
Эта статья помогла мне немного углубится в устройство и принцип работы контейнеров. Поэтому решил ее перевести. "Экосистема контейнеров иногда может сбивать с толку, этот пост может помочь вам понять некоторые запутанные концепции Docker и контейнеров. Мы также увидим, как развивалась экосистема контейнеров". Статья 2019 года.
Docker - одна из самых известных платформ контейнеризации в настоящее время, она была выпущена в 2013 году. Однако использование изоляции и контейнеризации началось раньше. Давайте вернемся в 1979 год, когда мы начали использовать Chroot Jail, и посмотрим на самые известные технологии контейнеризации, появившиеся после. Это поможет нам понять новые концепции.

Все началось с того, что Chroot Jail и системный вызов Chroot были введены во время разработки версии 7 Unix в 1979 году. Chroot jail предназначен для «Change Root» и считается одной из первых технологий контейнеризации. Он позволяет изолировать процесс и его дочерние элементы от остальной части операционной системы. Единственная проблема с этой изоляцией заключается в том, что корневой процесс может легко выйти из chroot. В нем никогда не задумывались механизмы безопасности. FreeBSD Jail была представлена в ОС FreeBSD в 2000 году и была предназначена для обеспечения большей безопасности простой изоляции файлов Chroot. В отличие от Chroot, реализация FreeBSD также изолирует процессы и их действия от Файловой системы.

Когда в ядро Linux были добавлены возможности виртуализации на уровне операционной системы, в 2001 году был представлен Linux VServer, который использовал chroot-подобный механизм в сочетании с «security contexts (контекстами безопасности)», так и виртуализацию на уровне операционной системы. Он более продвинутый, чем простой chroot, и позволяет запускать несколько дистрибутивов Linux на одном VPS.

В феврале 2004 года Sun (позже приобретенная Oracle) выпустила (Oracle) Solaris Containers, реализацию Linux-Vserver для процессоров X86 и SPARC. Контейнер Solaris - это комбинация элементов управления ресурсами системы и разделения ресурсов, обеспечиваемых «zone».
Подобно контейнерам Solaris, первая версия OpenVZ была представлена в 2005 году. OpenVZ, как и Linux-VServer, использует виртуализацию на уровне ОС и был принят многими хостинговыми компаниями для изоляции и продажи VPS. Виртуализация на уровне ОС имеет некоторые ограничения, поскольку контейнеры и хост используют одну и ту же архитектуру и версию ядра, недостаток возникает в ситуациях, когда гостям требуются версии ядра, отличные от версии на хосте. Linux-VServer и OpenVZ требуют патча ядра, чтобы добавить некоторые механизмы управления, используемые для создания изолированного контейнера. Патчи OpenVZ не были интегрированы в ядро.

В 2007 году Google выпустил CGroups - механизм, который ограничивает и изолирует использование ресурсов (ЦП, память, дисковый ввод-вывод, сеть и т. д.) для набора процессов. CGroups были, в отличие от ядра OpenVZ, встроены в ядро ??Linux в 2007 году.
В 2008 году была выпущена первая версия LXC (Linux Containers). LXC похож на OpenVZ, Solaris Containers и Linux-VServer, однако он использует CGroups, которые уже реализованы в ядре Linux. Затем в 2013 году компания CloudFoundry создала Warden - API для управления изолированными, эфемерными средами с контролируемыми ресурсами. В своих первых версиях Warden использовал LXC.

В 2013 году была представлена первая версия Docker. Он выполняет виртуализацию на уровне операционной системы, как и контейнеры OpenVZ и Solaris.
В 2014 году Google представил LMCTFY, версию стека контейнеров Google с открытым исходным кодом, которая предоставляет контейнеры для приложений Linux. Инженеры Google сотрудничают с Docker над libcontainer и переносят основные концепции и абстракции в libcontainer. Проект активно не развивается, и в будущем ядро этого проекта, вероятно, будет заменено libcontainer.
LMCTFY запускает приложения в изолированных средах на том же ядре и без патчей, поскольку он использует CGroups, namespases и другие функции ядра Linux.

Google - лидер в контейнерной индустрии. Все в Google работает на контейнерах. Каждую неделю в инфраструктуре Google работает более 2 миллиардов контейнеров.
В декабре 2014 года CoreOS выпустила и начала поддерживать rkt (первоначально выпущенную как Rocket) в качестве альтернативы Docker.

Jails, VPS, Zones, контейнеры и виртуальные машины
Изоляция и управление ресурсами являются общими целями использования Jail, Zone, VPS, виртуальных машин и контейнеров, но каждая технология использует разные способы достижения этого, имеет свои ограничения и свои преимущества.
До сих пор мы вкратце видели, как работает Jail, и представили, как Linux-VServer позволяет запускать изолированные пользовательские пространства, в которых программы запускаются непосредственно в ядре операционной системы хоста, но имеют доступ к ограниченному подмножеству его ресурсов.
Linux-VServer позволяет запускать VPS, и для его использования необходимо пропатчить ядро ??хоста.
Контейнеры Solaris называются Zones.
«Виртуальная машина» - это общий термин для описания эмулируемой виртуальной машины поверх «реальной аппаратной машины». Этот термин был первоначально определен Попеком и Голдбергом как эффективная изолированная копия реальной компьютерной машины.
Виртуальные машины могут быть «System Virtual Machines (системными виртуальными машинами)» или «Process Virtual Machines (процессными виртуальными машинами)». В повседневном использовании под словом «виртуальные машины» мы обычно имеем в виду «системные виртуальные машины», которые представляют собой эмуляцию оборудования хоста для эмуляции всей операционной системы. Однако «Process Virtual Machines», иногда называемый «Application Virtual Machine (Виртуальной машиной приложения)», используется для имитации среды программирования для выполнения отдельного процесса: примером является виртуальная машина Java.
Виртуализация на уровне ОС также называется контейнеризацией. Такие технологии, как Linux-VServer и OpenVZ, могут запускать несколько операционных систем, используя одну и ту же архитектуру и версию ядра.
Совместное использование одной и той же архитектуры и ядра имеет некоторые ограничения и недостатки в ситуациях, когда гостям требуются версии ядра, отличные от версии хоста.

Системные контейнеры (например, LXC) предлагают среду, максимально приближенную к той, которую вы получаете от виртуальной машины, но без накладных расходов, связанных с запуском отдельного ядра и имитацией всего оборудования.

Контейнеры ОС vs контейнеры приложений
Виртуализация на уровне ОС помогает нам в создании контейнеров. Такие технологии, как LXC и Docker, используют этот тип изоляции.
Здесь у нас есть два типа контейнеров:
Контейнеры ОС, в которые упакована операционная система со всем стеком приложений (пример LEMP).
Контейнеры приложений, которые обычно запускают один процесс для каждого контейнера.
В случае с контейнерами приложений у нас будет 3 контейнера для создания стека LEMP:
сервер PHP (или PHP FPM).
Веб-сервер (Nginx).
Mysql.

Докер: контейнер или платформа?
Коротко: и то и другое

Подробный ответ:
Когда Docker начал использовать LXC в качестве среды выполнения контейнера, идея заключалась в том, чтобы создать API для управления средой выполнения контейнера, изолировать отдельные процессы, выполняющие приложения, и контролировать жизненный цикл контейнера и ресурсы, которые он использует. В начале 2013 года проект Docker должен был создать «стандартный контейнер», как мы можем видеть в этом манифесте.

Манифест стандартного контейнера был удален.

Docker начал создавать монолитное приложение с множеством функций - от запуска облачных серверов до создания и запуска образов / контейнеров. Docker использовал libcontainer для взаимодействия с такими средствами ядра Linux, как Control Groups и Namespaces.

Давайте создадим контейнер с использованием СGroups и Namespaces
В этом примере я использую Ubuntu, но это должно работать для большинства дистрибутивов. Начните с установки CGroup Tools and утилиты stress, поскольку мы собираемся выполнить некоторые стресс-тесты.
sudo apt install cgroup-tools
sudo apt install stressЭта команда создаст новый контекст исполнения:
sudo unshare --fork --pid --mount-proc bash
ps aux
Команда "unshare" разъединяет части контекста исполнения процесса
Теперь, используя cgcreate, мы можем создать группы управления и определить два контроллера: один в памяти, а другой - в процессоре.
cgcreate -a $USER -g memory:mygroup -g cpu:mygroup
ls /sys/fs/cgroup/{memory,cpu}/mygroup
Следующим шагом будет определение лимита памяти и его активация:
echo 3000000 > /sys/fs/cgroup/memory/mygroup/memory.kmem.limit_in_bytes
cgexec -g memory:mygroup bash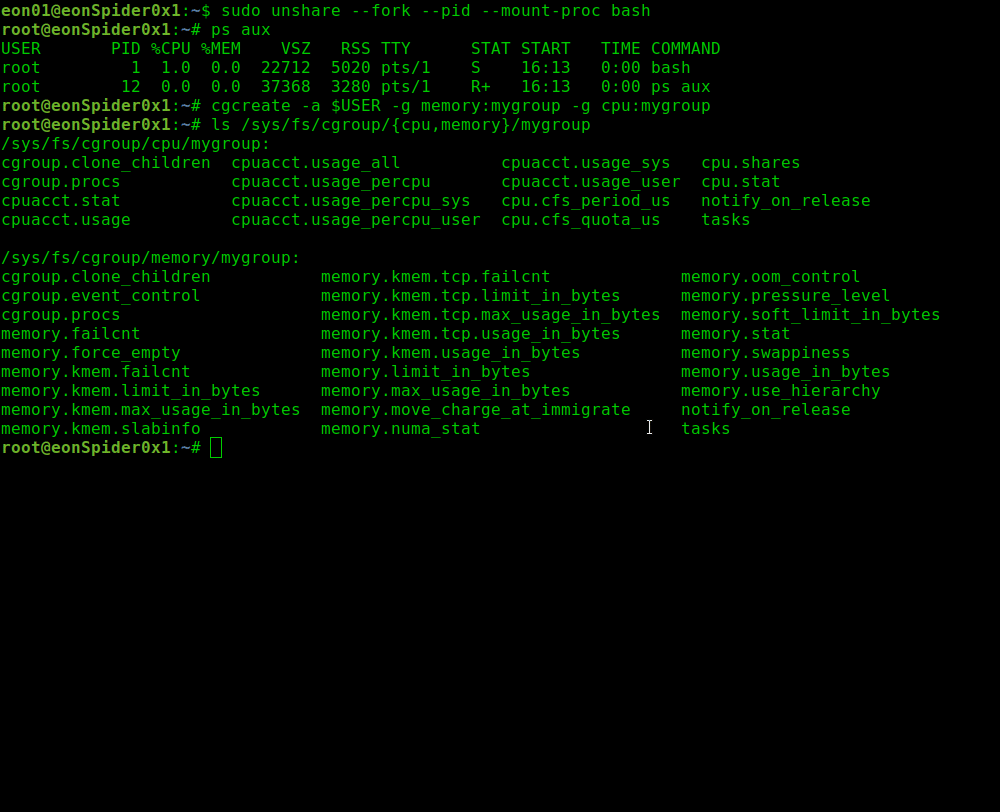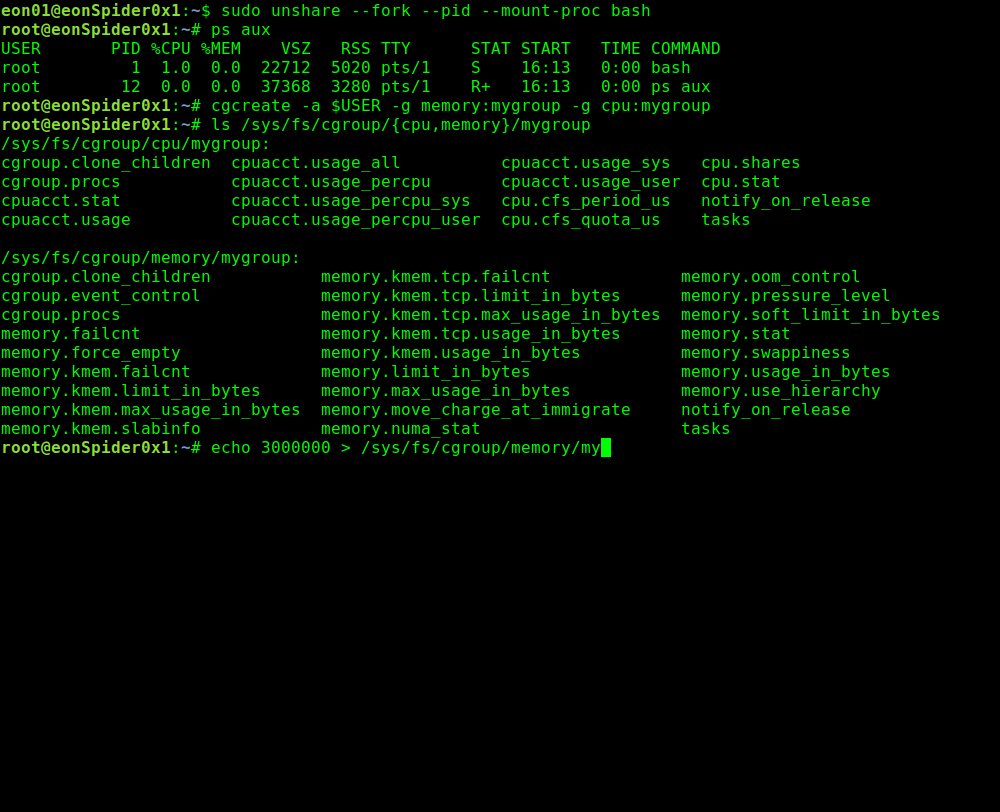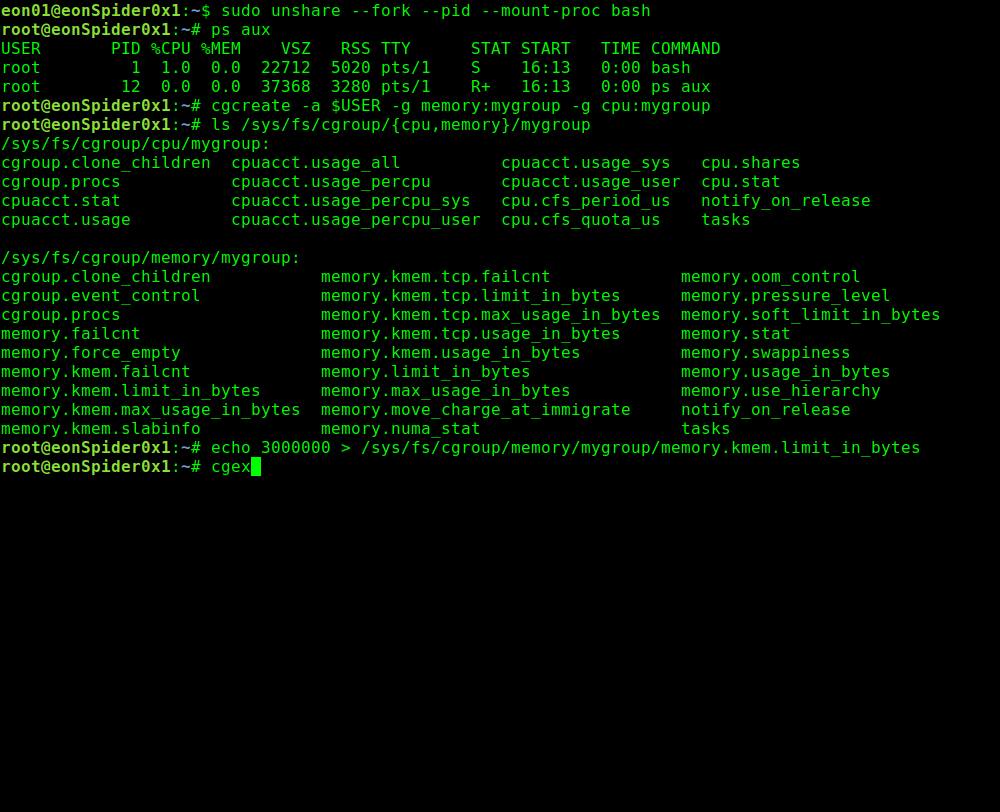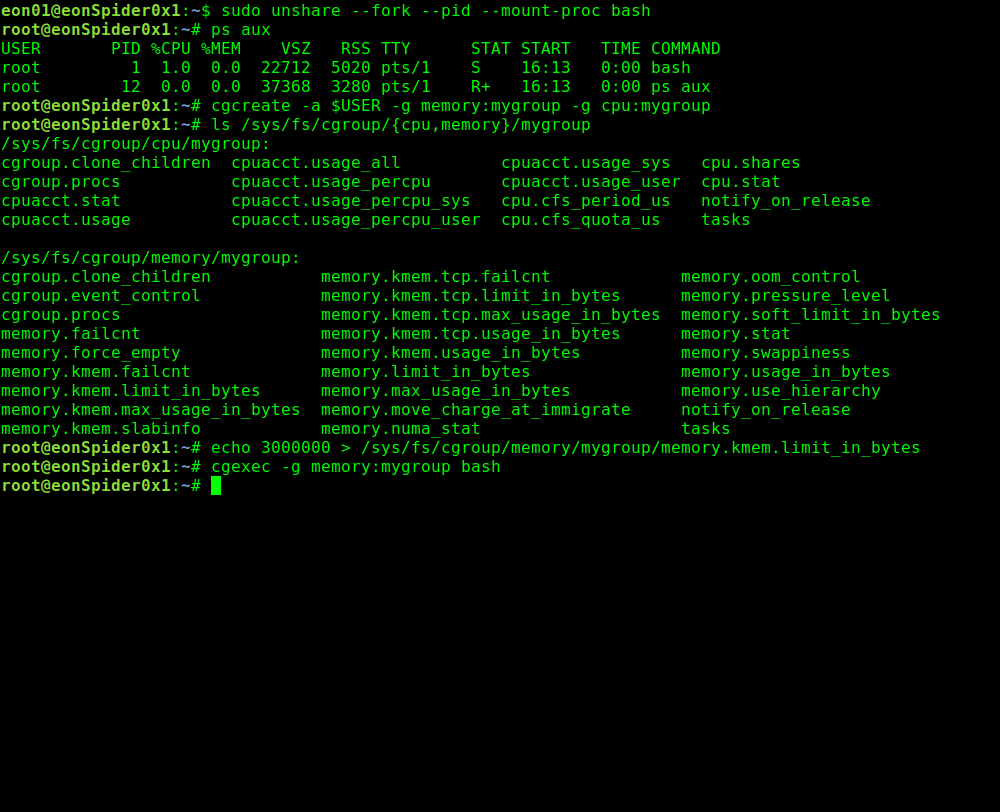
Теперь давайте запустим stress для изолированного namespace, которое мы создали с ограничениями памяти.
stress --vm 1 --vm-bytes 1G --timeout 10s
Мы можем заметить, что выполнение не удалось, значит ограничение памяти работает. Если мы сделаем то же самое на хост-машине, тест завершится без ошибки, если у вас действительно достаточно свободной памяти:

Выполнение этих шагов поможет понять, как средства Linux, такие как CGroups и другие функции управления ресурсами, могут создавать изолированные среды в системах Linux и управлять ими.
Интерфейс libcontainer взаимодействует с этими средствами для управления контейнерами Docker и их запуска.
runC: Использование libcontainer без Docker
В 2015 году Docker анонсировал runC: легкую портативную среду выполнения контейнеров.

runC - это, по сути, небольшой инструмент командной строки для непосредственного использования libcontainer, без использования Docker Engine.
Цель runC - сделать стандартные контейнеры доступными повсюду.
Этот проект был передан в дар Open Container Initiative (OCI).
Репозиторий libcontainer сейчас заархивирован. На самом деле, libcontainer не забросили, а перенесли в репозиторий runC.
Перейдем к практической части и создадим контейнер с помощью runC. Начните с установки среды выполнения runC (прим. переводчика: если стоит docker то этого можно (нужно) не делать):
sudo apt install runcДавайте создадим каталог (/mycontainer), в который мы собираемся экспортировать содержимое образа Busybox.

sudo su
mkdir /mycontainer
cd /mycontainer/
mkdir rootfs
docker export $(docker create busybox) | tar -C rootfs -xvf -Используя команду runC, мы можем запустить контейнер busybox, который использует извлеченный образ и файл спецификации (config.json).

runc spec
runc run mycontainerid
Команда runc spec изначально создает этот файл JSON:
{
"ociVersion": "1.0.1-dev",
"process": {
"terminal": true,
"user": {
"uid": 0,
"gid": 0
},
"args": [
"sh"
],
"env": [
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin",
"TERM=xterm"
],
"cwd": "/",
"capabilities": {
"bounding": [
"CAP_AUDIT_WRITE",
"CAP_KILL",
"CAP_NET_BIND_SERVICE"
],
"effective": [
"CAP_AUDIT_WRITE",
"CAP_KILL",
"CAP_NET_BIND_SERVICE"
],
"inheritable": [
"CAP_AUDIT_WRITE",
"CAP_KILL",
"CAP_NET_BIND_SERVICE"
],
"permitted": [
"CAP_AUDIT_WRITE",
"CAP_KILL",
"CAP_NET_BIND_SERVICE"
],
"ambient": [
"CAP_AUDIT_WRITE",
"CAP_KILL",
"CAP_NET_BIND_SERVICE"
]
},
"rlimits": [
{
"type": "RLIMIT_NOFILE",
"hard": 1024,
"soft": 1024
}
],
"noNewPrivileges": true
},
"root": {
"path": "rootfs",
"readonly": true
},
"hostname": "runc",
"mounts": [
{
"destination": "/proc",
"type": "proc",
"source": "proc"
},
{
"destination": "/dev",
"type": "tmpfs",
"source": "tmpfs",
"options": [
"nosuid",
"strictatime",
"mode=755",
"size=65536k"
]
},
{
"destination": "/dev/pts",
"type": "devpts",
"source": "devpts",
"options": [
"nosuid",
"noexec",
"newinstance",
"ptmxmode=0666",
"mode=0620",
"gid=5"
]
},
{
"destination": "/dev/shm",
"type": "tmpfs",
"source": "shm",
"options": [
"nosuid",
"noexec",
"nodev",
"mode=1777",
"size=65536k"
]
},
{
"destination": "/dev/mqueue",
"type": "mqueue",
"source": "mqueue",
"options": [
"nosuid",
"noexec",
"nodev"
]
},
{
"destination": "/sys",
"type": "sysfs",
"source": "sysfs",
"options": [
"nosuid",
"noexec",
"nodev",
"ro"
]
},
{
"destination": "/sys/fs/cgroup",
"type": "cgroup",
"source": "cgroup",
"options": [
"nosuid",
"noexec",
"nodev",
"relatime",
"ro"
]
}
],
"linux": {
"resources": {
"devices": [
{
"allow": false,
"access": "rwm"
}
]
},
"namespaces": [
{
"type": "pid"
},
{
"type": "network"
},
{
"type": "ipc"
},
{
"type": "uts"
},
{
"type": "mount"
}
],
"maskedPaths": [
"/proc/kcore",
"/proc/latency_stats",
"/proc/timer_list",
"/proc/timer_stats",
"/proc/sched_debug",
"/sys/firmware",
"/proc/scsi"
],
"readonlyPaths": [
"/proc/asound",
"/proc/bus",
"/proc/fs",
"/proc/irq",
"/proc/sys",
"/proc/sysrq-trigger"
]
}
}Альтернативой для создания кастомной спецификации конфигурации является использование «oci-runtime-tool», подкоманда «oci-runtime-tool generate» имеет множество опций, которые можно использовать для выполнения разных настроек.
Для получения дополнительной информации см. Runtime-tools.
Используя сгенерированный файл спецификации JSON, вы можете настроить время работы контейнера. Мы можем, например, изменить аргумент для выполнения приложения.
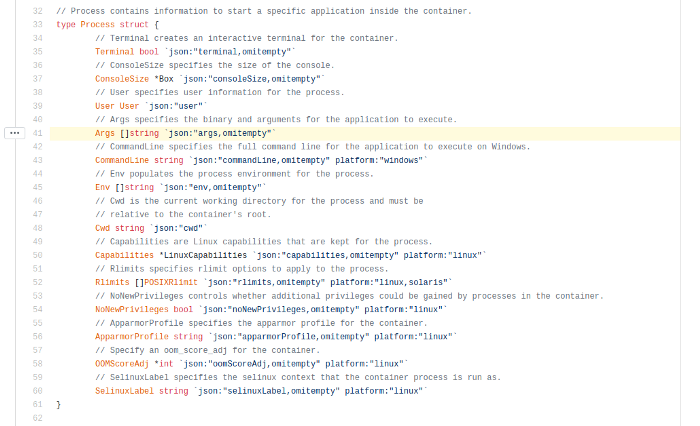
Давайте посмотрим, чем отличается исходный файл config.json от нового:

Давайте теперь снова запустим контейнер и заметим, как он ожидает 10 секунд, прежде чем завершится.
Стандарты сред исполнения контейнеров
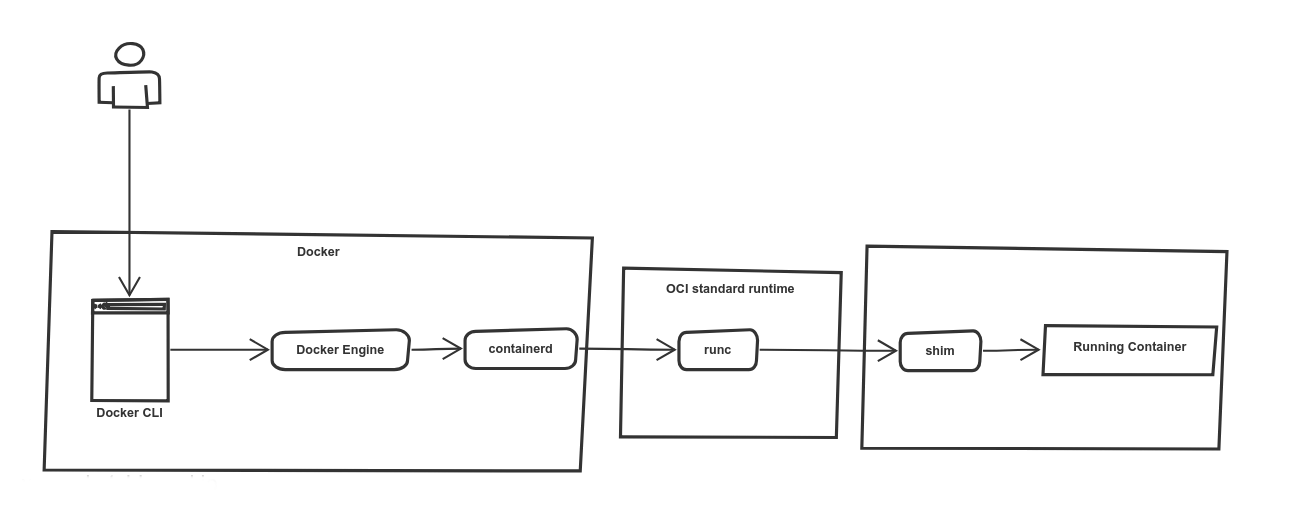
С тех пор, как контейнеры стали широко распространенными, различные участники этой экосистемы работали над стандартизацией. Стандартизация - ключ к автоматизации и обобщению передового опыта. Передав проект runC OCI, Docker начал использовать containerd в 2016 году в качестве среды выполнения контейнера, взаимодействующей с базовой средой исполнения низкого уровня runC.
docker info | grep -i runtime
Containerd полностью поддерживает запуск пакетов OCI и управление их жизненным циклом. Containerd (как и другие среды выполнения, такие как cri-o) использует runC для запуска контейнеров, но реализует также другие высокоуровневые функции, такие как управление образами и высокоуровневые API.

Сontainerd, Shim и RunC, как все работает вместе
runC построен на libcontainer, который является той же библиотекой, которая ранее использовалась для Docker Engine.
До версии 1.11 Docker Engine использовался для управления томами, сетями, контейнерами, образами и т. д.
Теперь архитектура Docker разбита на четыре компонента:
Docker engine
containerd
containerd-shim
runC
Бинарные файлы соответственно называются docker, docker-containerd, docker-containerd-shim и docker-runc.
Давайте перечислим этапы запуска контейнера с использованием новой архитектуры docker:
Docker engine создает контейнер (из образа) и передает его в containerd.
Containerd вызывает containerd-shim
Containerd-shim использует runC для запуска контейнера
Containerd-shim позволяет среде выполнения (в данном случае runC) завершиться после запуска контейнера
Используя эту новую архитектуру, мы можем запускать «контейнеры без служб» (“daemon-less containers”), и у нас есть два преимущества:
runC может завершиться после запуска контейнера, и нам не нужны запущенными все процессы исполнения.
containerd-shim сохраняет открытыми файловые дескрипторы, такие как stdin, stdout и stderr, даже когда Docker и /или containerd завершаются.
«Если runC и Containerd являются средами исполнения, какого черта мы используем оба для запуска одного контейнера?»
Это, наверное, один из самых частых вопросов. Поняв, почему Docker разбил свою архитектуру на runC и Containerd, вы понимаете, что оба являются средами исполнения.
Если вы следили за историей с самого начала, вы, вероятно, заметили использование сред исполнения высокого и низкого уровня. В этом практическая разница между ними.
Обе они могут называться средами исполнения, но каждая среда исполнения имеет разные цели и функции. Чтобы сохранить стандартизацию экосистемы контейнеров, среда исполнения низкоуровневых контейнеров позволяет запускать только контейнеры.
Среда исполнения низкого уровня (например, runC) должна быть легкой, быстрой и не конфликтовать с другими более высокими уровнями управления контейнерами. Когда вы создаете контейнер Docker, он фактически управляет двумя средами исполнения containerd и runC.
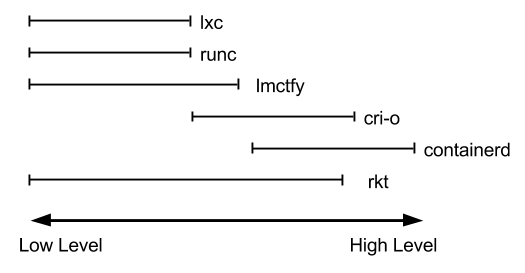
Вы можете найти множество сред исполнения контейнеров, некоторые из них стандартизированы OCI, а другие нет, некоторые являются средами исполнения низкого уровня, а другие представляют собой нечто большее и реализуют уровень инструментов для управления жизненным циклом контейнеров и многое другое:
передача и хранение образов,
завершение и наблюдение за контейнерами,
низкоуровневое хранилище,
сетевые настройки,
и т.п.
Мы можем добавить новую среду исполнения с помощью Docker, выполнив:
sudo dockerd --add-runtime=<runtime-name>=<runtime-path> Например:
sudo apt-get install nvidia-container-runtime
sudo dockerd --add-runtime=nvidia=/usr/bin/nvidia-container-runtimeИнтерфейс среды исполнения контейнера (Container Runtime Interface)
Kubernetes - одна из самых популярных систем оркестровки. С ростом числа сред выполнения контейнеров Kubernetes стремится быть более расширяемым и взаимодействовать с большим количеством сред выполнения контейнеров, помимо Docker.
Первоначально Kubernetes использовал среду исполнения Docker для запуска контейнеров, и она по-прежнему остается средой исполнения по умолчанию.
Однако CoreOS хотела использовать Kubernetes со средой исполнения RKT и предлагала патчи для Kubernetes, чтобы использовать эту среду исполнения в качестве альтернативы Docker.
Вместо изменения кодовой базы kubernetes в случае добавлении новой среды исполнения контейнера создатели Kubernetes решили создать CRI (Container Runtime Interface), который представляет собой набор API-интерфейсов и библиотек, позволяющих запускать различные среды исполнения контейнеров в Kubernetes. Любое взаимодействие между ядром Kubernetes и поддерживаемой средой выполнения осуществляется через CRI API.

Вот некоторые из плагинов CRI:
CRI-O:
CRI-O - это первая среда исполнения контейнера, созданная для интерфейса CRI kubernetes. Cri-O не предназначен для замены Docker, но его можно использовать вместо среды исполнения Docker в Kubernetes.

Containerd CRI :
С cri-containerd пользователи могут запускать кластеры Kubernetes, используя containerd в качестве базовой среды исполнения без установленного Docker.

gVisor CRI:
gVisor - это проект, разработанный Google, который реализует около 200 системных вызовов Linux в пользовательском пространстве для дополнительной безопасности по сравнению с контейнерами Docker, которые работают непосредственно поверх ядра Linux и изолированы с помощью namespace.

Google Cloud App Engine использует gVisor CRI для изоляции клиентов.
Среда исполнения gVisor интегрируется с Docker и Kubernetes, что упрощает запуск изолированных контейнеров.
CRI-O Kata Containers

Kata Containers - это проект с открытым исходным кодом, создающий легкие виртуальные машины, которые подключаются к экосистеме контейнеров. CRI-O Kata Containers позволяет запускать контейнеры Kata в Kubernetes вместо среды выполнения Docker по умолчанию.
Проект Moby
От проекта создания Docker как единой монолитной платформы отказались и родился проект Moby, в котором Docker состоит из множества компонентов, таких как RunC.

Moby - это проект по организации и разделения на модули Docker. Это экосистема разработки. Обычные пользователи Docker не заметят никаких изменений.

Moby помогает в разработке и запуске Docker CE и EE (Moby - это исходный код Docker), а также в создании среды разработки для других сред исполнения и платформ.
Open Containers Initiative
Как мы видели, Docker пожертвовал RunC Open Container Initiative (OCI), но что это?
OCI - это открытая структура, запущенная в 2015 году Docker, CoreOS и другими лидерами контейнерной индустрии.
Open Container Initiative (OCI) направлена на установление общих стандартов для контейнеров, чтобы избежать потенциальной фрагментации и разделения внутри экосистемы контейнеров.

Он содержит две спецификации:
runtime-spec: спецификация исполнения
image-spec: спецификация образов
Контейнер, использующий другую среду исполнения, можно использовать с Docker API. Контейнер, созданный с помощью Docker, должен работать с любым другим движком.
На этом статья заканчивается.
Буду рад замечаниям и возможно неточностям в статье оригинального автора. Это позволит избежать заблуждений в понимании внутреннего устройства контейнеров. Если нет возможности комментирования на Хабре, можете обсудить тут в комментариях.
ppnn
— Using the generated specification JSON file, you can customize the runtime of the container.
— Используя сгенерированный файл спецификации JSON, вы можете настроить время работы контейнера.
всё же runtime это не «время работы»
il_da_r Автор
В данном случае время работы — параметром «sleep 10»