
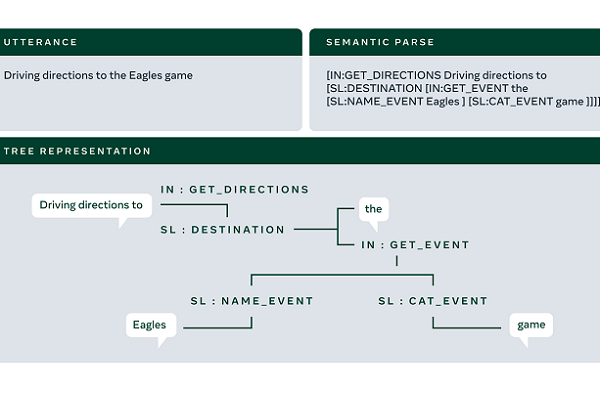
Крупные корпорации нет-нет, да и делают что-то бесплатно. На днях социальная сеть Facebook поделилась двумя крупными датасетами Conversational AI. Сделано это для того, чтобы стимулировать исследования и разработку в сфере ИИ-технологий, постепенно улучшая качество цифровых ассистентов, включая их взаимодействие с человеком.
Один из представленных датасетов предназначен для тренировки ИИ на основе небольшого объема raw-данных. Второй — для упрощения разработки мультиязычных голосовых помощников.
Data Share
Первый датасет создан для упрощения работы с уже размеченными данными для обучения. Традиционно разговорный ИИ требует использования огромных объемов информации для тренировки механизма понимания речи. Лишь после продолжительного обучения такой ИИ может нормально понимать пользователей и взаимодействовать с ними.
Набор данных включает восемь доменов и около 180 000 уже размеченных образцов. По словам разработчиков, Facebook удалось в 10 раз повысить эффективность использования данных для обучения цифровых агентов. К каждому новому интенту (intent) и ответу можно добавить 25 образцов записи.
В Facebook считают, что Conversational AI может активно развиваться лишь в том случае, если для обучения ИИ не нужно будет прикладывать огромные усилия и использовать большое количество ресурсов. Для того, чтобы этому поспособствовать, компания создала набор данных и открыла его для всех. В набор входит шесть языков, с ним сейчас работает около 100 000 специалистов.
«Разговорный искусственный интеллект и цифровые помощники быстро развиваются, что открывает новые горизонты их использования, но эти улучшения часто внедряются людьми, которые говорят на широко распространенных языках, таких как английский. Получается, что менее популярные языки остаются за бортом технологий. Более того, часто очень сложно масштабировать существующую модель для поддержки новых вариантов использования», — пояснили исследователи Facebook в своем блоге. «Масштабируя модели NLU для поддержки разнообразных вариантов использования на большем количестве языков, особенно тех, для которых отсутствуют обширные коллекции маркированных данных обучения, мы можем расширить возможности Conversational AI, открыв эту технологию большему количеству людей».
Обучение ИИ
Разработка и выпуск датасетов — часть крупного проекта, а именно — conversational AI Facebook и обмена результатами и методами, разработанными в рамках проекта. Еще в феврале Facebook поделился массивной базой данных по распознаванию речи и обучающим инструментом под названием Multilingual LibriSpeech (MLS) в виде набора данных с открытым исходным кодом с более чем 50 000 часов аудио на восьми языках из общедоступных аудиокниг с предварительно обученными языковыми моделями и другими данными. В октябре прошлого года Facebook опубликовал модель перевода M2M-100, которая может переключаться между любыми двумя из 100 языков. Примечательно, что она был построена без использования английского языка. Интересный момент — на основе более чем 16 000 часов голосовых записей ИИ оказался способен понимать 51 язык.
«Наборы открытых данных и бенчмарки были ключевыми драйверами последних разработок в области ИИ. MLS предоставляет ценный ресурс для исследований в области крупномасштабного обучения систем ASR», — пояснили исследователи проекта в своем блоге. «Несмотря на то, что существуют наборы данных и эталонные тесты для языков, отличных от английского, они часто относительно невелики либо фрагментированы, разбросаны по разным местам и редко доступны по открытой лицензии. Мы считаем, что, предоставляя большой многоязычный набор данных с неограниченной лицензией, MLS будет способствовать открытому и совместному исследованию многоязычного ASR, позволяя улучшать системы распознавания речи на большем количестве языков со всего мира».