
В преддверии старта курса "Microservice Architecture" подготовили для вас традиционный перевод материала.

При проектировании и планировании новой архитектуры на основе (микро) сервисов бывают моменты, когда архитекторам приходится думать о стратегии развертывания и, следовательно, задаваться вопросом: «Должны ли мы развернуть этот (микро) сервис как бессерверную функцию или лучше поместить его в контейнер? Или, быть может, лучше использовать выделенную виртуальную машину (VM)?»
Как это часто бывает в наши дни, есть только один ответ: «Это зависит от обстоятельств». Даже больше — это не только «зависит», это также может «меняться в зависимости». Сегодняшнее оптимальное решение может стать очень неоптимальным через несколько месяцев. При запуске нового приложения выбор бессерверных функций может быть целесообразен, поскольку они быстро настраиваются и требуют относительно небольших предварительных вложений.
Кроме того, их модель оплаты по мере использования (“pay per use”) очень привлекательна, когда мы не уверены, какая нагрузка придется на наше приложение. Позже, когда сервис станет зрелым и нагрузка станет предсказуемой, может оказаться целесообразным перейти к более традиционной топологии развертывания, основанной на контейнерах или выделенных серверах.
Поэтому при разработке новых систем облачной эпохи важно закладывать некоторое пространство для маневров, то бишь изменений стратегии развертывания различных (микро) сервисов с наименьшими затратами. Правильная инфраструктура в правильное время может результировать в значительной экономии на облачных расходах.
Бессерверные функции
Бессерверные функции (Serverless Functions, также известные как FaaS, функция как сервис) - это блоки определенной логики, которые создаются и выполняются в ответ на заданные события, такие как HTTP-запросы или сообщения, полученные в топике Kafka. По завершении своего выполнения такие функции исчезают, по крайней мере, логически, и их стоимость возвращается к нулю.

Все крупные общедоступные облака имеют FAAS предложения (AWS Lambda, Azure Functions, Google Functions, Oracle Cloud Functions). Кроме того FAAS также могут быть доступны в локальных вариациях с помощью таких фреймворков, как Apache OpenWhisk. У них есть некоторые ограничения с точки зрения ресурсов (например, для AWS максимум 10 ГБ памяти и 15 минут времени выполнения), но они могут покрыть многие варианты использования современных приложений.
Степень модульности бессерверной функции может варьироваться. От единственной, очень сфокусированной ответственности, например, создания SMS-сообщения при подтверждении заказа, до полноценного микросервиса, который может работать бок о бок с другими микросервисами, реализованными в контейнерах или работающими на виртуальных машинах (в этой беседе Сэм Ньюман подробно описывает взаимосвязь между FaaS и микросервисами).

Преимущества FaaS
Когда бессерверные функции простаивают, они ничего вам не стоят (модель «Pay per use»). Если бессерверная функция вызывается 10 клиентами одновременно, 10 ее инстансов запускаются почти одновременно (по крайней мере, в большинстве случаев). Полное предоставление инфраструктуры, управление, высокая доступность (по крайней мере, до определенного уровня) и масштабирование (от 0 до лимитов, определенных клиентом) полностью предоставляются командами специалистов, работающих за кулисами.
Бессерверные функции обеспечивают эластичность на стероидах и позволяют сфокусироваться на том, что выделяет ваш бизнес среди других.
Таким образом, FaaS подразумевает два больших преимущества.
Эластичность на стероидах: масштабирование вверх и вниз по необходимости и оплата только за то, что используется.
Фокус на том, что отличает ваш бизнес: сконцентрируйте силы на разработке наиболее важных приложений, не тратя драгоценную энергию на сложные области, такие как современные инфраструктуры, которые FaaS предлагает вам в качестве товара.
Эластичность и затраты
«Хорошее сервис» подразумевает, помимо прочего, стабильно хорошее время отклика. Ключевым моментом здесь является согласованность: она должна быть хорошей как при нормальной, так и при максимальной нагрузке приложения.
«Новый сервис» должен быстро выходить на рынок с минимально возможными стартовыми вложениями и с самого начала должен быть «хорошим сервисом».
Когда мы хотим запустить новый сервис, модель FaaS, вероятно, будет лучшим выбором. Бессерверные функции можно быстро настроить и минимизировать затраты на инфраструктуру. Их модель «pay per use» подразумевает отсутствие стартовых вложений. Их возможности масштабирования обеспечивают стабильное время отклика при различных уровнях нагрузки.
Если по прошествии некоторого времени нагрузка станет более стабильной и предсказуемой, тогда ситуация может измениться, и более традиционная модель, основанная на выделенных ресурсах, будь то кластеры Kubernetes или виртуальные машины, может стать более удобной, чем FaaS.
Различные профили нагрузки могут вызвать резкую разницу в счетах за облако при сравнении FaaS с решениями, основанными на выделенных ресурсах.
Но насколько большой может быть разница в затратах? Как всегда, это зависит от конкретного случая, но что не вызывает сомнений так это то, что неправильный выбор может иметь большое влияние на счет за облако.
Бессерверные функции могут СЭКОНОМИТЬ ВАМ МНОГО ДЕНЕГ, ровно также как и могут СТОИТЬ ВАМ БОЛЬШИХ ДЕНЕГ
Оценка затрат на облако сама по себе уже становится отдельной наукой, но все равно мы можем почувствовать потенциальные преимущества одной модели над другой, используя прайс-лист AWS на момент написания стаьи.
Пример приложения. Рассмотрим приложение, которое получает 3.000.000 запросов в месяц. Обработка каждого запроса с помощью Lambda с 4 ГБ памяти занимает 500 мс (ЦП назначается автоматически в зависимости от памяти).
FaaS имеет модель “pay per use”, поэтому, независимо от кривой нагрузки (будь то пиковая или фиксированная), стоимость в месяц является фиксированной: 100,60 долларов США.
С другой стороны, если мы рассмотрим модель, основанную на выделенных виртуальных машинах, все будет по-другому, и стоимость сильно зависит от формы кривой нагрузки.
Сценарий с пиками нагрузки. Если для нагрузки характерны пиковые моменты, и мы хотим гарантировать постоянное хорошее время отклика для наших клиентов, нам необходимо определить размер инфраструктуры, чтобы выдерживать пиковую нагрузку. Если на пике у нас есть 10 одновременных запросов в секунду (что вполне возможно, если 3.000.000 запросов сосредоточены в определенные часы дня или в определенные дни, например, в конце месяца), вполне возможно, что нам понадобится виртуальная машина (AWS EC2) с 8 процессорами и 32 ГБ памяти, чтобы обеспечить ту же производительность, что и Lambda. В этом случае ежемесячная стоимость подскочит до 197,22 долларов США (можно сэкономить при заключении многолетнего контракта, но это снижает финансовую гибкость). Затраты увеличились почти вдвое. Эту разницу можно уменьшить путем динамического включения и выключения экземпляров EC2 в зависимости от нагрузки, но для этого требуется, чтобы нагрузка была предсказуемой, что увеличивает сложность и стоимость решения.
Сценарий с равномерной нагрузкой. Если нагрузка в основном равномерная, то дела обстоят совсем по другому. Если нет пиков, то мы можем легко выдержать нагрузку с помощью гораздо более дешевой машины. Вероятно, будет достаточно виртуальной машины с 2 процессорами и 8 МБ памяти, а ежемесячные затраты в этом случае составят 31,73 доллара США, что меньше трети стоимости Lambda.
Реалистичное экономическое обоснование намного сложнее и требует тщательного анализа, но, просто глядя на эти упрощенные сценарии, становится ясно, что модель FaaS может быть очень привлекательной в некоторых случаях, но может стать очень обременительной при других обстоятельствах. Поэтому очень важно иметь возможность изменять модель развертывания соответствующим образом.
Тут возникает вопрос: как мы можем достичь такой гибкости? Насколько это будет сложно?
Анатомия кодовой базы современного приложения
При использовании современных методов разработки кодовая база приложения обычно разбивается на логические области
Логика приложения. Код (обычно написанный на таких языках, как Java, TypeScript или Go), который реализует то, что должно делать наше приложение
DevSecOps (CI/CD). Обычно это скрипты и файлы конфигурации, которые автоматизируют сборку, тестирование, проверки безопасности и развертывание приложения.
Логика приложения
Мы можем разделить логику приложения бэкенд сервиса на логические части
Бизнес-логика. Код, который реализует поведение службы, выраженное в форме логических API (методов или функций), которые обычно ожидают некоторые данные, например, в формате JSON, в качестве входных и возвращают некоторые данные в качестве выходных. Этот код не зависит от технических механизмов, связанных с реальной средой, в которой он выполняется, будь то контейнер, бессерверная функция или сервер приложения. Находясь в контейнере, эти логические API могут быть вызваны чем-нибудь наподобие Spring Boot (если языком является Java), Express (с Node) или Gorilla (с Go). При вызове в бессерверной функции он будет использовать конкретный механизм FaaS, реализованный конкретным облачным провайдером.
Код, связанный с развертыванием. Код, который касается механики среды выполнения. Если необходимо поддерживать более одной модели развертывания, должны быть разные реализации этой части (но только этой части). В случае развертывания в контейнерах это та часть, где сосредоточены зависимости от аналогов Spring Boot, Express или Gorilla. В случае FaaS эта часть будет содержать код, реализующий механизмы, определенные конкретным облачным провайдером (функции AWS Lambda, Azure или Google Cloud, которые имеют собственные проприетарные библиотеки для вызова бизнес-логики).

Для обеспечения гибкости стратегии развертывания с минимально возможными затратами крайне важно четко разделять эти две части, что подразумевает:
«Кода, связанный с развертыванием» импортирует модули «бизнес-логики»
«Бизнес-логика» никогда не импортирует какие-либо модули/пакеты, которые зависят от конкретной среды выполнения.
Следуя этим двум простым правилам, мы максимизируем объем кода (бизнес-логики), пригодного для использования всеми моделями развертывания, и, следовательно, минимизируем стоимость перехода от одной модели к другой.
Невозможно абстрактно оценить относительные размеры частей «бизнес-логики» и «кода, связанного с развертыванием». Но на примере, анализируя одну простую интерактивную игру, развертываемую как на AWS Lambda, так и на Google Application Engine, выясняется, что «код, связанный с развертыванием», составляет 6% от кодовой базы (всего около 7 200 строк кода). Таким образом, 94% кодовой базы одинаковы, независимо от того, работает ли служба в Lambda или в контейнере.
DevSecOps (CI/CD)
Это часть кодовой базы, отвечающая за автоматизацию сборки, тестирования (включая шлюзы безопасности) и развертывания приложения.
Этапы сборки и развертывания по своей природе сильно зависят от фактической среды выполнения, выбранной для выполнения сервиса. Если мы выберем контейнеры, то на этапе сборки, скорее всего, будут использоваться инструменты Docker. Если мы выберем поставщика FaaS, этапа сборки как такового не будет, но будут команды для загрузки кода в механизм FaaS и инструктирования на точке входа при вызове бессерверной функции. Точно так же могут быть проверки безопасности, специфичные для модели FaaS.
В то же время, если мы обеспечим четкое разделение между «бизнес-логикой» и «кодом, связанным с развертыванием», мы также сможем получить большие преимущества, когда дело доходит до тестирования. Если «бизнес-логика» и «код, связанный с развертыванием» разделены, модульные и, что наиболее важно, интеграционные тесты могут быть запущены независимо от конечной модели развертывания, выбрав простейшую конфигурацию и запустив для нее наборы тестов. Тесты можно запускать даже на рабочих станциях разработчиков, что значительно увеличивает скорость тестового фидбека.
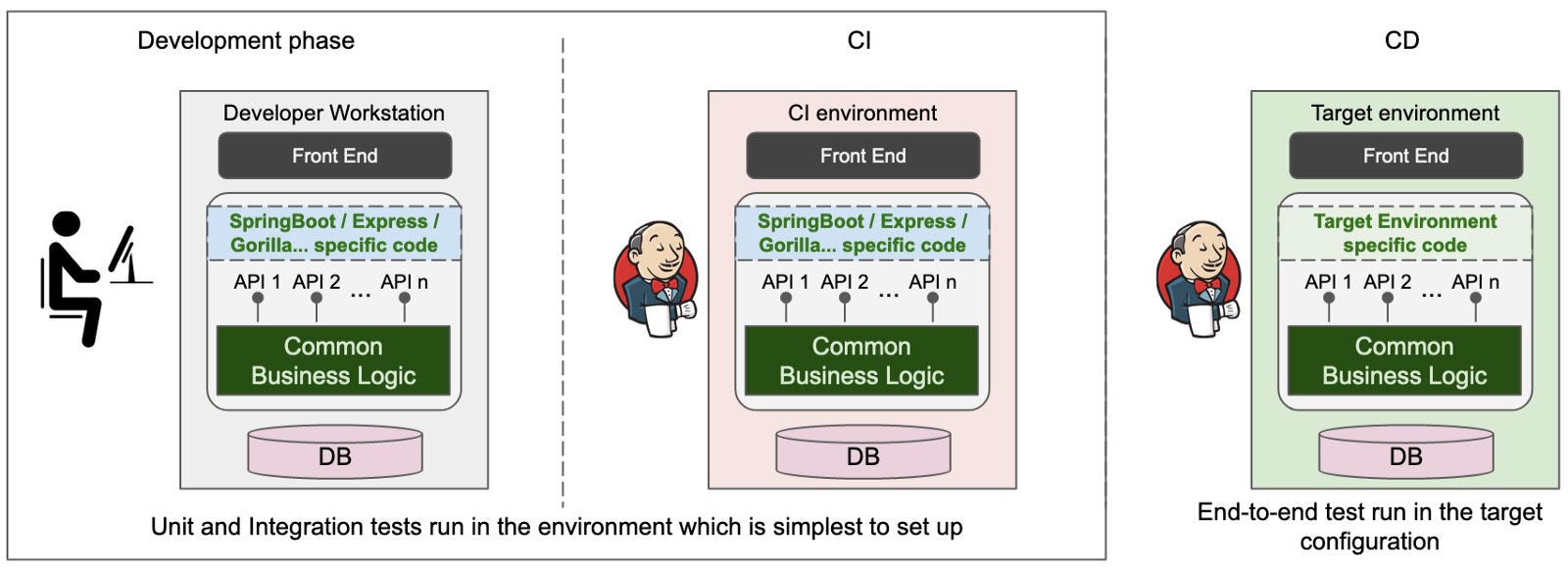
По-прежнему существует потребность в некоторых этапах тестирования после завершения развертывания, но основная часть тестовой работы, которая является проверкой правильности «бизнес-логики», может быть выполнена независимо от развертывания, что значительно повышает продуктивность разработчиков.
Стремитесь изолировать то, что не зависит от модели развертывания, и максимизировать это
Если мы хотим быть гибкими в выборе модели развертывания, мы должны сохранять четкие границы между тем, что относится к «коду, связанному с развертыванием», и тем, что является независимым. Это означает, что наши решения нужно продумывать заранее, чтобы минимизировать первое и максимизировать второе, а также обеспечить четкое разделение этих частей на протяжении всего жизненного цикла проекта/продукта, возможно, используя регулярные ревью дизайна и кода.

Заключение
Бессерверные функции представляют собой отличное решение для современных архитектур. Они предлагают самое быстрое время выхода на рынок, самую низкую стоимость входа и самую высокую эластичность. По этим причинам они являются лучшим выбором, когда нам нужно вывести на рынок новый продукт или когда нам приходится сталкиваться с очень непостоянными нагрузками.
Но со временем все может измениться. Нагрузки могут стать более стабильными и предсказуемыми, и в таких обстоятельствах модели FaaS могут оказаться намного дороже, чем более традиционные модели, основанные на выделенных ресурсах.
Поэтому важно сохранять гибкость для изменения моделей развертывания приложений с минимально возможными затратами. Это может быть достигнуто путем обеспечения четкого разделения между тем, что является ядром логики приложения, которое не зависит от платформы, на которой оно работает, и тем, что зависит от конкретной выбранной модели развертывания.
Следуя этим нескольким простым рекомендациям по архитектуре с самого начала и включив регулярные процессы экспертной оценки, мы можем сохранить эту гибкость.
Узнать подробнее о курсе "Microservice Architecture".
a-l-e-x
Я может что-то упустил, но на GCP «Google Application Engine» совсем не аналог «AWS Lambda» на AWS… И ценообразование для них будет сильно отличаться… И только в некоторых очень ограниченных случаях будет бесплатным то, что развёрнуто на Application Engine (и при этом не используется).
В целом я согласен, что бизнес логика и CI/CD желательно не смешивать, но сценарий, при котором одну и ту же бизнес логику (lambda function, cloud fucntion) нужно одновременно развернуть и на AWS и на GCP, к примеру, мне кажется несколько надуманным.