
Привет, Хабр! Мы продолжаем наш цикл статьей, посвященный инструментам и методам анализа данных. Следующие 2 статьи нашего цикла будут посвящены Hive — инструменту для любителей SQL. В предыдущих статьях мы рассматривали парадигму MapReduce, и приемы и стратегии работы с ней. Возможно многим читателям некоторые решения задач при помощи MapReduce показались несколько громоздкими. Действительно, спустя почти 50 лет после изобретения SQL, кажется довольно странным писать больше одной строчки кода для решения задач вроде «посчитай мне сумму транзакций в разбивке по регионам».
С другой стороны, классические СУБД, такие как Postgres, MySQL или Oracle не имеют такой гибкости в масштабировании при обработке больших массивов данных и при достижении объема большего дальнейшая поддержка становится большой головоной болью.

Собственно, Apache Hive был придуман для того чтобы объеденить два этих достоинства:
Под катом мы расскажем каким образом это достигается, каким образом начать работать с Hive, и какие есть ограничения на его применения.
Hive появился в недрах компании Facebook в 2007 году, а через год исходники hive были открыты и переданы под управление apache software foundation. Изначально hive представлял собой набор скриптов поверх hadoop streaming (см 2-ю статью нашего цикла), позже развился в полноценный фреймворк для выполнения запросов к данным поверх MapReduce.
Актуальная версия apache hive(2.0) представляет собой продвинутый фреймворк, который может работать не только поверх фреймворка Map/Reduce, но и поверх Spark(про спарк у нас будут отдельные статьи в цикле), а также Apache Tez.
Apache hive используют в production такие компании как Facebook, Grooveshark, Last.Fm и многие другие. Мы в Data-Centric alliance используем HIve в качестве основного хранилища логов нашей рекламной платформы.
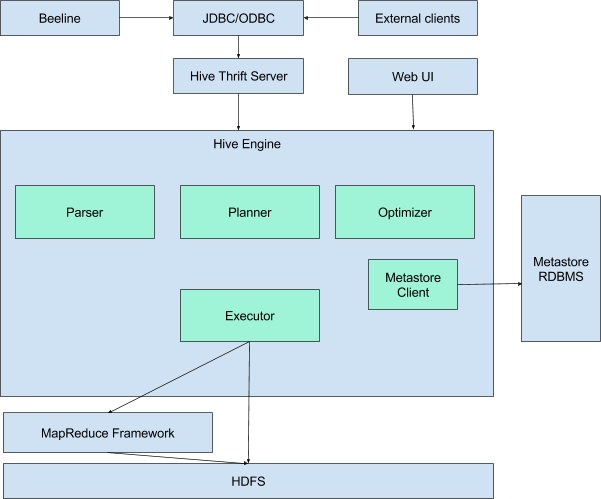
Hive представляет из себя движок, который превращает SQL-запросы в цепочки map-reduce задач. Движок включает в себя такие компоненты, как Parser(разбирает входящие SQL-запрсоы), Optimimer(оптимизирует запрос для достижения большей эффективности), Planner (планирует задачи на выполнение) Executor(запускает задачи на фреймворке MapReduce.
Для работы hive также необходимо хранилище метаданных. Дело в том что SQL предполагает работу с такими объектами как база данных, таблица, колонки, строчки, ячейки и тд. Поскольку сами данные, которые использует hive хранятся просто в виде файлов на hdfs — необходимо где-то хранить соответствие между объектами hive и реальными файлами.
В качестве metastorage используется обычная реляционная СУБД, такая как MySQL, PostgreSQL или Oracle.
Для того чтобы попробовать работу с hive проще всего воспользоваться его командной строкой. Современная утилита для работы с hive называется beeline (привет нашим партнёрам из одноименного оператора :) ) Для этого на любой машине в hadoop-кластере (см. наш туториал по hadoop) с установленным hive достаточно набрать команду.
Далее необходимо установить соединение с hive-сервером:
Также иногда бывает удобно не вводить sql-запросы в командную строку beeline, а предварительно сохранить и редактировать их в файле, а потом выполнить все запросы из файла. Для этого нужно выполнить beeline с параметрами подключения к базе данных и параметром -f указывающим имя файла, содержащего запросы:
При работе с hive можно выделить следующие объекты которыми оперирует hive:
Разберем каждый из них подробнее:
База данных представляет аналог базы данных в реляционных СУБД. База данных представляет собой пространство имён, содержащее таблицы. Команда создания новой базы данных выглядит следующим образом:
Database и Schema в данном контексте это одно и тоже. Необязательная добавка IF NOT EXISTS как не сложно догадаться создает базу данных только в том случае если она еще не существует.
Пример создания базы данных:
Для переключения на соответствующую базу данных используем команду USE:
Таблица в hive представляет из себя аналог таблицы в классической реляционной БД. Основное отличие — что данные hive’овских таблиц хранятся прост в виде обычных файлов на hdfs. Это могут быть обычные текстовые csv-файлы, бинарные sequence-файлы, более сложные колоночные paruqet-файлы и другие форматы. Но в любом случае данные, над которыми настроена hive-таблица очень легко прочитать и не из hive.
Таблицы в hive бывают двух видов:
Классическая таблица, данные в которую добавляются при помощи hive. Вот пример создания такой таблицы (источник примера):
Тут мы создали таблицу, данные в которой будут храниться в виде обычных csv-файлов, колонки которой разделены символом табуляции. После этого данные в таблицу можно загрузить. Пусть у нашего пользователя в домашней папке на hdfs есть (напоминаю, что загрузить файл можно при помощи hadoop fs -put) файл sample.txt вида:
Загрузить данные мы сможем при помощи следующей команды:
После hive переместит данныe, хранящемся в нашем файле в хранилище hive. Убедиться в этом можно прочитав данные напрямую из файла в хранилище hive в hdfs:
Классические таблицы можно также создавать как результат select-запроса к другим таблицам:
Кстати говоря, SELECT для создания таблицы в данном случае уже запустит mapreduce-задачу.
Внешняя таблица, данные в которую загружаются внешними системами, без участия hive. Для работы с внешними таблицами при создании таблицы нужно указать ключевое слово EXTERNAL, а также указать путь до папки, по которому хранятся файлы:
После этого таблицей можно пользоваться точно так же как и обычными таблицами hive. Самое удобное в этом, что вы можете просто скопировать файл в нужную папочку в hdfs, а hive будет автоматом подхватывать новые файлы при запросах к соответствующей таблице. Это очень удобно при работе например с логами.
Так как hive представляет из себя движок для трансляции SQL-запросов в mapreduce-задачи, то обычно даже простейшие запросы к таблице приводят к полному сканированию данных в этой таблицы. Для того чтобы избежать полного сканирования данных по некоторым из колонок таблицы можно произвести партиционирование этой таблицы. Это означает, что данные относящиеся к разным значениям будут физически храниться в разных папках на HDFS.
Для создания партиционированной таблицы необходимо указать по каким колонкам будет произведено партиционирование:
При заливке данных в такую таблицу необходимо явно указать, в какую партицию мы заливаем данные:
Посмотрим теперь как выглядит структура директорий:
Видно, что структура директорий выглядит таким образом, что каждой партиции соответствует отдельная папка на hdfs. Теперь, если мы будем запускать какие-либо запросы, у казав в условии WHERE ограничение на значения партиций — mapreduce возьмет входные данные только из соответствующих папок.
В случае External таблиц партиционирование работает аналогичным образом, но подобную структуру директорий придется создавать вручную.
Партиционирование очень удобно например для разделения логов по датам, так как правило любые запросы за статистикой содержат ограничение по датам. Это позволяет существенно сократить время запроса.
Партиционирование помогает сократить время обработки, если обычно при запросах известны ограничения на значения какого-либо столбца. Однако оно не всегда применимо. Например — если количество значений в столбце очень велико. Напрмер — это может быть ID пользователя в системе, содержащей несколько миллионов пользователей.
В этом случае на помощь нам придет разделение таблицы на бакеты. В один бакет попадают строчки таблицы, для которых значение совпадает значение хэш-функции вычисленное по определенной колонке.
При любой работе с бакетированными таблицами необходимо не забывать включать поддержку бакетов в hive (иначе hive будет работать с ними как с обычными таблицами):
Для создания таблицы разбитой на бакеты используется конструкция CLUSTERED BY
Так как команда Load используется для простого перемещения данных в хранилище hive — в данном случае для загрузки она не подходит, так как данные необходимо предобработать, правильно разбив их на бакеты. Поэтому их нужно загрузить при помощи команды INSERT из другой таблицы(например из внешней таблицы):
После выполнения команды убедимся, что данные действительно разбились на 10 частей:
Теперь при запросах за данными, относящимися к определенному пользователю, нам не нужно будет сканировать всю таблицу, а только 1/10 часть этой таблицы.
Теперь мы разобрали все объекты, которыми оперирует hive. После того как таблицы созданы — можно работать с ними, так как с таблицами обычных баз данных. Однако не стоит забывать о том что hive — это все же движок по запуску mapreduce задач над обычными файлами, и полноценной заменой классическим СУБД он не является. Необдуманное использование таких тяжелых команд, как JOIN может привести к очень долгим задачам. Поэтому прежде чем строить вашу архитектуру на основе hive — необходимо несколько раз подумать. Приведем небольшой checklist по использованию hive:
В данной статье мы разобрали архитектуру hive, data unit-ы, которыми оперирует hive, привели примеры по созданию и заполнению таблиц hive. В следующей статье цикла мы рассмотрим продвинутые возможности hive, включающие в себя:
Ссылки на предыдущие статьи цикла:
» Big Data от А до Я. Часть 1: Принципы работы с большими данными, парадигма MapReduce
» Big Data от А до Я. Часть 2: Hadoop
» Big Data от А до Я. Часть 3: Приемы и стратегии разработки MapReduce-приложений
» Big Data от А до Я. Часть 4: Hbase
С другой стороны, классические СУБД, такие как Postgres, MySQL или Oracle не имеют такой гибкости в масштабировании при обработке больших массивов данных и при достижении объема большего дальнейшая поддержка становится большой головоной болью.
Собственно, Apache Hive был придуман для того чтобы объеденить два этих достоинства:
- Масштабируемость MapReduce
- Удобство использования SQL для выборок из данных.
Под катом мы расскажем каким образом это достигается, каким образом начать работать с Hive, и какие есть ограничения на его применения.
Общее описание
Hive появился в недрах компании Facebook в 2007 году, а через год исходники hive были открыты и переданы под управление apache software foundation. Изначально hive представлял собой набор скриптов поверх hadoop streaming (см 2-ю статью нашего цикла), позже развился в полноценный фреймворк для выполнения запросов к данным поверх MapReduce.
Актуальная версия apache hive(2.0) представляет собой продвинутый фреймворк, который может работать не только поверх фреймворка Map/Reduce, но и поверх Spark(про спарк у нас будут отдельные статьи в цикле), а также Apache Tez.
Apache hive используют в production такие компании как Facebook, Grooveshark, Last.Fm и многие другие. Мы в Data-Centric alliance используем HIve в качестве основного хранилища логов нашей рекламной платформы.
Архитектура
Hive представляет из себя движок, который превращает SQL-запросы в цепочки map-reduce задач. Движок включает в себя такие компоненты, как Parser(разбирает входящие SQL-запрсоы), Optimimer(оптимизирует запрос для достижения большей эффективности), Planner (планирует задачи на выполнение) Executor(запускает задачи на фреймворке MapReduce.
Для работы hive также необходимо хранилище метаданных. Дело в том что SQL предполагает работу с такими объектами как база данных, таблица, колонки, строчки, ячейки и тд. Поскольку сами данные, которые использует hive хранятся просто в виде файлов на hdfs — необходимо где-то хранить соответствие между объектами hive и реальными файлами.
В качестве metastorage используется обычная реляционная СУБД, такая как MySQL, PostgreSQL или Oracle.
Command line interface
Для того чтобы попробовать работу с hive проще всего воспользоваться его командной строкой. Современная утилита для работы с hive называется beeline (привет нашим партнёрам из одноименного оператора :) ) Для этого на любой машине в hadoop-кластере (см. наш туториал по hadoop) с установленным hive достаточно набрать команду.
$beelineДалее необходимо установить соединение с hive-сервером:
beeline> !connect jdbc:hive2://localhost:10000/default root root
Connecting to jdbc:hive2://localhost:10000/default
Connected to: Apache Hive (version 1.1.0-cdh5.7.0)
Driver: Hive JDBC (version 1.1.0-cdh5.7.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:10000/default>root root — в данном контексте это имя пользователя и пароль. После этого вы получите командную строку, в которой можно вводить команды hive.Также иногда бывает удобно не вводить sql-запросы в командную строку beeline, а предварительно сохранить и редактировать их в файле, а потом выполнить все запросы из файла. Для этого нужно выполнить beeline с параметрами подключения к базе данных и параметром -f указывающим имя файла, содержащего запросы:
beeline -u jdbc:hive2://localhost:10000/default -n root -p root -f sorted.sqlData Units
При работе с hive можно выделить следующие объекты которыми оперирует hive:
- База данных
- Таблица
- Партиция (partition)
- Бакет (bucket)
Разберем каждый из них подробнее:
База данных
База данных представляет аналог базы данных в реляционных СУБД. База данных представляет собой пространство имён, содержащее таблицы. Команда создания новой базы данных выглядит следующим образом:
CREATE DATABASE|SCHEMA [IF NOT EXISTS] <database name>Database и Schema в данном контексте это одно и тоже. Необязательная добавка IF NOT EXISTS как не сложно догадаться создает базу данных только в том случае если она еще не существует.
Пример создания базы данных:
CREATE DATABASE userdb;Для переключения на соответствующую базу данных используем команду USE:
USE userdb;Таблица
Таблица в hive представляет из себя аналог таблицы в классической реляционной БД. Основное отличие — что данные hive’овских таблиц хранятся прост в виде обычных файлов на hdfs. Это могут быть обычные текстовые csv-файлы, бинарные sequence-файлы, более сложные колоночные paruqet-файлы и другие форматы. Но в любом случае данные, над которыми настроена hive-таблица очень легко прочитать и не из hive.
Таблицы в hive бывают двух видов:
Классическая таблица, данные в которую добавляются при помощи hive. Вот пример создания такой таблицы (источник примера):
CREATE TABLE IF NOT EXISTS employee ( eid int, name String,
salary String, destination String)
COMMENT 'Employee details'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;Тут мы создали таблицу, данные в которой будут храниться в виде обычных csv-файлов, колонки которой разделены символом табуляции. После этого данные в таблицу можно загрузить. Пусть у нашего пользователя в домашней папке на hdfs есть (напоминаю, что загрузить файл можно при помощи hadoop fs -put) файл sample.txt вида:
1201 Gopal 45000 Technical manager
1202 Manisha 45000 Proof reader
1203 Masthanvali 40000 Technical writer
1204 Kiran 40000 Hr Admin
1205 Kranthi 30000 Op AdminЗагрузить данные мы сможем при помощи следующей команды:
LOAD DATA INPATH '/user/root/sample.txt'
OVERWRITE INTO TABLE employee;После hive переместит данныe, хранящемся в нашем файле в хранилище hive. Убедиться в этом можно прочитав данные напрямую из файла в хранилище hive в hdfs:
[root@quickstart ~]# hadoop fs -text /user/hive/warehouse/userdb.db/employee/*
1201 Gopal 45000 Technical manager
1202 Manisha 45000 Proof reader
1203 Masthanvali 40000 Technical writer
1204 Kiran 40000 Hr Admin
1205 Kranthi 30000 Op AdminКлассические таблицы можно также создавать как результат select-запроса к другим таблицам:
0: jdbc:hive2://localhost:10000/default> CREATE TABLE big_salary as SELECT * FROM employee WHERE salary > 40000;
0: jdbc:hive2://localhost:10000/default> SELECT * FROM big_salary;
+-----------------+------------------+--------------------+-------------------------+--+
| big_salary.eid | big_salary.name | big_salary.salary | big_salary.destination |
+-----------------+------------------+--------------------+-------------------------+--+
| 1201 | Gopal | 45000 | Technical manager |
| 1202 | Manisha | 45000 | Proof reader |
+-----------------+------------------+--------------------+-------------------------+--+Кстати говоря, SELECT для создания таблицы в данном случае уже запустит mapreduce-задачу.
Внешняя таблица, данные в которую загружаются внешними системами, без участия hive. Для работы с внешними таблицами при создании таблицы нужно указать ключевое слово EXTERNAL, а также указать путь до папки, по которому хранятся файлы:
CREATE EXTERNAL TABLE IF NOT EXISTS employee_external ( eid int, name String,
salary String, destination String)
COMMENT 'Employee details'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION '/user/root/external_files/';После этого таблицей можно пользоваться точно так же как и обычными таблицами hive. Самое удобное в этом, что вы можете просто скопировать файл в нужную папочку в hdfs, а hive будет автоматом подхватывать новые файлы при запросах к соответствующей таблице. Это очень удобно при работе например с логами.
Партиция (partition)
Так как hive представляет из себя движок для трансляции SQL-запросов в mapreduce-задачи, то обычно даже простейшие запросы к таблице приводят к полному сканированию данных в этой таблицы. Для того чтобы избежать полного сканирования данных по некоторым из колонок таблицы можно произвести партиционирование этой таблицы. Это означает, что данные относящиеся к разным значениям будут физически храниться в разных папках на HDFS.
Для создания партиционированной таблицы необходимо указать по каким колонкам будет произведено партиционирование:
CREATE TABLE IF NOT EXISTS employee_partitioned ( eid int, name String,
salary String, destination String)
COMMENT 'Employee details'
PARTITIONED BY (birth_year int, birth_month string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;При заливке данных в такую таблицу необходимо явно указать, в какую партицию мы заливаем данные:
LOAD DATA INPATH '/user/root/sample.txt' OVERWRITE
INTO TABLE employee_partitioned
PARTITION (birth_year=1998, birth_month='May');Посмотрим теперь как выглядит структура директорий:
[root@quickstart ~]# hadoop fs -ls /user/hive/warehouse/employee_partitioned/
Found 1 items
drwxrwxrwx - root supergroup 0 2016-05-08 15:03 /user/hive/warehouse/employee_partitioned/birth_year=1998
[root@quickstart ~]# hadoop fs -ls -R /user/hive/warehouse/employee_partitioned/
drwxrwxrwx - root supergroup 0 2016-05-08 15:03 /user/hive/warehouse/employee_partitioned/birth_year=1998
drwxrwxrwx - root supergroup 0 2016-05-08 15:03 /user/hive/warehouse/employee_partitioned/birth_year=1998/birth_month=May
-rwxrwxrwx 1 root supergroup 161 2016-05-08 15:03 /user/hive/warehouse/employee_partitioned/birth_year=1998/birth_month=May/sample.txtВидно, что структура директорий выглядит таким образом, что каждой партиции соответствует отдельная папка на hdfs. Теперь, если мы будем запускать какие-либо запросы, у казав в условии WHERE ограничение на значения партиций — mapreduce возьмет входные данные только из соответствующих папок.
В случае External таблиц партиционирование работает аналогичным образом, но подобную структуру директорий придется создавать вручную.
Партиционирование очень удобно например для разделения логов по датам, так как правило любые запросы за статистикой содержат ограничение по датам. Это позволяет существенно сократить время запроса.
Бакет
Партиционирование помогает сократить время обработки, если обычно при запросах известны ограничения на значения какого-либо столбца. Однако оно не всегда применимо. Например — если количество значений в столбце очень велико. Напрмер — это может быть ID пользователя в системе, содержащей несколько миллионов пользователей.
В этом случае на помощь нам придет разделение таблицы на бакеты. В один бакет попадают строчки таблицы, для которых значение совпадает значение хэш-функции вычисленное по определенной колонке.
При любой работе с бакетированными таблицами необходимо не забывать включать поддержку бакетов в hive (иначе hive будет работать с ними как с обычными таблицами):
set hive.enforce.bucketing=true;Для создания таблицы разбитой на бакеты используется конструкция CLUSTERED BY
set hive.enforce.bucketing=true;
CREATE TABLE employee_bucketed ( eid int, name String, salary String, destination String)
CLUSTERED BY(eid) INTO 10 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;Так как команда Load используется для простого перемещения данных в хранилище hive — в данном случае для загрузки она не подходит, так как данные необходимо предобработать, правильно разбив их на бакеты. Поэтому их нужно загрузить при помощи команды INSERT из другой таблицы(например из внешней таблицы):
set hive.enforce.bucketing=true;
FROM employee_external INSERT OVERWRITE TABLE employee_bucketed SELECT *;После выполнения команды убедимся, что данные действительно разбились на 10 частей:
[root@quickstart ~]# hadoop fs -ls /user/hive/warehouse/employee_bucketed
Found 10 items
-rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000000_0
-rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000001_0
-rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000002_0
-rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000003_0
-rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000004_0
-rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000005_0
-rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000006_0
-rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000007_0
-rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000008_0
-rwxrwxrwx 1 root supergroup 31555556 2016-05-08 16:04 /user/hive/warehouse/employee_bucketed/000009_0Теперь при запросах за данными, относящимися к определенному пользователю, нам не нужно будет сканировать всю таблицу, а только 1/10 часть этой таблицы.
Checklist по использованию hive
Теперь мы разобрали все объекты, которыми оперирует hive. После того как таблицы созданы — можно работать с ними, так как с таблицами обычных баз данных. Однако не стоит забывать о том что hive — это все же движок по запуску mapreduce задач над обычными файлами, и полноценной заменой классическим СУБД он не является. Необдуманное использование таких тяжелых команд, как JOIN может привести к очень долгим задачам. Поэтому прежде чем строить вашу архитектуру на основе hive — необходимо несколько раз подумать. Приведем небольшой checklist по использованию hive:
- Данных которые надо обрабатывать много и они не влазят на диск одной машины (иначе лучше подумать над классическими SQL-системами).
- Данные в основном только добавляются и редко обновляются (если обновления часты — возможно стоит подумать об использовании Hbase например, см наш предыдущий материал.
- Данные имеют хорошо структурированную структуру и хорошо разбиваются на колонки.
- Паттерны обработки данных хорошо описываются декларативным языком запросов (SQL).
- Время ответа на запрос не критично(так как hive работает на основе MapReduce — интерактивности ждать не стоит).
Заключение
В данной статье мы разобрали архитектуру hive, data unit-ы, которыми оперирует hive, привели примеры по созданию и заполнению таблиц hive. В следующей статье цикла мы рассмотрим продвинутые возможности hive, включающие в себя:
- Транзакционную модель
- Индексы
- User-defined функции
- Интеграцию hive с хранилищами данных, отличными от hdfs
Ссылки на предыдущие статьи цикла:
» Big Data от А до Я. Часть 1: Принципы работы с большими данными, парадигма MapReduce
» Big Data от А до Я. Часть 2: Hadoop
» Big Data от А до Я. Часть 3: Приемы и стратегии разработки MapReduce-приложений
» Big Data от А до Я. Часть 4: Hbase
Поделиться с друзьями