

В серии статей я хочу опровергнуть заблуждения, связанные с управлением памятью, и глубже рассмотреть её устройство в некоторых современных языках программирования — Java, Kotlin, Scala, Groovy и Clojure. Надеюсь, эта статья поможет вам разобраться, что происходит под капотом этих языков. Сначала мы рассмотрим управление памятью в виртуальной машине Java (JVM), которая используется в Java, Kotlin, Scala, Clojure, Groovy и других языках. В первой статье я рассказал и разнице между стеком и кучей, что полезно для понимания этой статьи.
Структура памяти JVM
Сначала давайте посмотрим на структуру памяти JVM. Эта структура применяется начиная с JDK 11. Вот какая память доступна процессу JVM, она выделяется операционной системой:
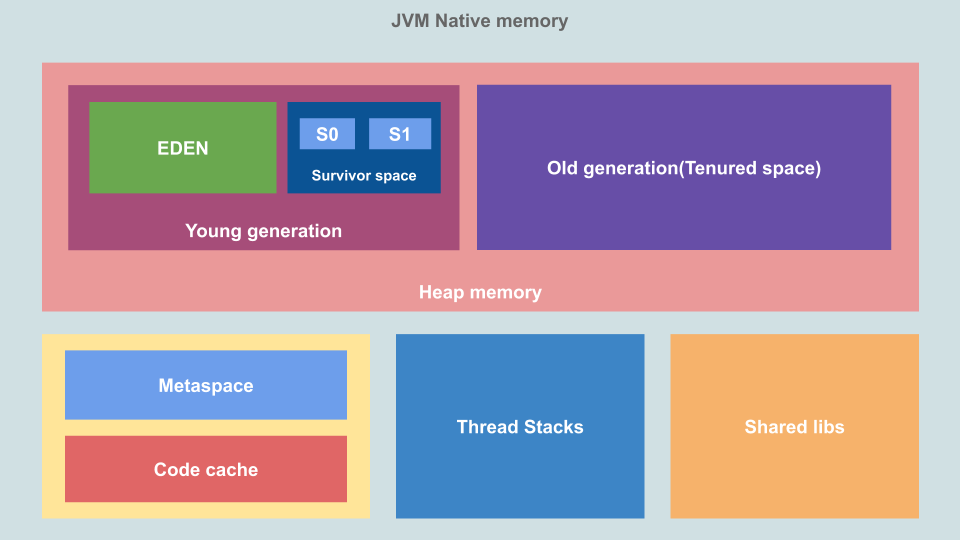
Это нативная память, выделяемая ОС, и её размер зависит от системы, процессор и JRE. Какие области и для чего предназначены?
Куча (heap)
Здесь JVM хранит объекты и динамические данные. Это самая крупная область памяти, в ней работает сборщик мусора. Размером кучи можно управлять с помощью флагов
Xms (начальный размер) и Xmx (максимальный размер). Куча не передаётся виртуальной машине целиком, какая-то часть резервируется в качестве виртуального пространства, за счёт которого куча может в будущем расти. Куча делится на пространства «молодого» и «старого» поколения.- Молодое поколение, или «новое пространство»: область, в которой живут новые объекты. Она делится на «рай» (Eden Space) и «область выживших» (Survivor Space). Областью молодого поколения управляет «младший сборщик мусора» (Minor GC), который также называют «молодым» (Young GC).
- Рай: здесь выделяется память, когда мы создаём новые объекты.
- Область выживших: здесь хранятся объекты, которые остались после работы младшего сборщика мусора. Область делится на две половины, S0 и S1.
- Старое поколение, или «хранилище» (Tenured Space): сюда попадают объекты, которые достигли максимального порога хранения в ходе жизни младшего сборщика мусора. Этим пространством управляет «старший сборщик» (Major GC).
Стеки потоков исполнения
Это стековая область, в которой на один поток выделяется один стек. Здесь хранятся специфические для потоков статичные данные, в том числе фреймы методов и функций, указатели на объекты. Размер стековой памяти можно задать с помощью флага
Xss.Метапространство
Это часть нативной памяти, по умолчанию у неё нет верхней границы. В более ранних версиях JVM эта память называлась пространством постоянного поколения (Permanent Generation (PermGen) Space). Загрузчики классов хранили в нём определения классов. Если это пространство растёт, то ОС может переместить хранящиеся здесь данные из оперативной в виртуальную память, что может замедлить работу приложения. Избежать этого можно, задав размер метапространства с помощью флагов
XX:MetaspaceSize и -XX:MaxMetaspaceSize, в этом случае приложение может выдавать ошибки памяти.Кеш кода
Здесь компилятор Just In Time (JIT) хранит скомпилированные блоки кода, к которым приходится часто обращаться. Обычно JVM интерпретирует байткод в нативный машинный код, однако код, скомпилированный JIT-компилятором, не нужно интерпретировать, он уже представлен в нативном формате и закеширован в этой области памяти.
Общие библиотеки
Здесь хранится нативный код для любых общих библиотек. Эта область памяти загружается операционной системой лишь один раз для каждого процесса.
Использование памяти JVM: стек и куча
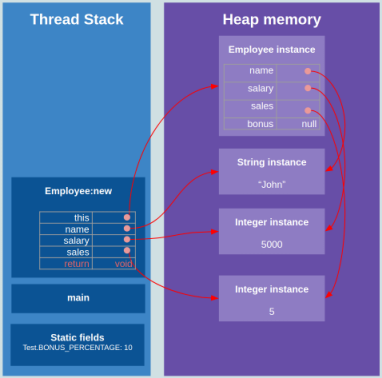
Теперь давайте посмотрим, как исполняемая программа использует самые важные части памяти. Воспользуемся нижеприведённым кодом. Он не оптимизирован с точки зрения корректности, так что игнорируйте проблемы вроде ненужных промежуточных переменных, некорректных модификаторов и прочего. Его задача — визуализировать использование стека и кучи.
class Employee {
String name;
Integer salary;
Integer sales;
Integer bonus;
public Employee(String name, Integer salary, Integer sales) {
this.name = name;
this.salary = salary;
this.sales = sales;
}
}
public class Test {
static int BONUS_PERCENTAGE = 10;
static int getBonusPercentage(int salary) {
int percentage = salary * BONUS_PERCENTAGE / 100;
return percentage;
}
static int findEmployeeBonus(int salary, int noOfSales) {
int bonusPercentage = getBonusPercentage(salary);
int bonus = bonusPercentage * noOfSales;
return bonus;
}
public static void main(String[] args) {
Employee john = new Employee("John", 5000, 5);
john.bonus = findEmployeeBonus(john.salary, john.sales);
System.out.println(john.bonus);
}
}
Здесь вы можете увидеть, как исполняется вышеприведённая программа и как используются стек и куча:
https://files.speakerdeck.com/presentations/9780d352c95f4361bd8c6fa164554afc/JVM_memory_use.pdf
Как видите:
- Каждый вызов функции добавляется в стек потока исполнения в качестве фреймового блока.
- Все локальные переменные, включая аргументы и возвращаемые значения, сохраняются в стеке внутри фреймовых блоков функций.
- Все примитивные типы вроде int хранятся прямо в стеке.
- Все типы объектов вроде Employee, Integer или String создаются в куче, а затем на них ссылаются с помощью стековых указателей. Это верно и для статичных данных.
- Функции, которые вызываются из текущей функции, попадают наверх стека.
- Когда функция возвращает данные, её фрейм удаляется из стека.
- После завершения основного процесса объекты в куче больше не имеют стековых указателей и становятся потерянными (сиротами).
- Пока вы явно не сделаете копию, все ссылки на объекты внутри других объектов делаются с помощью указателей.
Стеком автоматически управляет операционная система, а не JVM. Поэтому не нужно особо заботиться о нём. А вот куча уже так не управляется, и поскольку это самая большая область памяти, содержащая динамические данные, она может расти экспоненциально, и программа способна со временем занять всю память. Кроме того, постепенно куча фрагментируется, тем самым замедляя работу приложений. В решении этих проблем поможет JVM. Она автоматически управляет кучей с помощью сборки мусора.
Управление памятью JVM: сборка мусора
Давайте разберёмся с автоматическим управлением кучей, которое играет очень важную роль с точки зрения производительности приложения. Когда программа пытается выделить в куче больше памяти, чем доступно (в зависимости от значения
Xmx), мы получаем ошибки нехватки памяти.JVM управляет куче с помощью сборки мусора. Чтобы освободить место для создания нового объекта, JVM очищает память, занятую потерянными объектами, то есть объектами, на которые больше нет прямых или опосредованных ссылок из стека.
Сборщик мусора в JVM отвечает за:
- Получение памяти от ОС и возвращение её ОС.
- Передачу выделенной памяти приложению по его запросу.
- Определение, какие части выделенной памяти ещё используются приложением.
- Затребование неиспользованной памяти для использования приложением.
Сборщики мусора в JVM работают по принципу поколений (объекты в куче группируются по возрасту и очищаются во время разных этапов). Есть много разных алгоритмов сборки мусора, но чаще всего применяют Mark & Sweep.
Сборщик мусора Mark & Sweep
JVM использует отдельный поток демона, который работает в фоне для сборки мусора. Этот процесс запускается при выполнении определённых условий. Сборщик Mark & Sweep обычно работает в два этапа, иногда добавляют третий, в зависимости от используемого алгоритма.

- Разметка: сначала сборщик определяет, какие объекты используются, а какие нет. Те, что используются или доступны для стековых указателей, рекурсивно помечаются как живые.
- Удаление: сборщик проходит по куче и убирает все объекты, которые не помечены как живые. Эти места в памяти помечаются как свободные.
- Сжатие: после удаления неиспользуемых объектов все выжившие объекты перемещают, чтобы они были вместе. Это уменьшает фрагментацию и повышает скорость выделения памяти для новых объектов.
Такой тип сборщиков ещё называют stop-the-world, потому что пока они убираются, возникают паузы в работе приложения.
JVM предлагает на выбор несколько разных алгоритмов сборки мусора, и в зависимости от вашего JDK может быть ещё больше вариантов (например, сборщик Shenandoah в OpenJDK). Авторы разных реализаций стремятся к разным целям:
- Пропускная способность: время, затраченное на сборку мусора, а не работу приложения. В идеале, пропускная способность должна быть высокой, то есть паузы на сборку мусора короткие.
- Длительность пауз: насколько долго сборщик мусора мешает исполнению приложения. В идеале, паузы должны быть очень короткими.
- Размер кучи: в идеале, должен быть маленьким.
Сборщики в JDK 11
JDK 11 — это текущая версия LTE. Ниже приведён список доступных в ней сборщиков мусора, и JVM выбирает по умолчанию один из них в зависимости от текущего оборудования и операционной системы. Мы всегда можем принудительно выбрать какой-либо сборщик с помощью переключателя
-XX.- Серийный сборщик: использует один поток, эффективен для приложений с небольшим количеством данных, наиболее удобен для однопроцессорных машин. Его можно выбрать с помощью
-XX:+UseSerialGC. - Параллельный сборщик: нацелен на высокую пропускную способность и использует несколько потоков, чтобы ускорить процесс сборки. Предназначен для приложений со средним или большим количеством данных, исполняемых на многопоточном/многопроцессорном оборудовании. Его можно выбрать с помощью
-XX:+UseParallelGC. - Сборщик Garbage-First (G1): работает по большей части многопоточно (то есть многопоточно выполняются только объёмные задачи). Предназначен для многопроцессорных машин с большим объёмом памяти, по умолчанию используется на большинстве современных компьютеров и ОС. Нацелен на короткие паузы и высокую пропускную способность. Его можно выбрать с помощью
-XX:+UseG1GC. - Сборщик Z: новый, экспериментальный, появился в JDK11. Это масштабируемый сборщик с низкой задержкой. Многопоточный и не останавливает исполнение потоков приложения, то есть не относится к stop-the-world. Предназначен для приложений, которым необходима низкая задержка и/или очень большая куча (на несколько терабайтов). Его можно выбрать с помощью
-XX:+UseZGC.
Процесс сборки мусора
Вне зависимости от того, какой выбран сборщик, в JVM используется два вида сборки — младший и старший сборщик.
Младший сборщик
Он поддерживает чистоту и компактность пространства молодого поколения. Запускается тогда, когда JVM не может получить в раю необходимую память для размещения нового объекта. Изначально все области кучи пусты. Рай заполняется первым, за ним область выживших, и в конце хранилище.
Здесь вы можете увидеть процесс работы этого сборщика:
https://files.speakerdeck.com/presentations/f4783404769145f4b990154d0cc05629/JVM_minor_GC.pdf
- Допустим, в раю уже есть объекты (блоки с 01 по 06 помечены как используемые).
- Приложение создаёт новый объект (07).
- JVM пытается получить необходимую память в раю, но там уже нет места для размещения нового объекта, поэтому JVM запускает младший сборщик.
- Он рекурсивно проходит по графу объектов начиная со стековых указателей и помечает используемые объекты как (используемая память), остальные — как мусор (потерянные).
- JVM случайно выбирает один блок из S0 и S1 в качестве «целевого» пространства (To Space), пусть это будет S0. Теперь сборщик перемещает все живые объекты в «целевое» пространство, которое было пустым, когда мы начали работу, и повышает их возраст на единицу.
- Затем сборщик очищает рай, и в нём выделяется память для нового объекта.
- Допустим, прошло какое-то время, и в раю стало больше объектов (блоки с 07 по 13 помечены как используемые).
- Приложение создаёт новый объект (14).
- JVM пытается получить в раю нужную память, но там нет свободного места для нового объекта, поэтому JVM снова запускает младший сборщик.
- Повторяется этап разметки, который охватывает и те объекты, что находятся в пространстве выживших в «целевом пространстве».
- Теперь JVM выбирает в качестве «целевого» свободный блок S1, а S0 становится «исходным». Сборщик перемещает все живые объекты из рая и «исходного» в «целевое» (S1), которое было пустым, и повысил возраст объектов на единицу. Поскольку некоторые объекты сюда не поместились, сборщик переносит их в «хранилище», ведь область выживших не может увеличиваться, и этот процесс называют преждевременным продвижением (premature promotion). Такое может происходить, даже если свободна одна из областей выживших.
- Теперь сборщик очищает рай и «исходное» пространство (S0), а новый объект размещается в раю.
- Так повторяется при каждой сессии младшего сборщика, выжившие перемещаются между S0 и S1, а их возраст увеличивается. Когда он достигает заданного «максимального порога», по умолчанию это 15, объект перемещается в «хранилище».
Мы рассмотрели, как младший сборщик очищает память в пространстве молодого поколения. Это процесс типа stop-the-world, но он настолько быстрый, что его длительностью обычно можно пренебречь.
Старший сборщик
Следит за чистотой и компактностью пространства старого поколения (хранилищем). Запускается при одном из таких условий:
- Разработчик вызывает в программе
System.gc()илиRuntime.getRunTime().gc(). - JVM решает, что в хранилище недостаточно памяти, потому что оно заполнено в результате прошлых сессий младшего сборщика.
- Если во время работы младшего сборщика JVM не может получить достаточно памяти в раю или области выживших.
- Если мы задали в JVM параметр
MaxMetaspaceSizeи для загрузки новых классов не хватает памяти.
Процесс работы старшего сборщика попроще, чем младшего:
- Допустим, прошло уже много сессий младшего сборщика и хранилище почти заполнено. JVM решает запустить старший сборщик.
- В хранилище он рекурсивно проходит по графу объектов начиная со стековых указателей и помечает используемые объекты как (используемая память), остальные — как мусор (потерянные). Если старший сборщик запустили в ходе работы младшего сборщика, то его работа охватывает пространство молодого поколения (рай и область выживших) и хранилище.
- Сборщик убирает все потерянные объекты и возвращает память.
- Если в ходе работы старшего сборщика в куче не осталось объектов, JVM также возвращает память из метапространства, убирая из него загруженные классы, если это относится к полной сборке мусора.
Заключение
Мы рассмотрели структуру и управление памятью JVM. Это не исчерпывающая статья, мы не говорили о многих более сложных концепциях и способах настройки под особые сценарии использования. Подробнее вы можете почитать здесь.
Но для большинства JVM-разработчиков (Java, Kotlin, Scala, Clojure, JRuby, Jython) этого объёма информации будет достаточно. Надеюсь, теперь вы сможете писать более качественный код, создавать более производительные приложения, избегая различных проблем с утечкой памяти.

brrr
Хороший перевод. Вот только где тут мифы?)
yngui
Мифы развеяны.