
Особенности: преимущества и недостатки
Модуль WebFlux появился в 5й версии фреймворка Spring. Этот микрофреймворк является альтернативой Spring MVC и отражает собой реактивный подход для написания веб-сервисов. В основе WebFlux лежит библиотека Project Reactor, позволяющая легко запрограммировать неблокирующие (асинхронные) потоки (streams), работающие с вводом/выводом данных.
Следует учесть, что WebFlux для работы требуется встроенный в Spring сервер Netty. Встроенные Tomcat и Jetty не подходят. Следующая диаграмма иллюстрирует особенности окружения, в котором работает WebFlux [1].

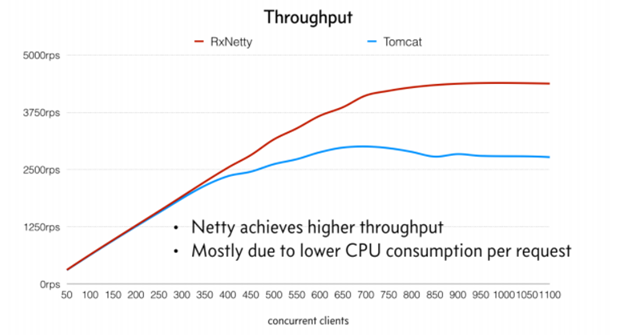
График внизу демонстрирует преимущество в производительности реактивных веб-сервисов [2] по сравнению с обычными, блокирующими. При загруженности сервера в 300 и более пользователей Netty начинает превосходить Tomcat по количеству одновременно обрабатываемых запросов. При предельной загруженности сервера в реактивном режиме может одновременно обслуживаться в 2 раза больше пользователей. По другим источникам преимущество не так внушительно, но заметно. Наибольший эффект реактивное программирование дает при вертикальном масштабировании.
Важная особенность реактивности еще в том, что она дает слабую связность. Например, если между клиентом и сервисом происходит разрыв соединения, оно воссоздается при восстановлении Интернет. Ограничения во времени не требуется, так-как соединение происходит для отдельного потока, не влияющего на другие. Но при этом реактивный подход должен быть реализован на обеих сторонах.
Программировать приложение с множеством неблокирующих потоков достаточно непривычная задача. Требуется особый подход и стиль программирования, основанный на лямбда-выражениях с использованием реактивных библиотек. Библиотека Project Reactor, входящая в WebFlux, отличается от реактивной библиотеки RxJava (реализованной, например, в Android) тем, что больше подходит для бэкэнда. Например, устранены некоторые проблемы, которые могут вызвать нехватку памяти.
К неудобствам реактивного программирования следует отнести более ограниченный инструментарий для работы с реляционными БД. Например, JPA-библиотеки Hibernate и EclipseLink не поддерживают реактивность. Невозможно в Java описывать сложные связи между объектами, как это делается обычно тегами @Entity, @OneToMany, @ManyToMany, @JoinTable и т.д.. Не получится программно описать ограничение целостности таблиц. Хотя это придает большую гибкость используемой БД. Для привязки классов к таблицам достаточно тегов @Table и @Column. Языки JPQL (HQL) не годятся для реактивных запросов к БД. Но при этом доступен нативный SQL. Вместо JDBC потребуется R2DBC. Об этом чуть позже.
Простейший пример реактивного REST-сервиса и REST-клиента
Для разработки реактивного сервиса достаточно в pom.xml добавить модуль spring-boot-starter-webflux, вместо обычного spring-boot-starter-web в Spring MVC.
<dependency> |
Кодирование REST сервисов и их клиентов в Spring WebFlux может полностью совпадать со Spring MVC. Отличие только в определении возвратов. На выходе методов в WebFlux мы добавляем Mono (или в особых случаях Flux, когда требуется последовательно в одном потоке передать несколько объектов). Например, метод sendSms контроллера SmsController
@RestController
@Api(tags = "Отправка СМС через Девино-Телеком")
public class SmsController extends Controller {
private static final Logger logger = LoggerFactory.getLogger(SmsController.class);
private final SmsService smsService;
public SmsController(SmsService smsService) {
this.smsService = smsService;
}
@GetMapping(value = "/sms/{to}/{text}")
@ApiOperation(value = "Тестирование отправки СМС")
@ApiResponse(code = 200, message = "Результат передачи СМС")
Mono<ResponseEntity<ResultDto>> sendSms(
@ApiParam(value = "Номер телефона", required = true) @PathVariable(name = "to") String to,
@ApiParam(value = "Текст сообщения", required = true) @PathVariable(name = "text") String text
) {
return smsService.sendSms(to, text);
}
}обращается к методу sendSms сервиса SmsService:
import org.springframework.web.reactive.function.client.WebClient;
import reactor.core.publisher.Mono;
@Service
public class SmsService {
private static final Logger logger = LoggerFactory.getLogger(SmsService.class);
private static final String PHONE_PREFIX = "7";
private final WebClient smsClient;
@Value("${sms.callingSystem}")
private String callingSystem;
@Value("${server.site}")
private String site;
@Value("${sms.callbackUrl}")
private String callbackUrl;
public SmsService(WebClient smsClient) {
this.smsClient = smsClient;
}
public Mono<ResponseEntity<ResultDto>> sendSms(String to, String text) {
MessageDto message = new MessageDto(callingSystem, PHONE_PREFIX + to, text);
message.setCallbackUrl(site + callbackUrl);
MessagesDto messages = new MessagesDto(message);
return smsClient.post()
.bodyValue(messages)
.exchange()
.flatMap(res -> res.bodyToMono(ResultsDto.class)
.map(rs -> {
List<ResultDto> results = rs.getResults();
return ResponseEntity.ok().body(results.get(0));
})
);
}
Цепочка методов smsClient.post().bodyValue() может заканчиваться методом retrieve().bodyToMono(), если не требуется дальнейшая обработка и преобразование объектов передаваемых клиентом. Иначе, как в примере, требуется exchange().flatMap(<лямбда-выражение>).
@Configuration
public class SmsConfig {
private static final Logger logger = LoggerFactory.getLogger(SmsConfig.class);
private static final String CONTENT_TYPE_HEADER = "Content-Type";
private static final String AUTH_HEADER = "Authorization";
@Value("${sms.url}")
private String url;
@Value("${sms.token}")
private String token;
@Bean
public WebClient smsClient() {
HttpClient httpClient = HttpClient
.create()
.tcpConfiguration(
tc -> tc.bootstrap(
b -> BootstrapHandlers.updateLogSupport(b, new CustomLogger(HttpClient.class))));
WebClient webClient = WebClient.builder()
.baseUrl(url)
.defaultHeader(CONTENT_TYPE_HEADER, MediaType.APPLICATION_JSON.toString())
.defaultHeader(AUTH_HEADER, token)
.clientConnector(new ReactorClientHttpConnector(httpClient))
.filters(exchangeFilterFunctions -> {
exchangeFilterFunctions.add(logRequest());
exchangeFilterFunctions.add(logResponse());
})
.build();
return webClient;
}
private ExchangeFilterFunction logRequest() {
return ExchangeFilterFunction.ofRequestProcessor(clientRequest -> {
logger.info("Sms REST CLIENT REQUEST: **********");
return Mono.just(clientRequest);
});
}
private ExchangeFilterFunction logResponse() {
return ExchangeFilterFunction.ofResponseProcessor(clientResponse -> {
logger.info("********** Sms REST CLIENT RESPONSE");
return Mono.just(clientResponse);
});
}
}Реактивный клиент в Spring определяется только через WebClient. Шаблон RestTemplate (из Spring MVC) не подходит. Подробнее о реактивных REST-сервисах здесь [3].
Работа с реактивными реляционными БД: Особенности
Для подключения реактивных реляционных библиотек через Maven в pom.xml потребуется добавить две зависимости. Пример для PostgreSQL.
<dependency> |
Приятным сюрпризом при переходе с JPA на R2DBC будет уменьшение размера, собираемого джарника приложения, на пару десятков мегабайт. Зависимость spring-boot-starter-data-jpa тянет множество библиотек, требуемых для поддержки JPA.
Вот как выглядит описание реактивного CRUD-репозитария
import org.springframework.data.r2dbc.repository.Query;
import org.springframework.data.repository.reactive.ReactiveCrudRepository;
import org.springframework.stereotype.Repository;
import reactor.core.publisher.Mono;
import ru.sksbank.privilege.demo.model.dc.Client;
@Repository
public interface ClientRepository extends ReactiveCrudRepository<Client, Long> {
@Query("SELECT * FROM client WHERE phone_number = :phone AND passive = 0")
Mono<Client> findByPhoneActive(String phone);
}
В примере объекты, возвращаемые запросами к БД, определяются классом Client приблизительно такого вида:
@Table("client")
public class Client {
@Id @Column("id") private Long id;
@Column("user_id") private Long userId;
@Column("person_id") private Long personId;
@Column("phone_number") private String phone;
}Поля имеют примитивные типы. Мы не описываем вложенные объекты User или PersonData. К этим объектам потребуется обращаться отдельными запросами зная userId или personId. Для ускорения, конечно лучше использовать один объединенный SELECT с JOIN из нативного SQL. Для JPA в подобных случаях (когда объекты не требуются) используют lazy loading.
Последняя особенность, это конфигурация источника данных. Простейший пример с указанием спецификации R2DBC (вместо JDBC) в файле application.yml.
spring: |
Ссылки
1 Reactive Programming: Reactor и Spring WebFlux
2 Реактивное программирование на Java: как, зачем и стоит ли?


maxzh83
Смелое заявление.
И это проблема, о которой тактично умалчивают в книгах и статьях про reactor. Типа вот есть r2dbc, в нем все можно, дерзайте. Но при этом на нем банальный join сделать — то еще приключение, особенно если хочется с удобством JPA, а не JdbcTemplate. А ведь в реальных проектах отношений может быть огромное количество.
smansh Автор
На счет преимуществ нативного SQL над JPQL в плане быстродействия. Думаю, если провести голосование, то большинство отдаст голос в пользу SQL. Поэтому не такой уж я и смелый в своем мнении.) На более низком уровне, SQL позволяет оптимизировать запросы в том числе и сложные с JOIN. Но интересно, конечно почитать специальные исследования об этом (о производительности). Пока нашел только quares.ru/?id=164860 где автор не поленился проверить эквивалентные запросы. У него JPA в полтора раза замедлил запрос. Конечно, это не исследование, но…
maxzh83
Что-то все в кучу смешалось. Первое — про утверждение, что пачка запросов вместо одного не скажется на производительности. А именно отдельно подтягивать данные вместо join (по userId или personId). Так вот, скажется. Это почти всегда будет медленнее, чем прогнать один запрос. И тут не должно быть сравнения с JPA, тут речь не про это, на чистом SQL будет медленнее.
Второе — про JPA. Конечно же, с JPA запросы зачастую будут менее оптимальные, чем написанные грамотным DBA. Но! Во многих категориях приложений это не критично. Гораздо важнее скорость разработки, удобство использования и поддержки. Особо критичные места всегда можно подтюнить или на крайний случай написать нативный запрос руками. И вот этого удобного механизма в реактивщине еще нет. И как мне кажется, этого очень не хватает, чтобы reactor начали использовать по настоящему массово.
smansh Автор
На счет пачки запросов, или отдельных запросов для каждого объекта — согласен, не самый лучший вариант в плане быстродействия. Подправил