

Я искал материалы об истоках объектно-ориентированного программирования. Причина была в том, что в сообществе Laravel возникла тенденция использовать паттерн Action и говорить вот что такое «настоящее ООП». У меня возникли некоторые сомнения, и вместо того, чтобы задавать вопросы, я решил поискать ссылки времён Smalltalk. Нашёл книгу Smalltalk, Objects, and Design. И мне было так интересно её читать, что я решил поделиться с вами своими находками.
Паттерн Action гласит, что логику нужно обёртывать в классы Action. Эта идея не нова, в других сообществах продвигалась «Чистая архитектура», при которой каждый «сценарий использования» (или Interactor) должен являться самостоятельным классом. Всё очень просто. Но об этом ли говорит ООП?
Если вам интересна суть статьи, то:
- Smalltalk был одним из первых ООП-языков. Он стал источником таких концепций, как наследование и обмен сообщениями (или как минимум он их популяризировал, насколько я вижу).
- Как сказал Алан Кей, придумавший термин «объектно-ориентированное программирование», объектов не достаточно. Они не обеспечивают нам архитектуру. Объекты — это про взаимодействие между ними, и в случае с большими системами вам нужна возможность разделения приложения на модули, которые можно отключать по отдельности, заменять и включать снова в общую систему, не кладя при этом всё приложение. В этом контексте Алан предлагает идею инкапсуляции «сообщений» в классы, когда каждый экземпляр является сообщением в системе, подкрепляя идею наличия в Чистой архитектуре классов «Action» или «интеракторов».
Продолжайте читать, если я разжёг в вас интерес.
Что такое объекты?
У объекта есть комбинация состояния и операций. Когда было предложено это понятие, приложения писали со структурами данных и процедурами. Объединив состояние и операции в единую «сущность» под названием «объект», мы наделяли её антропоморфным значением. Объекты можно назвать «маленькими существами». Им известна какая-то информация (состояние), и они могут реагировать на отправляемые им сообщения.
Эти сообщения обычно имеют форму вызова метода, и идея распространилась по другим языкам, в том числе Java и С++. Джо Армстронг, один из соавторов Erlang, написал на форуме Elixir, что в Smalltalk сообщения «были на самом деле не сообщениями, а замаскированными синхронными вызовами функций», и эту «ошибку» (по его мнению) повторили в других языках.
Многие ошибочно считают объекты типами. Типы (или абстрактные типы данных, что можно считать «синонимом» — или близким по значению, по крайней мере в контексте этой статьи) не являются объектами. Как отметил Кей на этом семинаре, нас может запутать способ использования объектов в те годы, потому что он тесно связан с другой идеей из 1960-х: с абстракцией данных. В какой-то степени эти понятия схожи, особенно в реализации, но назначение у них разное.
По словам Кея, суть абстракции заключалась в том, чтобы взять систему на Pascal или FORTRAN, которую уже было трудно изменить (в которой знание было распределено по процедурам), и создать обёртки для структур данных, вызывая операции в зависимости от назначения процедуры, чтобы несколько уменьшить зависимость от представления. Затем структуру данных обёртывали в процедуры, чтобы защитить её. Но сегодня такая получившаяся конструкция используется как новая структура данных в системе. И это не приводит к уменьшению кода. А одним из результатов применения ООП является уменьшение объёма программ.
По мнению Кея, Java и С++ не являются примерами «настоящего ООП». Барбара Лисков отметила, что Java была комбинацией абстракции данных с идеями наследования из Smalltalk. Честно говоря, я не могу сформулировать разницу между абстракциями данных и объектами в ООП. Возможно, потому, что я изучал ООП именно на примере Java.
Что ещё любопытно, в те годы не было уверенности в возможности реализации полиморфизма в сильно типизированных языках (откуда пришла абстракция данных), потому что компилятор явно свяжет типы и никому не захочется, к примеру, переписывать функции сортировки для каждого типа (Лисков говорит об этом в вышеупомянутом выступлении). Насколько я понимаю, эту проблему решают интерфейсы, протоколы и дженерики. Всё это для меня в каком-то смысле способ достижения динамического связывания в сильно типизированных языках (сюда я добавляют и некоторые паттерны проектирования).
Похоже, Кею не нравится то, во что превратилась исходная идея в результате смешивания абстракции данных и ООП. Он согласен с Армстронгом. По мнению Кея, объектная ориентированность связана с тремя понятиями:
- обямен сообщениями;
- локальным сохранением и защитой, а также со скрытием состояния-процесса (или инкапсуляцией);
- экстремальным динамическим связыванием.
Всё это, по словам Кея, черты «настоящее ООП». Термин «угнали» и каким-то образом превратили, по мнению Армстронга, в «организацию кода в виде классов и методов». Но «настоящее ООП» не об этом.
Объекты обычно больше самих структур данных. Обычно они охватывают целые компоненты. Это активные машины, которые сочетаются с другими активными машинами для создания структуры нового вида.
Чтобы выяснить истинную суть понятий, Кей предложил добавлять «не» к «основным убеждениям». Возьмём, к примеру, «большие данные». Если добавить «не», то получатся «НЕ большие данные», а если мы говорим не о больших данных, то о чём же тогда? Сделаем то же самое с «объектно-ориентированным программированием»: если дело не в объектной ориентации, то в чём? Похоже, мы говорим о сообщениях. Это ключевая идея ООП, пусть даже во времена Smalltalk много говорили о наследовании. Да, обмен сообщениями тоже является важной частью, но поскольку это было практически «замаскированными синхронными вызовами функций», сообщения выпали из поля зрения, когда идея стала мейнстримом.
Рассмотрим в качестве примера, банковское ПО. Смоделируем счёт: для него нужно отслеживать текущий баланс и уметь обрабатывать снятие денег со счёта, когда запрошенная сумма меньше текущего баланса. Также нужно уметь работать с депозитами. На иллюстрации показано возможное упрощённое представление объекта «счёт»:
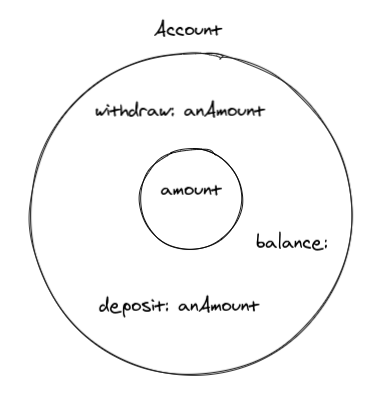
Есть несколько рекомендаций о том, как определять в требованиях объекты и методы: хорошими кандидатами на роль «объектов» являются существительные, а «глаголы» — кандидаты на роль «методов». Это рекомендации, а рекомендации считаются «хорошими по умолчанию».
Материализация
ООП очень удобно для моделировать абстрактных идей. Можно притвориться, что в нашем ПО существуют в виде объектов (или «маленьких существ») какие-то неосязаемые понятия. Термин «материализация» (reification) означает, что мы обращаемся с нематериальными понятиями так, как если бы они были материальные. Мы прибегаем к этому каждый раз, когда пишем программы, особенно в ООП. Наша модель счёта — один примеров материализации. Он удовлетворяет правилу «существительных» и «глаголов», потому что в нашем контексте это имеет смысл. Вот простой пример депозита:
class Account extends Model
{
public function deposit(int $amountInCents)
{
DB::transaction(function () {
$this->increment('balance_cents', $amountInCents);
});
}
}
Примечания к Active Record
Приведённый код написан в контексте Laravel. Мне повезло работать с собственными базами данных, так что я не считаю их внешним уровнем своего приложения (см. это), что позволяет мне использовать все возможности своих инструментов, таких как Eloquent ORM — реализации Active Record для тех, кто не знаком с Laravel. Поэтому в моей модели есть вызовы базы данных. Однако не все классы в моих расширениях предметной модели являются моделями Active Record (см. это). Советую поэкспериментировать с разными подходами, чтобы вы могли составить своё мнение. Я лишь показываю альтернативы, которые мне нравятся.
Но на этом история не заканчивается. Иногда в зависимости от ситуации нужно нарушать эти «правила». Например, вам может понадобиться отслеживать каждую транзакцию, связанную со счётом. Можете попробовать смоделировать это на основе релевантных предметных методов, например, с помощью событий и слушателей. Это может сработать. Допустим, вы должны иметь возможность запланировать перевод или платёж по счёту, или даже отменить эти операции, если они ещё не выполнены. И если хорошо прислушаться, то можно почти услышать, как ваша система о чём-то спрашивает. Нам мало знать один лишь баланс счёта. Пусть на нём лежит 100 тыс. долларов, но как они туда попали? Вам нужно знать об этом. И если смоделировать всё, что связано со счётом, то он разрастётся до размеров божественного объекта.
Поэтому возникли подходы вроде Event Sourcing (порождение событий). Он может быть решением, поскольку основным примером для него является банковская система. Но можно смоделировать эту задачу и с помощью объектно-ориентированного подхода.
Допустим, наш контекст изменился. И теперь нам нужно сосредоточиться на выполненных транзакциях, относящихся к счёту (пока только «снятие» и «депозит»). Они заслуживают главной сцены в нашем приложении. Пусть эти операции — транзакции — будут объектами. И эти объекты пусть имеют своё состояние. В этом случае мы могли бы иметь по одной операции для каждого метода в модели счёта в виде собственного объекта. Публичный API счёта не изменится, только внутренняя реализация.
Вместо простого манипулирования состоянием баланса, объект «счёт» будет создавать экземпляры каждый транзакции и внутренне их отслеживать. Но это не всё. Каждая транзакция будет по своему влиять на баланс счёта: депозит увеличивает, а снятие уменьшает. Всё это иллюстрирует другую важную идею из объектно-ориентированного программирования: полиморфизм.
Полиморфизм
Этот термин означает многообразие форм. Суть в том, что я могу создать разные реализации, удовлетворяющие одному API (интерфейсу, протоколу или утиному тесту). Это полностью соответствует нашему определению разных транзакций, которые по-разному влияют на счёт. Если смоделировать это с помощью моделей Active Record, то мы получим:
- счёт (AR-модель), который содержит отсортированный список всех транзакций;
- транзакцию в виде AR-модели, которая имеет полиморфическую связь под названием «transactionable»;
- все транзакции будут удовлетворять поведению «transactionable».
Хитрость в том, чтобы модель счёта никогда сама не трогала баланс. Поле баланса практически должно служить кешируемым значением результата каждой применённой транзакции. Потом счёт передаёт себя в транзакцию, ожидая, что транзакция обновит его баланс. Затем транзакция делегирует эту задачу каждой transactionable, которые могут применять к счёту свои изменения. Звучит сложнее, чем есть на самом деле, так что вот вам пример депозита:
use Illuminate\Database\Eloquent\Model;
class Account extends Model
{
public function transactions()
{
return $this->hasMany(Transaction::class)->latest();
}
public function deposit(int $amountInCents)
{
DB::transaction(function () {
$transaction = Transaction::make()
->transactionable()
->associate(Deposit::create([
'amount_cents' => $amountInCents,
]));
$this->transactions()->save($transaction);
$transaction->apply($this);
});
}
}
class Transaction extends Model
{
public function transactionable()
{
return $this->morphTo();
}
public function apply(Account $account)
{
$this->transactionable->apply($account);
}
}
class Deposit extends Model
{
public function apply(Account $account)
{
$account->increment('balance_cents', $this->amount_cents);
}
}
Как видите, публичный API для поведения
$account->deposit(100_00) не изменился.Ту же самую идею можно применить и к другим темам. Например, если у вас есть модель документа в контексте совместного редактирования текста, то вы не можете полагаться на одно текстовое поле
content, содержащее текущее состояние содержимого документа. Вам понадобится отслеживать каждую операцию трансформации документа.Впервые я узнал об этой идее из выступления Адама Уэтана и его статьи Pushing Polymorphism to the Database. Также я нашёл ссылки на неё в книге Smalltalk, Objects, and Design и в недавнем Rails PR, где представлены делегированные типы. Я считаю это мощным и универсальным инструментом, о котором мало говорят, поэтому упомянул о нём здесь.
Другой пример — PaaS-приложение. Вы выделяете серверы и развёртываетесь на них. Это короткое описание можно смоделировать как
$server->deploy(string $commitHash). А если пользователь может отменить развёртывание? Или откатиться на предыдущее? Такое изменение в требованиях должно подстегнуть вас хотя бы к экспериментам с передачей деплоя в собственный объект Deployment или нечто похожее.И хочу показать ещё один пример материализации. Пусть у вас есть две взаимодействующие по поведению сущности, а логика не соответствует одной из них. Или они обе могут быть кандидатами на это поведение. Допустим, у вас есть модели «студент» и «курс», и вам нужно отслеживать их присутствие и успеваемость (будем считать, что у присутствие имеет значения
present | absent, а успеваемость оценивается в диапазоне 0...10). Где нам хранить эти данные?Может показаться, что они не должны храниться ни в «курсе», ни в записях «студент». Почти кажется, что решением может стать полный отказ от ООП и использование функции, которой вы могли бы передать оба объекта. Если материализовать эту задачу, мы можем установить взаимосвязь студент/курс для объекта под названием
StudentCourse. Это было бы идеальным местом для хранения данных о присутствии и успеваемости. Абстракции как упрощения
Я уже писал об этой идее. У меня ощущение, что некоторые люди считают абстракции запутанными архитектурными решениями и синонимом «многочисленных уровней». Но я понимаю абстракции иначе — это упрощения.
У Алана Кея есть об этом хорошая презентация. Он утверждает, что мы достигаем простоты, когда находим более сложные кирпичики для наших теорий. Модель, которая лучше подходит под нашу тему, и понятия, которые «просто имеют смысл».
Возьму пример с Кеплером и теорией эллиптической орбиты, который использовал Кей (подробнее об этом написано здесь). В те времена религия утверждала, что планеты движутся по идеальным окружностям, Солнце вращается вокруг Земли, а другие объекты вращаются вокруг Солнца.

Это выглядело странно, потому что в разные дни небесные тела находились в разных местах небосвода (не считая иных нестыковок), поэтому возникла другая теория, согласно которой орбиты всё ещё оставались идеально круглыми, но объекты двигались не по кругу, а по сложным траекториям, которые на макроуровне сводились к окружностям:
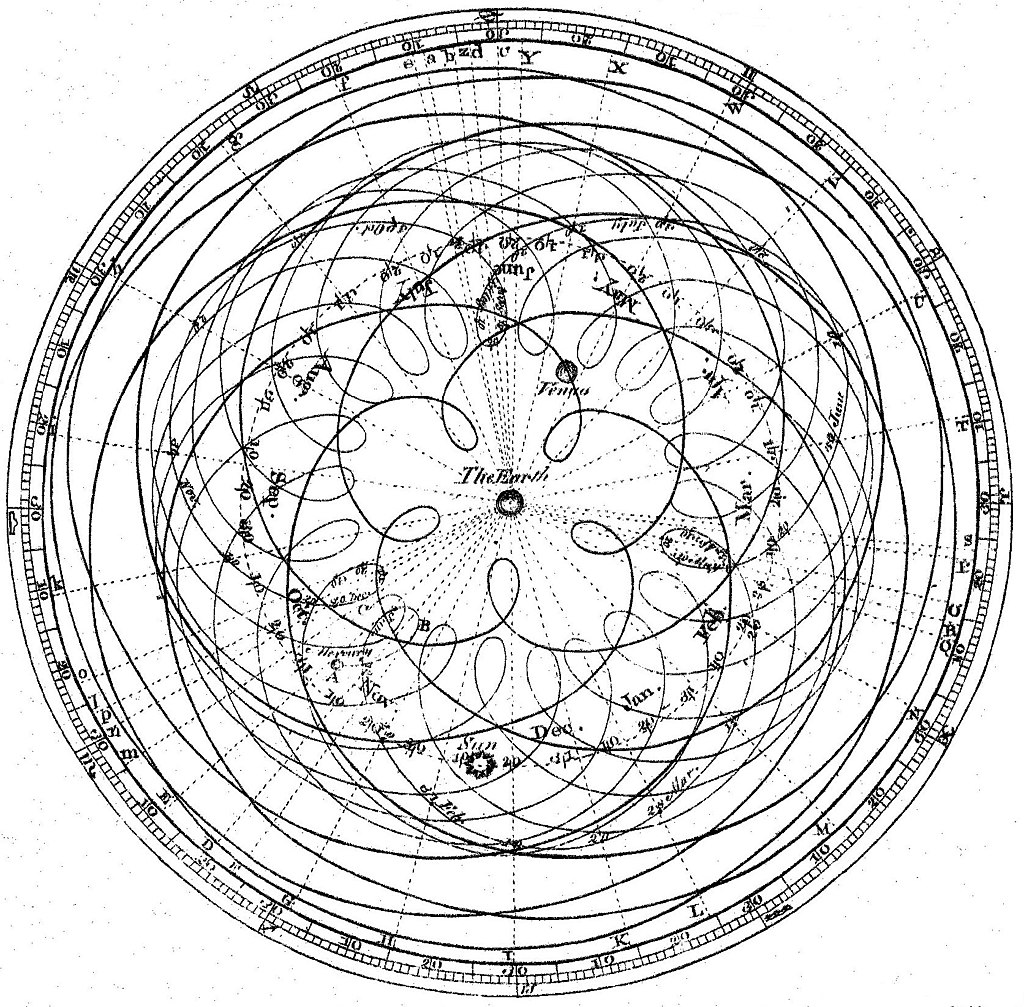
Кеплер тоже в это верил, но после бесплодных попыток объяснить некоторые особенности движения объектов он отбросил идею идеальных окружностей и предположил, что орбиты на самом деле эллиптические, а планеты вращаются вокруг Солнца, тем самым сильно упростив модель (подробнее читайте здесь).

Его наблюдения легли в основу теории тяготения Ньютона, которая позднее привела к теории относительности Эйнштейна. Этот пример иллюстрирует, что правильный уровень абстракции часто упрощает модели. Понятия «просто имеют смысл» потому, что они легче поддаются пониманию, чем альтернативы. И это итеративный процесс.
Объекты в целом
Мы говорили о присвоении методов объектам. Но это не то же самое, что применять в качестве классов Action или сценарии использования, верно? Тут речь о предметных моделях на правильном уровне абстракции.
На своём семинаре Кей утверждал, что в больших системах недостаточно одних лишь объектов, в основном из-за сложности систем. Нам нужна возможность отключать, заменять и возвращать в работу отдельные компоненты — модули — без влияния на работу всей системы. Или, скажем, вам удобно будет реализовать конкретную часть системы на другом языке из-за его производительности или более точных вычислений с плавающей запятой.
Сложность тут в том, что мы пытаемся защитить сообщения от внешнего мира (нашего протокола). Но даже со всеми защитами, которые предлагает ООП (например, инкапсуляцию), это не гарантирует нам хорошей архитектуры.
Кей даже упоминает, что в изучении Smalltalk и ООП было две фазы:
- Сначала вы очарованы парадигмой и считаете её серебряной пулей, которую так давно искали.
- А потом иллюзии рассеиваются, потому что вы на своём опыте убеждаетесь, что Smalltalk не масштабируется.
Один из способов заставить ООП работать в больших системах заключается в создании класса для тех «целей», достижение которых в нашем приложении мы хотим гарантировать. Это выглядит как тип в типизируемом языке, но не является структурой данных. Сосредоточиться нужно на цели, а не типе. Кей приводит в пример класс
Print, каждый экземпляр которого является сообщением (вместо вызовов методов в объекте). Это похоже на то, что мы видим сегодня в качестве Action или сценариев использования.В Smalltalk всё является объектами. С этим тут всё серьёзно, даже сообщения под капотом являются объектами. Разница между сообщение и вызовом функции в том, что сообщение содержит получатель. Например, в IBM Smalltalk даже есть разные классы для сообщений с получателем и без него (см. «Message and DirectedMessage» в документации). И когда мы отправляем объекту сообщение, мы на самом деле говорим runtime-среде назначить метод для получателя сообщения. Можете считать это целью по умолчанию для сообщения. Кей предлагает, чтобы мы могли создавать собственные цели для наших систем. Поговорим об этом ниже.
Другая проблема ООП, которую описал Кей, заключается в том, что мы слишком сильно беспокоимся о состоянии объектов и пренебрегаем потоком управления (кто и кому отправляет сообщение). Это приводит к путанице. Объект шлёт сообщение другому объекту, который шлёт сообщение нескольким другим объектам, к те шлют сообщения ещё большему количеству объектов. Желаю успеха в попытках разобраться в подобной системе.
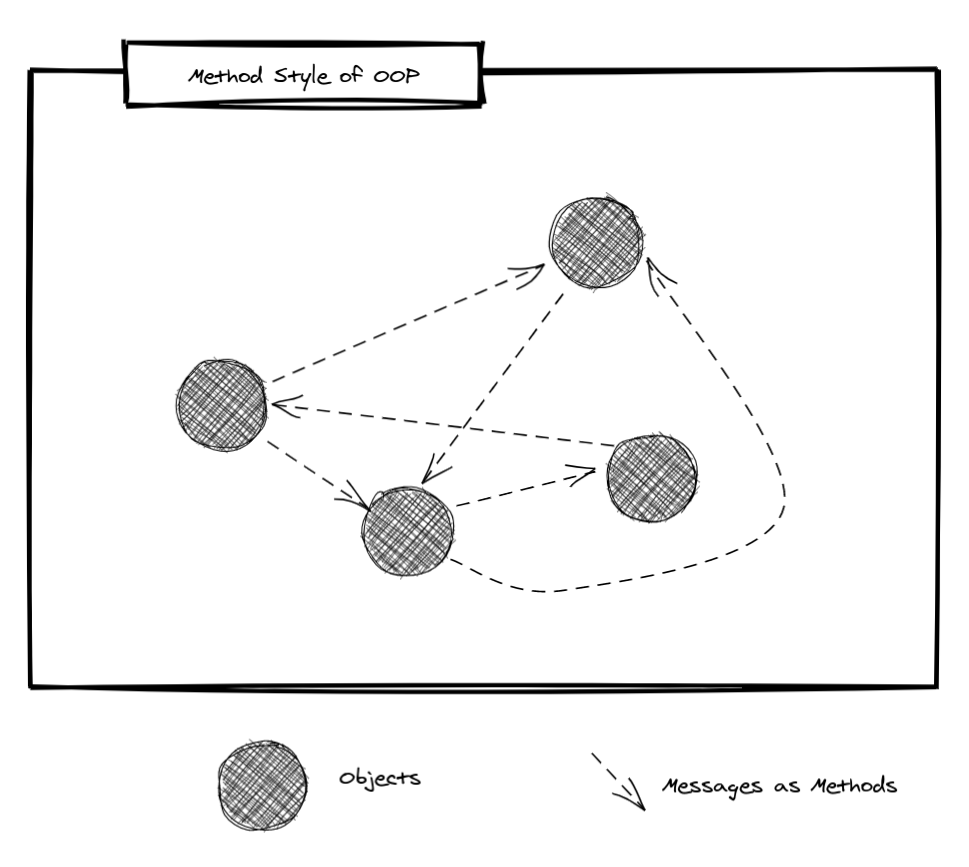
Кей предлагает переформулировать подход Pub/Sub. В Smalltalk использовался более декларативный подход. Вместо отправки сообщений напрямую друг другу, объекты должны объявлять системе, какие сообщения их интересуют (подписаться на на них). Затем сообщения вещаются в системе (публикуются). Если вы когда-нибудь занимались пользовательским интерфейсом, тот эта концепция вам знакома, потому что он выглядит как слушатели событий в JavaScript.
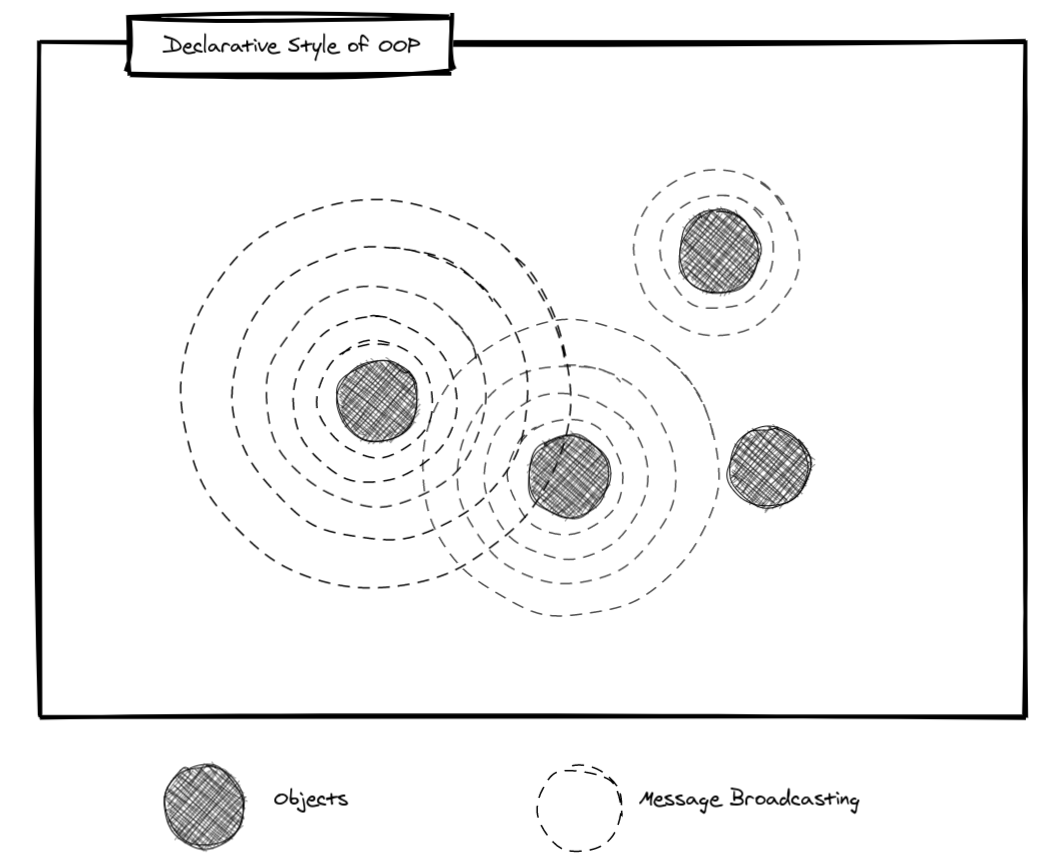
Такая декларативность впечатляет, она представлена в некоторых функциональных языках (если хотите узнать, где ООП-идеи пересекаются с ФП, то посмотрите выступление «Oops! OOP's not what I thought«).
Сообщения как объекты
Давайте обсудим предложение Кея о реализации собственных целей в системе. В нашем примере со счётом в приложении может быть действие
Deposit. Оно может быть полностью независимым от внешнего мира (транспортные механизмы: я обращаюсь с БД как с внутренней частью моих приложений), например, так:namespace App\Actions;
use App\Models\Account;
use App\Models\Transaction;
use App\Models\Transactions\Deposit as DepositModel;
use Illuminate\Support\Facades\DB;
class Deposit
{
public function handle(Account $account, int $amountInCents): void
{
DB::transaction(function () use ($account, $amountInCents) {
$transaction = Transaction::make()
->transactionable()
->associate(DepositModel::create([
'amount_cents' => $amountInCents,
]));
$account->transactions()->save($transaction);
$transaction->apply($account);
});
}
}
Вы могли заметить, что наша модель счёта больше не содержит метода для депозита (или не нуждается в нём). Честно говоря, у меня смешанные чувства от этого решения. Возможно, здесь всё в порядке, ведь мы также передали объекту сообщение
Deposit? Можно было бы реализовать в счёте интерфейс, который бы делегировал это действие:use App\Actions\Deposit as DepositAction;
class Account extends Model
{
public function deposit(int $amountInCents)
{
(new DepositAction())->handle($this, $amountInCents);
}
}
Так мы сохраним поведение отдельно от самого объекта, по прежнему обеспечивая в модели счёта простой в использовании API. Мне кажется, сегодня так будет удобнее.
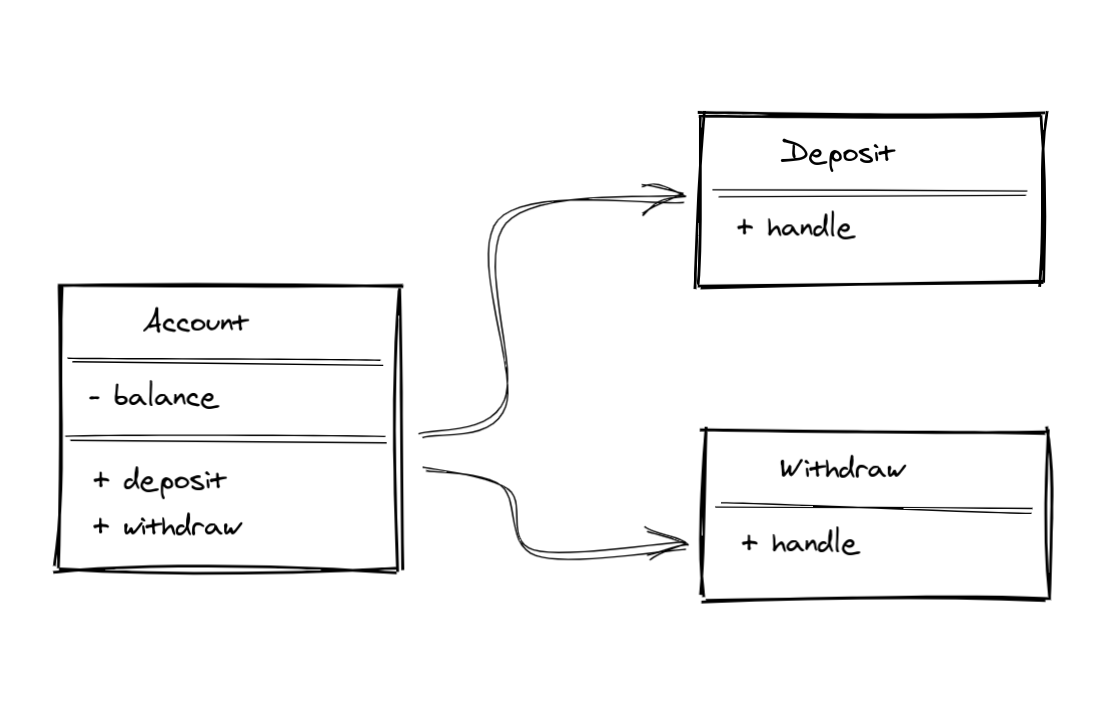
Один из «недостатков» этого подхода в том, что каждая зависимость сообщения
Deposit будет также частью сигнатуры метода интерфейса. Ничего особенного, и чаще всего это имеет смысл. Допустим, вы моделируете действие оплаты счёта, и наверняка вам понадобится передать зависимость PaymentProvider в интерфейс $invoice->pay($provider, $amount) (или фабрику).Кроме того, в Laravel здесь можно использовать абстракцию Job, которая может быть синхронной или асинхронной. Это тоже пойдёт нам на пользу (обработка фоновой job в качестве «сообщения» для асинхронного выполнения задачи).
Заключение
По большей части я хотел поделиться своими открытиями и услышать разные мнения. Я не пытался ни в чём вас убедить. Я сам примиряюсь с идеей использования действий в качестве поведения (как сообщений). Иногда это выглядит как «процедуры», в которых мы извлекаем логику по наименованию. Не уверен, что воспользуюсь этими идеями в своих приложениях, но мне нравится комбинировать их с интерфейсами в моделях.
Критика ООП
Читая книгу Smalltalk, Objects, and Design, я узнал, что Дейкстре не нравится ООП (см. ветку на Quora). Он против использования метафор и аналогий в ПО и за более «формальный» и математический способ построения приложения (в терминах формального мышления), поскольку он предложил термин «структурированное программирование». Но в книге также упоминается об экспериментальных исследованиях и творчестве, которые говорят о том, что творческий процесс подпитывает воображение, а не формальное мышление. Я считаю, что это очень интересная тема для исследования.
Ссылки
- Семинар Алана Кея об ООП (YouTube)
- Выступление Барбары Лисков на TEDxMIT: Как абстракция данных навсегда изменила информатику (YouTube)
- Smalltalk, объекты и проектирование (книга)
- Laravel Beyond CRUD: Actions (публикация в блоге)
- Беседа с Бадри Джанакираман о Hexagonal Rails (видео)
- Чистая архитектура (публикация в блоге)
- Выступление Алана Кея в 2015-м: Сила простоты (YouTube)
- Сообщение Джо Армстронга на форуме Elixir (ссылка)
- Джо Армстронг интервьюирует Алана Кея (YouTube)
- Выступление Адама Уэтона «Pushing Polymorphism to the Database» (публикация в блоге и видео)
- DHH Rails Pull Request с делегированными типами (ссылка)
- Выступление Анджаны Вакил «Oops! OOP's not what I thought» (YouTube)
- Выступление Анджаны Вакил «Programming Across Paradigms» (YouTube)
teology
Вариант 1. Студент1 присутствует на курсе1.
Вариант 2. Курс1 принимает студента1, студента2,…
Вариант 3. Журнал_посещаемости имеет запись про студента1 и курс1.
Все варианты материалистичны, тут просто вопрос: а в вашем бизнес-процессе как используется информация о посещениях? От этого и зависит выбор того или иного варианта.
ООП во многих (а скорее всего во всех) ЯП не позволяет границам объектов пересекаться. А это интересная мысль. Возможно в этом и состоит идея подписки/публикации.
Представим себе ЯП, в котором возможно следующее: переменная «посещение» будет относиться как к классу «студент», так и к классу «курс». Между классами возникло Intersection. У нас может быть 100 студентов и 3 курса. Автоматически выделяется память под каждое пересечение объектов. А обращаться к этой памяти как к объекту, так как пересечение объектов — это набор некоторых полей и методов, то есть тоже объект.
Обращение к пересечению объектов (как я вижу):
intersection(course1, student1).present
А если еще придумать обращение к пересечению классов? Тогда можно класс «журнал посещаемости» определить в два счета. Нет?
Такой подход с пересечениями мог бы избавить от думки, куда должна входить переменная. Да пускай она входит во все объекты, ведь это так на самом деле (материалистично). Но к сожалению, ЯП не позволяют пересечения объектов.(((
niko1aev
Мой опыт показывает, что глаголы должны быть убраны из описания предметных областей.
Они всегда всё портят. Нужно оставить только один глагол: TO BE
Есть студенты.
Есть курсы.
Есть посещения студентом курса. (Это отдельный класс, а если речь про БД, то это будет таблица где будут например данные: id, student_id, course_id, date, time)
То есть нет никакого «Журнала посещаемости», который имеет записи. Есть просто ПОСЕЩЕНИЯ.
И тогда да, у вас у студента будут student.visits, у курса будут course.visits
И это всё прекрасно работает. Если вам хочется пересечения, то это уже отдельный объект/класс/таблица БД и т.д.
И кажется, что это не зависит от языков программирования. Так просто удобно. Если мы говорим про объекты, то надо говорить про их объекты и их свойства.
VolCh
Журнал посещаемости — просто обёртка над коллекцией всех посещений, возможно с какими-то методами специфичными для предметной области типа получения списка прогульщиков, подлежащих отчислению
andreyverbin
Называется multiple dispatch, было ещё в lisp образцу 90х. Сейчас есть много где — https://en.m.wikipedia.org/wiki/Multiple_dispatch
teology
Интуитивно похоже на то, что я описал, но…
Я говорю про особенность выделения памяти для пересечений данных, а множественная диспетчеризация — это про функции, которые могут работать с этими пересечениями. То есть мультиметоды могут заполнять пересеченные данные. Или я что-то не понимаю?
Например, в игровом движке — юнит1 и юнит2, мы задаем для них пересечение — переменная булевого типа. False — нет столкновения, True — есть столкновение. Эта переменная имеет одинаковое имя и доступна в обоих объектах, а память используется общая. Все, больше я ничего не предлагаю.
И тут приходят на помощь мультиметоды, которые позволят вычислить столкновение разных игровых объектов. Результат выполнения мультиметода можно записывать в переменную-пересечение.
Мне кажется, это что-то вроде дружественного класса (friend в c++), точнее дружественного поля.)))