
pyinstrument

При долгой работе с большим проектом так или иначе упираешься в поиск узких мест в коде. Что только программисты не используют для этого — от навороченных профайлеров и брейкпоинтов до выводов print и замеров времени выполнения вручную с выводом таймстампов на консоль.
Теперь в свой арсенал можно добавить профайлер pyinstrument. Традиционные профайлеры по шагам отслеживают выполнение программы, а pyinstrument реализуется концепцию статистического профайлинга — это когда профайлер не вмешивается в выполнение кода, а лишь записывает состояние стека вызова с определенной периодичностью.
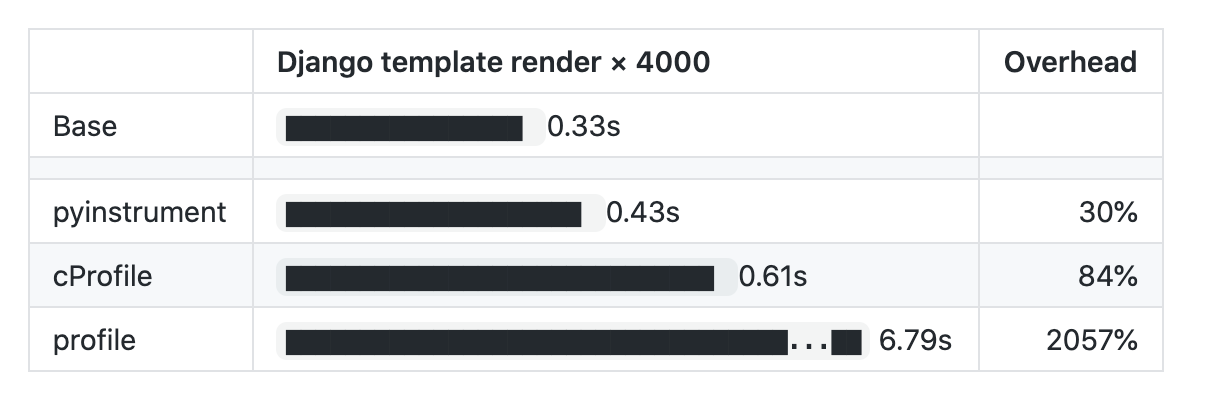
Такой подход снижает тормоза при профилировании программы. Видно, что оверхед на статистическое профилирование несравнимо меньше, чем при применении стандартных профайлеров.
Пользоваться профайлерм просто — он встраивается напрямую в код. Можно отпрофилировать лишь участок кода, нет нужды смотреть весь стек вызовов.
from pyinstrument import Profiler
profiler = Profiler()
profiler.start()
# Ваш код для профилирования
profiler.stop()
print(profiler.output_text(unicode=True, color=True))В документации предлагается решение для профилирования запросов API в веб приложениях.
from flask import Flask, g, make_response, request
app = Flask(__name__)
@app.before_request
def before_request():
if "profile" in request.args:
g.profiler = Profiler()
g.profiler.start()
@app.after_request
def after_request(response):
if not hasattr(g, "profiler"):
return response
g.profiler.stop()
output_html = g.profiler.output_html()
return make_response(output_html)Mimesis

Когда программисты пишут базовые тесты для своего кода, в приложении появляются пользователи с именем qwerty, фамилией asdf и живущие в городе zxcv. Оно и понятно — надо писать код, а не сидеть и придумывать имена тестовым юзерам. Но у действительно крутых спецов даже тесты выглядят аккуратно и с вниманием к деталям. А самые крутые из крутых используют генераторы реалистичных тестовых данных.
Mimesis генерирует реалистичные тестовые данные для имен, фамилий, емейлов и прочих полей, над генерацией значений для которых обычно нет времени думать.
>>> from mimesis import Person
>>> person = Person('en')
>>> person.full_name()
'Brande Sears'
>>> person.email(domains=['mimesis.name'])
'roccelline1878@mimesis.name'
>>> person.email(domains=['mimesis.name'], unique=True)
'f272a05d39ec46fdac5be4ac7be45f3f@mimesis.name'
>>> person.telephone(mask='1-4##-8##-5##3')
'1-436-896-5213Есть поддержка генерации фейковых данных для разных локалей.
>>> from mimesis import Person
>>> from mimesis.enums import Gender
>>> de = Person('de')
>>> en = Person('en')
>>> de.full_name(gender=Gender.FEMALE)
'Sabrina Gutermuth'
>>> en.full_name(gender=Gender.MALE)
'Layne Gallagher'kb
Чтобы вести успешную профессиональную деятельность в ИТ, недостаточно каждый день приходить на работу и писать код. Нужно еще и учиться. Алгоритмы, новые архитектурные решения, полезные библиотеки и приемы написания кода — все это приходиться изучать и запоминать. Большинство из известных мне успешных инженеров в том или ином формате ведет свою базу знаний с конспектами статей, ссылками и сниппетами кода.
В большинстве случаев это специализированный софт для ведения заметок или репозитории с чем-то типа markdown внутри.
А сейчас мы посмотрим инструмент для хадкорных тру инженеров. kb — консольная база знаний, написанная на Python.

Работает 100% из консоли. Можно, например, запустить на сервере.
Есть экспорт и импорт, можно хранить данные в своем репозитории.
Можно хранить двоичные данные — pdf, картинки, книги.
Есть все фичи хорошей базы знаний — теги, категории, шаблоны заметок, поиск.
Исходники системы — интересное чтение. Весь консольный UX реализован авторами самостоятельно, из зависимостей они используют только colored для удобства вывода цветных строк в консоль и парсеры атрибутов.
На сегодня все, прошлые питонячие радости смотрите по ссылке.
eumorozov
Для генерации имён и т.п. давно существует faker. Кстати, не только для Python, но и для кучи других языков, включая Rust.
А вот это:
Пример ярой нетолерантности и шовинизма. Как можно?! В юникод уже даже ввели эмодзи "бородатая женщина", а тут какой-то прошлый век!