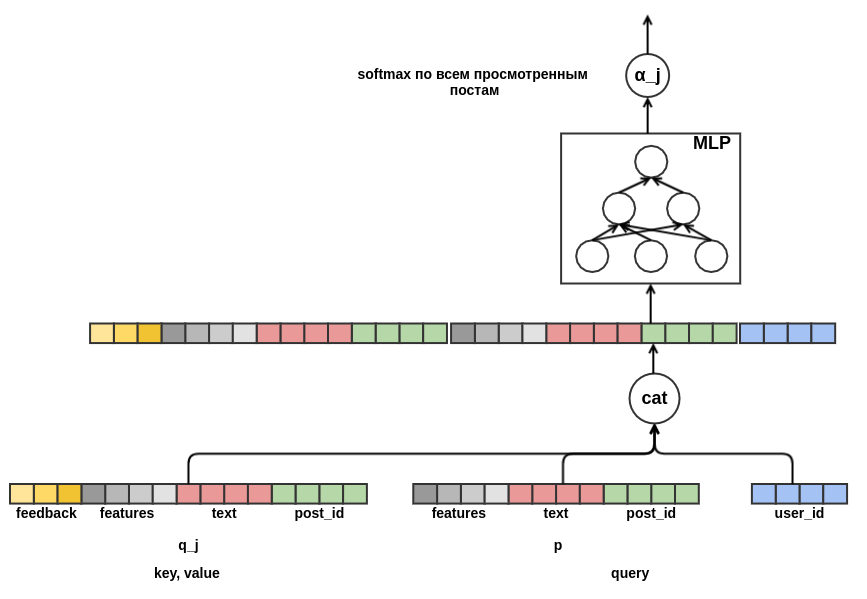
После того как я
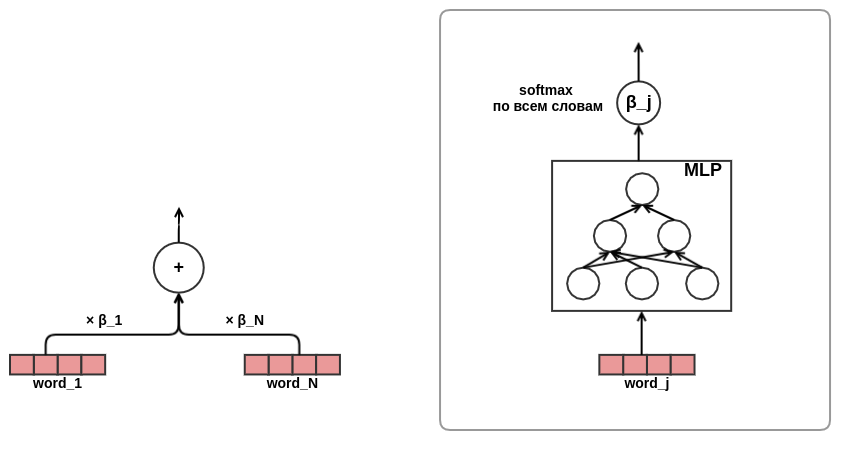
На этом разработка архитектуры модели была закончена. В итоге я прошел путь от классической матричной факторизации к довольно сложной sequence-модели.
Результаты и анализ
Свое решение я разрабатывал и отлаживал на одной седьмой части данных на ноутбуке с 16 Гб памяти и видеокартой GeForce 930MX. Эксперименты на полных данных запускались на выделенном сервере с 256 Гб памяти и картой Tesla T4. Для оптимизации использовался алгоритм Adam с параметрами по-умолчанию из MXNet. В таблице представлены результаты для урезанной модели — длина последовательности постов была ограничена десятью. В конкурсном сабмите я использовал последовательности длины пятьдесят.
| Модель |
Log Loss |
Улучшение по сравнению с предыдущей строкой |
Время обучения |
|---|---|---|---|
| Рандом |
0.4374 ± 0.0009 |
||
| Перцептрон |
0.4330 ± 0.0010 |
0.0043 ± 0.0002 |
7 мин |
| Перцептрон с признаками |
0.4119 ± 0.0008 |
0.0212 ± 0.0003 |
44 мин |
| Перцептрон с последовательностью постов |
0.3873 ± 0.0008 |
0.0247 ± 0.0003 |
4 часа 16 мин |
| Перцептрон с последовательностью постов и attention в текстах |
0.3874 ± 0.0008 |
0.0001 ± 0.0001 |
4 часа 43 мин |
Самой неожиданной для меня оказалась последняя строка: использование attention в представлении текстов не дает видимого улучшения результата. Я ожидал, что attention-сеть выучит веса слов в текстах, что-то вроде idf. Возможно этого не произошло, потому что организаторы заранее убрали стоп-слова и в подготовленных списках остались слова примерно одной важности. Поэтому «умное» взвешивание не дало ощутимого преимущества по сравнению с простым усреднением. Другая возможная причина в том, что attention-сеть для слов была довольно маленькой: она содержала только один узкий скрытый слой. Возможно, ей не хватило representation capacity, чтобы выучить что-то полезное.
Механизм query-key-value attention дает возможность заглянуть внутрь модели и выяснить, на что она «обращает внимание» при принятии решения. Чтобы это проиллюстрировать, я выбрал несколько примеров:
Узнайте, какого цвета ваша аура прямо сейчас http://ollston.ru/2018/02/10/uznajte-kakogo-cveta-vasha
- [0.02] PADDING
- [0.02] PADDING
- [0.02] PADDING
- [0.02] PADDING
- [0.16] НЛО Возле солнца и на снимках Марса 2016 НЛО Возле солнца и на снимках Марса 2016 GZ8btjgY_Q0 https:
- [0.16] Истории успеха. Nike http://ollston.ru/2018/02/04/istorii-yspeha-nike/ Узнал сам - расскажи другому:
- [0.09] Истории на ночь - 5 странных переписок Истории на ночь - 5 странных переписок O3qAop0A5Qs https://ww
- [0.09] ... В результате минивэн оказался под большегрузом, и тяжелая машина на всей скорости снесла ему кры
- [0.22] Microsoft Windows — история успеха http://ollston.ru/2018/02/06/microsoft-windows-istoriia-yspeha/ У
- [0.20] Буддисты говорят, что есть 6 типов душ. Знаете, какая у вас? http://ollston.ru/2018/02/08/buddisty-gВ первой строке показан текст поста, который нужно оценить, дальше — просмотренные до этого посты и соответствующий attention score. С облегчением замечаем, что модель научилась не обращать внимания на padding. Наиболее важными модель сочла посты про типы душ и про Windows. Стоит иметь в виду, что attention может быть как позитивным (пользователь отреагирует на пост про ауру примерно также, как и на пост про типы душ), так и негативным (оцениваем пост про ауру — следовательно реакция будет не такой, как реакция на пост про технологии). Следующий пример — attention «во всей красе»:
Феодосия п Приморский Семейный отдых у моря без посредников Част
- [0.20] Приглашаем вас на отдых в 2018 году в ЕВПАТОРИЮ (КРЫМ), в мае, июне и в сентябре. Мы сдаем свои доми
- [0.08] Показал ребятам как надо играть на гитаре... КЛАССНЫЙ МУЗЫКАНТ!!! Подпишись на нашу группу по этой с
- [0.04] Немного замарался))) дети
- [0.18] Бронирование отелей по всему миру ! Авиабилеты в любые направления, в режиме онлайн. Более 10 лет на
- [0.18] Ялта Сдается 2-х комнатная квартира в Ялте, до 5 человек, кондиционер, 2 ТВ, стир. машина. До центра
- [0.07] Обалдеть что творят эти ребята! Колхозный панк - СЕКТОРА ГАЗА (Кавер) Подпишись на нашу группу по эт
- [0.03] ПРОПАЛ КОТИК Откликается на "Барсика". Район улицы Физкультурная. Очень дорог для семьи и детише
- [0.13] На фото кораллы, их насчитывают б
- [0.05] Эй, ты куда собралась ...
- [0.05] Такого я ещё не видел... Здесь модель явно увидела тему летнего отдыха. Даже дети и котята ушли на второй план. Следующий пример показывает, что интерпретировать attention не всегда возможно. Иногда даже совсем ничего не понятно:
лучше быть волком одиночкой чем в стаде шакалов !
- [0.02] PADDING
- [0.02] PADDING
- [0.02] PADDING
- [0.02] PADDING
- [0.02] PADDING
- [0.15] КРАСАВЧИК, ПАРЕНЬ! СМОТРЕТЬ ОДНО УДОВОЛЬСТВИЕ!!!
- [0.16] Добрый вечер! http://gifok.ru/dobryj-vecher/
- [0.20] http://gifq.ru/aforizmy/
- [0.25] Когда ты мастер своего дела. Внутренняя отделка.
- [0.15] МЯСО, ТУШЕНОЕ С ШАМПИНЬОНАМИ И СЛАДКИМ ПЕРЦЕМ. Ингредиенты: 800 г свинины 250-300 г шампиньоновПосле просмотра некоторого количества подобных списков я сделал вывод, что модель смогла выучить то, что я ожидал. Следующее, что я сделал — посмотрел на эмбеддинги слов. В нашей задаче нельзя ожидать, что эмбеддинги получатся такие же красивые, как при обучении language model: мы пытаемся предсказать довольно шумную переменную, кроме того у нас нет маленького контекстного окна — эмбеддинги всех слов просто усредняются без учета их порядка в тексте. Примеры токенов и их ближайших соседей в пространстве эмбеддингов:
- кошк : сос, бега, щенк, стерилизова, куша
- сельдер : отжа, провар, сформирова, миллилитр, размеша
- айфон : шу, примечательн, защищ, разва, ёки
- программ : твар, помож, инициатив, демократ, бл
- санкт : перербург, бензин, шоколадк, вулка, кругКое-что из этого списка легко объяснить (программа — бл), кое-что вызывает недоумение (айфон — ёки), но в целом результат опять соответствовал моим ожиданиям.
Заключение
Мне нравится подход к построению моделей, основанный на дифференцируемых графах (многие согласны). Он позволяет уйти от нудного ручного выделения признаков и сосредоточиться на правильной постановке задачи и проектированию интересных архитектур. И хотя моя модель заняла в текстовой задаче SNA Hackathon 2019 только второе место, я вполне доволен этим результатом, учитывая ее простоту и практически неограниченные возможности расширения. Я уверен, что в будущем будет появляться все больше интересных и применимых в боевых системах моделей, основанных на похожих идеях.
Комментарии (7)

sergeyns
26.03.2019 17:36Не понял что это за желтый квадратик «класс или его остутствие» которые появляется на первой картинке и наравне со сигмоидной от скалярного произведением лезет в min. Это «target» на обучении?
anokhinn Автор
26.03.2019 18:41Да, это целевая переменная (y в уравнении). Я добавил ее на диаграммы, чтобы на них были представлены все компоненты, которые есть в уравнении.
myrov_vlad
26.03.2019 19:11Благодарю за решение!
Было интересно наблюдать как вы заняли почти на всех треках первое место.
Я сам не пробовал добавлять user_id как категориальную фичу (все-таки что-то около ~3800000 пользователей при ~16000000 постов), но пробовал добавлять пользователя как усредненный эмбеддинг постов которые он лайкнул, в результате сесть очень сильно переобучалась и вместо P(like | user, post) решал P(like | post), что, видимо, сыграло свою отрицательную роль (выше 0.64 не смог подняться).
В результате использовал классические RNN.
Сорцы решения: github.com/Vlad0922/mlboot_sna_textanokhinn Автор
26.03.2019 21:16Было интересно наблюдать как вы заняли почти на всех треках первое место.
Это не я, скорее всего вы имеете в виду Ивана Брагина.
Я сам не пробовал добавлять user_id как категориальную фичу
я сделал для топ-100к user_id собственные эмбединги, а все остальные были на одном oov-значении. При этом в моем случае добавление последовательности постов дало намного больше прирост качества, чем собственно user_id.
выше 0.64 не смог подняться
0.64 в топ-15 по этой задаче, следовательно вы прошли квалификацию на очную часть. Возможно, там увидимся.
sannikovdmitry
Грац статья!