
 Привет, Хабр! Этой статьёй я открываю цикл материалов, посвящённых работе с большими данными. Зачем? Хочется сохранить накопленный опыт, свой и команды, так скажем, в энциклопедическом формате – наверняка кому-то он будет полезен.
Привет, Хабр! Этой статьёй я открываю цикл материалов, посвящённых работе с большими данными. Зачем? Хочется сохранить накопленный опыт, свой и команды, так скажем, в энциклопедическом формате – наверняка кому-то он будет полезен. Проблематику больших данных постараемся описывать с разных сторон: основные принципы работы с данными, инструменты, примеры решения практических задач. Отдельное внимание окажем теме машинного обучения.
Начинать надо от простого к сложному, поэтому первая статья – о принципах работы с большими данными и парадигме MapReduce.
История вопроса и определение термина
Термин Big Data появился сравнительно недавно. Google Trends показывает начало активного роста употребления словосочетания начиная с 2011 года (ссылка):
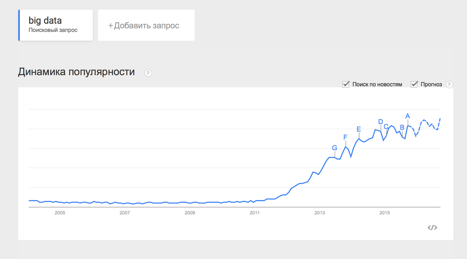
При этом уже сейчас термин не использует только ленивый. Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и освятить вопрос – необходимо определиться с понятием.
В своей практике я встречался с разными определениями:
· Big Data – это когда данных больше, чем 100Гб (500Гб, 1ТБ, кому что нравится)
· Big Data – это такие данные, которые невозможно обрабатывать в Excel
· Big Data – это такие данные, которые невозможно обработать на одном компьютере
И даже такие:
· Вig Data – это вообще любые данные.
· Big Data не существует, ее придумали маркетологи.
В этом цикле статей я буду придерживаться определения с wikipedia:
Большие данные (англ. big data) — серия подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети, сформировавшихся в конце 2000-х годов, альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence.
Таким образом под Big Data я буду понимать не какой-то конкретный объём данных и даже не сами данные, а методы их обработки, которые позволяют распредёлено обрабатывать информацию. Эти методы можно применить как к огромным массивам данных (таким как содержание всех страниц в интернете), так и к маленьким (таким как содержимое этой статьи).
Приведу несколько примеров того, что может быть источником данных, для которых необходимы методы работы с большими данными:
· Логи поведения пользователей в интернете
· GPS-сигналы от автомобилей для транспортной компании
· Данные, снимаемые с датчиков в большом адронном коллайдере
· Оцифрованные книги в Российской Государственной Библиотеке
· Информация о транзакциях всех клиентов банка
· Информация о всех покупках в крупной ритейл сети и т.д.
Количество источников данных стремительно растёт, а значит технологии их обработки становятся всё более востребованными.
Принципы работы с большими данными
Исходя из определения Big Data, можно сформулировать основные принципы работы с такими данными:
1. Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать.
2. Отказоустойчивость. Принцип горизонтальной масштабируемости подразумевает, что машин в кластере может быть много. Например, Hadoop-кластер Yahoo имеет более 42000 машин (по этой ссылке можно посмотреть размеры кластера в разных организациях). Это означает, что часть этих машин будет гарантированно выходить из строя. Методы работы с большими данными должны учитывать возможность таких сбоев и переживать их без каких-либо значимых последствий.
3. Локальность данных. В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом – расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
Все современные средства работы с большими данными так или иначе следуют этим трём принципам. Для того, чтобы им следовать – необходимо придумывать какие-то методы, способы и парадигмы разработки средств разработки данных. Один из самых классических методов я разберу в сегодняшней статье.
MapReduce
Про MapReduce на хабре уже писали (раз, два, три), но раз уж цикл статей претендует на системное изложение вопросов Big Data – без MapReduce в первой статье не обойтись J
MapReduce – это модель распределенной обработки данных, предложенная компанией Google для обработки больших объёмов данных на компьютерных кластерах. MapReduce неплохо иллюстрируется следующей картинкой (взято по ссылке):

MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи.
Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce.
2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce.
3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce().
Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Несколько дополнительных фактов про MapReduce:
1) Все запуски функции map работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
2) Все запуски функции reduce работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных машинах кластера. Пункты 1-3 позволяют выполнить принцип горизонтальной масштабируемости.
4) Функция map, как правило, применяется на той же машине, на которой хранятся данные – это позволяет снизить передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет. Это означает, что MapReduce плохо применим, когда ответ требуется очень быстро.
Примеры задач, эффективно решаемых при помощи MapReduce
Word Count
Начнём с классической задачи – Word Count. Задача формулируется следующим образом: имеется большой корпус документов. Задача – для каждого слова, хотя бы один раз встречающегося в корпусе, посчитать суммарное количество раз, которое оно встретилось в корпусе.
Решение:
Раз имеем большой корпус документов – пусть один документ будет одной входной записью для MapRreduce–задачи. В MapReduce мы можем только задавать пользовательские функции, что мы и сделаем (будем использовать python-like псевдокод):
|
|
Функция map превращает входной документ в набор пар (слово, 1), shuffle прозрачно для нас превращает это в пары (слово, [1,1,1,1,1,1]), reduce суммирует эти единички, возвращая финальный ответ для слова.
Обработка логов рекламной системы
Второй пример взят из реальной практики Data-Centric Alliance.
Задача: имеется csv-лог рекламной системы вида:
<user_id>,<country>,<city>,<campaign_id>,<creative_id>,<payment></p>
11111,RU,Moscow,2,4,0.3
22222,RU,Voronezh,2,3,0.2
13413,UA,Kiev,4,11,0.7
…
Необходимо рассчитать среднюю стоимость показа рекламы по городам России.
Решение:
|
|
Функция map проверяет, нужна ли нам данная запись – и если нужна, оставляет только нужную информацию (город и размер платежа). Функция reduce вычисляет финальный ответ по городу, имея список всех платежей в этом городе.
Резюме
В статье мы рассмотрели несколько вводных моментов про большие данные:
· Что такое Big Data и откуда берётся;
· Каким основным принципам следуют все средства и парадигмы работы с большими данными;
· Рассмотрели парадигму MapReduce и разобрали несколько задач, в которой она может быть применена.
Первая статья была больше теоретической, во второй статье мы перейдем к практике, рассмотрим Hadoop – одну из самых известных технологий для работы с большими данными и покажем, как запускать MapReduce-задачи на Hadoop.
В последующих статьях цикла мы рассмотрим более сложные задачи, решаемые при помощи MapReduce, расскажем об ограничениях MapReduce и о том, какими инструментами и техниками можно обходить эти ограничения.
Спасибо за внимание, готовы ответить на ваши вопросы.
Ссылки на другие части цикла:
Big Data от А до Я. Часть 2: Hadoop
Комментарии (29)

Informatik
21.09.2015 20:06+5У индейцев племени Пираха, живущих в тропических лесах Бразилии, в отдалении от цивилизации в языке имеются только три числительных, одно переводится примерно как «один-два», другое — «несколько» и третье — «гораздо больше». Последнее удивительным образом напоминает Big Data.

grossws
21.09.2015 20:45+8Как и большинство таких публикаций — ни о чём. Писать статью «введение в MR» по содержанию меньше чем tutorial к hadoop'у — просто смешно.
Если хочется несколько погрузиться в тему, то сейчас на coursera есть интересный курс от Стэнфорда.
asash
21.09.2015 20:50+6Туториал по hadoop'у в следующей части. Считаю что правильно разбивать материал на порции на осознание которых не уйдет больше 20 минут. Если вы уже знали материал то для вас естественно статья «ниочем» :)
Ссылка хорошая, так же могу порекомендовать книжку на основании которой построен курс: www.mmds.org.grossws
21.09.2015 21:32+1Да, книжка есть в описании курса.
А с подходомСчитаю что правильно разбивать материал на порции на осознание которых не уйдет больше 20 минут.
крайне не согласен. Проблемы:
— сильно замусоривает ленту;
— автор обычно исчезает в середине цикла.
Результат получается удручающий: в энный раз описаны тривиальные вещи, а до сложных так и не дошло. Возможно, у вас этого не случится, но пока статистика по многим циклам публикаций такова.

antaries
21.09.2015 22:43+17Злые вы все какие-то.
А мне понравилась статья. Даже несмотря на то, что почти все это я знал.
Изложено просто и понятно, читать приятно, без лишней воды. Есть ощущение, что автор действительно знает тему и потому, есть надежда, что цикл дойдет до сложных статей. Надежда на это подкупает.
Что касается того, что «обычно до сложных тем не доходит в циклах» — так может потому и не доходит, что все набрасываются за то, что цикл начинается с простого?
В общем, к автору обращаюсь с просьбой продолжать писать и завершить цикл, а не прервать его на середине.asash
21.09.2015 22:46+4Спасибо!
Постараюсь не обмануть ожиданий :)
no_smoking
22.09.2015 08:41+2Я также поддержу, главное продолжайте читать очень легко и понятно, хочется узнать чем все закончилось :)


RPG18
22.09.2015 00:45+1Как-то странно читать про MapReduce, без ссылок на MapReduce: Simplied Data Processing on Large Clusters.
Интересно было бы почитать про потоковые алгоритмы обработки данных.asash
22.09.2015 00:51До потоковой обработки тоже надеюсь дойдем.
Про то как мы занимаемся потоковой обработкой можно почитать в одной из наших предыдущих статей:
habrahabr.ru/company/dca/blog/260845

eMptywee
22.09.2015 02:01+1Спасибо, интересно. Еще было бы интересно, если бы осветили вопрос тюнинга нод в Hadoop-кластерах. Какие параметры есть, на что влияют и как крутить и при каких условиях и для каких задач. С точки зрения сисадминов и devops. Если, конечно же, знаете.
Mindstorms
22.09.2015 03:21+2Хорошая статья. Написано простым и понятным языком.
Продолжайте писать. :)
zamonier
22.09.2015 11:15+2Мне понравился стиль изложения. Объем тоже. Не слушайте критиков — пишите дальше!
Artiomtb
22.09.2015 12:05+4Для новичка в области BigData — то, что нужно, чтобы постичь общую суть и ознакомиться с принципами.
but
22.09.2015 12:33+1Спасибо, интересная тема, читабельный текст, не много букв )) Жду статью про Хадуп в таком же стиле.

donRumatta
06.10.2015 20:38А можно попродробнее насчет:
shuffle прозрачно для нас превращает это в пары (слово, [1,1,1,1,1,1])
Каков псевдокод этого метода?asash
06.10.2015 21:50псевдокода нету, поскольку это делает MapReduce framework. По сути — происходит распределенная сортировка по ключу, а дальше объединение всех значений соответствующих одому ключу в список значений.
donRumatta
06.10.2015 21:53А почему бы не посчитать количество сразу на это этапе?
asash
06.10.2015 22:11этот этап не программируем. все равно чтобы посчитать количество вам понадобятся все записи. На самом деле, в ситуациях подобных данной результаты можно предагрегировать еще до передачи их на reducer — возспользоваться методом Combine, про который я расскажу в 3-ей части этого цикла статей.
zmey2
Хотелось бы, чтобы каждый новый автор, решающий открыть миру глаза на Big Data, начинал со слов: " я заработал своей компании на Big Data XX млн, что подтверждено такой-то и такой аудированной отчетностью". Это даст импульс внимания со стороны читающей публики, а ряду читателей поможет сэкономить время
asash
Спасибо за комментарий по существу:)
Моей целью не является «открыть миру глаза», лишь систематизировать свои знания и поделиться ими с теми кому это интересно.
brainick
Неизвестно, заработал ли автор XX миллионов на Big Data, но доподлинно известно, что он зарабатывает отличные деньги обучая других как надо зарабатывать на Big Data.
Подробности (в жгущих камментах)здесь
http://habrahabr.ru/post/267107/
http://habrahabr.ru/company/npl/blog/252589/
asash
Я действительно занимаюсь преподавательской деятельностью и горжусь этим.
Но преподавательская деятельность не является моим основным занятием — это хобби и оно не приносит существенного дохода для меня.
Основная деятельность — разработка и проектирование систем связанных с большими данными, более конкретно о тем чем занимаюсь я и компания в которой я работаю можно прочитать в других статьях этого блога и просто поискав в интернете.
Меряться миллионами — это мне кажется не для хабра, а для forbes или ведомостей. Оценить уровень зарплат в сфере работы с данными можно посмотрев вакансии по соответствующим запросам на hh.ru, яндекс.работа и прочих сервисов. Как работадатель могу сказать, что на рынке существует существенный кадровый голод и найти сотрудника с нужными компетенциями очень-очень сложно и поиск сотрудника на позицию длится как правило месяцами.
zmey2
То есть в вашем случае XX =0
asash
Нет.
Считаю бессмысленным дальнейшее обсуждение моих доходов в данной статье. Мне хватает на хлеб, а также масло и возможность съездить в отпуск.
zmey2
Речь не про ваши доходы конечно, они меня не касаются. Просто хочется понять, вы преподаете, потому что… что?
asash
Потому что мне нравится преподавать. Я получаю удовольствие от того что делюсь знаниями с людьми. Мне нравится заводить новые знакомства, которые часто переходят в совместные проекты. Нравится наблюдать за формирующимся сообществом единомышленников.
До того как преподавать на курсах NPL я преподавал в кружках олимпиадного программирования — тоже не за деньги(естественно зарплата была, но весьма символическая).
zmey2
Спасибо вам. Спасибо!