
Предисловие
Я изучаю PostgreSQL дома и очень люблю обрабатывать большое количество данных. Пишу на ЯП C/C++ на Qt фреймворке. К сожалению Qt драйвер для постреса не поддерживает функционал, необходимый для быстрой загрузки. Поэтому я написал свою библиотеку на С++ для этого, а теперь хочу с Вами поделиться этим прекрасным методом добавления и самой библиотекой.
Привет, $username !
Сегодня пойдёт речь о быстрой загрузке данных в СУБД PostgreSQL ( далее `постик` ). Делать мы это будем через механизм COPY с передачей данных по сети в бинарном формате.
Первым делом рассмотрим плюсы данной методики добавления:
Очень большая скорость добавления
Всё обуславливается тем, что мы на минимум снимаем потребность в обработке данных ( разные преобразования ), постику остаётся только проверять, правильный ли мы используем формат.
Не теряем данные, в отличии от текстового формата.
Например, как это может произойти с double числом. Нам не нужно будет в этом методе выяснять, сколько знаков до и после запятой. Данные передаются `как есть`.
В данном посте я не буду раскрывать все подробности, которые описаны в документации. Мы просто напишем лёгкий метод добавления, т.е. без специфик и прочего. Все функции, которые будут вызываться в коде — это функции из библиотеки “libpq-fe.h”. Так-же весь код будет писаться на С/С++.
Алгоритм создания бинарного буфера
Структура буфера:
[шапка начала буфера]
{строка данных}
{строка данных}
{строка данных}
. . .
{строка данных}
[шапка конца буфера]
Шапка начала буфера
Шапка начала буфера состоит из следующей последовательности байт:
Сигнатура COPY-буфера
'P','G','C','O','P','Y','\n','\377','\r','\n','\0'Поле флагов
'\0','\0','\0','\0'В случае, если мы включаем в данные OID – выставляем 16-й бит в 1
Длина области расширения заголовка
'\0','\0','\0','\0'В настоящее время заголовок не используется, а длина их должна быть равна нулю. Сделано это для того, чтобы в будущем не было проблем с совместимостью буферов.
Расширение заголовка
Поскольку в текущих версиях этого расширения нет ( на данный момент 13.1 последняя версия ), то ничего и не пишем.
Строка данных
Строка данных состоит из:
Длина записи
Это int16_t число, указывающее, сколько столбцов будет добавляется в текущем столбце. На данное время это число постоянно одно и то же, в будущем, возможно, будут изменения.
После этого следует указанное количество данных о столбцах:
1) Длина данных
Указываем, сколько байт занимают данные, которые нужно добавить в текущий столбец
2) Непосредственно сами данные
Хотелось бы тут заметить, что разные типы данных могут добавляются совсем по другому:
Например массивы.
Чтобы добавить массив int64_t нужно вставлять не просто данные, а их сигнатуру. ( там идёт своя шапка данных и описание массива ). К сожалению, описание добавления для каждого типа не описано в док-ции постреса. Поэтому, чтобы узнать сигнатуру массива надо или смотреть в исходники или создавать дамп через COPY TOи уже оттуда смотреть, что и как лежит.
Шапка конца буфера
0xff, 0xffДля дополнительной синхронизации передачи буфер необходимо закрыть. Таким образом, когда постик будет просматривать новую длину строки данных — увидит, что достигнут конец буфера (ну данные ведь не могут быть длинной -1).
Алгоритм добавления данных
Для того, чтобы подключиться к серверу — создадим подключение
string conninfo =
"host=127.0.0.1 port=5432 dbname=postgres user=postgres password=postgres connect_timeout=10";
PGconn *conn = PQconnectdb(conninfo.c_str());
// conninfo - это срока параметрами подключения ( connect_timeout измеряется в секундах )
Подготовим COPY-запрос
pg_result *res = PQexec(conn, cquery);в качестве cquery у нас выступает COPY запрос. В моём примере это COPY testtable5 ( col1, col2, col3, col4 ) FROM STDIN (format binary);
Добавим буфер
PQputCopyData(conn, buf, currentSize);, где buf – указатель на буфер, currentSize — длина буфера в байтах.
Очень важно то, что буфер можно передавать частями. Это очень удобно. Я лично использую буферы по 2-128 Мб.
Скажем серверу, что это конец данных
PQputCopyEnd(conn, NULL);Очень важно!
Все данные должны передаваться в сетевом формате.
Что это значит? Например, int16_t tmp = 2; На самом деле в оперативке данные будут лежать так: 0x02, 0x00 А не так как мы привыкли 0x00, 0x02. Это связано с архитектурой процессора. Процессоры архитектуры SPARC хранят данные уже в сетевом формате. Поэтому, если у вас не SPARC-архитектура, нужно все байты вставлять в буфер задом на перёд ( за исключением строк )
Немного графиков
Я сделал вторую программу для добавления в БД строк данных.
Написано это было на Qt:
db.open();
QSqlQuery query(db);
query.prepare("insert into testtable5 ( col1, col2, col3, col4 ) values (?,?,?,?);");
for(int i=0; i<20000000; i++)
{
query.addBindValue("column1");
query.addBindValue(double(12983712987.4383453947384734853872837));
query.addBindValue(int(12345678));
query.addBindValue(float(123.4567));
query.exec();
}Нижеприведённые графики будут показывать время добавления ( в мс ) следующих 10.000 данных - по оси Y, кол-во добавленных данных - по оси X.
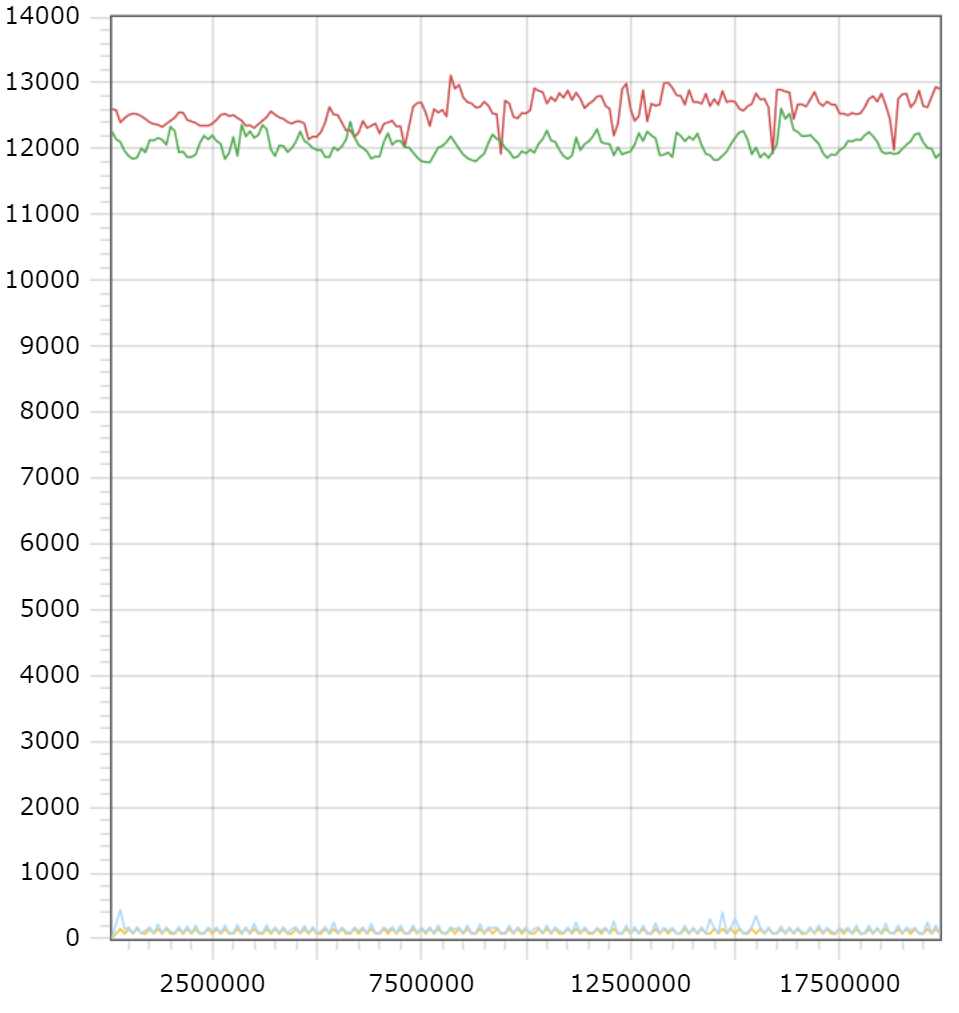
Сравнительный график скорости работы COPY и INSERT запросов.
Красным - INSERT-вставка в постоянную таблицу.
Зелёный - INSERT-вставка во временную таблицу.
Синий- COPY-вставка в постоянную таблицу.
Жёлтый - COPY-вставка во временную таблицу.
Сравнительный график скорости работы INSERT запросов.
Жёлтый - INSERT-вставка в постоянную таблицу.
Синий- INSERT-вставка во временную таблицу.

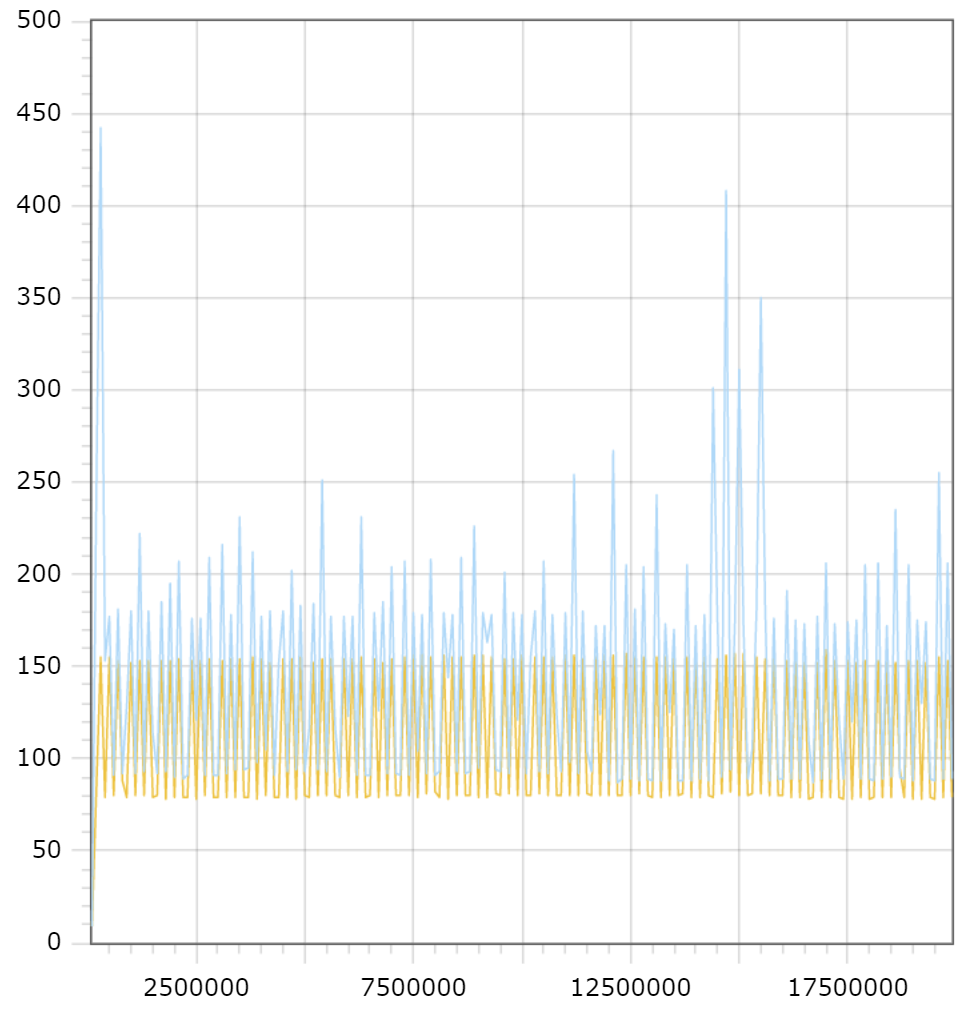
Сравнительный график скорости работы COPY запросов.
Синий- COPY-вставка в постоянную таблицу.
Жёлтый - COPY-вставка во временную таблицу.
Немного расчётов
Давайте посмотрим на графики и попробуем найти средние показатели добавления.
Вот что у меня получается:
Чтобы добавить порцию из 10.000 данных ( строк ), мне требуется:
12.620 мс на добавление в постоянную таблицу при помощи INSERT
12.050 мс на добавление во временную таблицу при помощи INSERT
150 мс на добавление в постоянную таблицу при помощи COPY
120 мс на добавление во временную таблицу при помощи COPY
Тут хотелось бы остановиться сразу и сказать... Что я не смог замерить время коммита запроса COPY. Думаю, оно не сильно будет играть роль.
Исходный код
Поскольку библиотеку я писал в основном под свои нужды — она имеет ограниченный функционал. В будущем, надеюсь, что мне удастся довести библиотеку до того уровня, чтобы каждый мог использовать её в своих продуктах.
Ссылка на документацию по использованию COPY
P.S.: это мой первый пост, прошу меня простить за кривизну моих рук.
Хотелось бы услышать хороших комментариев и конструктивной критики.


ky0
«Постик» [x]
Серьёзно? :)
miruzzy Автор
ну а почему-бы и нет ?)
Когда я начинал учить SQL — мой 'учитель' сказал, чтобы я начинал с 'постика'. Вот так и прижилось название
ky0
«С постика на компуктере», что ли? :)