

Крупнейшие облачные провайдеры подключают виртуальные накопители к выделенным физическим серверам. Но если заглянуть в ОС сервера, то там будет физический диск с именем провайдера в поле «производитель». Сегодня мы разберем, как это возможно.
Что такое Smart NIC?
В основе этой «магии» лежат «умные» сетевые карты (Smart NIC). Такие сетевые карты имеют собственный процессор, оперативную память и накопитель. По факту это мини-сервер, выполненный в виде PCIe-карты. Основная задача «умных» карт — разгрузка CPU от операций ввода-вывода.
В данной статье мы поговорим о конкретном устройстве — NVIDIA BlueField 2. NVIDIA называет такие устройства DPU (Data Processing Unit), целью которых производитель видит «освобождение» центрального процессора от множества инфраструктурных задач — СХД, сети, информационной безопасности и даже управления хостом.
В нашем распоряжении устройство, внешне похожее на обычную 25GE сетевую карту, но в ней установлен восьмиядерный ARM-процессор Cortex-A72 c 16 ГБ оперативной памяти и 64 ГБ постоянной eMMC-памяти.
Дополнительно видны разъемы Mini-USB, NC-SI и RJ-45. Первый разъем предназначен исключительно для отладки и в продуктовых решениях не используется. NC-SI и RJ-45 позволяют подключаться к BMC-модулю сервера через порты карты.
Хватит теории, время запускать.
Первый запуск
После установки сетевой карты первый запуск сервера будет непривычно долгим. Все дело в том, что UEFI-прошивка сервера опрашивает подключенные PCIe-устройства, а «умная» сетевая карта блокирует этот процесс, пока не загрузится сама. В нашем случае процесс загрузки сервера длился около двух минут.
После загрузки ОС сервера можно увидеть два порта умной сетевой карты.
root@host:~# lspci
98:00.0 Ethernet controller: Mellanox Technologies MT42822 BlueField-2 integrated ConnectX-6 Dx network controller (rev 01)
98:00.1 Ethernet controller: Mellanox Technologies MT42822 BlueField-2 integrated ConnectX-6 Dx network controller (rev 01)
98:00.2 DMA controller: Mellanox Technologies MT42822 BlueField-2 SoC Management Interface (rev 01)На этот момент умная сетевая карта ведет себя как обычная. Для взаимодействия с картой нужно скачать и установить BlueField-драйверы со страницы NVIDIA DOCA SDK. По окончании процесса установщик предложит перезапустить сервис openibd, чтобы загрузились установленные драйверы. Перезагружаем:
/etc/init.d/openibd restartЕсли все было выполнено правильно, то в ОС появится новый сетевой интерфейс tmfifo_net0.
root@host:~# ifconfig tmfifo_net0
tmfifo_net0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::21a:caff:feff:ff02 prefixlen 64 scopeid 0x20<link>
ether 00:1a:ca:ff:ff:02 txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 13 bytes 1006 (1.0 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0По умолчанию BlueField имеет адрес 192.168.100.2/24, поэтому назначаем интерфейсу tmfifo_net0 адрес 192.168.100.1/24. Затем запускаем сервис rshim и ставим его в автозагрузку.
systemctl enable rshim
systemctl start rshimПосле этого доступ к ОС карты с сервера возможен двумя способами:
- через SSH и интерфейс tmfifo_net0;
- через консоль — символьное устройство /dev/rshim0/console.
Второй способ работает вне зависимости от состояния ОС карты.
Также возможны и другие способы удаленного подключения к ОС карты, которые не требуют доступа к серверу, в который установлена карта:
- по SSH через 1GbE out-of-band mgmt порт или через uplink интерфейсы (в том числе с поддержкой PXE boot);
- консольный доступ через выделенный RS232 порт;
- RSHIM интерфейс через выделенный USB порт.
Взгляд изнутри
Теперь, когда мы получили доступ в ОС карты, есть возможность удивиться тому факту, что внутри нашего сервера стоит сервер поменьше. Предустановленный на карте образ ОС содержит все необходимое ПО для управления картой и, кажется, даже больше. На сетевой карте стоит полноценный дистрибутив Linux, в нашем случае — Ubuntu 20.04.
При необходимости на сетевую карту возможно установить любой дистрибутив Linux, поддерживающий архитектуру aarch64 (ARMv8) и UEFI. Если подключиться через консоль, то нажатием ESC при загрузке карты можно попасть в ее собственный UEFI Setup Utility. Здесь непривычно мало настроек, по сравнению с серверным аналогом.
ОС на BlueField 2 можно загрузить при помощи протокола PXE, а UEFI Setup Utility позволяет настраивать порядок загрузки (Boot Order). Вы только представьте: сетевая карта загружает по PXE сначала себя, а потом сервер!

Так было обнаружено, что по умолчанию в ОС доступен docker, хотя кажется, что для сетевой карты это избыточно. Хотя если уж речь зашла про избыточность, то мы поставили JVM из пакетного менеджера и запустили на сетевой карте сервер Minecraft. Хотя никаких серьезных тестов не проводилось, на сервере вполне комфортно можно играть маленькой компанией.
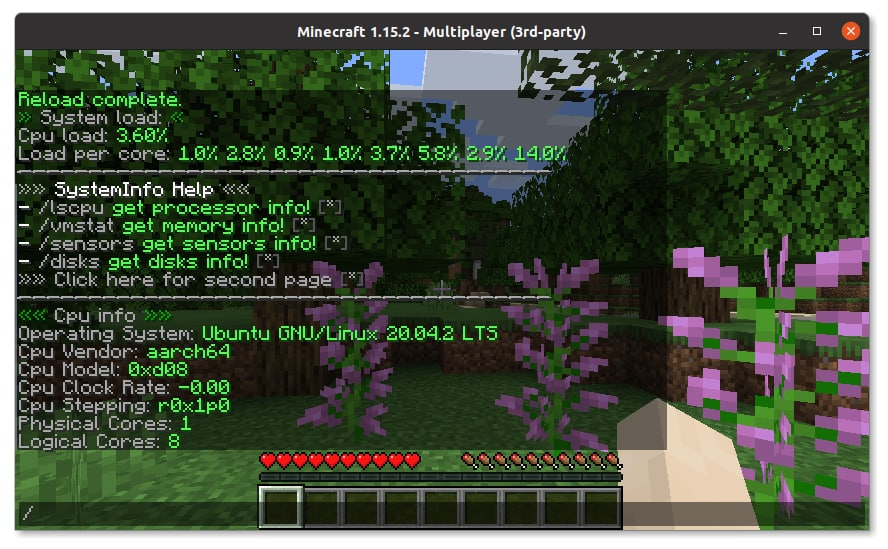
В ОС сетевой карты отображается множество сетевых интерфейсов:
ubuntu@bluefield:~$ ifconfig | grep -E '^[^ ]'
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
oob_net0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
p0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
p1: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
p0m0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
p1m0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
pf0hpf: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
pf0sf0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
pf1hpf: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
pf1sf0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
tmfifo_net0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500Интерфейсы tmfifo_net0, lo и docker0 нам уже известны. Интерфейс oob_net0 соответствует out-of-band mgmt порту RJ-45. Остальные интерфейсы связаны с оптическими портами:
- pX — представление (representor device) физического порта карты;
- pfXhpf — представление физической функции хоста (Host Physical Function), интерфейса, который доступен хосту;
- pfXvfY — представление виртуальной функции хоста (Host Virtual Function), виртуальных интерфейсов, используемых для виртуализации SR-IOV на хосте;
- pXm0 — это специальный PCIe Sub-Function интерфейс, который используется для взаимодействия карты с портом. Данный интерфейс может использоваться для доступа карты в сеть;
- pfXsf0 — представление PCIe Sub-Function интерфейса pXm0.
Проще всего понять назначение интерфейсов по диаграмме:

Интерфейсы напрямую связаны с виртуальным коммутатором (Virtual Switch), который реализован в BlueField 2. Но об этом мы поговорим в другой статье. В этой же статье мы хотим рассмотреть эмуляцию NVMe, которая позволяет подключать программно-определяемые хранилища (Software Defined Storage, SDS) к выделенным серверам как физические диски. Это позволит использовать все плюсы SDS на «голом железе».
Настройка эмуляции NVMe
По умолчанию режим эмуляции NVMe отключен. Включаем его командой mlxconfig.
mst start
# Общие настройки
mlxconfig -d 03:00.0 s INTERNAL_CPU_MODEL=1 PF_BAR2_ENABLE=0 PER_PF_NUM_SF=1
mlxconfig -d 03:00.0 s PF_SF_BAR_SIZE=8 PF_TOTAL_SF=2
mlxconfig -d 03:00.1 s PF_SF_BAR_SIZE=8 PF_TOTAL_SF=2
# Включаем эмуляцию NVMe
mlxconfig -d 03:00.0 s NVME_EMULATION_ENABLE=1 NVME_EMULATION_NUM_PF=1После включения режима NVMe Emulation нужно перезагрузить карту. Настройка эмуляции NVMe сводится к двум этапам:
- Настройка SPDK.
- Настройка snap_mlnx.
На данный момент официально заявлены только два способа доступа к удаленному хранилищу: NVMe-oF и iSCSI. Причем только NVMe-oF имеет аппаратное ускорение. Тем не менее, возможно использовать и другие протоколы. Наш интерес — подключить ceph-хранилище.
К сожалению, поддержки rbd «из коробки» нет. Поэтому для подключения к ceph-хранилищу необходимо использовать модуль ядра rbd, который создаст блочное устройство /dev/rbdX. А стек для эмуляции NVMe, в свою очередь, будет работать с блочным устройством.
В первую очередь необходимо указать, где находится хранилище, которое мы будем представлять как NVMe. Делается это через аргументы скрипта spdk_rpc.py. Для персистентности при перезагрузках карты команды записываются в /etc/mlnx_snap/spdk_rpc_init.conf.
Для подключения блочного устройства используется команда bdev_aio_create <путь до блочного устройства> <имя> <размер блока в байтах>. Параметр <имя> используется далее в настройках, и он не обязательно должен совпадать с именем блочного устройства. Например:
bdev_aio_create /dev/rbd0 rbd0 4096Для прямого подключения rbd устройства необходимо перекомпилировать SPDK и mlnx_snap с поддержкой rbd. Мы получили исполняемые файлы, скомпилированные с поддержкой rbd от технической поддержки. Для подключения мы использовали команду bdev_rbd_create <имя пула> <имя rbd> <размер блока в байтах>. Эта команда не позволяет задавать имя устройства, а придумывает его сама и выводит по завершении. В нашем случае — Ceph0. Имя устройства нужно запомнить, оно потребуется нам в дальнейшей настройке.
Хотя решение подключить rbd через модуль ядра и использовать в качестве накопителя блочное устройство вместо прямого использования rbd кажется несколько некорректным решением, оказалось, что это тот самый случай, когда «костыли» работают лучше, чем решение «по уму». В тестах производительности получилось, что «правильное» решение работает медленнее.Далее необходимо настроить представление, которое будет видеть хост. Настройка производится через snap_rpc.py, а команды сохраняются в /etc/mlnx_snap/snap_rpc_init.conf. Сперва создаем накопитель следующей командой.
subsystem_nvme_create <NVMe Qualified Name (NQN)> <Серийный номер> <модель>Далее создаем контроллер.
controller_nvme_create <NQN> <менеджер эмуляции> -c <конфигурация контроллера> --pf_id 0Менеджер эмуляции чаще всего называется mlx5_x. Если вы не используете аппаратное ускорение, то можно использовать первый попавшийся, то есть mlx5_0. После выполнения этой команды будет выведено имя контроллера. В нашем случае — NvmeEmu0pf0.
В заключение добавляем пространство имен (NVMe Namespace) к созданному контроллеру.
controller_nvme_namespace_attach <тип устройства> <идентификатор устройства> -c <имя контроллера>Тип устройства у нас всегда spdk, идентификатор устройства мы получили на этапе настройки spdk, а имя контроллера — в предыдущем шаге. В результате файл /etc/mlnx_snap/snap_rpc_init.conf у нас выглядит так:
subsystem_nvme_create nqn.2020-12.mlnx.snap SSD123456789 "Selectel ceph storage"
controller_nvme_create nqn.2020-12.mlnx.snap mlx5_0 --pf_id 0 -c /etc/mlnx_snap/mlnx_snap.json
controller_nvme_namespace_attach -c NvmeEmu0pf0 spdk Nvme0n10 1Перезапускаем сервис mlnx_snap:
sudo service mlnx_snap restartЕсли все настроено правильно, то сервис запустится. На хосте NVMe диск сам не появится. Нужно перезагрузить модуль ядра nvme.
sudo rmmod nvmesudo modprobe nvmeИ вот, на хосте появился наш виртуальный физический диск.
root@host:~# nvme list
Node SN Model Namespace Usage Format FW Rev
---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- --------
/dev/nvme0n1 SSD123456789 Selectel ceph storage 1 515.40 GB / 515.40 GB 4 KiB + 0 B 1.0
Теперь у нас есть виртуальный диск, представленный системе как физический. Проверим его на обычных для физических дисков задачах.
Тестирование
В первую очередь мы решили установить ОС на виртуальный диск. В ход пошел установщик CentOS 8. Он увидел диск без особых проблем.

Установка прошла в штатном режиме. Проверяем в UEFI Setup Utility загрузчик CentOS.
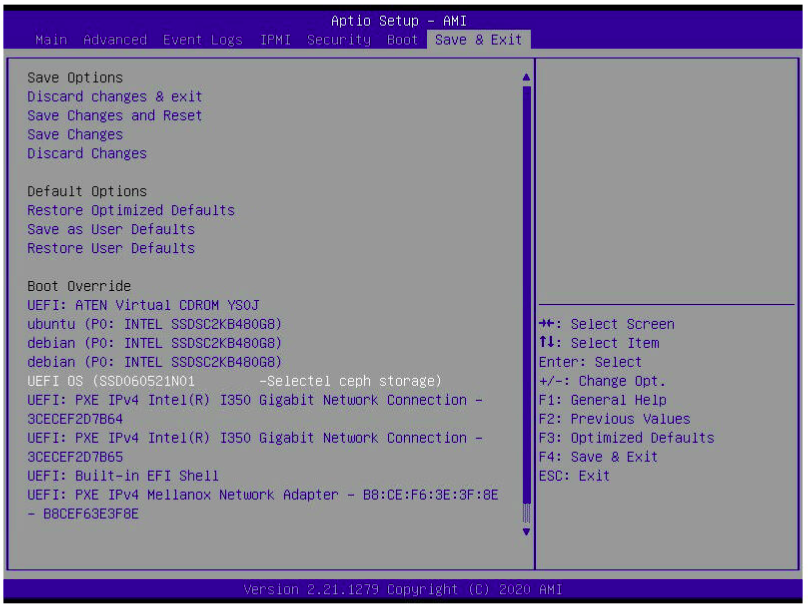
Мы загрузились в установленную CentOS и убедились, что корень ФС находится на NVMe-диске.
[root@localhost ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 447.1G 0 disk
|-sda1 8:1 0 1M 0 part
|-sda2 8:2 0 244M 0 part
|-sda3 8:3 0 977M 0 part
`-sda4 8:4 0 446G 0 part
`-vg0-root 253:3 0 446G 0 lvm
sdb 8:16 0 447.1G 0 disk
sr0 11:0 1 597M 0 rom
nvme0n1 259:0 0 480G 0 disk
|-nvme0n1p1 259:1 0 600M 0 part /boot/efi
|-nvme0n1p2 259:2 0 1G 0 part /boot
`-nvme0n1p3 259:3 0 478.4G 0 part
|-cl-root 253:0 0 50G 0 lvm /
|-cl-swap 253:1 0 4G 0 lvm [SWAP]
`-cl-home 253:2 0 424.4G 0 lvm /home[root@localhost ~]# uname -a
Linux localhost.localdomain 4.18.0-305.3.1.el8.x86_64 #1 SMP Tue Jun 1 16:14:33 UTC 2021 x86_64 x86_64 x86_64 GNU/LinuxМы также провели тестирование эмулируемого диска утилитой fio. Вот что получилось.
| Тест | AIO bdev, IOPS | Ceph RBD bdev, IOPS |
|---|---|---|
| randread, 4k, 1 | 1 329 | 849 |
| randwrite, 4k, 1 | 349 | 326 |
| randread, 4k, 32 | 15 100 | 15 000 |
| randwrite, 4k, 32 | 9 445 | 9 712 |
Заключение
«Умные» сетевые карты — это настоящая техническая магия, которая позволяет не только разгружать центральный процессор от операций ввода-вывода, но и «обманывать» его, представляя удаленный накопитель локальным.
Такой подход позволяет использовать преимущества программно-определяемых хранилищ на выделенных серверах: по «щелчку пальцев» переносить диски между серверами, менять размер, делать снапшоты и разворачивать готовые образы операционных систем за секунды.

Комментарии (50)


Mike-M
25.06.2021 14:16Дополнительно видны разъемы Mini-USB,
Странно, почему не micro-USB?
aspq
25.06.2021 18:00Разъемы и кабели надежнее :)
Mike-M
25.06.2021 19:48+1Никак нет:
«The Micro plug design is rated for at least 10,000 connect-disconnect cycles, which is more than the Mini plug design».BratPilot
29.06.2021 12:27дело не в колличесте циклов коннект-дисконнект. дело в том, что найти трухольный коннектор микро или тайп-С оказалось не такой уж простой задачей. обратите внимание, что коннектор расположен на правой стороне карты - т.е. механически он ничем не защищен. это черевато вырыванием коннектора с кишками. так же стоит упомянуть, что этот интерфейс сугубо для апгрейта софта. т.е. для обычной работы платы он не должен быть подключенным.
ЗЫ: я думал за аудиоджек тапки полетят - а его по ходу никто не заметил. :)

yleo
27.06.2021 16:09А что если вынести журналы вашего "тестового и не самого быстрого кластера ceph" на NVRAM NVMe или PMEM/NVDIMMы ?
inetstar
Хорошая технология, чтобы обманывать покупателей услуг виртуальных серверов, обещая им локальные nvme.
aspq
Сейчас эта технология позволяет получить производительность в ~4.7M IOPS @ 4K (randread) и средним latency в ~15 мкс на эмулируемом NVMe диске, подключенном к remote Storage таргету по NVMe over Fabrics (это на 100GbE картах).
Так что, при желании, провайдер может дать покупателю облачного сервера производительность в несколько раз выше локального NVMe диска :)
Nizametdinov
Так то да, но и атомная энергия по-идее это свет в домах и тепло. А по жизни — разные применения получились, и в основном как побольше людишек выпилить.
Получается теперь наличие локального nvme не показатель, надо Iops мерять периодически.
Статья огонь, где еще о таких волшебных железках узнаешь.
mbobka
Атомная энергия как раз в основном свет и тепло, остальное побочные эффекты.
creker
Оно никогда не было показателем. Единственный показатель это заявленные иопсы. Как подключен диск к машине совершенно этому ортогонально. Вы может удивитесь, но скоро и видеокарты не будут подключены к машине локально.
inetstar
В статье люди намеряли 15 000 иопс на чтение и 10 000 на запись. Как-то жалковато.
aspq
Производительность в основном зависит от того, какая СХД используется в качестве бэкенда для эмуляции. В статье говорится о Ceph, который применяется не для производительности, а скорее для минимизации стоимости решения и достижения максимальной емкости хранения.
Если нужна производительность — используете СХД с NVMe дисками и поддержкой NVMe over Fabrics.
inetstar
Вообще-то статья подтверджает мой изначальный тезис. В блоге облачного провайдера рассказываетя о том, как они подключили медленный дисковый кластер по сети в качестве локального nvme. Наверное ради этого всё и задумывалось. Если нужна быстрая сеть, то зачем тогда нужна эта карта? Быстрые сетевые диски итак можно подключать безо всякой маскировки, которая в данном случае ещё и денег стоит.
creker
Ничего она не подтверждает. Если клиенту заявлено 15к иопсов, то он их получит и никого не волнует, локальный это диск или сетевой. Вся идея nvme over fabrics в том, что разницы на практике нет. Задержки теже, а скорости можно получить во многие разы выше.
Эта карта именно для быстрой сети и нужна, т.к. современные процессоры не способны прокачать сотни гигабит. Поэтому индустрия пошла по пути SmartNIC/DPU — в сеть торчит эта железка, а за ней находятся pcie диски. Почитайте про Fungible DPU. BlueField2 конечно довольно убог в этом плане, ибо очень медленный, но другие представители этого класса устройств с этим справляются на ура. Собственно, эту тему по-моему начал амазон со своими nitro.
inetstar
Тут есть противоречие. Если процессоры не способны, то зачем такую карту втыкать в сервер, где процессор не способен прокачать её скорость?
200Гбит — это всего лишь 20 GiB. Рейд из нескольких nvme.
Но на практике карта имеет всего 8 линий PCI-e, поэтому она никогда не сможет прокачать 200Гбит.
creker
А смысл в том, что процессора в шасси никакого и не будет, а если и будет, то он будет не задействован в этих задачах. Я поэтому упомянул funible DPU. Там ничего кроме дисков и DPU нет.
bluefield с двумя 100гбит портами имеет 16 линий 4.0, а это даже больше 200гбит.
inetstar
Эта карта как раз обеспечивает доступ процессора к nvme хранилищу. В этом и суть статьи, что карта нужна для организации доступа виртуалок к «локальному» nvme.
creker
Чего? При чем тут обеспечение чего-то? У вас вопрос был «Если процессоры не способны, то зачем такую карту втыкать в сервер, где процессор не способен прокачать её скорость?» Ответ на него простой — там, где эта карта будет стоять, процессора и не будет. Это один из юзкейсов DPU — JBOF шасси, в которых нет ничего, кроме SSD и DPU. Второй юзкейс — да, втыкать эту карту в сервер, чтобы эмулировать nvme pcie устройство, хотя сами диски находятся где-то далеко. Полезно для того, чтобы сервер мог загружаться с таких «дисков». В вычислителях не нужно будет даже загрузочные диски ставить.
BratPilot
Маленькое уточнение - эта карта - SMART NIC а не CONTROLLER. по железу это почти одно и тоже , разница лишь в тонкостях настройки PCIe шины. SMART NIC он "End Point" на шине, а CONTROLLER он "root complex". конкретно эта модель ввиде контроллера никогда не выпускалась так как является младшей в линейке. в линейке так же есть х16 борды с 100GbE /EDR портами и повышенной частотой ядер. на их базе и создавались контроллеры которые используются в JBOF.
кстати , в JBOF есть еще один немаловажный компонент - PCIe свич. ибо прямое подключение SSD к DPU не еффективно. все же SSD остается "узким местом" для пропускной способности (подразумевается что PCIe работает в gen4 режиме). а вот подключение к скажем 32ум дисками через свичи выглядит уже куда более интересным.
creker
Гугл говорит, что root complex она может, но тут может действительно не уточнили просто вариант карты конкретный. Да и в даташитах это мелькало forums.developer.nvidia.com/t/obtaining-and-building-linux-kernel-source-for-doca-1-0/175916/4
Да даже если не может, я все же больше о DPU в общем там вел речь. Сабж так то обрезок во многих планах — проц совсем медленный у нее по сравнению с конкурентами. Надо 3 версию ждать видимо.
Ну хз. Если у нас дофига дисков и свитч, это значит на полную все диски работать не смогут. В каких-то платформах это наверное не критично. Я вот смотрю fungible платформу — там свитча не видно, DPU напрямую к бэкплейну похоже подключены.
Понятное дело, что если мы строим JBOF, где важен объем для тех же QLC дисков, то там да. Можно свитчами обложиться и петабайты ворочить. Скорость тут второстепенна. Но если цель все таки получить сверх быстрое СХД, то как по мне должно быть прямое подключение.
BratPilot
сабж был залочен для Смарт Ников. тот же Fungible даже S1 будет не просто впихнуть даже в FHHL форм фактор (у них вобще есть PCIE девайсы? а то я на сайте не заметил.)
как их сравнивать по скорости? у них архитектура ядер разная. я не знаю например как сравнить 52 ядра 1.6Гц МИПС с 8 ядрами на 2.5Гц АРМ. подскажите?
каких конкурентов вы имеете ввиду?
если сравнивать сабж с fungible F1 по PCIe конечно последний жирнее и имеет собственные 64 линии (ген 3 правда). и конечно же ему не надо никаких свичей он сам себе свич. с другой стороны такой чип больше никуда не пойдет кроме тех самых систем о которых вы упомянали. т.е. гибкость в применении весьма скромная. BlueFiled-1 имел 32 линии. BlueField-3 ..... скоро узнаем :)
creker
Еле откопал в их куче рекламы, таки есть pages.fungible.com/rs/038-PGB-059/images/PB0051.00.12020330-Fungible-Data-Centers.pdf
Я чисто сужу по отзывам, что блюфилд совсем медленный. Собственно и подход у них какой-то не такой. Все остальные обмазывают свои DPU аппаратными ускорителями, внедряют ОС собственные, SPDK оптимизируют под них и прочее, а про блюфилд ничего толком. Ну и подход к железу разный, да. Что fungible, что какой-нить kalray — там прям видно, что это специализированный ускоритель под задачу, а не прилепленный ARM SoC к сетевухе.
Хотя бы fungible и kalray. По крайней мере по описанию и позиционированию, у них решения так сказать next-gen. Про остальных просто ничего не знаю, так то решений дофига, рынок быстро заполняется.
BratPilot
странный отзыв. ибо скорость таких девайсов сильно зависит от того, чем их загружать. сравнивали на одних и тех же аппликациях с теми же Песандро. DPU не единственная функция которую они могут выполнять. и кстати голый диск контроллер / диск виртуализатор очень скромен по ресурсным запросам. заускали DPDK на полную пропускную способность.
ну так и тут аккселераторами полна ж... простите горница людей. :) но с ними другая проблема. они место на силиконе хотят и электричество жрут в не зависимости от использования. а собственные ОС - клиенты такого не любят. проходили...
creker
Есть просто вот такая штука arxiv.org/pdf/2105.06619.pdf и результаты тут совсем не впечатляют. В раздельном режиме он не тянет, только в embedded режиме, что как-то не очень для устройства, которое как раз таки должно быть точкой подключения, а не только снифером пакетов.
Да, но когда речь о миллионах IOPS, я чето начинают сомневаться в блюфилде. Особенно смотря на то, что творят его конкуренты.
Ну это видимо до поры до времени, пока запросы маленькие. Все таки внедряют их явно не от хорошей жизни, а чтобы достичь нужных скоростей. Контрол плейн пожалуйста на линуксе, а датаплейн работает на том, что лучше подходит для задач. Думаю гиперскейлеры переживут, раз уж им не лень с FPGA даже возиться. А остальным, по большому счету, все эти DPU не особо и нужны.
creker
Ceph спокойно может миллионы иопсов наравне с коммерческими СХД за тонны денег. Тут данная статья совсем не показатель.
inetstar
Кстати, в даташите по этой карте нигде не указано про 4.7М иопсов. Откуда цифры?
Более того, она не может выдать (та карта с картинки) такие цифры даже в теории, поскольку имеет всего 8 линий pci-e. По моим расчётам именно эта карта может выдать не более миллиона иопс с учётом многочисленных накладных расходов.
creker
В даташите никаких опсов указывать и нет смысла, это не накопитель, а DPU. Сколько он чего выдаст целиком и полностью зависит от того, какое приложение на него будет установлено. А цифры думаю взяты из готовой системы. Не знаю какой, но гугл с подобными цифрами выдает решение western digital, которое точно также полагается на DPU со 100гбит интерфейсами.
inetstar
Конечно, имеет. Потребитель должен знать насколько узким местом является эта карта. Если на практике она пропускает всего 1 миллион иопс, то ваша дутая цифра в 4.7М (которая относится к маркетинговым материалам WD, а не к этой NVidia-карте) — это маркетинговый bullshit.
creker
Вы совсем читать не умеете? Может давайте intel будет у процессоров своих iops указывать? Чушь не порите.
Ну точно читать не умеете. Во-первых. Где я сказал, что это решение на bluefield? Там стоит другой DPU. Во-вторых, ваши расчеты не стоят выеденного яйца, т.к. ни на чем не основаны.
inetstar
Эта статья посвящена конкретной карте NVIDIA bluefield 2. Поэтому не нужно вводить читателей в заблуждение, подсовывая им цифры из маркетинговых материалов WD.
Читай, изучай.
Из 100Гбит выжимают только 13-36Гбит, да и то при использовании размера кадра от 256КБ до 1МБ. Такой размер кадра уменьшает иопсы случайного доступа 4К в 32-256 раз. Поэтому реальные случайные иопсы, которые даст 1 такая карта будут в 100-200 раз ниже, чем даст локальный накопитель.
Как и получилось у авторов статьи. Хотя они подключили целый КЛАСТЕР, а не какой-то там жалкий 1 накопитель.
creker
Это нужно говорить человеку выше, который цифры дал, не мне. Он точно так же говорил о nvme-of решениях, а не конкретно bluefield.
Ага, а 400гбит свитчи и сетевухи делают, потому что делать нечего. В вашей же статье все 100гбит они спокойно достигли твиком пары параметров, которые и так все знают. И все эти ваши разы опять не стоят ничего. Когда на практике все эти иопсы будут посланы в параллель с большой глубиной очередей, все эти скорости будут легко достигнуты.
inetstar
Вот когда на практике это будет сделано, тогда и поговорим. А сейчас ты просто работаешь по маркетинговым материалам как попугай.
Нужно дождаться результатов сторонних тестирований.
И, о чудо!!! Мы имеем всего 15К иопс с целого кластера. Читай статью.
А мой 1 локальный NVMe — 750К.
creker
Можете погуглить, примеров достаточно вплоть до десятков миллионов иопс. Не хотите — ваше дело верить, что это все маркетинг. Вы, будучи продаваном, лучше бы за трендами следили. А то так индустрия без вас на nvme-of перейдет, а вы все будете твердить, что оно не работает.
inetstar
Для nvme-of точно также нужны nvme, которыми я и торгую.
Что-то не нагуглил ни одного примера NVMe-OF с десятками миллионов иопс не связанного с производителями хранилищ NVMe.
Вообще, единственное что есть, это маркетинговый материал WD c 4М.
site6893
не в ту сторону смотрите. єта технология по сути значительно расширяет провайдеру возможности для оверселлинга клиентам ресурсов которых у провайдера даже близко нет. За счет тех клиентов кторые платят за резервирование мощностей, но по факту их никогда не используют на полную.
creker
nvme это просто протокол, который вообще ничего не означает и ни привязан ни каким дискам. Сейчас по nvme будут подключать hdd. Соответствующая поддержка внесена в nvme спецификацию, а производители дисков думают, как это реализовать в контроллерах их дисков.
Технология эта нужна, чтобы осовременить стек и существенно увеличить скорость СХД. nvme это общий протокол доступа к блочным хранилищам. Как iscsi, один в один, который уходит на свалку истории. Сейчас nvme диски, которые pcie интерфейс имеют, очень сильно ограничены в скорости т.к. завязаны на медленные и малочисленные линии pcie. С nvme over fabrics с помощью вот таких DPU и SmartNic как в статье, диски будут подключены к какой-нить ethernet фабрике, где скорости куда выше нынче, чем в pcie.
Что до обмана, никто никого обманывать не будет. Пользователя вообще не волнует, как ему диски подключены. Провайдер дает ему главное — сколько иопсов он получит. Подключен диск локально или по фабрике значения тут не имеет. Благодаря фабрике как раз таки провайдер имеет куда больше возможностей предоставить много иопсов всем и сразу.
inetstar
Не сейчас, а в возможном будущем. В реальности таких HDD СЕЙЧАС не существует.
Эта карта имеет всего 8 линий PCI-e, поэтому она не сможет даже в теории обеспечить линейную скорость большую, чем всего 1 хороший локальный NVMe c 8ю линиями.
А несколько локальных NVME в рейде точно её превзойдут. По линейным скоростям уж точно. Какое бы крутое не было удалённое хранилище.
creker
И какой смысл в этой придирке? У меня вообще слово «будут» написано. Их появление уже гарантировано. Сроки тоже есть примерные — сегейт собирался сэмплы к концу следующего года дать.
Основные формфакторы в датацентрах сейчас это U.2 и m.2, а это не более 4 линий. Поэтому версия этой карты на 16 линий спокойно потянет 4 таких накопителя. Если поставить несколько карт, то еще больше.
Весь смысл DPU в том, что он сможет всю это пропускную способность выдать по фабрике. Нет никакого смысла в этих ваших локальных дисках в рейде, если их нет в машине, где крутится код клиента. Смысл, чтобы взять эти диски из соседней стойки и не потерять в скорости. Для этого nvme over fabric и эти DPU и делают.
И как раз локальные nvme в рейде никого не превзойдут. nvme over fabric решение не имеет пределов по масштабированию — этих коробочек с дисками и DPU можно хоть тысячу наставить и подключить как одно nvme хранилище в виртуалку. Локальные диски будут оставлены далеко позади очень быстро.
inetstar
Пока вещь не появилась, то ничего не гарантированно.
m.2 — это основной формат в настольных компьютерах и ноутбуках. А в датацентрах российских основной формат — hh-hl, западных — u.2.
Не потянет на полной скорости, так как есть ещё сетевые издержки и сетевые задержки. Сеть всегда медленнее локального доступа по PCI-E.
creker
Интерес гиперскейлеров это гарантирует. Люди отказываются от sata и sas.
Опять чушь порите. Почитайте распределение формфакторов ssd в энтерпрайзе www.ngdsystems.com/page/Flash-storage-grows-up-with-new-EDSFF-SSDs-denser-3D-NAND Подавляющее большинство это сата, u.2 и m.2. hh-hl там на уровне погрешности, это мертвый продукт в свете перехода на новые формфакторы заместо u.2. Уж про m.2 так вообще смешно такие вещи читать. Вы похоже вообще с рынком не знакомы. Это один из основных форматов у гиперскейлеров.
Сеть уже быстрее локальных pcie — нынче 400гбит порты внедряются. Только с приходом pcie 5.0 можно будет делать сетевухи хотя бы с одним таким портом — больше 16 линий не может. Отчасти поэтому nvme-of и внедряется. Так что пропускную способность сеть обеспечит полную, это не проблема вообще. Латентность — да, чуть больше будет, но тоже не особо проблема. Вы же знаете про RDMA, правда?
inetstar
NVMe протокол на hdd никак их не ускорит. Не верь маркетологам.
HDD даже SATA III полностью утилизировать не могут.
А с рынком NVMe я точно знаком лучше тебя. Так как торгую ими. Об этом есть инфа в профиле.
Там вообще график трендов, а не реального использования по данным какого-то журнала. Даже без ссылки на сам журнал.
А я говорю не о трендах, а о реальности.
m.2 сильно проигрывает u.2, так как с ним нельзя делать горячую замену, рейды с hot-swap. Он маленький. Там не разместишь много памяти, мощный процессор и суперконденсаторы.
creker
Я знаю, что торгуете, я поэтому и намекаю — вам бы лучше в рынке разбираться стоило бы. Подобные заявления про m.2 позволено делать разве что обывателям, которые про серверное железо никогда ничего не слышали.
Я тоже говорю о реальности. Помимо этого графика можно было пойти и ознакомиться, что ставят гиперскейлеры в свои серверы. Если вам конечно интересно разобраться в теме чуть по-лучше. Ежели нет, можете продолжать дальше верить, что m.2 это настолки и ноутбуки
inetstar
Вера тут нипричём. У меня было всего парочка клиентов из дешевых хостеров, которые брали m.2 для серверов с целью экономии.
А все остальные предпочитали hh-hl. И только после этого только U.2.
Но доля u.2 медленно повышается, так как на новых шасси они стали появляться.
creker
А кто сказал что-то об ускорении? Ускорение таки есть небольшое, но это не важно. Единственная причина перевода hdd на nvme это унификация стэка протоколов и интерфейсов. И толкают эту идею никакие не маркетологи, а инженеры, которые сейчас спеки пишут и контроллеры разрабатывают.
Невероятно, а я и не знал. Представляете, именно поэтому гиперскейлеры придумали новый формфактор, чтобы заменить все свои m.2 и решить перечисленные проблемы. А заодно еще u.2 получится на пенсию отправить, с ним тоже свои проблемы.
inetstar
А какие проблемы с u.2? Я вижу только одну — предлагает всего 4 линии, но новомодные форматы тоже не более 4х предлагают.
edo1h
проблема. низкие задержки — это причина, по которой ssd вытеснили hdd. и это единственный фактор, который продаёт оптаны.
и RDMA никак не может сделать задержку обращения к сетевому накопителю меньше, чем к локальному
creker
Не только поэтому. Они вытеснили, потому что они могут много iops, а их много они могут, потому что очереди глубокие делаются, что скрывает задержки. Когда идет речь о nvme-of мы имеем теже самые глубокие очереди, что даст нам то же количество iops, но с чуть больше задержкой. Это замедлит интерактивные операции, вроде ожидания отклика на действие юзера, но в глобально масштабе параллельность запросов эти латентности скрывает. ssd накопители это не область, которая критична к задержкам. Поэтому индустрия и смотрит на nvme-of спокойно. Иначе бы за эту затею даже не брались. На iSCSI живут же как-то, а тут будет еще лучше. В конце концов, кэширование на хостах никто не отменял, что задержки потенциально вообще устранит.
Оптейн это понятно дело. Его этот фактор только продает, потому что он стоит как самолет. У него единственные юзкейсы и получаются, либо персистентная память, либо кэш записи быстрый. Собственно, оптейн по фабрике подключать вроде и не собирался никто, потому что его юзкейсы как раз чувствительны к задержкам.
А RDMA поможет эту задержку сократить относительно наивной реализации по сокетам. Локальной конечно не достигнет, физику никто не отменял.