
Экстенсивный рост количества неструктурированных данных (твитов, постов, комментов, фото и видео), генерируемый человечеством – и фантастические возможности, и головная боль для многих старых и новых индустрий.
На днях мы уже приводили фактографию по объемам количества сообщений, производимых человечеством в сутки, понятно, что миллиарды высказываний требуют совершенно других решений и технологий. «Старые» (ужас, прошло 3-5 лет, и уже старые) подходы и люди, их разрабатывающие, борются за место под солнцем. Но…
В качестве классического примера приводим перевод недавнего материала от подразделения IBM Watson:
======
IBM Watson может распознавать эмоциональный тон сообщения
(источник)
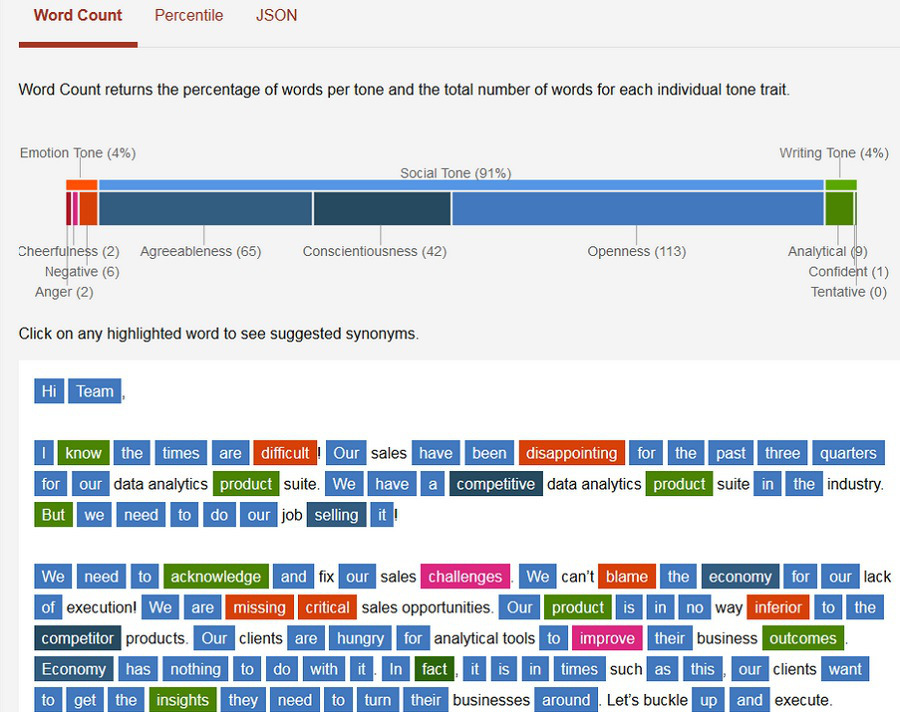
Исследователи из IBM создали IBM Watson Tone Analyzer, приложение для суперкомпьютеров, которое может сообщение прочитать и определить передаваемые в нём эмоции.
Эта задача из разряда тех, что естественно легко выполняется человеком, но, как правило, для принятия верного решения требуется гораздо больше информации о мире, нежели та, которой «владеет» компьютер.
Рама Аккираджу, инженер и опытный изобретатель в IBM Watson User Technologies, написал в блоге: «Может ли компьютер автоматически распознавать передаваемые в сообщении эмоции достаточно точно? Помощь людям в оценке и улучшению эмоционального тона в письменной коммуникации — интересное испытание в областях искусственного интеллекта и когнитивных наук. С помощью IBM Watson мы, наконец, сможем начать отвечать на этот вопрос.»
Всё это звучит так, как будто здесь за занавесом всё таки присутствует человек. Но ещё в 2013 году, мы писали, как исследователи из IBM могут “расшифровать” ваш характер всего в 200 твитов.
Порой эмоциональный тон сообщения может быть упущен, нежелателен или в недостаточной мере раскрыт автором. IBM Watson Tone Analyzer уже доступен в экспериментальном режиме, это сервис, который поможет оценить и улучшить эмоциональный тон в письменной коммуникации.”
Технологическая составляющая похожа на лингвистический анализ, который используется в IBM Watson Personality Insights. Tone Analyzer анализирует выбранный текст и предоставляет информацию об эмоциональных, социальных и письменных акцентах, отраженных в тексте. Подобная информация может быть применена для целого ряда задач, включая личные и бизнес коммуникации, брендинг, исследования рынка, PR и контактный центр», — говорит Аккираджу.
Основные эмоциональные элементы тональности включают жизнерадостность, негативные эмоции и злость. “Жизнерадостность подразумевает под собой позитивные эмоции, такие как радость, оптимизм, довольство, вдохновение и счастье. Негативные эмоции включают в себя чувства страха, отвращение, отчаянья, вины, и унижения. Злость тоже есть вид негативных эмоций с наиболее сильным эмоциональным окрасом, как например раздражение, враждебность, агрессия, боль, разочарование и ярость”.
IBM Watson также может распознавать социальные тональности, такие как открытость, уступчивость и добросовестность. “Открытость же есть мера готовности человека к занятию новыми видами деятельности; уступчивость – тенденция к сопереживанию и активному взаимодействию с окружающими; добросовестность — это склонность к организованному и продуманному действию. Мы используем эти три измерения для иллюстрации открытости, уступчивости и добросовестности автора, как отражено в тексте”.
=================
Казалось бы – все замечательно? Но судя по последним действиям «Голубого гиганта» на рынке, подобные «черепашьи» скорости в разработке лингвистики никак не устраивают руководство. Несколько лет (как минимум с 2013 года) решать задачу семантического анализа и автоматического определения тональности с окраской высказываний – непозволительная медлительность разработки в наше время, когда бизнесу нужна оперативность решений.
Итог: IBM весной покупает за $100 млн AlchemyAPI (см. 9-ю серию сериала про Big Data), компанию, которая умеет быстро обрабатывать англоязычные потоки неструктурированных данных.
Подобные проблемы не только у IBM, но у всех «китов» (SAP, Google, MS, HP и т.д.), занимающихся разработкой продуктов и систем обработки неструктурированных данных. Если с английским языком (с точки зрения лингвистики достаточно простым) еще как-то более-менее, то с другими, типа немецкого или русского – просто беда.
Общаясь с европейскими центрами впечатляет, когда после многолетних изысканий и требований сверху «Вы срываете сроки!», рождаются решения типа: переведем с русского на английский и возьмем тональность текста перевода. И это не шутка.
Для тех, кто интересуется лингвистикой: поработать с русскоязычной лингвистикой можно на сайте Eureka Engine, там же и подробное описание различных лингво-модулей.
Для желающих проверить "Правило 200 твитов/постов" от исследователей из IBM: возьмите сообщения кого-то из лидерующих медиа-персон в разных соцмедиа (см. публичный Рейтинг авторов и групп) и проверьте, насколько лингвисты ошибаются :-)
А если у кого-то из читателей возникнет желание сделать полноценную «обертку» в виде системы "Кто ты есть в твоих постах?", то мы предоставим доступ к данным (сообщениям) и API Eureka Engine. Кто знает, вдруг «Она вращается!»?
На днях мы уже приводили фактографию по объемам количества сообщений, производимых человечеством в сутки, понятно, что миллиарды высказываний требуют совершенно других решений и технологий. «Старые» (ужас, прошло 3-5 лет, и уже старые) подходы и люди, их разрабатывающие, борются за место под солнцем. Но…
В качестве классического примера приводим перевод недавнего материала от подразделения IBM Watson:
======
IBM Watson может распознавать эмоциональный тон сообщения
(источник)
Исследователи из IBM создали IBM Watson Tone Analyzer, приложение для суперкомпьютеров, которое может сообщение прочитать и определить передаваемые в нём эмоции.
Эта задача из разряда тех, что естественно легко выполняется человеком, но, как правило, для принятия верного решения требуется гораздо больше информации о мире, нежели та, которой «владеет» компьютер.
Рама Аккираджу, инженер и опытный изобретатель в IBM Watson User Technologies, написал в блоге: «Может ли компьютер автоматически распознавать передаваемые в сообщении эмоции достаточно точно? Помощь людям в оценке и улучшению эмоционального тона в письменной коммуникации — интересное испытание в областях искусственного интеллекта и когнитивных наук. С помощью IBM Watson мы, наконец, сможем начать отвечать на этот вопрос.»
Всё это звучит так, как будто здесь за занавесом всё таки присутствует человек. Но ещё в 2013 году, мы писали, как исследователи из IBM могут “расшифровать” ваш характер всего в 200 твитов.
Порой эмоциональный тон сообщения может быть упущен, нежелателен или в недостаточной мере раскрыт автором. IBM Watson Tone Analyzer уже доступен в экспериментальном режиме, это сервис, который поможет оценить и улучшить эмоциональный тон в письменной коммуникации.”
Технологическая составляющая похожа на лингвистический анализ, который используется в IBM Watson Personality Insights. Tone Analyzer анализирует выбранный текст и предоставляет информацию об эмоциональных, социальных и письменных акцентах, отраженных в тексте. Подобная информация может быть применена для целого ряда задач, включая личные и бизнес коммуникации, брендинг, исследования рынка, PR и контактный центр», — говорит Аккираджу.
Основные эмоциональные элементы тональности включают жизнерадостность, негативные эмоции и злость. “Жизнерадостность подразумевает под собой позитивные эмоции, такие как радость, оптимизм, довольство, вдохновение и счастье. Негативные эмоции включают в себя чувства страха, отвращение, отчаянья, вины, и унижения. Злость тоже есть вид негативных эмоций с наиболее сильным эмоциональным окрасом, как например раздражение, враждебность, агрессия, боль, разочарование и ярость”.
IBM Watson также может распознавать социальные тональности, такие как открытость, уступчивость и добросовестность. “Открытость же есть мера готовности человека к занятию новыми видами деятельности; уступчивость – тенденция к сопереживанию и активному взаимодействию с окружающими; добросовестность — это склонность к организованному и продуманному действию. Мы используем эти три измерения для иллюстрации открытости, уступчивости и добросовестности автора, как отражено в тексте”.
=================
Казалось бы – все замечательно? Но судя по последним действиям «Голубого гиганта» на рынке, подобные «черепашьи» скорости в разработке лингвистики никак не устраивают руководство. Несколько лет (как минимум с 2013 года) решать задачу семантического анализа и автоматического определения тональности с окраской высказываний – непозволительная медлительность разработки в наше время, когда бизнесу нужна оперативность решений.
Итог: IBM весной покупает за $100 млн AlchemyAPI (см. 9-ю серию сериала про Big Data), компанию, которая умеет быстро обрабатывать англоязычные потоки неструктурированных данных.
Подобные проблемы не только у IBM, но у всех «китов» (SAP, Google, MS, HP и т.д.), занимающихся разработкой продуктов и систем обработки неструктурированных данных. Если с английским языком (с точки зрения лингвистики достаточно простым) еще как-то более-менее, то с другими, типа немецкого или русского – просто беда.
Общаясь с европейскими центрами впечатляет, когда после многолетних изысканий и требований сверху «Вы срываете сроки!», рождаются решения типа: переведем с русского на английский и возьмем тональность текста перевода. И это не шутка.
Для тех, кто интересуется лингвистикой: поработать с русскоязычной лингвистикой можно на сайте Eureka Engine, там же и подробное описание различных лингво-модулей.
Для желающих проверить "Правило 200 твитов/постов" от исследователей из IBM: возьмите сообщения кого-то из лидерующих медиа-персон в разных соцмедиа (см. публичный Рейтинг авторов и групп) и проверьте, насколько лингвисты ошибаются :-)
А если у кого-то из читателей возникнет желание сделать полноценную «обертку» в виде системы "Кто ты есть в твоих постах?", то мы предоставим доступ к данным (сообщениям) и API Eureka Engine. Кто знает, вдруг «Она вращается!»?
Комментарии (7)
denis_g
20.09.2015 21:29+2Интересно было бы натравить его на какой-нибудь ресурс вроде РИА Новости, НТВ или Lienews ;)

kstep
20.09.2015 22:36+1Не поможет. Как я понял оно только англоязычное пока что. Разве что пропускать текст через Google Translate, но что тогда получится…

priv8v
21.09.2015 10:10По-моему, эмоциональный окрас более ярко выражен на «Эхе Москвы» (если брать известных), а если учесть, что значительную часть контента Эха составляют авторские блоги различных известных персон, то градус эмоциональности там вообще зашкаливает.

auine
22.09.2015 08:25А я видел уже такое, указываешь урл и оно оценивает настроение и русский брало отлично. Но потерял линк на сайт :(

ganqqwerty
20.09.2015 23:40Кто из специалистов знает — в sentiment analysis есть что-то более интеллектуальное чем туча эвристик?
Kosyura
Распознавание эмоций в тексте это, конечно, клево и проделана огромная работа, но как это использовать в коммерческих целях?
Может я веду твиттер специально с некоторой ноткой агрессии или напишу текст с большим сарказом, но это ведь не будет учитываться. Как быть?
gaploid
В том то и дело, что по идее будет учитываться и сарказм тоже. А используют это уже сейчас, особенно в маркетинге, когда нужно замерить тональность маркетинговой компании после ее прошествии. На биржах используют после объявление новости — смотрят тональность новостных агенств. Подводят итоги выступлений, к примеру в администрации у Обамы так обрабатывают результаты его выступлений по тональности твитов, новостей и постов и смотря как и что больше нравится народу.