

AWS Fault Injection Simulator (FIS) — инструмент, который позволит реализовывать заранее известные сценарии внутреннего сбоя системы внутри сервисов AWS. Зачем? — чтобы команды смогли отработать сценарии их ликвидации и в целом оценить поведение своего продукта в предложенных условиях. Система будет сразу предлагать несколько шаблонов со сценариями сбоя, например, замедление серверов, их отказ, ошибка обращения к БД или ее падение. При этом FIS будет гарантировать, что эксперимент не зайдет слишком далеко и при достижении определенных параметров тестирование будет остановлено, а работоспособность системы придет в норму. Основной слоган нового продукта облачного гиганта — «повышение отказоустойчивости и производительности с помощью технологии контролируемого хаоса». Релиз новой системы тестирования намечен на 2021 год.
Также в AWS предлагают тестирование и распределенных виртуализированных систем, которые менее зависимы от одного узла. Специфика сбоя в распределенной системе заключается в том, что проблема может быть циклична и иметь более сложную структуру. Новая функция AWS позволит искать уязвимые точки не только в инфраструктуре монолитов, но и в распределенных системах и приложениях.
Давайте посмотрим, почему это важно и круто.
Хаос-инжиниринг — это процесс симуляционного тестирования, при котором основной удар по системе происходит изнутри и затрагивает инфраструктуру проекта. Команда симулирует ситуации, в которых инфраструктурная часть проекта сталкивается с техническими и прочими неполадками, например, с точечным или системным снижением производительности на инстансах. Сюда же можно записать сбои сервера, отказы API и прочие ночные кошмары бэкэнда, с которыми команда может столкнуться в любой момент или, того хуже, в день релиза очередной версии.
Однозначного определения хаос-инжиниринга пока нет, так что приведем несколько наиболее популярных и, на наш взгляд, точных вариантов. Хаос-инжиниринг — это: «подход, предусматривающий проведение экспериментов над системой продакшена, чтобы убедиться в ее способности выдерживать различные помехи, возникающие во время работы» и «эксперимент, призванный смягчить последствия сбоев».
Зачем вообще нужен AWS Fault Injection Simulator
Разработчики инструмента называют несколько причин, по которым FIS будет полезен командам при тестировании и подготовке их систем.
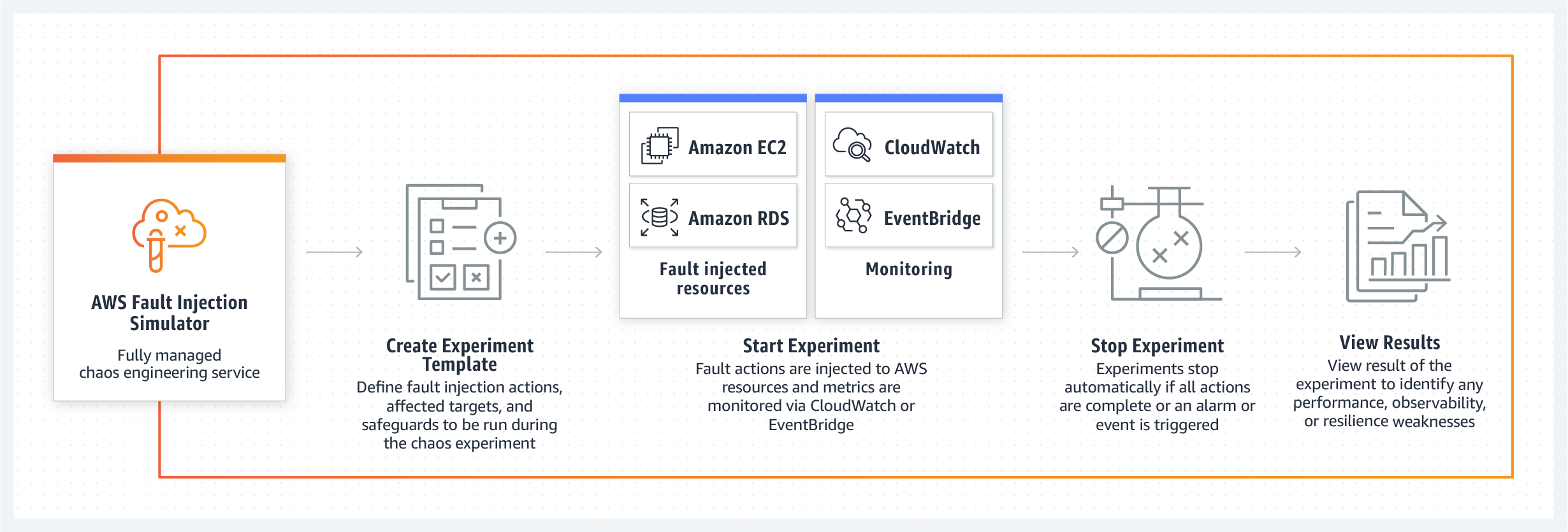
Производительность, устойчивость и прозрачность систем — один из основных тезисов команды AWS FIS.
AWS Fault Injection Simulator позволит командам легко запускать и наблюдать за своими экспериментами от начала и до конца, упростит поиск слепых зон мониторинга, узких мест в производительности или других «неизвестных» слабостей, которые не учитываются при традиционных тестах программного обеспечения.
На самом деле, привычные методы тестирования — это, в первую очередь, симуляция внешней нагрузки на систему. Например, симуляция хабраэффекта или внешней DDoS-атаки на систему или сервис. Чаще всего все основные системы мониторинга завязаны именно на эти узлы, тогда как отслеживание поведения внутренней инфраструктуры, зачастую, ограничивается только получением данных в стиле «работает/не работает» или нагрузки на ЦП. При этом наибольший ущерб и самые мощные сбои последних лет связаны именно с внутренними отказами или ошибками инфраструктуры. Достаточно вспомнить прошлогодний сбой CloudFlare, когда из-за ряда фейлов и ошибок разработчики буквально своими руками заставили «прилечь» половину интернета.
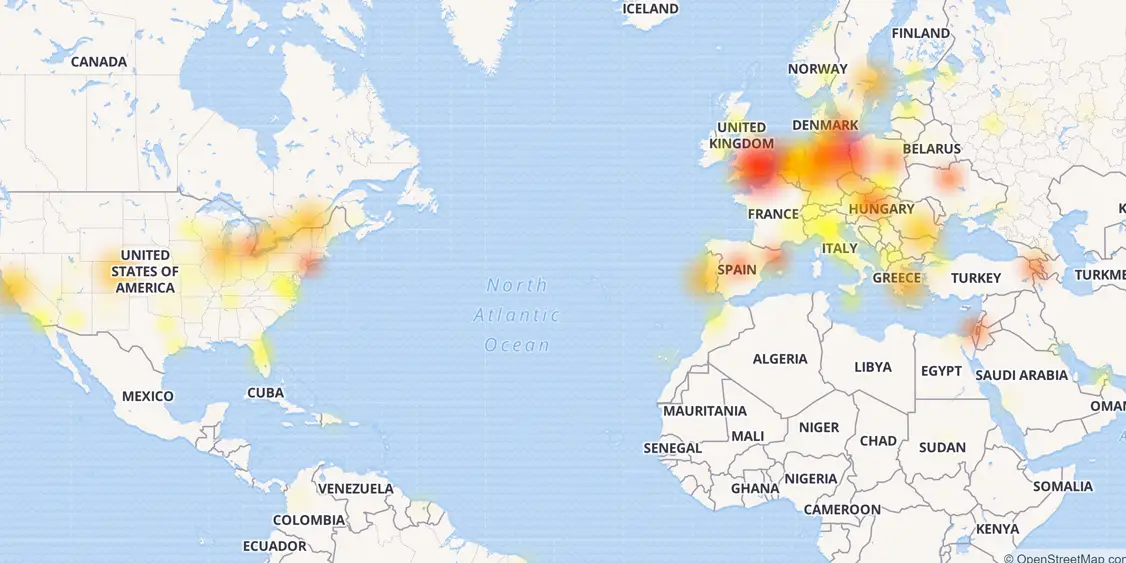
Карта того самого сбоя CloudFlare
Новый инструмент способен отработать как готовые шаблоны сценариев отказа БД, API или снижения работоспособности, так и создать рандоминизированные условия «слепого теста», при котором неполадки будут возникать в произвольной последовательности на различных узлах.
Еще одна сильная сторона нового инструментария AWS — контролируемость создаваемого командой хаоса в системе. Инженеры уверяют, что с помощью их панели управления разработчики смогут в любой момент остановить сценарий контролируемого сбоя и вернуть систему в первоначальное рабочее состояние. Fault Injection Simulator поддерживает Amazon CloudWatch и сторонние инструменты мониторинга, подключенные через Amazon EventBridge, поэтому разработчики смогут использовать свои метрики для мониторинга экспериментов по созданию управляемого хаоса. Ну и, само собой, после остановки теста администратор получит полный отчет о том, какие узлы системы и в какой последовательности были затронуты сбоем, что в дальнейшем поможет выработать комплекс мер и процедур по локализации и устранению проблем.
Как возникли Повелители Хаоса
Очевидно, что такое стресс-тестирование системы логичнее всего проводить в предрелизный период, дабы убедиться, что имеющаяся в распоряжении инфраструктура на AWS выдержит новый патч. Однако на самом деле методика хаос-инжиниринга восходит к более старым практиками, основателем которых является один из менеджеров Amazon 2000-х годов Джесси Роббинс. Его позиция официально называлась «Master of Disaster», что в пафосном переводе можно принять за «Повелителя катастроф», а в вольном его должность звучала как «Мастер-ломастер».
 Именно Роббинс — в прошлом пожарный-спасатель — внедрил в Amazon использование GameDay. Цель инициативы Роббинса была крайне проста — выработать у команд инженеров интуитивное понимание того, как бороться с катастрофой, так же, как это чувство тренируют в пожарных бригадах. Именно для этого была выбрана методика глобальной симуляции всеобщего хаоса: все ломается со всех сторон, одновременно или последовательно, а каждая попытка справиться со сбоем приводит к новым и новым проблемам.
Именно Роббинс — в прошлом пожарный-спасатель — внедрил в Amazon использование GameDay. Цель инициативы Роббинса была крайне проста — выработать у команд инженеров интуитивное понимание того, как бороться с катастрофой, так же, как это чувство тренируют в пожарных бригадах. Именно для этого была выбрана методика глобальной симуляции всеобщего хаоса: все ломается со всех сторон, одновременно или последовательно, а каждая попытка справиться со сбоем приводит к новым и новым проблемам. Когда неподготовленный человек сталкивается с буйством стихии, он, чаще всего, впадает либо в ступор, либо в панику. Большинство разработчиков и инженеров психологически не готовы к ситуации, когда решение проблемы должно занять трое суток, а уровень стресса вокруг просто зашкаливает.
Самым главным результатом GameDay Роббинс называет психологический эффект от подобных учений: они вырабатывают способность принять факт того, что масштабные сбои случаются. Именно принятие факта того, что все вокруг горит и рушится, он называет очень важным для инженера, чтобы тот мог собраться с мыслями и наконец-то приступить к «тушению пожара». Неподготовленный человек будет, в лучшем случае, бегать кругами и кричать «все пропало».
После внедрения практики GameDay выяснилось, что подобные учения прекрасно выявляют архитектурные проблемы и узкие места, на которые в ходе классического тестирования и проверок не обращают внимания.
Еще одно существенное отличие GameDay от привычных нам учений «по методичке и разнарядке» в том, что мало кто знает конкретный сценарий и что вообще будет происходить. Информация о грядущих «играх» дается весьма общая и размытая, чтобы участники не могли в полной мере подготовиться к этому мероприятию. Идеально — огласить только дату следующего «игрового дня» без вообще каких-либо уточнений, просто чтобы участники не приняли его за реальную аварию. Конечно, эта методология не масштабируется на огромную компанию, например, GameDay невозможно провести сразу по всему Яндексу или Microsoft.
Как итог, практика модернизировалась до локального GameDay и была введена во всех ныне существующих крупных IT-компаниях, например, в Google, Flickr и многих других. Там есть свои Повелители Катастроф (ну или Мастеры-Ломастеры, кому как больше нравится), которые занимаются организацией учебных сбоев и последующим анализом полученных результатов на конкретных проектах.
Основная сложность внедрения этой практики повсеместно кроется в двух аспектах: как это организовать и как собрать данные так, чтобы GameDay был проведен не зря. Именно поэтому в компаниях поменьше эта методика до недавнего времени использовалась не слишком широко (если использовалась воообще). Вместо GameDay и симуляции катастроф бизнес больше сосредоточился на различных типах тестирования, CI/CD и прочих методологиях упорядоченной и последовательной разработки. То есть на том, что предотвращает катастрофу как таковую.
Новый инструментарий AWS позволит отрабатывать другую сторону сбоев: вместо предотвращения, которое, несомненно, важно, FIS позволит инженерным командам любых размеров эффективно тренироваться в устранении глобальных инфраструктурных сбоев. Ведь главное, что отмечает Роббинс, — катастрофы случаются в любом случае: их не избежать.
propell-ant
Следовало бы написать, что это только анонс:
по ссылке aws.amazon.com/fis