
Если вы используете OllyDbg не для отладки собственных приложений, для которых у вас есть отладочная информация, а для реверс-инжиниринга или исследования сторонних, типичная ваша деятельность — это вникание в машинный код чужого продукта, осознание сути происходящих вещей и расстановка большого числа меток (labels) и комментариев по всему коду, а также по секциям данных. Вы планомерно разведываете суть процедур/функций и переменных и даёте им имена, отражающие ваше понимание их предназначения.

И вот спустя несколько часов (а то и дней) работы, когда вы разобрались и подписали сотни, а то и тысячи процедур и переменных, OllyDbg внезапно зависает или вылетает, унося в небытие все ваши наработки (в которые могут входить не только labels и comments в большом числе, но и расставленные в нужных местах брекпоинты и модификации). Это потеря времени и чудовищно демотивирующий фактор, от которого опускаются руки и бледнеет лицо.
Эта статья о том, как я в такой экстренной ситуации использовал OllyDbg для того, чтобы оперативно разреверсить OllyDbg (частично), спасти висящие на волоске данные и выработать рецепт действий на случай таких катастроф.
Раз уж вы продолжили читать статью, давайте с самого начала договоримся о некоторых вещах:
- Эта статья относится к OllyDbg 1.xx, но не OllyDbg 2.xx, хотя очень поверхностный взгляд на дизасм кода последней свидетельствует о том, что аспекты организация хранения в ней интересующих нас данных в какой-то мере похожи на то, как это сделано в линейке версий 1.xx (что и обозревается в этой статье).
- Если у вас прямо сейчас завис OllyDbg или вылетел с ошибкой, и вы не знаете, что делать, т.е. если вы находитесь в «экстренной ситуации» — можете сразу перейти к разделу «Методика спасения данных», пропустив длительное вступление, обзор альтернативных методов и описание процесса анализа исполняемого кода, результатом которого стала предлагаемая методика, снабжённое также размышлениями о найденных в процессе анализа недостатках и багах кода OllyDbg. В ином случае лучше читать статью последовательно, но даже в этом случае будьте осторожны, раскрывая спойлеры — вас может затянуть в кроличью нору.
- Автор прекрасно знает об IDA Pro и других инструментах, но предпочитает OllyDbg для прикладных приложений. Не стоит под статьёй о ремонте Audi писать «а я езжу на BMW» и устраивать холивары. В конце концов лучший инструмент — тот, которым ты владеешь в совершенстве.
- Я некоторое время колебался по поводу того, писать ли эту статью. Она написана «по горячим следам» и на основе личного опыта. Но раз уж на хабре публикуются howto-статьи на тему того, как проксировать трафик через SSH, хотя это абсолютно документированная возможность, то почему методика спасения данных, полагающаяся на нигде не освещённые знания, не заслуживает внимания? Кстати, я вдохновлялся статьёй «Жизнь после BSOD» покойного Криса Касперски — очень интересная статья, если режим ядра для вас не тёмный лес, рекомендую. Поехали?
Я буду использовать слово «наработки» для того, чтобы обобщённо называть всё то, что вы расставляете в отладчике, перемещаясь по коду, и всё то, что обычно бывает болезненно потерять. А именно:
- Метки (Labels) — OllyDbg даёт вам возможность ставить метки в произвольных местах, например, чтобы подписать безымянную процедуру или переменную.
- Комментарии (Comments) — любому месту в образе исполняемого файла можно присоединить комментарий.
- Точки останова (Breakpoints) — в пояснении не нуждаются.
- Подсказки по анализу (Hints) — можете указать OllyDbg, к примеру, что вот эти 4 байта нужно отображать не как 4 отдельных байта, а как один DWORD.
Больше всего, конечно, меня волнуют именно метки и комментарии, потому что в брекпоинтах кроется не так много уникальной и сложновосполнимой в случае утраты информации. Если вы потеряли десяток важных брекпоинтов, но у вас все процедуры как следует подписаны и код внутри процедур щедро откомментирован, то обычно не составляет труда найти нужные места и установить брекпоинты заново. А вот ориентироваться в бинарнике, в котором не подписано ничего, полагаясь лишь на адреса, сможет только законченный гений и уникум — обычному же человеку крайне важно и полезно иметь человеко-понятные подписи и имена.
Кстати говоря, забегая вперёд, скажу, что подобные сущности, то есть пары {адрес в отлаживаемом процессе > текстовое значение} обобщённо в рамках самого отладчика OllyDbg обозначаются термином names. Набор их типов не ограничивается четырьмя вышеперечисленными.
- NM_LABEL — User-defined label
- NM_EXPORT — Exported (global) name
- NM_IMPORT — Imported name
- NM_LIBRARY — Name extracted from library, object file or debug data
- NM_CONST — User-defined constant (currently not implemented)
- NM_COMMENT — User-defined comment
- NM_LIBCOMM — Automatically generated comment from library or object file
- NM_BREAK — Condition related with breakpoint
- NM_ARG — Arguments decoded by analyser
- NM_ANALYSE — Comment added by analyser
- NM_BREAKEXPR — Expression related with breakpoint
- NM_BREAKEXPL — Explanation related with breakpoint
- NM_ASSUME — Assume function with known arguments
- NM_STRUCT — Code structure decoded by analyzer
- NM_CASE — Case description decoded by analyzer
- NM_PLUGCMD — Plugin commands to execute at breakpoint
- NM_INSPECT — Several last entered inspect expressions
- NM_WATCH — Watch expressions
Все эти сущности при штатном завершении отладчика заботливо сохраняются в специальный файл (с расширением .udd), а при последующем открытии бинарника под отладчиком — загружаются. Поэтому если вы расставили несколько меток, установили сколько-то брекпоинтов и закрыли отладчик, а затем заново открыли под отладчиком то, над чем вы работали, все ваши метки и брекпоинты (как и всё остальное) будут на месте. Каждому модулю, загруженному в адресное пространство отлаживаемого процесса, соответствует свой UDD-файл, так что метки внутри supercool.dll, которую использовал foo.exe, будут видны и при отладке bar.exe, если он тоже использует supercool.dll.
Пути потери данных
К сожалению, при всех своих достоинствах, OllyDbg имеет и большое число недостатков и недоработок (истинный масштаб которых открывается только по мере обретения большого стажа работы с этим отладчиком). К ним относится и склонность OllyDbg терять все те наработки, которые пользователь делает в процессе отладки.
Почему данные теряются, если всё сохраняется в UDD-файлы? Во-первых, часть всех невзгод проистекает из того, что сохранение в UDD-файл происходит только при завершении отладочной сессии, то есть при закрытии отладчика или переход на отладку совершенно другого процесса. Нет никакого автосохранения ваших отладочных данных в UDD с заданной периодичностью. В меню нет никакого пункта «Save everything to UDD». Есть запрятанный подальше пункт «Update .udd file now» — он находится в контекстном меню списка загруженных модулей (EXE/DLL/OCX) и сбрасывает на диск данные только для одного выбранного модуля. Не все знают про этот пункт, и не у всех хватит дисциплины и терпения регулярно заходить в окно Modules и прощёлкивать этот пункт у каждого из модулей, для которых что-то должно быть сохранено. Поэтому при нештатном завершении отладчика всё, что не было сохранено в UDD, будет потеряно. Если вы начали с чистого листа и 20 часов реверсили какой-то бинарник, не сбрасывая результат в UDD принудительно и не закрывая отладчик, вы рискуете потерять абсолютно всё и начинать опять с чистого листа. Во-вторых, есть пара других сценариев развития катастрофы.
Я выделяю 4 основных пути потери данных:
- Нештатное завершение — внешние причины. Сюда относятся BSOD или пропадание электропитания. Эти случаи за рамками рассмотрения данной статьи.
- Нештатное завершение — внезапный вылет. Необработанное исключение, возникшее уже не в отлаживаемом приложении, а в самом отладчике, ведёт к появлению печально известного диалога, в котором вам предлагается выбор между одинаково фатальными «Отправить отчёт» и «Не отправлять отчёт». Но если у вас в системе установлен отладчик (а иначе зачем вы читаете эту статью?), то выбор предстаёт уже между завершением процесса и возможностью присоединиться к умирающему процессу с помощью отладчика и попыткой исправить ситуацию. О перспективах такой возможности будет сказано далее. На самом деле, хоть такое и случается с OllyDbg, но случается сравнительно редко, и виноват в этом чаще всего какой-то плагин, а не сам отладчик.
- Зависание и последующее принудительное завершение. Гораздо чаще OllyDbg любит в некоторый момент просто намертво зависнуть. Здесь нет как такового нештатного завершения, но вы сами убьёте процесс OllyDbg.exe, когда вам надоест ждать. Хотя ждать иногда имеет смысл: мне известен случай, когда OllyDbg самостоятельно «отвис» спустя 27 часов после зависания. С этой ситуацией тоже можно побороться, как и с предыдущей. Кстати, чаще всего в подобных случаях виновником зависания является не сам OllyDbg, а deadlock где-то в ядре Windows, на возникновение которого наличие активно работающего отладчика как-то благотворно влияет (точную причинно-следственную связь я не брался устанавливать). В иных случаях виноват сторонний процесс, например Microsoft-овская утилита Spy++, позволяющая смотреть «внутреннее устройство» окон и обмен оконными сообщениями, для чего Spy++ внедряет во все GUI-процессы собственную DLL, которая и отвечает за перехват оконных сообщений. Если что-то в этом механизме перехвата ломается, зависают все GUI-приложения. Формально они не зависают, а лишь перестают реагировать на оконные сообщения, что для обычного пользователя эквивалентно зависанию. Консольные приложения при этом единственные остаются на плаву.
- Помимо этого OllyDbg любит просто портить UDD-файлы, причём делать это тихо и незаметно. В некоторых случаях при сохранении в UDD-файл происходит сбой, и об этом OllyDbg никак не сигнализирует. Например, на диске может банально кончиться место. При следующем запуске OllyDbg попытается прочитать файл, но не сможет, потому что он окажется битым — в этом случае все данные из файла будут отброшены, отладчик начнёт как бы с чистого листа, при закрытии отладчика будет записан новый UDD-файл, в котором всех ваших наработок уже не будет. В других случаях файл сохраняется нормально, но возникает какая-то проблема при загрузке нормально записанного файла. Всё это происходит молча, OllyDbg не загружает данные из UDD, но при штатном завершении записывает вместо него пустой UDD-файл. Наконец, поскольку UDD-файлы идентифицируются по имени модуля, а не по хешу, возможно, что под отладчиком окажется модуль, чьё имя конфликтует с одноимёнными модулями. Типичный пример — много разных версий одной и той же DLL. В этом случае OllyDbg «подцепит» неподходящий UDD-файл, и либо его контент будет отброшен по причине того, что это откровенно неподходящий UDD-файл, либо прогон анализатора сгенерирует иные сущности, которые наложатся на сущности из неподходящего UDD-файла. Бороться с этим можно только регулярными бэкапами директории для UDD-файлов.
Специальный плагин и способы спасти данные
Прежде чем описать тот способ выхода из положения, которому, собственно, и посвящается эта статья, я хочу опять сделать небольшое отступление и рассказать про специальный плагин, который имеет прямое отношение к вопросу сохранения наработок, и который я нестандартно использовал для спасения данных вплоть до последнего момента, когда мне пришлось найти более прямолинейный и агрессивный способ (т.к. прежний способ не подходил — причины будут описаны далее).
UDD — бинарный формат. Я очень люблю и, как правило, всегда предпочитаю бинарные форматы хранения данных текстовым. Они эффективнее по обработке, они компактнее по хранению и передачи. Но этот случай явно относится к числу исключений.
В данном случае проблема бинарных UDD в двух аспектах:
- Бинарные файлы плохо поддаются версионному контролю. Да, всеми любимый git (которым и я пользуюсь) с лёгкостью может помещать бинарные файлы под версионный контроль (потому что он хранит слепки состояний, а не диффы между состояниями). Но посмотреть diff между двумя ревизиями или найти ревизию, в которой сделано конкретное изменение в случае с бинарными файлами почти что нельзя (да, я знаю о custom diff в git). А уж вести две параллельные ветки работы над объектом, а потом делать merge между результатами этих параллельных разработок в случае с бинарным объектом — невозможно.
- Бинарный файл гораздо сложнее починить вручную, если он сохранился с повреждениями или повредился после сохранения, нежели текстовый. Особенно учитывая то, что формат UDD официально не документирован.
Я уже много лет занимаюсь реверс-инжинирингом и работал в том числе и над довольно большими продуктами, где число процедур измеряется десятками тысяч. Где реверс-инжиниринг целесообразно делать не в одиночку, а командой, в которой каждый член группы начинает распутывать клубок машинного кода каждый со своего конца. В таком случае очень полезно результат реверс-инжиниринга (первичные данные — те самые метки и комментарии, расставляемые в дизассемблере, а также вторичную документацию, которую пишут вручную на основе осмысления разведанного, часто включающую в себя псевдокод, прототипы функций, и т.п.) сохранять в какой-то человеко-читаемый формат и держать под версионным контролем.
При командном реверс-инжиниринге это позволяет использовать VCS типа Git для того, чтобы обмениваться результатами обратной разработки и объединять результаты в единое целое. Типичный пример: один человек начал реверсинг с одной отправной точки (например из процедуры WinMain()), другой — совершенно с другого конца (например из процедуры, сообщающей об ошибке). В процессе работы они неизбежно будут натыкаться на общие процедуры и переменные, но делать это независимо, и каждый из них будет давать одни и тем же процедурам не всегда одинаковые имена. Например, оба будут почти гарантированно натыкаться на статически влинкованные функции стандартной библиотеки (типа memcpy, strncat, qsort в случае стандартной библиотеки Си). Когда результат реверсинга подвергнут версионному контролю, и каждый работает в своей ветке, последующее слияние веток и разрешение закономерно возникающего конфликта слияния (merge conflict), позволит придти к общей терминологии и общему виденью того, как устроен изучаемый бинарник. Частые синхронизации своего репозитория с коллективным позволит меньше и реже «открывать Америку», которую раньше тебя успели разреверсить твои коллеги.
Кроме того, если кто-то в какой-то момент пошёл по неправильному пути и, исходя из неправильных предпосылок, построил частично неправильную картину того, как «устроен мир», при наличии версионного контроля и истории развития репозитория всегда можно вычислить, в какой момент ошибочная теория стала частью «картины мира», и внести исправления. Например, то, что длительное время кто-то принимал за отдельную глобальную переменную, может оказаться на деле полем экземпляра класса, размещённого статически (как глобальная переменная, в противоположность размещению на куче с помощью оператора new).
В общем, использование систем контроля версий при реверс-инжиниринге софта (а особенно больших продуктов) и помещение под версионный контроль документа, содержащего сопоставление адресов исследуемого бинарника и импровизированных названий, присвоенных реверсером тем функциям и переменным, которые он разведал, очень давно казалось мне превосходной идеей.
Кстати, я также на правах хобби занимаюсь сочинением музыки, и идея помещать под версионный контроль музыкальные проекты тоже не даёт мне покоя, но используемый мною DAW сохраняет проекты только в бинарном формате. Типичный случай: исходно-одна композиция существует в виде 5—6 версий, начавшихся от общего предка, но со временем сильно разошедшихся в звучании, концепции, оформлении, стилистике. Было бы здорово сделать merge, взяв от одной ветки наиболее партию баса, получившуюся наиболее удачно именно в этой ветке, а от другой — удачные параметры VST-эффектов на каналах микшера, от третьей — что-то ещё. Или просто выяснить, почему предыдущая версия, хоть и была короче, но звучала лучше, сделав простой git diff, а не перебирая и не сверяя все параметры всех VST-инструментов и VST-эффектов между старой и новой версией файла-проекта.
Но поскольку UDD-файлы не могут служить таким документом из-за того, что это не текстовые файлы, достаточно давно я сделал собственный плагин для OllyDbg, позволяющий экспортировать все наработки (расставленные метки (имена функций, переменных) и комментарии) в текстовый файл (своеобразный дамп), структура и синтаксис которого оптимизированы для работы с системами контроля версий.
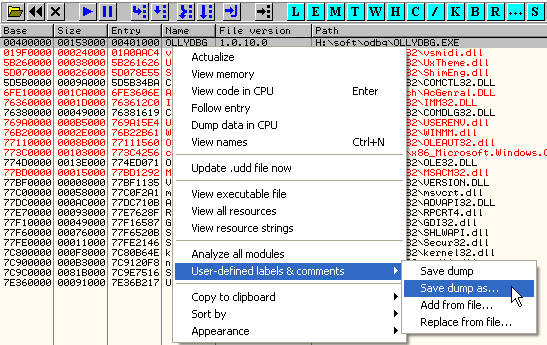
Я назвал этот плагин Markup Dumper, потому что markup — это то, как я традиционно называю расставляемые в процессе реверсинга чужого исполняемого файла метки и коментарии. В рамках данной статьи я употреблял термин «наработки», но наработки — это не только markup, это, к примеру, ещё и брекпоинты.
Дамп разметки модуля OllyDbg, сгенерированный через меню, изображенное на скриншоте выше, выглядит следующим образом. Он состоит из заголовка, позволяющего идентифицировать модуль и случайно не импортировать дамп от какого-то постороннего модуля в качестве разметки для текущего. Заголовок также позволяет во время слияния веток и разрешения конфликта понять, что два файла разметки относятся к разным исполняемым файлам или разным версиям одного и того же бинарника, и пытаться как-то это сливать в одно целое в принципе не имеет смысла.
@ MODULE OLLYDBG
@ VERSION 1.0.10.0
@ BASEADDR 00400000
@ CHECKSUM 17ca77a5
//
// Section: .text
//
LABEL 0040c214 like_ParseStuff
CMT 0040c4c5 colon case
CMT 0040c521 eq case
CMT 0040c575 checking for 1-byte typespec
CMT 0040c578 jump if more than 2 byte spec
CMT 00463f08 checking arg1 (addr) against 0
CMT 00463f0c EDI = arg2 (type of name)
CMT 00463f0f goto error if addr==NULL
CMT 00463f11 checking [addr] against 0
CMT 00463f15 goto error if 0
...
LABEL 004642fb Insertname_EPILOGUE
LABEL 004a3530 like_memcpy
LABEL 004a36d4 like_strlen
LABEL 004a38bc parse_keyword_1
LABEL 004a6c2c like_sprintf
//
// Section: .data
//
LABEL 004eae14 pNamesBlock
LABEL 004eae18 cNameEntriesCur
LABEL 004eae1c cNameEntriesMax
LABEL 004eae30 pNamesStringPool
LABEL 004eae34 cbStringPoolUsed
LABEL 004eae38 cbStringPoolTotal
LABEL 004eae3c xxxWtfNameStringPoolrelatedЗаголовки секций плагин вставляет автоматически. Многоточие поставил я сам, вырезав множество промежуточных строк.
Обратите внимание, что директивы типа CMT вставляются в дамп с двухпробельным отступом от начала строки, а LABEL — нет. Это сделано не просто так. Дело в том, что git diff использует отступы для того, чтобы определить и показать пользователю контекст, в котором находится строка с правкой — причём независимо от языка программирования исходного файла, лишь бы в файле логическая структура выделялась при помощи отступов. Поскольку LABEL в большинстве случаев соответствуют началу очередной процедуры, а CMT появляются, как правило, внутри процедур, такой подход позволяет во время вызова git diff увидеть, к какой процедуре относится добавляемый или изменяемый комментарий (или же метка), что особенно полезно при добавлении чего-то внутрь огромных процедур, не умещающихся целиком на одном экране:
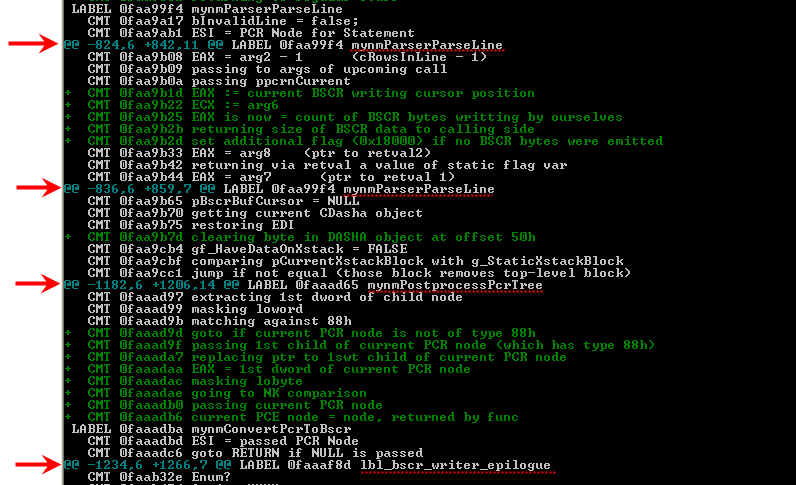
В не меньшей степени это полезно, когда, к примеру, вы разом выгрузили кучу новой разметки в файл, но хотите разобрать её на несколько отдельных коммитов с помощью интерактивного режима (git add --patch).
Этот плагин не является предметом статьи, а нужен лишь для удачной подводки к способу спасения (висящей на волоске от утраты) разметки, который я использовал последние годы, но который не удалось применить в последний раз, из-за чего и пришлось применить более прямолинейный подход.
Хотя надо отметить, что сам по себе плагин, а особенно в комбинации с DVCS отлично решает проблему риска утери данных, описанных выше как пути №1 (BSOD или блэкаут) и №4 (тихая порча UDD).
Но нас интересуют ситуации №2 и №3 (внезапный вылет или зависание). Разберём меры спасения положения в этих ситуациях.
Внезапный вылет
То, что обычные люди называют словами «процесс вылетел», «процесс рухнул», «крешнулся», для нас — необработанное SEH-исключение, которое мы можем попытаться обработать вручную, присоединившись отладчиком, «замяв дело» и продолжив как ни в чём не бывало (если только это не было SEH-исключением с флагом EXCEPTION_NONCONTINUABLE).
Большинство падений OllyDbg с исключением (хотя само по себе это большая редкость) — это исключение типа EXCEPTION_ACCESS_VIOLATION (0xc0000005), и обычно это обращение по нулевому указателю. Это самый простой и легко корректируемый случай, потому что EIP указывает на корректный код, так же как и ESP/EBP содержат корректные значения, стек цел и обычно не повреждён. Почти всегда можно перескочить проблемное место и продолжить, либо перескочить сразу на эпилог процедуры (в которой произошло исключение) и вернуться в вызывающую сторону. В большинстве таких случаев уже в вызывающей процедуре возникнет новое исключение, потому что вызываемая процедура вернула неправильное значение или не подготовила какие-то данные для вызывающей стороны. Поэтому придётся каскадно совершить «принудительный возврат» с раскруткой стека вплоть до тех пор, пока мы не попадём внутрь цикла прокачки оконных сообщений (GetMessage>TranslateMessage>DispatchMessage), откуда брала начала цепочка вызовов, последний элемент которой и спровоцировал возникновения исключения. Так как OllyDbg является GUI-приложением, так или иначе всё берёт начало из подобного цикла, если исключение произошло в процессе фоновой работы, а не в процессе инициализации или завершения отладчика.
Несколько сложнее, если в какой-то процедуре произошло переполнение буфера, размещённого на стеке. Запись за пределы границы буфера имеет высокий риск перезаписать находящиеся там сохранённое значение регистра EBP и адрес возврата. Хакеры используют это для эксплуатации уязвимости и передачи управления на желаемое место, в нашем же случае (не являющемся злонамеренным) подмена адреса возврата на случайное значение приведёт к тому, что после выполнения инструкции retn выполнение (EIP) улетает в тартарары и начинает выполняться неизвестно что.
Как правило, адрес, по которому переходит управление, вообще не является корректным — в виртуальном адресном пространстве (АП) страницы по этому адресу не выделены. Попытка перейти туда и начать выполнение по этому адресу приводит к EXCEPTION_ACCESS_VIOLATION, и именно по этому поводу мы увидим сообщение о необработанном исключении и приглашение воспользоваться отладчиком (для отладки отладчика). Если по ошибочному адресу в АП имеются выделенные страницы, но они имеют атрибуты доступа, не подразумевающие выполнение, а у нас, на счастье, включен DEP, результат будет ровно тем же. Если же нам не повезёт и мы наткнёмся на страницу, выполнение которой разрешено (или DEP не функционирует), этот произвольный и фактически случайный код (или случайные данные, интерпретируемые как код) будет выполняться некоторое время, пока не будет нанесён более серьёзный выстрел себе в ногу. Сложность этого случая в том, что, когда мы подключимся отладчиком к упавшему отладчику, EIP будет указывать скорее всего в никуда, и будет совершенно непонятно, откуда мы сюда прилетели (и куда вернуться, чтобы продолжить всё как было). Стек тоже будет частично нарушен, насколько сильно и глубоко — зависит от случая.
Тем не менее, даже если всё просто, как при случае обращения по нулевому указателю, с тех пор, как у меня появился плагин Markup Dumper, я больше не утруждал себя раскруткой стека вызовов и возвратом в message loop (цикл прокачки оконных сообщений) .
Поскольку внутренности собственного плагина я знал идеально (к нему у меня были отладочные символы), я подключался к умирающему процессу OllyDbg и вместо того, чтобы исправить ситуацию (починить стек, перепрыгнуть проблемное место), я делал нечто совершенно иное.
Я формировал на стеке фрейм с аргументами, которые должны были в норме передаваться при вызове той функции из моего плагина, которая сохраняет дамп, а затем просто насильно менял EIP так, чтобы выполнение продолжилось с этой функции из моего плагина. Естественно, найти адрес этой функции в АП умирающего процесса OllyDbg было наилегчайшей задачей, при условии, что в него был загружен мой плагин (а он был). На выходе из этой функции я ставил ловушку в виде брекпоинта, после чего давал умирающему процессу возможность выполнить мою функцию. Умирающий процесс выполнял процедуру сохранения дампа из моего плагина и сбрасывал дамп в текстовом виде на диск. Дальнейшая судьба умирающего процесса меня не волновала, и я давал ему спокойно умереть: дамп уже был у меня на диске, так что я просто запускал отладчик снова и импортировал дамп, после чего продолжал реверс-инжиниринг как ни в чём не бывало.
Не хочу сделать вид, будто бы в моём плагине есть что-то особенное, что помогает спасти данные в катастрофических обстоятельствах. Он занимает несколько тысяч строк кода, но, если отбросить обработку всех возможных ошибок, защиту от дурака, красивое форматирование выходного файла и прочее, код перечисления и дампинга меток и комментариев можно уместить в пару десятков строк.
Здесь Findname() и Findnextname() — API-функции, которые OllyDbg предоставляет плагинописателям.
void DumpMarkupEx(FILE * fiOutput, int iNameType, char* pszNameType, ulong vaStart, ulong vaLimit)
{
ulong vaCur;
char rgchName[TEXTLEN];
Findname(vaStart-1, iNameType, NULL);
while(vaCur = Findnextname(rgchName) && vaCur<vaLimit)
if(vaCur >= vaStart) fprintf(fiOutput, "%5s %.8x %s\n", pszNameType, vaCur, rgchName);
}
void DumpMarkup(FILE * fiOutput, ulong vaStart, ulong vaLimit)
{
DumpMarkupEx(fiOutput, NM_LABEL, "LABEL", vaStart, vaLimit
DumpMarkupEx(fiOutput, NM_COMMENT, "CMT", vaStart, vaLimit)
}В реальности пользоваться таким кодом не стоит: длина возвращаемого строкового значения ограничена константой TEXTLEN только на бумаге в документации, а фактически же ограничена только объёмом доступной памяти, так что API-функция Findnextname() с радостью переполнит ваш буфер rgchName со всеми вышеперечисленными последствиями. В моём плагине используется более замысловатый подход.
Тем не менее, в экстренных ситуациях даже такой код может быть скомпилирован и инжектирован в умирающий процесс OllyDbg. Точнее мог бы быть, потому что предназначение этой статьи — показать совершенно другой подход к спасению разметки/наработок, нежели вот эту фишку с перенаправлением выполнения в специальный плагин.
Зависание намертво
В этом случае потеря данных происходит потому, что, устав ждать, мы убиваем зависший процесс OllyDbg. Но и тут, как в случае с исключением, мы можем подключиться к зависшему процессу OllyDbg каким-либо отладчиком (например, тем же OllyDbg) и попытаться устранить зависание.
По моей собственной статистике зависания происходят на порядок чаще, чем внезапные вылеты из-за исключения. После подключения к отладчику с помощью другого отладчика можно увидеть, что зависший отладчик застрял и крутится в каком-нибудь бесконечном цикле. Тогда можно попытаться либо прервать этот бесконечный цикл (сфальсифицировав выходное условие для цикла), либо сделать принудительную раскрутку (unwinding) стека, вернув выполнение сразу в message loop. С тех пор, как у меня был мой плагин Markup Dumper, я больше не воевал с бесконечными циклами, а поступал ровно так же, как и в случае с вылетами из-за исключения — насильно менял значение EIP так, чтобы он указывал на сохраняющую функцию из плагина, формировал стековый фрейм и запускал выполнение дальше — код плагина дампил всё, что нужно, в текстовый файл, после чего я спокойно убивал зависший процесс отладчика и запускал новый, импортировав дамп.
Однако лишь в 10—20% случаев зависания в нём виноват сам OllyDbg и возникший в его коде бесконечный цикл. В 80—90% случаев причина зависания была в том, что OllyDbg вызвал какую-нибудь WinAPI-функцию, та дошла до системного вызова, поток перешёл в режим ядра и продолжил выполнение кода ядра, и именно в ядре возник тот самый бесконечный цикл. А если быть точнее, то обычно там был даже не бесконечный цикл, а какой-нибудь вызов NtWaitForSingleObject, сделанный в режиме ядра. В итоге поток просто засыпал в wait-состоянии, ожидал на каком-нибудь объекте синхронизации, который всё никак не удовлетворял это ожидание. Пока не прервётся бесконечный цикл в ядерной части Windows или пока не устранится deadlock, возврата из режима ядра в пользователький режим не произойдёт. Проблема в том, что ждать этого возврата почти не имеет смысла и надежды.
Когда поток перешёл в режим ядра и застрял в ядерном режиме, OllyDbg не имеет никакого контроля над тем, что делает поток. Нет возможности остановить выполнение зависшего потока, нет возможности переместить выполнение на произвольную инструкцию (команда меню New origin here или правка EIP). Ведь что функция New Origin Here, что правка EIP или других регистров процессора — всё это реализуется через обычную WinAPI-функцию SetThreadContext(). Наивно полагать, что Windows позволила бы нам в произвольный момент времени поменять контекст потока, находящегося в привилегированном режиме — это была бы уязвимость галактического масштаба. Настолько же бесполезна отправка зависшему таким образом потоку APC. Чудо не произойдёт и поток не «вынырнет» из режима ядра для обработки нашей APC.
В целом, это скорее проблема Windows, чем проблема OllyDbg, что наличие в системе активного отладчика, присоединённого к процессу, увеличивает вероятность наступления deadlock-а в ядре, но в идеальном отладчике поток, обслуживающий UI отладчика и позволяющий отладчику оставаться живым и интерактивным для пользователя, и поток, который делает обращения к системе для манипулирования отлаживаемым процессом (WaitForDebugEvent, ReadProcessMemory, WriteProcessMemory) — это должны быть разные потоки. И если бы я писал свой идеальный отладчик, то был бы ещё третий watchdog-поток, который в случае зависания GUI-потока создавал бы консольное окно и в нём бы запускал текстовую версию (с использованием псевдографики в том числе) интерфейса отладчика. Как я уже писал выше, устроить коллапс в оконных приложениях тем же сошедшим с ума Spy++ гораздо проще, чем поломать функциональность консольных окон.
Тем не менее, и из такой ситуации, когда главный поток OllyDbg намертво завис в ядре, был очень простой выход. Поскольку OllyDbg — однопоточный по своей природе, при условии, что главный поток усыплён, код самого отладчика и плагина почти во всех случаях можно было запустить в рамках другого потока. Использование глобальных переменных, а не TLS означает, что код, выполняющийся в другом потоке, увидит ровно те же данные, что увидел бы этот же код, выполняйся он в рамках основного потока. Тот факт, что основной поток спит, гарантирует, что синхронного доступа к одним и тем же глобальным объектам, обращения к которым нужно синхронизировать/сериализировать, не произойдёт.
Так что в случае подобных зависаний я формировал где-нибудь в конце секции кода OllyDbg крохотный переходничок, вызывающий спасительную функцию из моего плагина и порождал новый поток с точкой входа на этом переходничке с помощью CreateRemoteThread().
push param1
push param2
push param3
call <адрес_функции_из_моего_плагина>
int3
int3
int3Функция из плагина вызывалась в рамках отдельного потока (только что созданного), сохраняла дамп, после чего новый поток вставал на int3 — в этот момент можно было убивать зависший отладчик и запускать заново, подгрузив дамп из файла (как и в ранее описанных сценариях) и продолжать работу по реверс-инжинирингу.
Это был обзор контрмер, которые помогали спасти наработки отладочной сессии, в случае, когда OllyDbg завис или рухнул. Я пользовался этими трюками последние годы и они выручали, позволяя меньше чем за минуту исправить ситуацию. Но недавно произошёл из ряда вон выходящий случай, когда подобные решения оказались попросту неприемлемыми и неосуществимыми.
Пришлось очень оперативно найти новое решение, которое оказалось универсальным и покрывало не только этот особый случай, но и все описанные до этого.
Особый случай
Формально то, что произошло, может быть отнесено к категории №2 — внезапный вылет из-за необработанного исключения. Но отличие от вышеописанных случаев заключалось в том, какое именно исключение произошло и по поводу чего.
В момент «вылета» появилось следующее сообщение об ошибке:
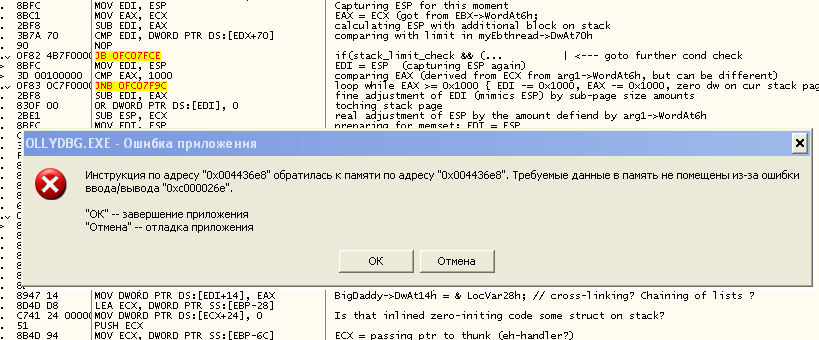
Внимание привлекла к себе необычная формулировка, необычный код исключения 0xC000026E (вовсе не тот привычный 0xC000005 — STATUS_ACCESS_VIOLATION, характерный для доступа по неправильному адресу и/или к неправильной странице), а также необычный адрес 0x004436E8. Люди, занимающиеся отладкой и реверсингом, узнают в адресе 0x00400000 базовый адрес для загрузки EXE-образов, являющийся стандартом де-факто (хотя ничего не мешает использовать другие базовые адреса).
Я не стал нажимать «Отмена», чтобы тут же присоединиться к умирающему отладчику другим отладчиком, потому что почуял неладное (и не зря, как оказалось), а оставил это сообщение висеть. Первым делом я пошёл выяснять, что означает незнакомый мне код 0xC000026E. Как выяснилось, это ошибка STATUS_VOLUME_DISMOUNTED. Но что за размонтированный том и причём тут OllyDbg и какая-то инструкция по адресу 0x004436E8, которая, судя по всему, является частью образа OllyDbg?
Не буду затягивать, и просто расскажу, что произошло:
- В результате работы механизма подкачки некоторые страницы виртуального адресного пространства процесса OllyDbg.exe были выкинуты из физической памяти. Обычно это происходит с теми страницами, доступ к которым осуществляется реже всего. В число таких страниц попала и страница, являющаяся частью проекции секции кода OllyDbg.exe, в которой находилась функция, отвечающая за показ диалога «Go to address» — не самая часто вызываемая функция, очевидно:

- В какой-то момент я нажал Ctrl+G, чтобы перейти по нужному мне адресу (любопытно, обычно я использую команду
atплагина CommandBar, а не Ctrl+G). - Это привело к вызову функции, отвечающей за показ данного диалога. Был осуществлён переход управления на адрес
0x004436E8— это как раз тот самый адрес из сообщения об ошибке — он же адрес начала функции, отвечающей за показ диалога «Go to expression». - Процессор сперва перевёл логический адрес CS:EIP=
001B:004436E8в линейный адрес004436E8(используя таблицы дескрипторов сегментов), а затем попытался перевести линейный адрес004436E8в физический, чтобы выставить его на шину адреса. Это то, что x86-процессор делает при каждом обращении к памяти, когда функционирует в защищённом режиме (бит PE регистра CR0 установлен) с включённым страничным режимом (бит PG регистра CR0 установлен). - В процессе перевода (трансляции) линейного адреса в физический процессор выяснил, что соответствующей странице виртуального АП никакая физическая страница не соответствует — бит P (Present) в соответствующей PDE или PTE был сброшен.
- По этому поводу было сгенерировано прерывание #PF (Page Fault), что является нормальным звеном работы механизма подкачки при страничной организации памяти.
- Прерывание было обработано штатным обработчиком ядра Windows, который должен срабатывать в таких случаях (
KiTrap0E()>MmAccessFault()>и т.д) и подгружать нужную страницу в физическую память с диска — из файла-образа (для проекций исполняемых файлов или файлмаппингов) или из файла подкачки (для страниц, выделенных (в случае user-mode) с помощьюVirtualAlloc, или страниц, являвшихся когда-то частью спроецированного образа или файлмаппинга, но поменявших свой статус с image-backed на swap-backed в результате их модификации в следствие использования режима copy-on-write для них). - Поскольку страница
00443000являлась частью секции кода, в которую никто ничего не писал, а образ в целом не был подвергнут релокации, эта страница так и осталась в статусе image-backed. - Система попыталась подгрузить страницу из файла-образа (
h:\soft\odbg\ollydbg.exe), но в этот момент или непосредственно перед этим произошёл аппаратный сбой, в результате которого жесткий диск, на котором располагался томH:\, отвалился от системы. Поэтому попытка подгрузить страницу не увенчалась успехом, что и привело к генерации исключенияSTATUS_VOLUME_DISMOUNTED(0xC000026E).
Надо сказать, что с таким редким стечением обстоятельств я раньше не сталкивался. Учитывая внезапное пропадание из системы целого тома, неизбежным следствием которого стал тот факт, что в АП процесса имелась целая куча страниц, которые потенциально могли не входить в рабочий набор (working set) к данному моменту, то есть не присутствовали в физической памяти, но которые неоткуда было подгрузить, подключаться к такому процессу с помощью отладчика было чревато неприятностями.
 Я сомневался (и продолжаю сомневаться), что в OllyDbg был должным образом учтён тот редкий случай, что какая-то часть АП отлаживаемого процесса является легитимной с точки зрения
Я сомневался (и продолжаю сомневаться), что в OllyDbg был должным образом учтён тот редкий случай, что какая-то часть АП отлаживаемого процесса является легитимной с точки зрения VirtualQueryEx(), но фактически нечитаема из-за аппаратного сбоя. Поэтому подключение к умирающему отладчику с помощью другого экземпляра отладчика с целью проворота вышеописанного трюка с привлечением плагина для сброса дампа было рискованным делом — второй отладчик мог сам рухнуть от того, что виртуальная память подконтрольного процесса (первого отладчика) частично нечитаема, при этом, падая, он бы унёс собой и первый отладчик, в АП которого остались ценные данные.
Более того, все плагины (а это обычные DLL, подгружаемые в АП процесса OllyDbg) тоже жили на отвалившемся томе H:\. К моменту наступления катастрофической ситуации плагином Markup Dumper долго не пользовались, а скорее всего вообще ни разу не пользовались с момента запуска отладчика. Это означало, что и страницы плагинов с очень большой вероятностью тоже отсутствовали в физической памяти (ФП), потому что были выкинуты из рабочего набора, а подгрузить их система в случае обращения к ним (при попытке «перекинуть» выполнение на функцию из плагина, как я обычно делал) точно так же не смогла бы.
Даже если бы нужные страницы плагина по счастливому стечению обстоятельств оказались в физической памяти на момент возникновения проблемы, плагин ведь не может функционировать, не обращаясь к основному модулю.
В общем, в этой редкой ситуации, когда всё, что было спроецировано в адресное пространство с диска, оказалось фактически недоступным, трюк с созданием дампа силами самого умирающего процесса (путём подмены EIP на нужный адрес из плагина-дампера с привлечением ещё одного отладчика) стал невозможен.
Нужно было что-то принципиально иное, и единственным очевидным решением было найти место в памяти, где OllyDbg хранит те самые данные (names), потеря которых была критичной, и сохранить эти данные в файл, а потом уже разобрать этот файл.
Новое решение
Но для этого нужно было знать две вещи: где искать эти данные и как организовано хранение этой информации. Узнать это как либо, кроме как путём реверс-инжиниринга самого отладчика, было нельзя. Разве что написать автору отладчика (Oleh Yuschuk), и надеяться на ответ...
Поскольку в первые минуты было непонятно, что ещё может отвалиться и чем именно вызван аппаратный сбой, наиболее мудрым казалось решение не изобретать велосипед, а готовым инструментом как можно скорее сделать дамп всех доступных страниц АП умирающего процесса, перезагрузиться, разобраться с аппаратными проблемами, и уже при стабильно работающем железе выискивать нужные данные в сохранённом дампе памяти.
Всем известный Process Explorer от Марка Руссиновича умеет создавать дампы АП произвольного процесса, и я решил воспользоваться им. Но оказалось, что и в нём не предусмотрен такой редкий случай, когда из-за аппаратного сбоя отваливается том и часть страниц виртуального АП не может быть подгружена в ФП. Видимо Process Explorer получал перечень присутствующих в виртуальном АП страниц (или список VAD-ов), а затем наивно пытался прочитать их все — одну за другой, используя ReadProcessMemory(). Как только такой наивный алгоритм натыкался на неподгружаемую страницу, процесс создания дампа обрывался.
В итоге было принято решение оставить умирающий процесс в подвешенном состоянии — не закрывать диалог с сообщением об исключении, не нажимать ни «ОК», ни от «Отмена», не пытаться присоединиться к нему отладчиком. И пока процесс в этом замороженном состоянии находится, оперативно выяснить, как обнаружить в АП процесса нужные данные и как они там организованы — конечно же путём реверс-инжиниринга OllyDbg под OllyDbg. Отвалившийся том H:\ для этого был совершенно не обязательным.
В качестве отправной точки для такого исследования была выбрана API-функция отладчика под названием Insertname(), позволяющая добавить новый name (а это может быть и метка, и комментарий и что-то ещё того же рода) в коллекцию names. Коллекция names — это именно те наработки отладочной сессии, включающие в себя разметку (markup), которую мы стремимся спасти.
Какой вообще могла бы быть организация структуры данных, хранящей так называемые names?
- В тупейшем случае это просто массив троек {адрес, тип, значение}. Добавление происходило бы в конец массива, поиск нужного — последовательным сканированием массива от начала до конца. Чудовищно неэффективный подход: тут и затраты на поиск нужного элемента (), и добавление нового элемента, при котором, когда массиву некуда расти, требуется перевыделение и копирование всего хранилища в новое место, и удаление элемента, требующее сдвига всех элементов, стоящих после удаляемого, на одну позицию влево.
- В более умном случае это был бы тот же массив, но отсортированный по первичному ключу (адресу). Отсортированность позволила бы применить бинарный поиск, а это уже — для миллиарда элементов пришлось бы в худшем случае делать не миллиард итераций, а лишь 30 итераций. Удаление элемента осталось бы почти таким же дорогим (за вычетом того, что находить удаляемый элемент стало бы проще). Добавление бы стало чуть дороже, потому что в среднем всегда бы требовалось раздвигание двух «половинок» массива для вставки элемента в середину, чтобы сохранять отсортированность.
- Всевозможные деревья поиска, в том числе и сбалансированные двоичные деревья поиска (RB, AVL, и т.п.). Чуть больший расход памяти, столь же быстрое нахождение элемента как и в случае двоичного поиска по отсортированному массиву, но более эффективное удаление и добавление (особенно при большим объёмах хранимой информации) за счёт того, что не нужно копировать/двигать огромные непрерывные блоки памяти, а достаточно выделять/освобождать маленькие кусочки памяти под узлы дерева.
Я предвкушал, что мне предстоит иметь дело с третьим случаем и реверсить точную организацию хранения подобного дерева, чтобы из дерева получить плоский «список», с которым было бы удобно работать. Но наиболее лёгким для работы стал бы первый или второй вариант — достаточно было бы сдампить из АП умирающего процесса один единственный большой блок, а дальше с ним работать.
Итак, когда я открыл OllyDbg под OllyDbg и нашёл _Insertname(), я увидел следующее:
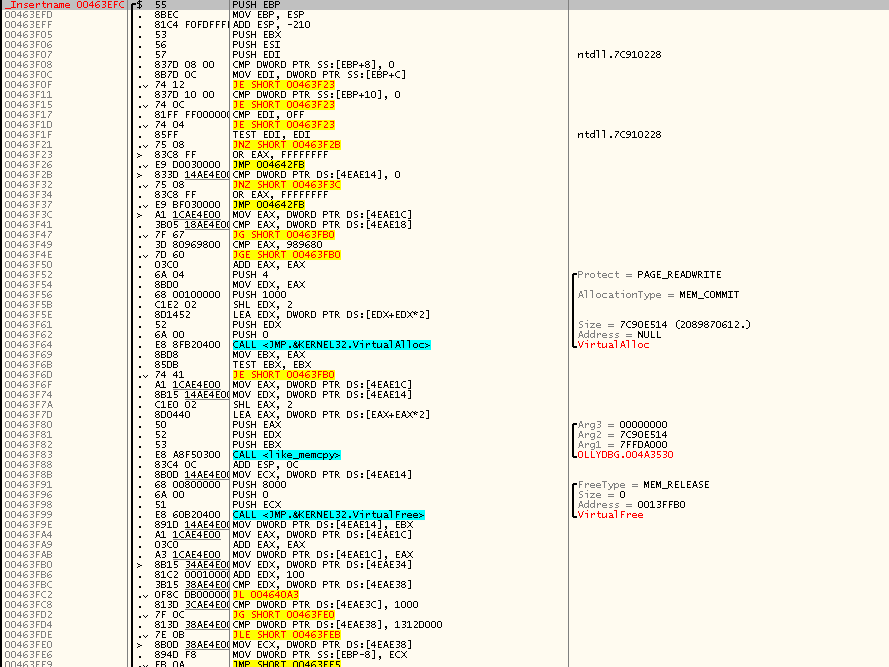
Установка фрейма, резервирование на стеке места под локальные переменные, сохранение EBX, ESI, EDI, проверка значений входных параметров — обычные вещи. Но то, что сразу бросилось мне в глаза — это пара вызовов VirtualAlloc() и VirtualFree(), между которыми стоял вызов memcpy из стандартной библиотеки, которую я уже когда-то находил в недрах OllyDbg при более раннем реверсинге.
Когда-то давно я чисто случайно наткнулся на любопытный факт: изучая вывод Process Monitor (также известный как FileMon), было обнаружено, что при подгрузке в отлаживаемый процесс какого-нибудь модуля (например TEST.DLL), процесс-отладчик пытался прочитать с диска не только TEST.UDD, но и некий TEST.ARG (которого на диске не существовало, понятное дело). Что это за таинственный ARG-файл я не знал, и я принялся исследовать, что будет, если подсунуть OllyDbg
какой-нибудь файл в качестве ARG-файла.
Всё это вылилось в реверс-инжиниринг OllyDbg с целью понять, что ожидает отладчик от ARG-файла, как он его анализирует и что делает с его содержимым. Результатом стало очень ценное для меня открытие: ARG-файлы позволяли решить крайне важную задачу и добавляли крайне желанную функцию в OllyDbg. ARG-файлы позволяли описать custom-функции, их аргументы и способ декодирования аргументов, таким образом, что OllyDbg начинал распознавать и красиво отображать вызовы нестандартных процедур — в точности так, как, например, он показывает вызов известных ему VirtualAlloc() и VirtualFree(), не только обводя формирование фрейма аргументов блочком, не только подписывая названия аргументов, но и декодируя числовые значения как соответствующие контексту константы (push 4 подписывается не как fProtect = 4, а как fProtet = PAGE_READWRITE).
Я был в шоке: нигде в интернете не было ни слова про ARG-файлы, нигде не был документирован их синтаксис. Это была пасхалка на миллион. Через некоторое время путём реверсинга был выяснен синтаксис и ключевые слова, которые нужно использовать для написания ARG-файов.
Ту же самую разведанную like_memcpy (которая на самом деле memcpy() из libc) можно было описать так, чтобы её аргументы подписывались не как
Arg3 = ...
Arg2 = ...
Arg1 = ...а как
count = ...
src = ...
dest = ...Причём механизм позволял не только подписывать аргументы, но и делать декодирование простеньких структур, например вместо clr = 8000FF показывать clr = (R=255 G=0 B=128)
Я долго собирался объединить все свои знания об ARG-файлах и поделиться с миром об этой недокументированной фишке, но спустя некоторое время по совершенно другому поводу чисто случайно наткнулся в хелпе OllyDbg на раздел «Custom function descriptions», где всё это было прекрасно документировано.
Воистину, RTFM twice.
Выделение нового блока, копирование и освобождение какого-то другого блока — хм… это очень похоже на то, что могло бы делаться при применении одного из тех двух простых подходах с массивом место деревьев.
Неужели это выделение того самого большого массива, за которым я охочусь? Это могло бы быть и выделением какого-то временного буфера, конечно. Это могло бы также быть и выделением всего лишь блока под новую ноду (узел) дерева — я ещё не знал, используется ли древовидная структура или плоский массив.
Но два соображения подогревали мой оптимизм:
- Если бы это был кусочек памяти под новый узел дерева или под временный буфер (для дальнейшей обработки с занесением в дерево), он скорее всего выделялся бы через
malloc()/HeapAlloc(), а не черезVirtualAlloc(), которая выделяет память со страничной гранулярностью (размерами, кратными 4 кб) и обычно используется для выделения больших блоков. Тем более, что размер выделяемого блока здесь определялся как EDX*24, а EDX брался из глобальной переменной, которая перед этим сравнивалась с какой-то другой глобальной переменной. Это могла бы быть переменная с количеством элементов, а 24 — размером одного элемента. - Хелп и Plugin Development Kit (PDK) говорил, что помимо Insertname() есть более быстрая альтернатива в виде Quickinsertname() и Mergequicknames(), которые нужно использовать для эффективного добавления большого количества новых names — эти API-функции были хорошо мне известны со времён написания плагина. Сам факт существования альтернативного пути для группового добавления намекал на то, что операция единичной вставки элемента протекает не самым эффективным образом, и что за хранилищем элементов может стоять структура данных типа упорядоченный массив.
Начинаю реверсить код API-функции Insertname(), последовательно двигаясь по ходу его выполнения и подписывая происходящие действия:
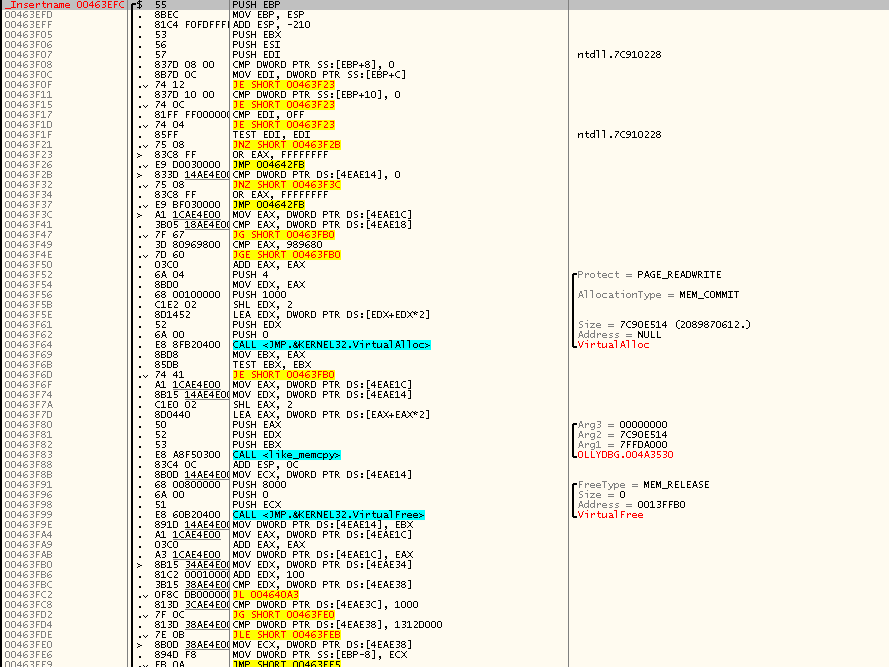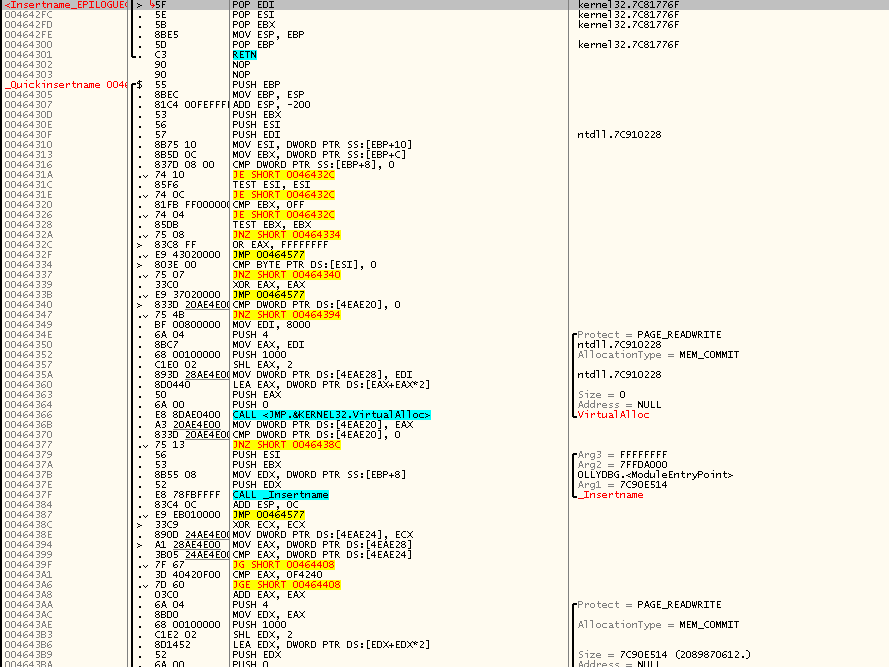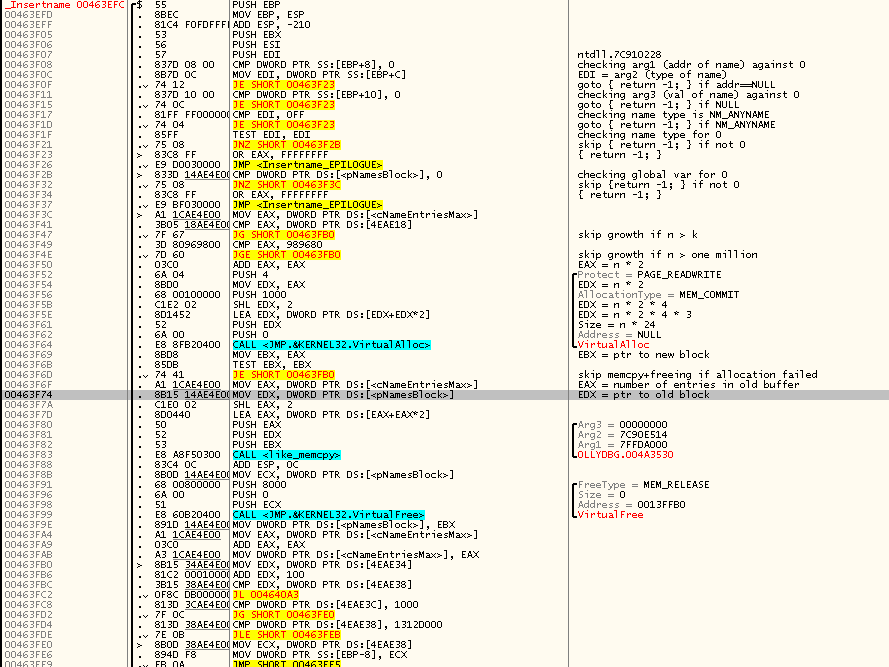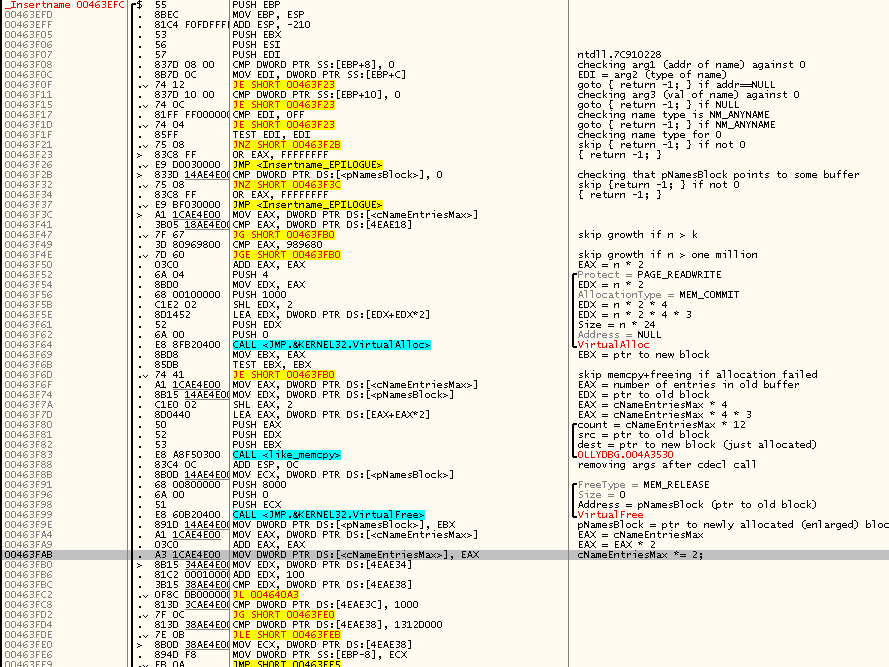
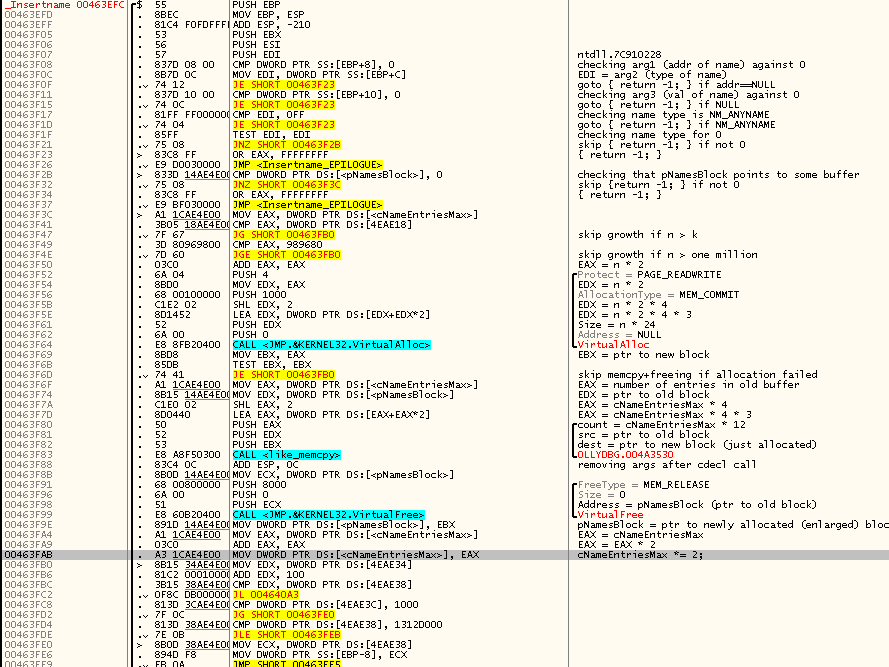
Предположения, родившиеся при первом взгляде, начинают ещё больше двигаться в сторону их полного подтверждения. Names, похоже, живут в одном непрерывном массиве — массиве структур, размером, правда, не 24 байта, а 12 байт, что как раз соответствует размеру структуры с тремя DWORD-полями (очевидно — адресом, типом, значением). Умножение числа элементов на 24 стоило понимать как умножение числа элементов на 12, а затем на 2 — это одна из канонических стратегий увеличения размера хранилища в случае его нехватки, при которой размер хранилище каждый раз увеличивается вдвое.
Если вам сложно глядя на дизассемблерный листинг ясно представлять себе стоящий за ним исходный сишный код, то вот псевдокод начальной части Insertname():
int Insertname(ulong addr,int type,char *name)
{
//
// Проверка корректности входных аргументов
//
if(addr == NULL ||
name == NULL ||
type == NM_ANYNAME || type == NM_NONAME)
{
return -1;
}
//
// Проверка, что буфер для массива name-записей существует
//
if(!pNamesBlock) return -1;
if(!(cNameEntriesCur < cNameEntriesMax) && cNameEntriesMax < 1000000)
{
//
// Выделяем новый буфер в два раза больше, чем используемый сейчас
//
void* const pNewBlock = VirtualAlloc(NULL,
2 * cNameEntriesMax * sizeof(NAME_REC),
MEM_COMMIT,
PAGE_READWRITE);
if(pNewBlock)
{
//
// Если получилось выделить, переносим старые данные в новый буфер
// и освобождаем старый.
//
memcpy(pNewBlock, pNameBlock, cNameEntriesMax * sizeof(NAME_REC));
VirtualFree(pNamesBlock, 0, MEM_RELEASE);
//
// Назначаем новый блок памяти блоком с массивом структур,
// устанавливаем переменную, храняющую предельное число хранимых
// элементов на вдвое большее значение.
//
pNamesBlock = (NAME_REC*)pNewBlock;
cNameEntriesMax *= 2;
}
}
// Здесь прожолжается код по адресу 00463FB0Кстати, обратие внимание, что если аргумент name принимает значение NULL, то это считается некорректным значением, и функция сразу же возвращает -1. А вот что говорит нам документация на эту API-функцию:
Insertname
Inserts new or replaces existing name of given type in the name table. If name is NULL or empty, entry is deleted. Returns 0 on success and -1 on error. Note: do not call this function between calls to Quickinsertname and Mergequicknames!
int Insertname(ulong addr,int type,char *name);**
Parameters:
addr — name address;
type — name type (NM_xxx for predefined types);
name — name to insert. If name is NULL or empty, entry is removed from the name table.
И таких нестыковок и расхождений там десятки. Я вообще был шокирован корявой и примитивной архитектурой плагинной подсистемы и отладчика вообще, как только когда-то давно взялся за написание первого плагина к OllyDbg.
Отлично. Я запустил OllyDbg под OllyDbg, и в дочернем инстансе OllyDbg подобавлял вручную меток и комментариев, а в родительском экземпляре OllyDbg убедился, что действительно в этот самый буфер заносятся новые тройки вида {адрес, значение, тип} c ожидаемыми для меня значениями поля «адрес» и поля «тип» (это были NM_LABEL и NM_COMMENT).
То есть структура элемента нашего массива была такой:
| Размер | Поле |
|---|---|
| DWORD | Address |
| DWORD | Value |
| DWORD | NameType |
Однако, в поле «Value» я ожидал увидеть указатели на строковые значения добавляемых names, а если быть точным, на нуль-терминированные ASCII-строки. Но то, что там обнаружилось, не было адресами строк — это были какие-то числовые значения другого толка.
Можно было бы предположить, что это индексы, ссылающиеся на элементы какого-то другого массива (массива строковых значений), но для индексов у них были слишком большие промежутки между значениями соседних элементов. Скорее это были какие-то смещения.
Так или иначе, вытаскивание из умирающего процесса OllyDbg и сохранения дампа одного лишь большущего блока, выделяемого с помощью VirtualAlloc и содержащего набор трёхDWORDных записей, оказалось бы недостаточным: адреса и типы сущностей у нас содержатся прямо в этом блоке, а вот значения хранятся где-то в другом месте.
Смотрим, какой же код находится в функции дальше?
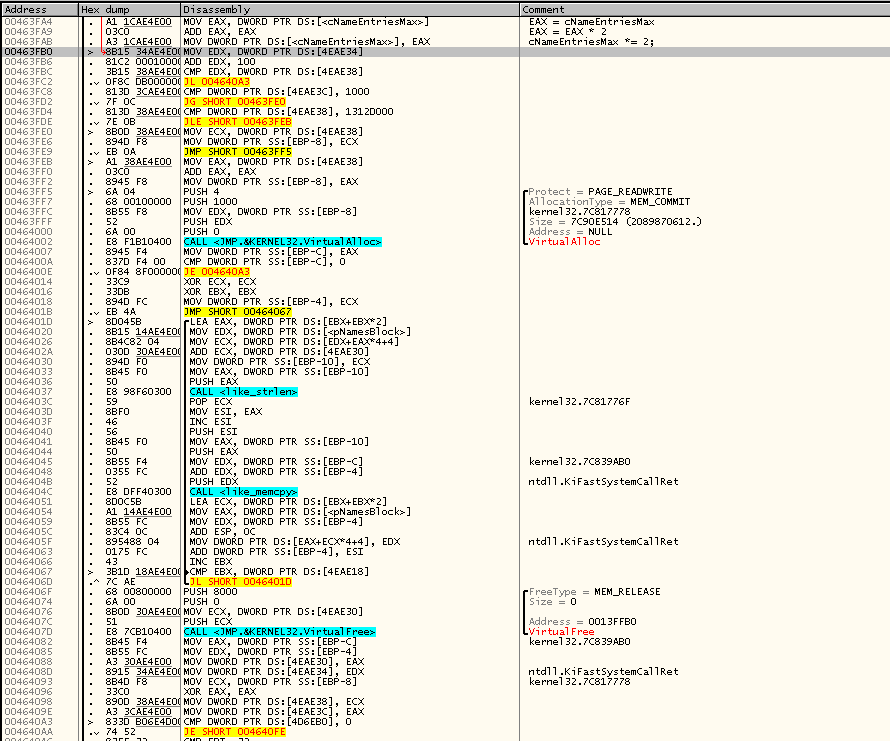
Картина очень сильно напоминает то, что мы видели до этого: какие-то две глобальные переменные сравниваются, и если не получается так, что одна меньше другой, то выполняется некий блок инструкций, состоящего из вызовов VirtualAlloc и VirtualFree между которыми стоит правда не одиночный вызов memcpy, как мы видели до этого, а некий цикл, внутри которого вызывается strlen и memcpy.
Даже без подробного вникания в код мне было интуитивно понятно, что все строковые значения name'ов хранятся в другом буфере, и это, очевидно, код, который проверяет, есть ли ещё свободное место в этом втором буфере, и если достаточного места нет — наращивает размер второго буфера, выделяя новый блок памяти и перенося в него содержимое старого.
Но мы разреверсим и этот код шаг за шагом, чтобы ничего не упустить:
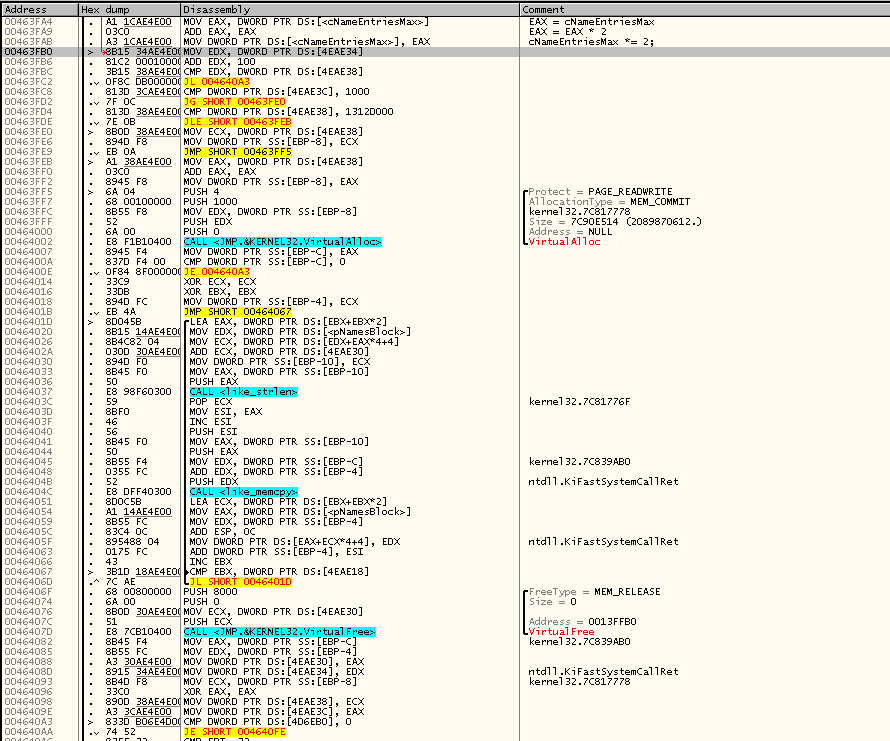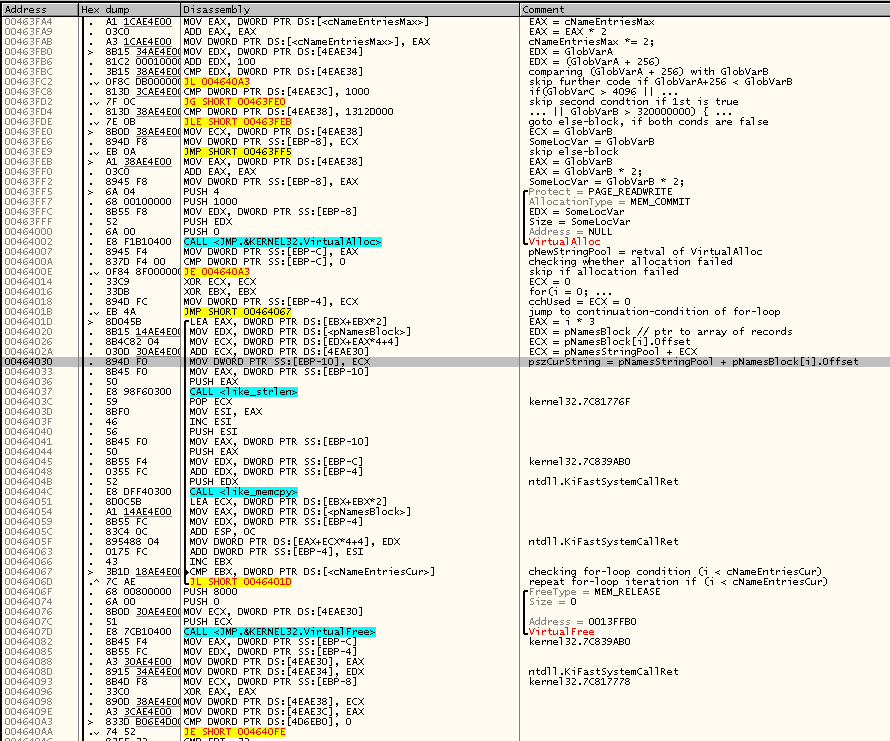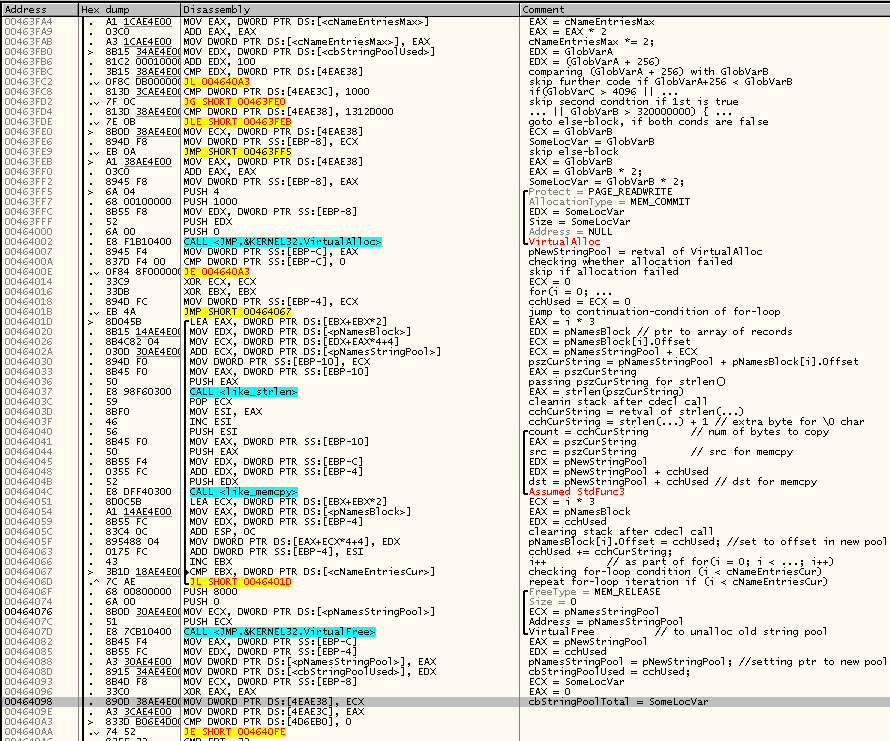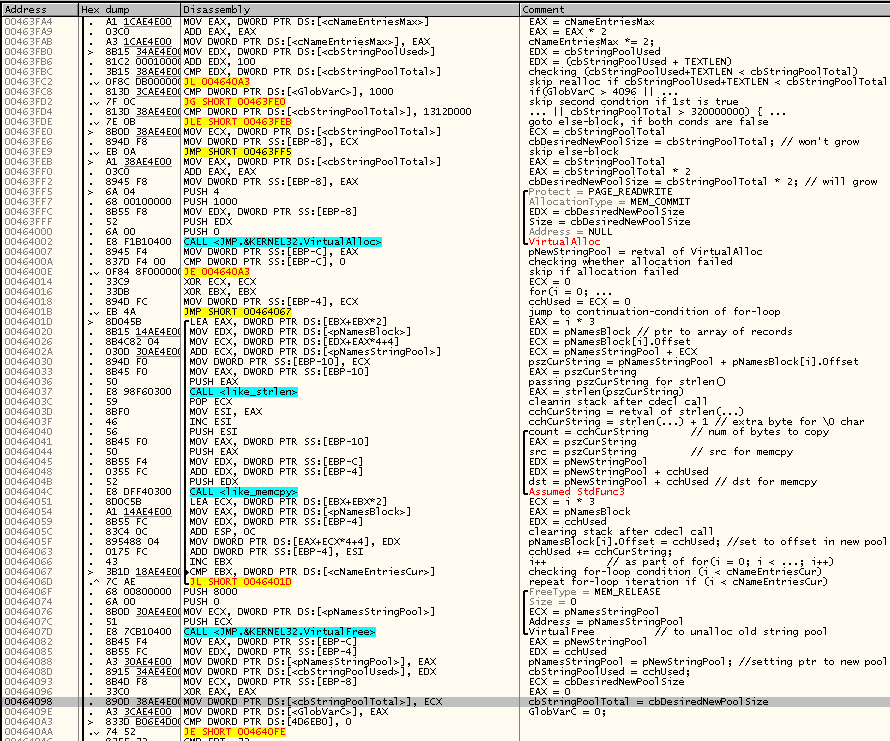
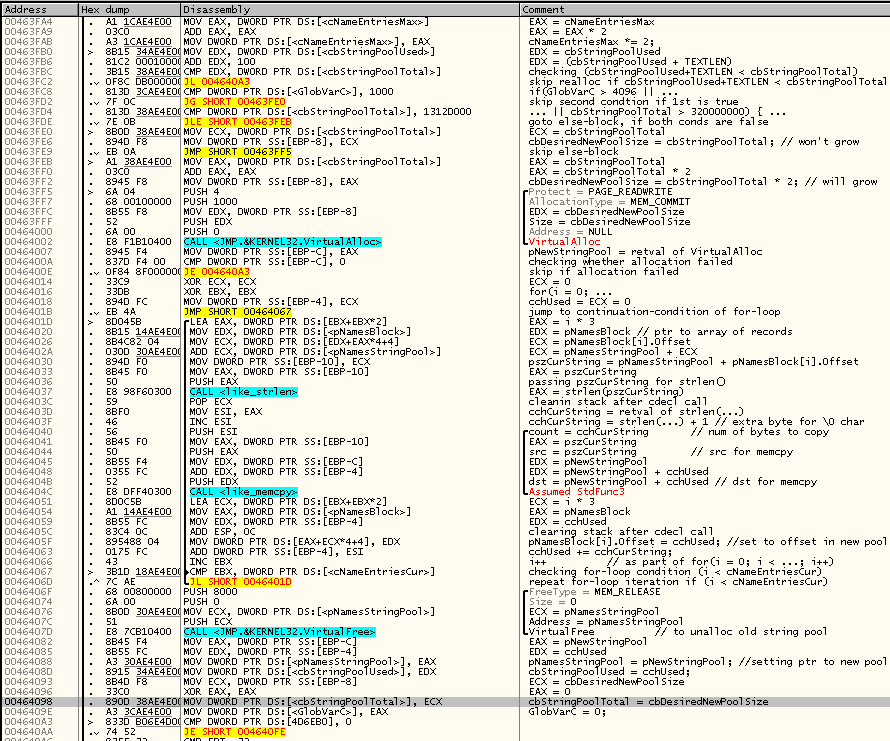
В общем, все предположения относительно этого кода подтвердились. Продолжаем псевдокод с того места, на котором остановились:
if(!(cbStringPoolUsed + TEXTLEN < cbStringPoolTotal))
{
char* pNewStringPool;
int cbDesiredNewPoolSize;
if(GlobVarC > 4096 || cbStringPoolTotal > 320000000)
cbDesiredNewPoolSize = cbStringPoolTotal;
else
cbDesiredNewPoolSize = cbStringPoolTotal * 2;
pNewStringPool = VirtualAlloc(NULL,
cbDesiredNewPoolSize,
MEM_COMMIT,
PAGE_READWRITE);
if(pNewStringPool)
{
int cchUsed = 0;
int i;
for(int i = 0; i < cNameEntriesCur; i++)
{
char* pszCurString = pNamesStringPool + pNamesBlock[i].Offset;
int cchCurString = strlen(pszCurString) + 1;
memcpy(pNewStringPool + cchUsed, pszCurString, cchCurString);
pNamesBloc[i].Offset = cchUsed;
ccUsed += cchCurString;
}
VirtualFree(pNamesStringPool, 0, MEM_RELEASE);
pNamesStringPool = pNewStringPool;
cbStringPoolUsed = cchUsed;
cbStringPoolTotal = cbDesiredNewPoolSize;
GlobalVarC = 0;
}
}Любопытно, что если строковый пул (буфер, где компактно обитают нуль-терминированные строковые значения name'ов, включая метки и комментарии) переполнился, выполняется попытка его увеличить (вдвое), но рост пула запрещается, если текущий размер пула превышает 320 миллионов байт, или если некая глобальная переменная-счётчик (я назвал её GlobVarC) превысила значение 4096.
Зачем нужен цикл с перебором и поочерёдным копированием каждого строкового значения в отдельности, если можно весь контент старого строкового пула скопировать в новый пул одним вызовом memcpy? Сдаётся мне, что таким образом реализован механизм сбора мусора — по всей видимости в других местах удаление строки из пула заключается просто в забвении указателя на неё (точнее смещения, ведь структуры в первом буфере используют смещения на строки во втором буфере, строковом пуле). И лишь когда этот мусор исчерпывает всё свободное место в строковом пуле, происходит выделение нового буфера, в ходе которого в новый буфер из старого переносятся лишь те строки, на которые кто-то ссылается, а мусор в новый буфер не переносится. При этом новый буфер имеет не увеличенный, а такой же, как и старый, размер, если старый размер превышал 320 миллионов байт или если GlobVarC > 4096. Я не реверсил дальше, но сдаётся мне GlobVarC — это счётчик мусорных строк, ожидающих отложенного (delayed) удаления из пула. Эта гипотеза подтверждается тем, что после прогона цикла копирования/дефрагментации пула эта переменная зануляется.
Интересно, что для проверки того, хватит ли в существующем строковом пуле места под новую строку, используется выражение cbStringPoolUsed + TEXTLEN < cbStringPoolTotal, а не более рациональное
cchCurString = strlen(Value) + 1;
if(!(cbStringPoolUsed + cchCurString < cbStringPoolTotal))Во-первых, такой код позволил бы не выделять новый буфер под строковый пул и не переносить весь контент, если сейчас, к примеру, добавляется строка из 5 символов, а в пуле осталось 100 байт свободного места, что меньше, чем 256 (константа TEXTLEN), но более чем достаточно для добавления в пул пятисимвольной строки.
Во-вторых, это позволило бы не ограничивать длину добавляемых значений лимитом в 256 символов, включая нуль-терминирующий символ. Но автор посчитал, что 255 символов должно быть достаточно для каждого, и стал ограничивать.
Ирония же в том, что в дальнейшем по ходу выполнения strlen(value) для новой строки так ни разу и не проверяется, поэтому функция Insertname() при получении длинной строки ни ошибку не возвращает, ни даже урезания размера строки до 255 символов не производит!
То есть строка длиной 1000 символов без малейшего шума принимается функцией и со свистом улетает в строковый пул, а в дальнейшем возвращается функциями Findname() и Findnextname(), переполняя буферы, предоставляемые им вызывающей стороной.
Но с некоторой вероятностью в момент добавления в пул строки свободного пространства в нём будет больше, чем TEXTLEN, но меньше, чем фактическая длина строки. В этом случае отладчик почти гарантированно рухнет прямо в момент добавления. Почти гарантированно, а не гарантированно, потому что впритык вслед за строковым пулом может оказаться другой блок памяти, доступный для записи — это спасёт отладчик от мгновенного вылета с исключением, но повредит какие-то другие данные, что скорее всего приведёт к вылету в ближайшее время. Получается, что иногда свободного места может хватать, но буфер всё равно увеличивается, а иногда не хватает, но увеличения не происходит.
Во-первых, не забывайте, что Insertname() используется не только для меток и комментариев. Брекпоинты, watch expressions, условные брекпоинты и брекпоинты, дающие возможность указать команды, выполняемые при срабатывании — всё это тоже частные случаи name-ов. Представить себе условный брекпоинт со сложным условием, длина выражения для которого не вмещается в ограничение в 255 символов, я могу вполне легко.
Во-вторых, сам по себе интерфейс OllyDbg не даст ввести метку или комментарий длиннее, чем TEXTLEN символов, так что вызвать крушение процесса просто так не получится. Но вот плагины, добавляющие сущности через Insertname() или Quickinsertname(), ничем не ограничены. И я такие плагины могу перечислить при желании. Один из примеров, который не нужно вспоминать, популярный плагин OllyScript, суть которого понятна из названия. Существует огромное количество скриптов, распространяемых в соответствующей среде, и ничто не мешает скрипту добавить чрезмерно длинный комментарий или метку, вызвав в отдалённой перспективе аварийное завершение процесса.
OllyDbg умеет адекватно воспринимать задекорированные имена процедур и красиво их отображать (кстати, раздекорирование при отображении можно и отключить).
Куда приятнее иметь дело с функцией CNFFMappedStream::Unmap, нежели видеть малопонятное ?Unmap@CNFFMappedStream@@UAGXEPAPAX@Z, и OllyDbg умеет это «из коробки». Но в этом малопонятном задекорированном идентификаторе зашита также и информация о типах аргументов и типе возврата. Иногда очень хочется видеть прототип функции, чтобы иметь представление о том, параметры какие типов она ожидает увидеть. В данном случае такой:
virtual void __stdcall CNFFMappedStream::Unmap(unsigned char,void * *)Эту потребность я в своё время реализовал с помощью скриптов. Однако есть один нюанс. Существует такое явление, происходящее во время линковки, как COMDAT folding.
В простейшем случае компилятор весь машинный код и все данные формирует в объектном файле в виде больших секций, содержащих всё необходимое. Но при желании можно сделать так, чтобы каждая отдельная функция, каждая отдельная переменная, каждая строковая константа или вообще, выражаясь в терминах Си, статически размещаемая сущность, располагалась в объектном файле в своей отдельной маленькой секции. Такая секция, снабжённая дополнительными атрибутами, например контрольной суммой, а также флагом, определяющим, как можно и как нельзя поступать с этой секцией в некоторых интересных случаях, именуется также как COMDAT (от Communal Data).
Под «интересными случаями» имеются в виду две возможных крайности: имеются COMDAT, на которые вообще никто не ссылается (и их можно без вреда, а только с пользой, заключающейся в уменьшении размера выходного исполняемого файла, выкинуть; или нельзя, если COMDAT-атрибуты или ключи, указанные при вызове линкера, запрещают это делать). Другая крайность — это когда на вход линкеру поступает множество COMDAT с разными именами, но с одинаковым содержимым. Например если в каждом объектном файле присутствует строковая константа "ERROR", незачем включать в итоговый исполняемый файл сотню копий этой строки — можно ликвидировать все дубликаты, включив в файл только одну копию. То же самое касается и процедур, исходный код которых может быть на удивление непохожим, но сгененированный машинный код окажется идентичным байт-в-байт.
Например:
unsigned short GetCodepointLength(const char* pCodepoint)
{
#ifdef UNICODE_STRINGS
#if UNICODE_STINGS == UTF8
const char cp = *pCodepoint;
unsigned short cbExtra;
for(cbExtra = 0; (cp & 0x80) && (cbExtra < 3); cbExtra++, cp<<=1)
if(cp & 0x40) {if(!(cp & 0x20)) break; } else return 0;
return 1 + cbExtra;
#else // UCS-2 or UTF-16
return sizeof(wchar_t);
#endif
#else
return sizeof(char);
#endif
}
LONG __stdcall CFlatArrayObject::GetDimensionsCount() // for IArrayObject::GetDimensionsCount
{
return 1;
}
BOOL CAudioCodec::IsSampleFormatSupported(SAMPLE_FORMAT sf)
{
return TRUE; // We support all
}Все три функции будут скомпилированы так:
mov eax, 00000001
retn 4При линковке произойдёт (для популярных версияй компилятора и линкера от Microsoft это поведение по умолчанию) так уже упомянутый COMDAT-folding и в выходной файл попадёт только один экземпляр машинного кода для этих процедур. В таком случае в файле отладочной информации одному и тому же адресу будут соответствовать сразу три символа.
При обработке скриптом, если одному и тому же адресу в результате COMDAT folding'а соответствовало сразу несколько символов, я комбинировал прототипы всех функций, оказавшихся «свёрнутыми воедино», в одну длинную строку, разделённую символами // и префиксированную пометкой «FOLDED:». Иногда в результате COMDAT-folding'а объединёнными оказывались десятки процедур (типичные пример это когда в проекте используется COM и имеются реализации методов ряда COM-интерфейсов, возвращающих E_NOTIMP — реализации нескольких десятков таких методов у совершенно разных классов сворачивались до 5—6 тривиальных процедур в итоговом бинарнике, различающихся только количеством параметров, принимаемых методом, которое влияет на инструкцию RETN). Однако каждой из таких процедур присоединялся комментарий, состоящих их склеенных в одну длинную строку прототипов для десятков исходных методов. Естественно, что такая длинная строка не укладывалась TEXTLEN символов. Но откуда мне было знать? В документации к OllyScript не было ни слова об ограничении на длину комментариев.
Дальше код этой API-функции продолжается, но я не стал реверсить оставшуюся часть, ведь у меня уже сформировалось представление о том, как организовано хранение спасаемых сущностей и как добраться до блоков памяти, содержащих нужные данные.
Все те глобальные переменные, которые мы «открыли» в ходе реверсинга первой половины Insertname(), находятся в секции данных, причём, что не удивительно, лежат они почти вплотную друг к другу (так они объявлены в исходном файле):
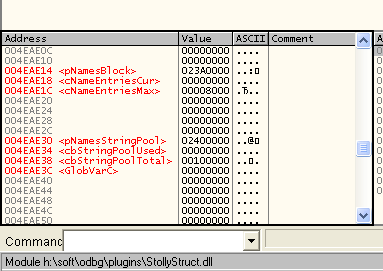
В таблице секций PE-файла (EXE или DLL) для каждой секции указывается полный и инициализированный объём секции: страницы неинициализированной части секции данных (да и любой секции в общем случае) сразу становятся swap-backed страницами, инициализированная часть изначально является image-backed, но механизм copy-on-write при первой же модификации страницы может перевести её из image-backed в swap-backed, после чего в процессе подкачки страница будет выгружаться/подгружаться уже в/из файла подкачки, а не из первоначального образа PE-файла.
Вне зависимости от того, в какой секции или в какой части секции (если одна секция используется и для инициализированных, и для неинициализированных данных, как это имеет место в случае с OllyDbg и большинством бинарников, не имеющих отдельной секции для неинициализированных данных, называющейся, как правило, .bss) были бы размещены глобальные переменные, раз эти переменные в ходе работы OllyDbg модифицировались (а они не могли не модифицироваться), страница, на которую они приходятся, гарантированно является swap-backed-страницей.
Поскольку файл подкачки у меня точно не находился на отвалившемся томе H:\ (файл подкачки у меня находится на отдельном SSD-диске), в отличие от других страниц спроецированного образа OllyDbg.exe, страница именно с этими переменными должна была быть читаемой, а значит, её содержимое можно было прочитать с помощью ReadProcessMemory().
И вот мы подходим к кульминационному моменту статьи — тому, ради чего эта статья и вся предшествующая часть, с рассказом об альтернативных способах и всей подоплёке, затевались — к методике спасения данных из процесса, висящего на грани гибели. Поскольку в самом начале статьи я предлагал тем, кто прямо сейчас находится в экстренной ситуации (а не читает статью просто из интереса) сразу перейти к этому месту, я буду дальше писать уже не с позиции реверс-инжиниринга и исследования, не буду задавать риторических вопросов, не буду обсуждать случайно найденные баги, а напишу в стиле методички по спасению данных.
Методика спасения данных
Итак, все наработки отладочной сессии — метки, комментарии, брекпоинты, хинты анализатора и тому подобное — всё это хранится с использованием двух больших непрерывных блоков памяти:
- Первый блок хранит массив структур
NAME_REC, олицетворяющих тройки вида {адрес, значение, тип сущности}. Каждый элемент занимает 12 байтов. Элементы в массиве строго упорядочены по значению поля «адрес» для высокоэффективного поиска нужного элемента в массиве. Этот блок мы будем называть таблицей записей. - Второй блок хранит исключительно строки произвольной длины, терминированный нуль-символом, являющиеся истинными значениями ассоциированных с адресами сущностей (комментариев, меток и т.п.). Поле «значение» структур из первого блока хранят не само значение, а смещение во втором блоке строки, являющейся значением данной сущности. Этот блок мы будем называть строковым пулом.
В секции данных модуля OllyDbg.exe по постоянным адресам находятся несколько глобальных переменных, хранящих адреса этих блоков и информацию об их размере — эти глобальные переменные нужно использовать как отправные точки для нахождения этих двух блоков памяти.

Извлечение из адресного пространства умирающего процесса и сохранение на диск содержимого этих блоков и обеспечит нам спасение всех наработок отладочной сессии, которые висят на грани исчезнования. Для того, чтобы прочитать содержимое этих блоков, нужно знать, откуда и сколько читать — для получения адресов и размеров блоков нам нужно прочитать участок секции данных, содержащий 7 вышеуказанных глобальных переменных (на самом деле нам минимально достаточно лишь 4 из них).
Очевидно, что адреса глобальных переменных в секции данных могут меняться от версии к версии. Приведённые на скриншотах выше адреса актуальны для версии 1.10. Вам они могут не подойти! Даже если вы используете версию 1.10, нет гарантии, что не существует двух бинарно различных билдов OllyDbg, гуляющих по сети, использующих этот номер версии.
Поэтому прежде, чем читать по адресу 0x004EAE14, вы должны убедиться, что это правильный адрес интересующей нас группы глобальных переменных, и, если это не так, определить правильные адреса глобальных переменных в вашей версии OllyDbg. Это делается очень легко: один из самых простых способов найти их — это изучение дизассемблерного листинга API-функции Insertname(). Пример такого изучения показан выше (если вы не читали статью целиком, а перешли сразу сюда). Скорее всего в вашем билде код этой API-функции будет полностью идентичен показанному на скриншотах выше. Даже если там будут минимальные отличия, я уверен, что вы легко найдёте нужные глобальные переменные через нахождение обращений к ним. К примеру, глобальные переменные, хранящие адреса блоков, легко найти по тому признаку, что их значение передаётся в VirtualFree, после чего в них записывается новое значение, полученное ранее от VirtualAlloc.
Если вы выяснили точный адрес группы глобальных переменных, спасение данных становится тривиальной задачей. В моём случае процесс OllyDbg попал в критическое состояние по причине того, что диск, где находился файл-образ (ollydbg.exe), спроецированный в память, внезапно отвалился от системы из-за аппаратного сбоя. Часть «случайных» страниц АП процесса стала нечитаемой, так как они были выгружены из физической памяти, а подгрузить их стало неоткуда. Поэтому я очень спешно написал утилиту-дампер, псевдокод которой, если вырезать обработку возможных ошибок, выглядел очень просто:
struct
{
struct
{
DWORD pNamesBlock;
DWORD cNameEntriesCur;
DWORD cNameEntriesMax;
} NameBlockInfo;
struct
{
DWORD pNamesStringPool;
DWORD cbStringPoolUsed;
DWORD cbStringPoolTotal;
DWORD wtf;
} StringPool;
} Metadata;
void main()
{
HANDLE hOdbgProc;
DWORD cbRead = 0;
DWORD pid = ?????????;
hOdbgProc = OpenProcess(PROCESS_ALL_ACCESS, FALSE, pid);
ReadProcessMemory(hOdbgProc,
(LPCVOID)0x004EAE14,
&Metadata.NameBlockInfo,
sizeof(Metadata.NameBlockInfo),
&cbRead))
ReadProcessMemory(hOdbgProc,
(LPCVOID)0x004EAE30,
&Metadata.StringPool,
sizeof(Metadata.StringPool),
&cbRead))
VOID* pNamesBlock;
VOID* pNamesPool;
pNamesBlock = VirtualAlloc(0, Metadata.NameBlockInfo.cNameEntriesMax * 12, MEM_COMMIT, PAGE_READWRITE);
pNamesPool = VirtualAlloc(0, Metadata.StringPool.cbStringPoolTotal, MEM_COMMIT, PAGE_READWRITE);
ReadProcessMemory(hOdbgProc,
(LPCVOID)Metadata.NameBlockInfo.pNamesBlock,
pNamesBlock,
Metadata.NameBlockInfo.cNameEntriesMax * 12,
&cbRead))
ReadProcessMemory(hOdbgProc,
(LPCVOID)Metadata.StringPool.pNamesStringPool,
pNamesPool,
Metadata.StringPool.cbStringPoolTotal,
&cbRead))
DumpBlockToFile(&Metadata, sizeof(Metadata), "names-meta.dat");
DumpBlockToFile(pNamesBlock, Metadata.NameBlockInfo.cNameEntriesMax * 12, "names-tbl.dat");
DumpBlockToFile(pNamesPool, Metadata.StringPool.cbStringPoolTotal, "names-pool.dat");
VirtualFree(pNamesBlock, 0, MEM_RELEASE);
VirtualFree(pNamesPool, 0, MEM_RELEASE);
}Если Си — не ваш язык, вы можете написать дампер на любом другом языке, который даёт возможность пользоваться ReadProcessMemory. Более того, дампер как таковой понадобился мне только из-за того, что работоспособность процесса поломалась из-за очень редкой причины — внезапного пропадания жесткого диска из дерева устройств, и существовал большой риск, что подключение к умирающему отладчиком другим отладчиком могло сильно усугубить ситуацию, а готовых утилит-дамперов, способных читать и сохранять произвольные участки памяти у меня под рукой не было. При возникновении менее экзотических проблем, вроде внезапного вылетания и зависания (описанных в начале статьи), вам вообще не нужна специальная утилита-дампер — посмотреть содержимое глобальных переменных и сделать дампы двух регионов памяти прекрасно можно и из OllyDbg.

Тем не менее, если вы вдруг решите написать специальную утилиту, которая будет полностью сама спасать данные из адресного пространства умирающего процесса OllyDbg, и особенно если вы будете спасать наработки отладочной сессии из отладчика, который рухнул из-за исключения при обращении по неправильному адресу, нужно обязательно учесть один важный момент.
Если вам пришлось прибегнуть к вытягиванию чего-то из зависшего или упавшего отладчика, существует ненулевая вероятность, что перед тем, как зависнуть или упасть, внутри отладчика произошло повреждение вышеописанных структур данных. Могла быть повреждена, затёрта или искажена таблица записей или строковый пул, а могли быть затёрты глобальные переменные, хранящие адреса этих двух блоков. Могло быть затронуто и то, и то.
Поэтому прежде чем что-то дампить, убедитесь, что внутри дампа окажется именно то, что вы ожидаете там увидеть. Какие меры можно предпринять, чтобы проверить, что рассмотренные выше глобальные переменные содержат актуальные значения, а не какой-нибудь мусор?
- Поскольку оба блока выделяются с помощью
VirtualAlloc(), совершенно бесспорно, что адреса блоков должны быть кратными размеру страницы (4K для x86). Если побитовое-И адреса с маской 0x00000FFF даёт ненулевой результат, значит адрес гарантированно неправильный. - Если хорошенько посмотреть на то, как именно вызывается
VirtualAlloc()внутриInsertname()и чуть-чуть подумать, становится ясно, что адрес должен быть выравнен не только по границе страниц, но и по границе SYSTEM_INFO::dwAllocationGranularity, которая для x86 составляет 64K. То есть все 16 младших бит адреса должны быть занулены, в противном случае мы имеем дело с ненастоящим адресом. - С помощью
VirtualQueryEx()можно проверить, выделен ли (был) такой регион памяти с помощьюVirtualAlloc(), какие атрибуты защиты данного региона (в нашем случае это должно бытьPAGE_READWRITE), каков размер выделенного блока и насколько он соотносится с размером, который можно получить из рассмотренных выше глобальных переменных. - Если все вышеперечисленные условия выполняются, можно оценить на «правдоподобность» содержимое самих блоков.
- У первого блока (таблицы записей) при последовательном обходе записей и проверке адресов мы не должны встретить адрес, который бы оказался меньше, чем предыдущий увиденный нами адрес — последовательность адресов должна быть неубывающей. Поле, содержащее смещение строки в строковом пуле, при рассмотрении как 32-битное знаковое число, никак не может быть отрицательным или хотя бы превышать 640 миллионов. Поле, содержащее тип сущности, не может принимать значение, отличное от констант
NM_xxxx, содержащихся в заголовочном файле из PDK. - Второй блок (строковый пул) при проверке должен содержать только нуль-терминированные строки, идущие подряд. Это означает, что до какой-то отметки при последовательном сканировании мы не должны встречать два или более нулевых
байтовсимволов, идущих подряд (за каждым нулевым байтом должен обязательно идти ненулевой байт), но после этой отметки — мы наоборот не должны встречать ничего, кроме нулевых символов вплоть до самого конца региона выделенных страниц (т.е. до самого конца блока). Иными словами, как только мы встретили два подряд идущих нулевых байтах, всё последующее содержимое блока должно состоять из нулевых байтов. - Если указатели на блоки утрачены, можно попытаться обнаружить эти блоки в АП процесса, перебирая все выделенные регионы АП и применяя к ним вышеописанные критерии (особенно два последних).
В общем, если кто-то загорится идеей написать гибкую утилиту, спасающую из памяти «подбитой Ольки» нужные данные — дерзайте, простора для действий при реализации всех этих эвристических методик очень много. Наверняка придётся включить в состав такой утилиты и дизассемблирующий движок, который мог бы сам анализировать ту же API-функцию Insertname и самостоятельно определять адреса нужных нам глобальных переменных, а не полагаться на жестко вшитые, которые могут зависеть от версии и от билда.
Что делать с дампами?
Хорошо, мы получили пару дампов для пары блоков памяти. Теперь мы можем дать возможность умирающему процессу окончательно умереть. Но что делать с этим дампами?
Дальнейшие действия зависит от того, какой именно подход вам ближе:
- В моём случае, имея плагин Markup Dumper, о котором рассказывалось в начале статьи, я предпочёл сделать простейшую дополнительную утилитку, которая из двух бинарных дампов сгенерировала один текстовый дамп (в формате, совместимом с моим плагином). Этот дамп я смерджил с лежащим в репозитории дампом, а полученный результирующий дамп импортировал с помощью своего плагина в перезапущенную OllyDbg. Я хочу ещё раз отметить, что меня интересовало только спасение 5 тысяч меток и комментариев, созданных за предшествующий день работы. Спасение сущностей другого типа (например брекпоинтов) меня не интересовало.
- Но вы можете избежать «текстовой» фазы, а загрузить сущности (причём всех поддерживаемых типов, а не только метки и комментарии) напрямую в OllyDbg, обуздав мощь API-функций, предоставляемых отладчиком для создателей плагинов к нему. Т.е. пробежаться по дампу таблицы записей и для каждой записи вызвать
Insertname()(или её аналог для транзакционного добавления большого числа записей). После этого можно штатно завершить работу отладчика, и все сущности будут сохранены в UDD-файл. - И наконец, радикальный и опасный, но технически изящный способ — после перезапуска OllyDbg загрузить содержимое файлов в АП нового процесса и модифицировать глобальные переменные этого процесса так, чтобы они указывали на новые буферы и содержали актуальные значения текущего/максимального числа хранимых элементах. После чего штатное завершение отладчика вызвало бы сохранение этих данных в UDD-файл. Без более полного реверс-инжиниринга нельзя достоверно сказать, что такая наглая манипуляция не окончится непредсказуемыми последствиями. К тому же, нужно быть уверенным, что сторонний процесс прямо в это мгновение не выполняет код, работающий именно с этими глобальными переменными.
Для первых двух способов необходимо знать описание структуры элемента массива записей, которое вплоть до этого описывалось лишь словесно, но не в виде кода. Что ж, вот оно:
typedef struct
{
DWORD Va; // virtual address of NAME in debugger process
DWORD Offset; // offset of NAME's value in string pool
DWORD Type; // one of NM_xxxxx values
} NAME_REC;Уверен, что for-цикл, перебирающий cNameEntriesCur элементов из массива и для каждого вызывающий Insertname(), передавая в качестве трёх параметров три данных поля, вы в состоянии написать самостоятельно.
P.S. Это моя первая статья на Хабре. С одной стороны, я хотел, чтобы для людей, которые попали в неприятное положение, она стала спасительной пилюлей. С другой стороны, я меньше всего хотел получить howto-статью, поэтому большую часть статьи посвятил разбору альтернативного способа, специального плагина, связанной с ним проблематики параллельной работы по реверс-инженирингу с применением Git или другой VCS, реверс-инжинирингу API-функций OllyDbg, наблюдением по недочётам кода OllyDbg, маленькими подробностями о функционировании менеджера памяти Windows или по протеканию процессе линковки. Получилось, как мне кажется, раздуто, но, надеюсь, информация станет для кого-то полезной или хотя бы интересной.






vladkorotnev
В чём преимущество OllyDbg перед x96dbg?
Олька часто зависала на многодневных отладочных сессиях, со вторым пока ни разу не было, интерфейс почти одинаковый, кроме иконок.