
Привет, Хабр!
На связи команда Datalore by JetBrains. Хотим поделиться с вами результатами анализа нескольких миллионов публично доступных репозиториев Github с Jupyter-ноутбуками. Мы скачали ноутбуки, чтобы немного больше узнать в цифрах о текущем статусе, пожалуй, самого популярного инструмента для data science.

Вдохновившись исследованием, проведенным командой Design Lab из UC San Diego, мы дважды скачали Jupyter-ноутбуки: в октябре 2019 и в октябре 2020.
Два года назад в открытом доступе было 1,23 миллиона ноутбуков. В октябре 2020 года число ноутбуков выросло в 8 раз, и мы смогли скачать 9,72 миллиона файлов. Этот датасет мы сделали публичным — инструкцию по скачиванию можно найти в конце поста.
Все цифры и графики были подсчитаны в этом Datalore ноутбуке. Datalore — это онлайн Jupyter-ноутбуки с умной поддержкой кода, которые мы делаем в JetBrains. Вы можете создать копию ноутбука, перейдя по ссылке, и работать с данными в Datalore.
Мы будем рады, если вы захотите поработать с данными и провести собственный анализ. Делитесь с нами результатами, отмечая в Твиттере @JBDatalore или написав нам на contact@datalore.jetbrains.com.
Теперь перейдем к цифрам.
Язык data science
Несмотря на большой рост популярности R и Julia в последние годы, Python остается лидирующим программным языком для Jupyter-ноутбуков.
Помимо этого встречаются ноутбуки, написанные на Bash, MatLab и Scilab, а также на языках, с которыми ноутбуки ассоциируются, пожалуй, в последнюю очередь: Scala, C++ и Java.
На графике можно посмотреть распределение языков программирования в ноутбуках. Ноутбуки, язык которых не был указан в метаданных, относятся к категории “nan”.

В табличке можно увидеть разницу в процентах использования Python 2 и Python 3 в ноутбуках в 2018, 2019 и 2020 годах.
Python 2 | Python 3 | Other languages | |
Исследование 2018 | 52,5% | 43,8% | 3,7% |
Исследование 2019 (JetBrains Datalore) | 18,1% (всего 1029 K) | 72,6% (всего 4128 K) | 9,3% (всего 529 K) |
Исследование 2020 (JetBrains Datalore) | 11,8% (всего 1154 K, +125 K к 2019) | 79,3% (всего 7710 K, +3582 K к 2019) | 10,8% (всего 1050 K, +521 K к 2019) |
Количество ноутбуков, написанных на Python 3, увеличилось с 2019 года на 87%, а количество ноутбуков с Python 2 — на 12%.
На графике ниже можно увидеть распределение количества ноутбуков, написанных на Python и R, по версиям языков:

Топ библиотек data science
Чтобы помочь пользователям Datalore начать работу с ноутбуками как можно быстрее, мы предустановили самые используемые Python-библиотеки. Для этого мы посчитали статистику импортов в скачанных Jupyter-ноутбуках.
Не оказалось неожиданностью, что 60% ноутбуков содержат в списке зависимостей Numpy, 47% импортируют Pandas и Matplotlib.
Более подробную информацию можно увидеть на графике:
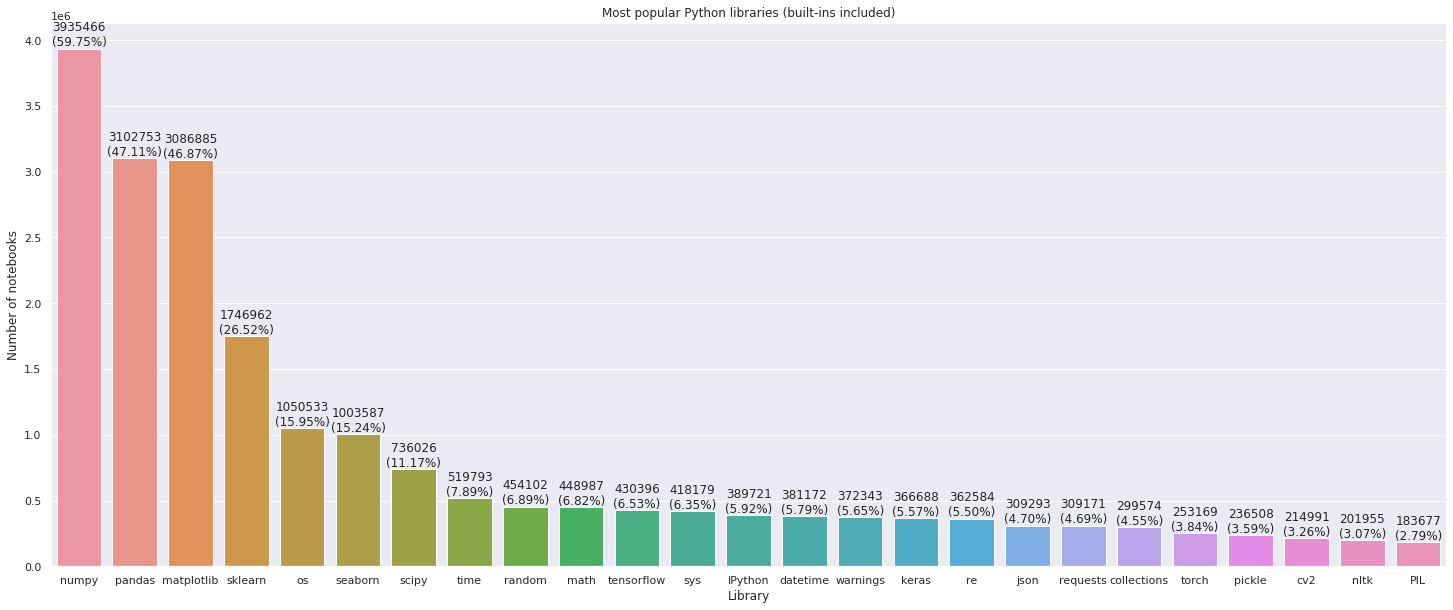
Самые популярные комбинации библиотек:

Рост PyTorch и TensorFlow
Члены нашей команды интересуются библиотеками для глубинного обучения, и мы решили сравнить рост библиотек PyTorch и TensorFlow.
Из таблицы ниже можно увидеть, что число импортов у PyTorch растет значительно быстрее, чем у TensorFlow.
В то же время нужно учитывать, что библиотека Keras может использовать TensorFlow в качестве транзитивной зависимости, а Fast.ai использует PyTorch в качестве зависимости. Это означает, что скорость роста TensorFlow, вероятно, выше, но мы не можем говорить с уверенностью, какая из библиотек больше использовалась в последние годы.
TensorFlow | Keras | PyTorch | Fastai | |
Исследование 2019 (JetBrains Datalore) | 321 K | 231 K | 110 K | 19 K |
Исследование 2020 (JetBrains Datalore) | 430 K (+34%) | 367 K(+59%) | 253 K(+130%) | 25 K(+32%) |
Содержание ячеек в ноутбуках
Немного общих цифр относительно ячеек (данные подсчитаны для ноутбуков, написанных на Python 3.6 и выше):
71,90% ноутбуков содержат Markdown.
42,13% ноутбуков содержат графики или картинки в output.
12,34% ноутбуков содержат LaTex.
19,77% ноутбуков содержат HTML.
20,63% ноутбуков содержат код внутри Markdown.
Markdown очень широко используется в Jupyter-ноутбуках. 50% ноутбуков содержат более 4 ячеек Markdown и более 14 ячеек кода.
Графики ниже показывают распределения Markdown-ячеек и ячеек с кодом:


На графике ниже можно увидеть распределение количества строк кода. Хотя существуют отдельные экземпляры ноутбуков, имеющие более 25 000 строк кода, 95% ноутбуков содержат менее 465 строк:

Использование графиков тоже популярно. Выше мы упоминали, что 42% ноутбуков содержат визуализации. 10% этих ноутбуков содержат более 8 изображений.

Воспроизводимость Jupyter-ноутбуков
Для Jupyter-ноутбуков существует проблема — не всегда готовый ноутбук можно воспроизвести. Зачастую это означает, что ячейки были выполнены автором не в прямой последовательности. Мы проверили порядок выполнения ячеек кода всех доступных Jupyter-ноутбуков и выяснили, что 36% Jupyter-ноутбуков выполнены в нелинейном порядке, т. е. при исполнении кода линейно результат выполнения может отличаться.
Мы стали смотреть детальнее, зависит ли порядок выполнения кода в ноутбуке от количества Markdown-ячеек и ячеек кода. Не удивительно, но оказалось, что, чем меньше ячеек кода в ноутбуке, тем больше вероятность, что код выполнен в линейном порядке.

Количество Jupyter-ноутбуков невероятно выросло за последние годы, и в этом исследовании мы постарались побольше узнать об этом очень популярном инструменте работы над задачами data science.
Мы надеемся, что статья была для вас интересной и вдохновила на дальнейший анализ. Посмотреть, как мы получили графики и цифры, можно в этом Datalore-ноутбуке.
Ссылки
Предыдущее исследование 2018 года
Ноутбук в Datalore с предобработанными данными
Инструкция по получению доступа к данным:
Скачайте оригинальный датасет:
Ссылка для скачивания исходных данных из бакета (10 млн файлов, 4,4 ТБ): https://github-notebooks-update1.s3-eu-west-1.amazonaws.com/
Получение списка файлов c помощью AWS S3 API может занять время, поэтому воспользуйтесь этим JSON со всеми именами файлов: https://github-notebooks-samples.s3-eu-west-1.amazonaws.com/ntbslist.json
Добавьте имя файла из JSON к адресу бакета, чтобы получить прямую ссылку, например: https://github-notebooks-update1.s3-eu-west-1.amazonaws.com/0000036466ae1fe8f89eada0a7e55faa1773e7ed.ipynb
Или воспользуйтесь предобработанными данными из исследования (3 ГБ). Файлы доступны в этом Datalore-ноутбуке.






Cost_Estimator
Вопрос от человека, изучающего Data Science на курсере. Что почистили, чтобы объем датасета упал с 4.4тб до 3гб? Можно в виде алгоритма?
alenaguzharina Автор
Мы выделили фичи, которые хотим исследовать. Например, посчитали количество ячеек кода в каждом ноутбуке, выделили импорты, вычислили количество графиков. В итоге получили файлы с фичами, а сами .ipynb файлы исключили из датасета
demon416nds
Почёму бы не перевести как блокнот?
Это в русском языке куда ближе к исходному смыслу и уж точно не так режет глаза.
alenaguzharina Автор
Получили много таких комментариев, учтем на будущее, спасибо! Исходили из того что в гугле по запросу «Jupyter ноутбук» больше поисковых запросов, чем «Jupyter блокнот». Поэтому решили, что «ноутбук» чаще употребляется и использовали такой перевод.