
В настоящей статье расскажу историю о том, как можно столкнуться с довольно простой проблемой на больших инсталляциях продуктов компании Atlassian, в частности на Jira.
Методы анализа и поиска узких мест:
статистика
сэмплирование
профилирование и трассировка
В этой статье мы разберем трассировку запросов, которая показывает практически весь отрезок запроса, а именно от начала запроса с браузера клиента до перехода к обратному прокси, если он существует, к серверу приложений и от него до кэшей, поисковых индексов Lucene, СУБД.
Важный момент — сложно провести анализ системы со стороны заказчика, так как с их стороны были жесткие требования по использованию инструментов, которые перечислены в требованиях.
Требования
Расходы на APM-инструменты (инструменты для мониторинга производительности) изначально не были заложены в бюджете проекта, поэтому одним из главных критериев выбора стала бесплатность решения. Другой важный момент — нужно было предварительно проверить инструмент на наличие уязвимостей и вредоносного кода. Стало очевидно, что чтобы удовлетворить первые два критерия поиска, нужно искать open source решения. Еще одно требование — чтобы данные не выходили за пределы ограниченного контура, и была дополнительная возможность интеграции с существующей инфраструктурой.
Поэтому критерии выбора инструмента были следующими:
бесплатный;
установка на собственной инфраструктуре (On-Premise);
открытый исходный код;
возможность интеграции с Elasticsearch (Opendistro);
совместимость с JVM (поскольку Atlassian написан в основном, на Java), или как javaagent;
возможность связки запроса HTTP c SQL-запросы;
наличие графиков в перцентилях;
Для меня последний пункт важен, поскольку он помогает выявить отправную точку, чтобы не заниматься последствиями. На рисунке ниже видно, что проблема фактически началась в 12 часов ночи, а не спустя 1 час. В случае отсутствия деления на процентили легко можно потратить много времени на устранение симптомов и только потом разобраться с причиной. Конечно, случаи бывают разные.

В качестве отправной точки использовался сайт https://openapm.io/landscape, который собрал практически все актуальные APM-инструменты. После проведения сравнительного анализа мы остановили выбор на инструменте Glowroot, который удовлетворял всем критериям.
Установка
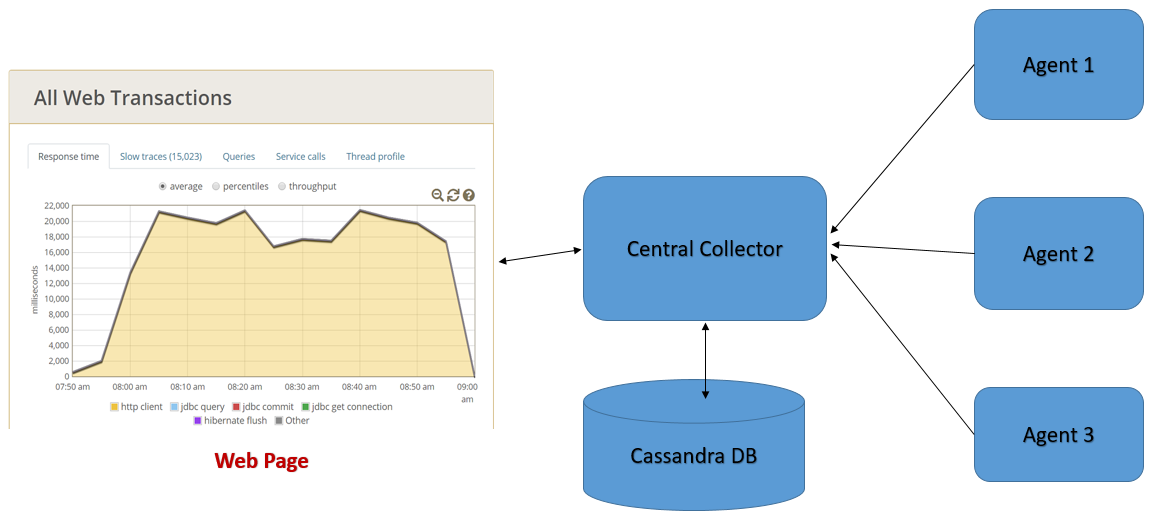
Установка приложения довольно простая на агентах, и в данной статье показана схема работы со встроенным коллектором, но для промышленных инсталляций используется Cassandra (как представлено на диаграмме) со связкой с Elasticsearch.
Скачиваем инсталлятор
wget -c https://github.com/glowroot/glowroot/releases/download/v0.13.6/glowroot-0.13.6-dist.zip2. Для проверки создаем директорию mkdir -p /jira/glowroot/tmp, чтобы владелец процесса приложения Jira мог писать в эту же директорию, и устанавливаем права на владение для простоты, но рекомендуется просто выдать возможность записи владельцу процесса Jira
chown -R jira: /jira/home/glowroot3. Устанавливаем дополнительно аргумент в setenv.sh в инсталляционной директории jira, в нашем случае это /jira/current/bin. По умолчанию, Атлассиан использует директорию /opt/atlassian/jira/bin в файле добавляем следующую строку:
JVM_SUPPORT_RECOMMENDED_ARGS="-javaagent:/jira/glowroot/glowroot.jar ${JVM_SUPPORT_RECOMMENDED_ARGS}"4.После перезапускаем приложение:
systemctl restart jiraИ мониторим на наличие ошибок посредством команды:
tail -f {jira_installation_directory}/logs/catalina.out Так как по умолчанию биндится адрес 127.0.0.1, то идем в директорию в glowroot и смотрим, что появились файлы такие, как admin.json. В ней можете поменять bindAddress на 0.0.0.0 или на нужный вам. В моем случае я добавлю contextPath - /glowroot.
И после на reverse proxy (в данном случае nginx), устанавливаем:
location /glowroot {
proxy_pass http://127.0.0.1:4000;
}Дополнительно можете посмотреть на приложенную документацию Agent-Installation-(with-Embedded-Collector)
Как результат, по нашему адресу jira.example.com/glowroot видит транзакции.

Первичные анализы
Спустя некоторое время графики и сэмплы пополняются, как следствие инженер по исследованию узких мест начинает создавать множество задач.
Например, о том, что интеграции медленные, и часть запросов идет синхронно или запросы дублируются.

Чем больше система, тем неожиданнее сюрпризы
Посредством glowroot было обнаружено, что при каждом изменении задачи в проекте с количеством пользователей более 30000, при проверке прав создавались временные таблицы на стороны СУБД. Ниже представлен trace, который это демонстрирует.
Как результат, создаются временные таблицы на стороне СУБД PostgreSQL, а на кластере PostgreSQL эта активность сильно влияет на производительность в связи с высоким показателем IOPS.

Возникал вопрос — почему кэширование на стороне приложения Jira не отрабатывало, ведь согласно thread dump информации показывает, что существует кэширование объектов.
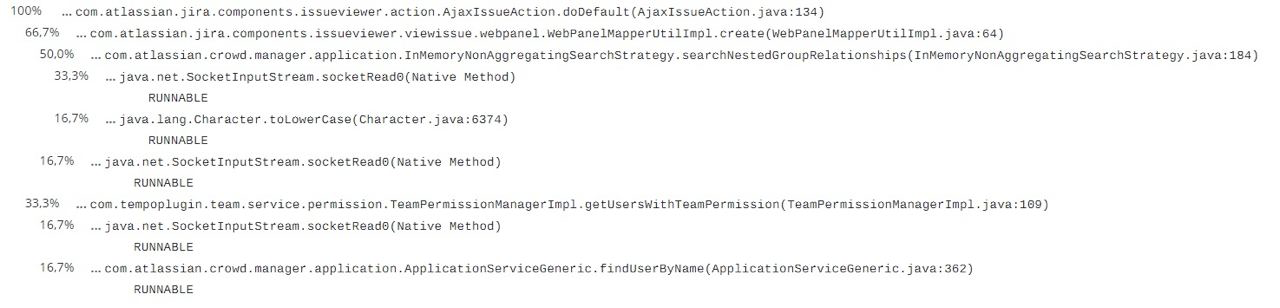
Согласно stacktrace из трассированого запроса был видно, что реализация кэширования выполнена абсолютно удобно.

При изучении stacktrace было обнаружено, что метод createTemporaryTablesIfNeeded влиял на эту деградацию по производительности.
И нижеприведенный пулл реквест изменил поведение приложения, https://bitbucket.org/atlassian/entity-engine/pull-requests/32/stable-issue-stable-issue-raid-438-in/diff, как следствие мы столкнулись с этой проблемой на большой инсталляции.

Причиной изменения было ограничение неправильно настроенных проектов и ограничение действительно больших проектов. Так что данное решение является довольно прагматичным решением в программной инженерии.
В качестве вывода
Как мы видим из примера изменения в entity engine, вендор также беспокоится за продукт и с удовольствием принимает запросы на улучшение, если это относится к его компоненте.
А решили мы свои проблемы пересборкой компоненты под наши реалии, не дожидаясь правильного и официального фикса.
Фактически у нас были следующие варианты по устранению поведения приложения для большого количества пользователей:
Изменить константу и пересобрать компонент
Изменить схему прав безопасности на уровне приложения и провести очистку и полное ревью
Переделать на unlogged таблицу cwd_users в PostgreSQL
Подскажите,сталкивались ли вы подобными ситуация и как решали? Особенно, интересны ситуации, связанные с поиском узких мест в системе посредством инструментов по анализу производительности? Как много времени потратили на установку, настройку инструментов и выявление проблем?
Буду рад вашим вопросам, а также можно задавать Atlassian сообществе в Телеграм.
Хорошего дня, Гончик.