
Мы решили дать публичный доступ к архиву 1 млн насыщенных мета-данными сообщений соцмедиа (несколько сотен источников, включая посты и комментарии соцсетей, блогов, форумов, СМИ и т.п.).
Предлагаем попробовать свои силы в создании различных эвристик, закладываемых в классические SMA-системы (Social Media Analytics). Чем больше эвристик вы придумаете и сможете реализовать, тем выше ваш класс в Data Scientist. Возможно в вас живет настоящий профи: Data Scientist — одна из крутых профессий ближайшего будущего!
Для состоявшихся фанатов-профи — это возможность проверить и показать свои способности, а также, при обоюдном желании и радости, получить годовой контракт на $30.000 — $50.000.
Подробнее под катом
Стратегический ситуационный уровень:
— Ежедневно человечество генерит десятки (30-40) млрд онлайн-сообщений, из которых 5-7% публичных.
— Русскоязычные сообщения составляют 2-3% мирового потока, т.е. ~100 млн в сутки.
— В отличие от структурированных данных (чеки в магазине, информация о звонках, электронные платежи и пр.) НЕструктурированные данные требуют других инструментов для создания аналитических систем и подходов к анализу данных аналитиками: скоростная лингвистика, нечеткие мета-данные, «размазанная» геолокация, выявление и противодействие «чужому разуму» (ботам) и т.д., и т.п.
Тактический уровень:
— Человечество практически «закончилось» — темпы прироста в онлайн и генерации контента составляют естественные единицы процентов.
— Платформы сбора данных, а также первичного анализа (SMA — Social Media Analytics), включая и лингвистические модули (обычно самые медленные процессы) вышли на промышленный уровень, справляясь с текущими потоками генерации данных.
— Теперь дело за «мозгами» — какие (адаптивные) алгоритмы AI (ИИ, искусственного интеллекта или машинного самообучения) будут создаваться, развиваться и применяться для решения реальных задач человеческого социума.
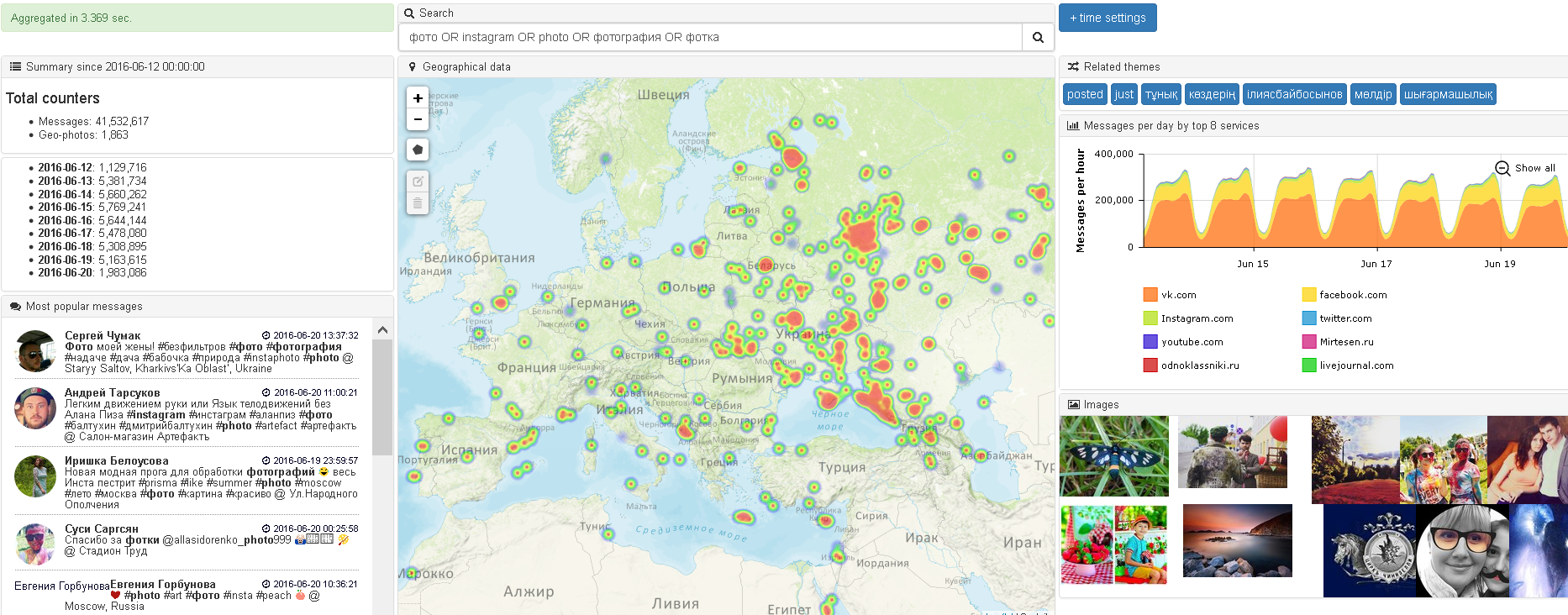
Понятийный пример (см. картинку выше):
Есть набор насыщенных мета-данными соцмедиа-сообщений, а также некий стандартный набор эвристик, выработанных аналитиками для клиентов в течение нескольких лет, например: количество сообщений (иногда с разбивкой по периоду), разблюдовка по коммуникационным каналам и т.д. Если сообщения дополнить «непрямой» информацией мета-данных, отсуствующих в исходном сообщении (т.е. задействовать «мозги и память»), то для твитов можно доопределить пол (отсутствующее поле в аккаунте), а для комментария к статье в СМИ доопределить, например, гео по фразе «Болею за наших в Париже». Тогда можно создать НОВУЮ эвристику — показать сообщения на карте, актуализируя такие аттрибуты, как концентрация и гео-динамика события.
Насыщение и расширение мета-данных — сама по себе интересная задача, которая уже частично и в разной степени успешности решается в крупных компаниях (IBM, Google, MS), и соцсетях (Facebook, Twitter, LinkedIn). Для этих процессов чаще всего задействуют появляющиеся новые технологии — например, определение людей по фотографиям, или получение доступа к данным о физических перемещениях людей (телеком-метки).
Наступает момент, когда технологии и задачи выходят на следующий уровень «мозговитости» — когда системы САМОСТОЯТЕЛЬНО находят новые закономерности и делают прогноз о развитии событий и ситуаций.
Подобные фазы развития прошли, например, автоматические финансовые роботы: на анализе прошлых данных строились различные модели и эвристики, которые далее в автоматическом режиме работают и зарабатывают (как минимум разработчики этих роботов).
Профессия Data Scientist предполагает некоего кентавра: смесь программиста с аналитиком. Чего в кентавре больше — дело важное, но вторичное, главное — результат деятельности специалиста. По прогнозам исследовательских агентств потребность DS только в США составит 180.000 человек.
Конкретика:
1. 1млн+ публичных сообщений с мета-данными выложены в публичный доступ:
CSV, 55 мб
JSON, 350 мб (традиционный json. Один массив с 1млн+ объектами)
JSON, 415 мб (Один json-объект на 1 строку, разделитель LF ("\n") )
Данные представляют собой некую выборку за ~6 часов одного дня.
2. Для интересующихся и желающих попробовать свои силы и возможности — попробуйте «повторить» простейшие эвристики, закладываемые в классические SMA-системы. Чем больше эвристик вы придумаете (подсмотрите) и сможете реализовать, тем выше ваш класс в DS. В обязательном порядке найдите критерий выборки данного 1 млн сообщений. Напомню, что по статистике дневной набор русскоязычного потока ~100 млн, значит за несколько часов должно было бы быть 10-15 млн, а в выборке — только 1 млн. Что могло быть критерием выборки? Небольшая подсказка — обычно простые выборки делаются по словам («ключевикам»).
3. На Хабре периодически появляются посты по анализу неструктурированных данных, вполне возможно, что кто-то из фанатов-профи согласится участвовать в нашем новом R&D-спиноффе на постоянной основе (годовой контракт, $30-50тыс). Не имеет значение пол, возраст, образование, место проживания, значение имеет только результат, который нужно реализовать на данном наборе данных, и желание творить и создавать НОВЫЕ эвристики.
Каким результатом может похвастаться профи:
— Стандартные статистики SMA — данных полей в мета-данных вполне хватает для понимания.
— Расширение новыми мета-данными, за счет сбора дополнительных данных по авторам набора из соцсетей, например: женат/холост, учится/работает, дети/родители.
— «Интеллектуальные» мета-данные — очень сильный плюс. Например: динамика тональности высказываний, или кластеризация интересов.
— И, конечно, НОВЫЕ эвристики, которые только придут в голову.
Если будет получаться что-то интересное — присылайте на sz@palitrumlab.ru.
Код присылать не надо! Только таблички или картинки с результатами.
P.S. К существующей Платформе данных SDS и лингвистической платформе EurekaEngine мы сейчас ведем разработку Платформы мета-данных. Надеемся, что к концу года мы сможем обеспечить доступ ко всем Платформам для разработчиков разных уровней, а также групп и команд, в целях создания сторонних новых решений и систем, для работы которых необходимо получать открытые данные из соцмедиа и публичные наборы данных.
UPD: не прошло и часа, как пришли первые «картинки» с эвристиками «А что за выборка»:


UPD2: Dropbox закрыл доступ после пары тысяч скачиваний, CSV и JSON доступен на Я.Диске, Заодно выложена версия JSON с одним объектом на строку.
Комментарии (18)

OzzyTech
20.06.2016 21:22Ответил не в ветку. Исправил

MaxAkaAltmer
20.06.2016 21:34+11. Поверьте таких как я будет много. Можете из-за банальной вещи — упустить кого-то стоящего. Но дело хозяйское, лично я использую свой сервер для подачи материалов, чтобы не было лишних проблем.
2. И какова мотивация сторонних команд?
3. Я скептик. Верхняя — средний уровень аутсорсера для США. Хорошая вполне, во ее бы и сделал нижней — мотивированных людей значительно прибавится, тем более, говорите, что и больше можно.OzzyTech
20.06.2016 21:482. Заработать. PaaS — отичная схема множества стартапов и компаний для реализаций потребностей клиентов в Slack, Bitrix24, Google Adwords и множества других.
Мы — технологическая компания, и не можем покрыть растущий пул потребностей людей и различных индустрий. Обеспечить данными, лингвистикой, мета-данными — это для нас ближе.
P.S. Скопипастил небольшую подборку из списка запросов-хотелок людей, компаний, госструктур:
— Динамика распространения гриппа (аналог Google Flu) по городам России.
— Кто еще пойдет на мероприятие?
— Где родились и где живут сейчас – карта и волны миграции
— Автоклассификация интересов аккаунта.
— Родительский контроль за семейными аккаунтами, упоминаний ребенка
— Рейтинг сущностей (люди, предметы, события), используемых в данном/ых аккаунте/ах.
— Кластеризация и персонализация инфопотоков
— Подборка дня — что произошло у моих друзей и медиа-персон: лента, кластеризация по моим интересам — Топ-10.
— Нахождение «друзей по интересам», а не знакомых.
— Сообщения и фотки людей, находящихся рядом.
…MaxAkaAltmer
20.06.2016 22:15Спасибо за развернутый ответ.
Почему-то вспомнил мультик про козленка, который всех посчитал.OzzyTech
20.06.2016 22:22Один из самых прекрасных мульт-персонажей. Столько желающих «вломить» этому козленку было ;)
Если по серьезному, то (IMHO) сила новых направлений с подобными технологиями — в прогностике. Не в анализе (подсчете) прошлого, а в предсказании будущих процессов. Но это уже отдельный большой разговор.

kretuk
20.06.2016 23:13-6Можно много всего красивого понаписать, покрасоваться, а потом узнать, что у вас эта ваша платформа сделано на пхп. и все как-то сразу плавно превращается в цирк…
OzzyTech
20.06.2016 23:18+2P.S. Не очень понял насчет PHP — что в нем такого плохого? Разные части Платформ написаны на разных языках и средствах: и PHP, и C/С++, и Java, кое где и ассемблер встречается.
По теме: у Вас есть доступ к данным, соответственно Вы можете реализовать свою идею/эвристику на каком удобном Вам инструменте. Без всякого цирка.
Для аналитиков и лингвистов (для «гипсовых заготовок») удобен Python, поскольку доступно много готовых библиотек…
kretuk
21.06.2016 08:33-3что же тут не понятного? делать сервисы на пхп — это не серьезно. это говорит о том, что нанять хороших специалистов вы не можете. поэтому разговоры по «нижняя планка 30K $ в год» и есть цирк.
paranoik2
21.06.2016 12:53проблема со скачиванием
Error (429)
This account's links are generating too much traffic and have been temporarily disabled!OzzyTech
21.06.2016 12:55Dropbox (бесплатный) выдал два письма-прежупреждения (слишком много загрузок) и закрыл доступ. Сейчас коллеги закачают на другой хостинг, ссылки поменяем.


maxood
21.06.2016 23:02+1В вашей таблице есть уникальный ключ? Как вы собираетесь проверять результат исследований?
В JSON-файле 1 013 063 записей, при этом уникальных idExternal — 1 011 071.
Например — cat ./messages.json | grep \«idExternal\»:\«5-41:\» | wc -l
1205
Уникальных url еще меньше — 977462.
Поясните, как вы будете сопоставлять «эвристики» с исходными данными и, вообще, что вы подразумеваете под термином «эвристика»?OzzyTech
22.06.2016 11:13Никакого уникального ключа нет. Это обычный последовательный по времени поток данных соцмедиа с фильтром по слову «я» (с включенной морфологией). Механистический подход «взвесить в граммах» — никому не интересен.
Эвристика и эвристические методы — см. https://ru.wikipedia.org/wiki/%D0%AD%D0%B2%D1%80%D0%B8%D1%81%D1%82%D0%B8%D0%BA%D0%B0
Стандартные инструменты SMA-систем автоматически используют статистические эвристики с использованием мета-данных, например:

и

MaxAkaAltmer
Вы бы данные выложили, на собственный сервер, а не на DropBox, который требует регистрацию. Не солидно.
Похоже у вас не хватает собственной фантазии для эвристик и вам нужны идеи, может лучше провести конкурс с призами? Чем обещать трудоустройство, которое лично меня не впечатляет нижней планкой.
OzzyTech
1. DropBox позволяет скачать без регистрации. Ссылки на отказ от регистрации и перехода к процессу скачивания находятся внизу страниц.
2. К сожалению, у нас другая проблема: идей (собственных и клиентов) слишком много, чтобы успеть все реализовать :( Поэтому и принято стратегическое решение двигаться к предоставлению доступа к Платформам данных, чтобы сторонние команды могли покрыть существующие и новые потребности.
3. Впечатлитесь верхней планкой (которая тоже не предел). Было бы за что.
MaxAkaAltmer
Ответил чуть ниже, увы исправить уже не могу.