
Мы уже писали про Vectorization Advisor и примеры его применения на простых сэмплах. Сегодня поделимся информацией том, как инженеры Intel совместно с исследователями из STFC Daresbury Laboratory в Великобритании оптимизировали пакет DL_MESO.

DL_MESO – научный пакет для симуляции конденсированных сред на мезоскопическом уровне (да простят меня химики и физики, если не совсем корректно перевёл). Пакет разработан в лаборатории Дарсбери и широко применяется как в исследовательском сообществе, так и в индустрии (компаниями Unilever, Syngenta, Infineum). С помощью этого ПО ищутся оптимальные формулы для шампуней, удобрений и топливных присадок. Этот процесс называют “Computer Aided Formulation” (CAF) – я перевёл как «САПР в области разработки химических формул».
Симуляция CAF – очень ресурсоёмкие вычисления, поэтому разработчики были сразу заинтересованы в максимально производительном дизайне. И DL_MESO был выбран одним из совместных проектов в “Intel Parallel Computing Center” (IPCC) между Intel и Hartree.
Разработчики DL_MESO хотели воспользоваться аппаратными возможностями векторного параллелизма, ведь грядущие технологии вроде AVX-512 потенциально могут сделать код в 8 раз быстрее на числах с двойной точностью (по сравнению с не векторизованным кодом).
В этом посте мы расскажем, как учёные из Дарсбери использовали Vectorization Advisor для анализа кода Lattice Boltzmann Equation в DL_MESO, какие конкретно проблемы они нашли, и как исправили свой код, чтобы разогнать его в 2.5 раза.
Что такое Vectorization Advisor, читайте в первой статье. Здесь перейдём сразу к профилю Survey компонента Lattice Boltzman. Около половины всего времени исполнения приходится на десять «горячих» циклов, среди которых нет явных лидеров, каждый тратит не более 12% общего времени программы. Эта картина близка к «плоскому профилю» (flat profile), что обычно плохо для программиста. Ведь для достижения заметного ускорения, придётся оптимизировать каждый из циклов в отдельности.
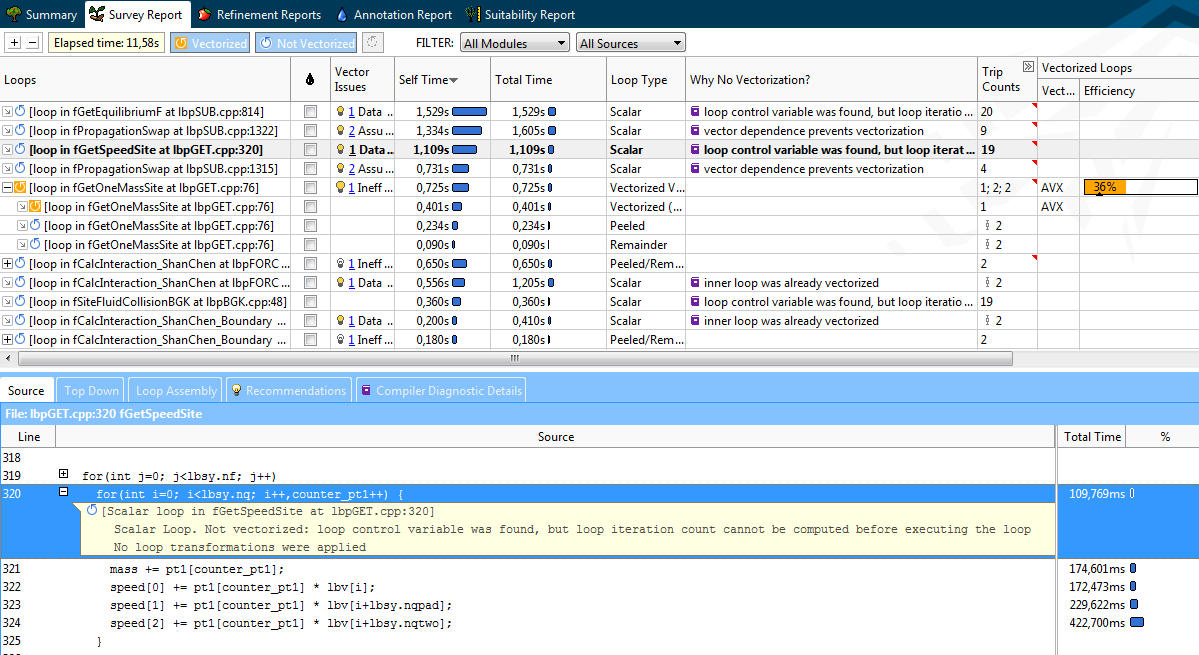
Но, к счастью для разработчиков из Дарсбери, Vectorization Advisor может быстро охарактеризовать циклы следующим образом:
Vectorization Advisor не только выдаёт информацию по циклам. Вкладки Recommendations и Compiler Diagnostic Details позволяют узнать о специфичных проблемах и путях их решения.
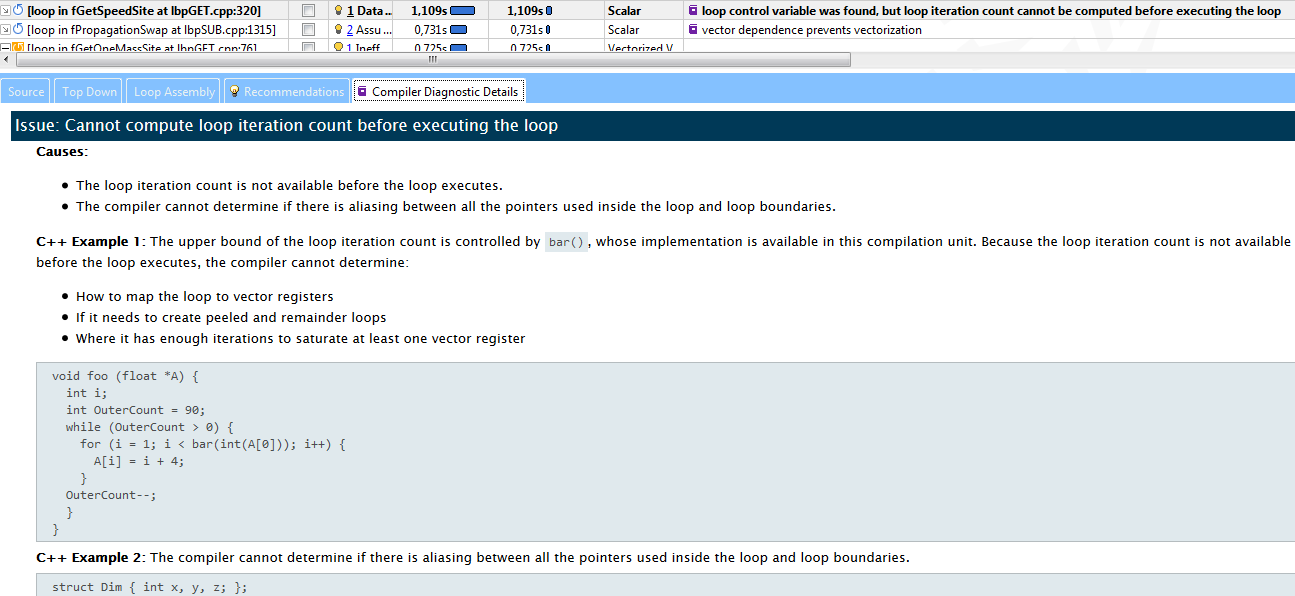
В нашем случае, третий хотспот («горячий» цикл, да простят меня блюстители чистоты языка) в fGetSpeedSite не смог векторизоваться, потому что компилятор не смог оценить, сколько в нём будет итераций. Compiler Diagnostic Details описывает суть проблемы с примером и предложениями по её решению – добавить директиву «#pragma loop count». Следуя совету, данный цикл был быстро векторизован и переместился из категории 2 в категорию 4.
Даже когда код может быть векторизован, это не обязательно сразу ведёт к росту производительности (категории 2 и 3). Поэтому важно исследовать уже векторизованные циклы на предмет их эффективности.
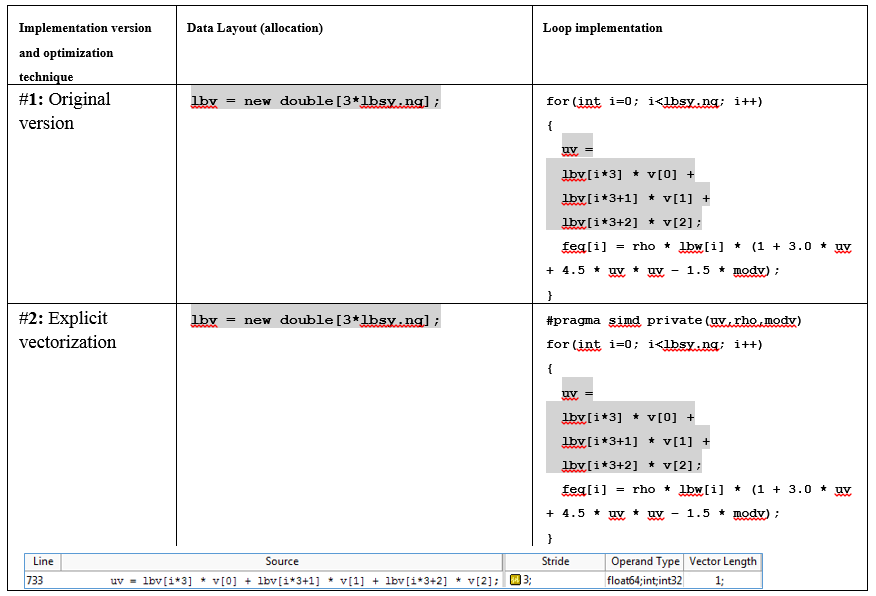
Массив lbv хранит скорости для пространственной решётки по всех измерениях. Переменная lbsy.nq содержит количество скоростей. Модель представляет трёхмерную 19-скоростную решётку (схема D3Q19). Т.е. значение lbsy.nq равно 19. Результирующее равновесие хранится в массиве feq[i].
При первом анализе цикл был скалярным, не векторизованным. Простым добавлением "#pragma omp simd" перед циклом, он был векторизован, и его доля в общем времени ЦПУ упала с 13% до 9%. Но даже с этими изменениями, здесь ещё есть возможности для улучшений.
Новый результат Advisor XE показал, что компилятор сгенерировал не один, а два цикла:
Этот Скалярный remainder – ненужный накладной расход. Его наличие наносит ущерб параллельной эффективности. Такой большой «вес» remainder-а вызван тем, что количество итераций не делится на VL (длину вектора) ровно. Компилятор генерирует векторные инструкции для итераций 0-15, а оставшиеся итерации с 16 по 18 выполняются в скалярном remainder. 3 итерации, да ещё и медленно последовательно исполняющиеся, и составляют 30% времени выполнения цикла. В идеале все итерации должны быть исполнены в векторном коде, и remainder вообще не должно быть.
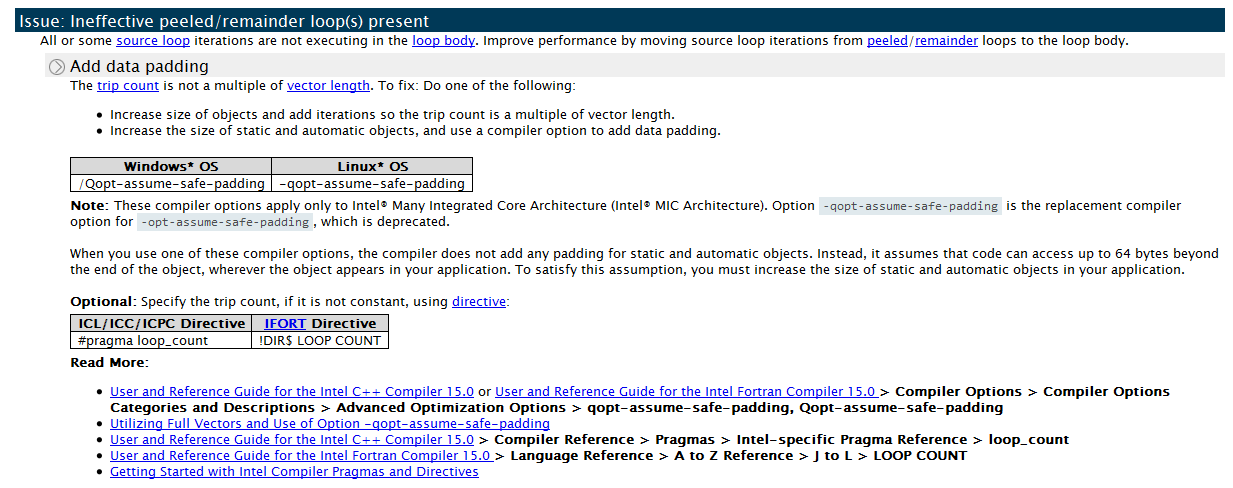
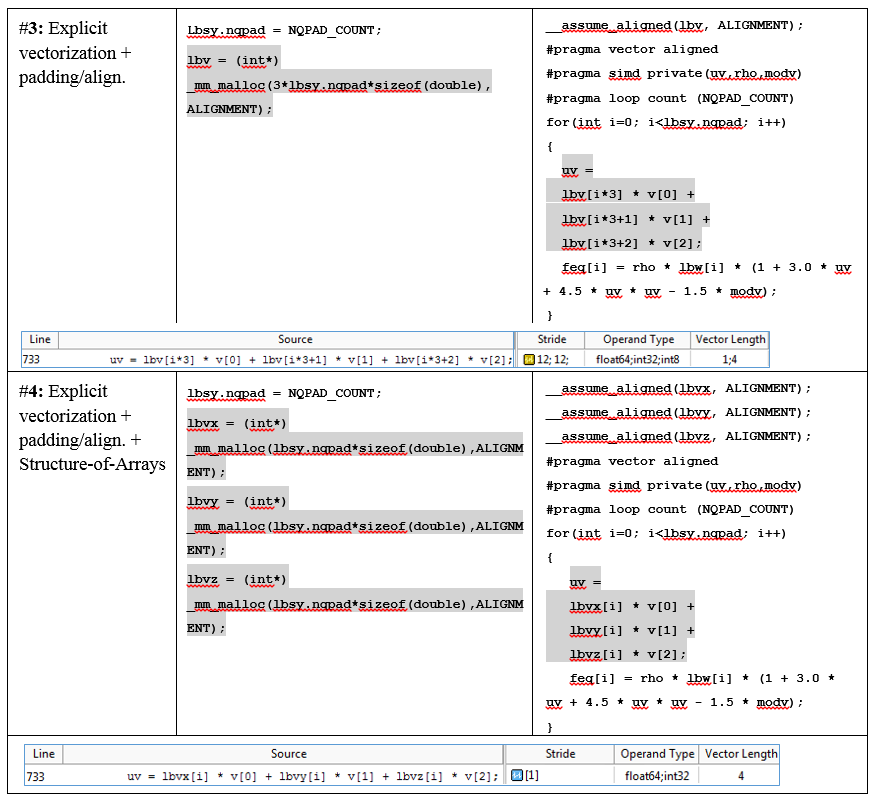
Мы может применить технику «подбивки» (data padding) к нашему циклу. Увеличим количество итераций до 20, что будет кратно VL (4). Advisor XE явно советует это сделать на вкладке Recommendations:
Чтобы «подбить» данные, нужно будет увеличить размеры массивов feq[], lbv[] и lbw[], чтобы не получить segmentation fault. В таблице в конце статьи показаны изменения в коде. Значение lbsy.nqpad является суммой оригинального количества итераций и значения padding (NQPAD_COUNT).
Кроме того, разработчики DL_MESO добавили директиву “#pragma loop count” перед циклом. Явно видя, что количество итераций кратно VL, компилятор генерирует векторный код, и remainder не исполняется.
В коде DL_MESO есть много таких же конструкций, которые можно улучшить тем же способом. Мы исправили три другие цикла в том же исходном файле и получили 15% ускорения каждого из них.
Техника подбивки, использованная для первых двух циклов, имеет свою цену:
В нашем случае положительный эффект на производительность перевесил минусы, и усложнение кода было приемлемым.
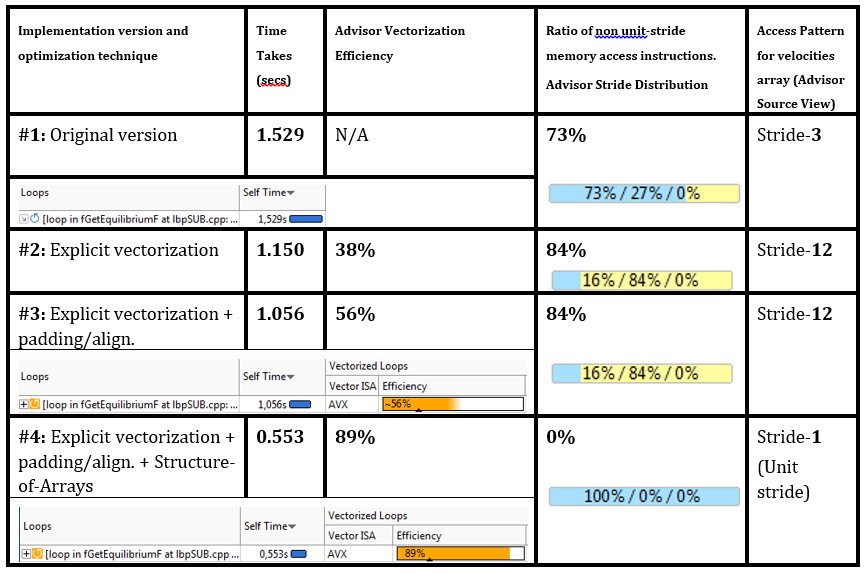
Векторизация, data padding и выравнивание данных улучшили производительность хотспота №1 на 25-30%, эффективность векторизации по оценке Advisor XE выросла до 56%.
Т.к. 56% всё ещё далековато от 100%, разработчики решили исследовать, что блокирует рост производительности. Посмотрев ещё раз на “Vector Issues/Recommendation”, они обнаружили новую проблему – “Possible inefficient memory access patterns present”. Соответствующая рекомендация советует запустить анализ “Memory Access Pattern” (MAP). Такой же совет был в колонке Traits:

Для запуска MAP анализа, разработчик отмечает нужные циклы и нажимает кнопку запуска MAP на панели Workflow.

Распределение страйдов в результате MAP показывает наличие unit-stride (последовательного доступа) и non-unit “constant” stride – обращений к памяти с постоянным шагом:

Данные MAP в исходном коде говорят о наличии обращений со страйдом 3 (для оригинальной скалярной версии) и страйдом 12 (для векторизованной версии с паддингом) при обращении к массиву lbv (см. таблицу в конце).
Обращение с шагом 3 происходит к элементам массива скоростей lbv. Каждая новая итерация смещается на 3 элемента массива. Откуда берётся 3 понятно из выражения lbv[i*3+X], к которому аттрибутируются наши обращения к памяти.
Такой непоследовательный доступ не очень хорош для векторизации, потому что не даёт загрузить все элементы в векторный регистр за одну инструкцию типа mov («упакованный» её вариант называется иначе). Но обращения с постоянным шагом зачастую можно преобразовать в последовательный доступ, применив преобразование из «массива структур» в «структуру массивов». Заметим, что после MAP анализа окно рекомендаций советует именно это (AoS->SoA) для решения проблемы неэффективного обращения к памяти – см. скриншот выше.
Разработчики применили такое преобразование к массиву lbv. Для этого массив lbv, изначально содержащий скорости для X, Y и Z, разбили на три массива: lbvx, lbvy и lbvz.
Разработчики DL_MESO говорят, что преобразование структуры массивов было трудозатратным по сравнению с паддингом, но результат оправдал усилия – цикл в fGetEquilibrium стал в 2 раза быстрее, и подобные улучшения случились ещё с несколькими циклами, работающими с массивом lbv.
Результаты трансформации структур данных и оптимизации циклов (padding, выравнивание), вместе с метриками эффективности и шаблонов доступа к памяти Advisor XE:
Эволюция исходного кода рассматриваемого цикла – директивы векторизации, выравнивание, паддинг, трансформация AoS -> SoA, вместе с результатами MAP из Advisor XE:
С помощью анализа DL_MESO в Vectorization Advisor и добавив в код несколько директив, удалось уменьшить время трёх самых горячих циклов на 10-19%. Все оптимизации основывались на рекомендациях Advisor-а. Была проделана работа по «включению» векторизации и улучшения производительности цикла с помощью «подбивки данных» (padding). Применив подобные техники к ещё нескольким циклам, было получено ускорение всего приложения на 18%.
Следующее серьёзное улучшение было получено при трансформации данных: «массива структур» в «структуру массивов». Опять же, исходя из рекомендации Advisor XE.
Кроме того, работа и тесты изначально проводились на серверах с процессорами Xeon (Advisor пока не работает на сопроцессоре). Когда то же самое было сделано для кода, работающего на сопроцессоре Xeon Phi, был получен примерно такой же выигрыш – заоптимизировали сопроцессор без дополнительных усилий.
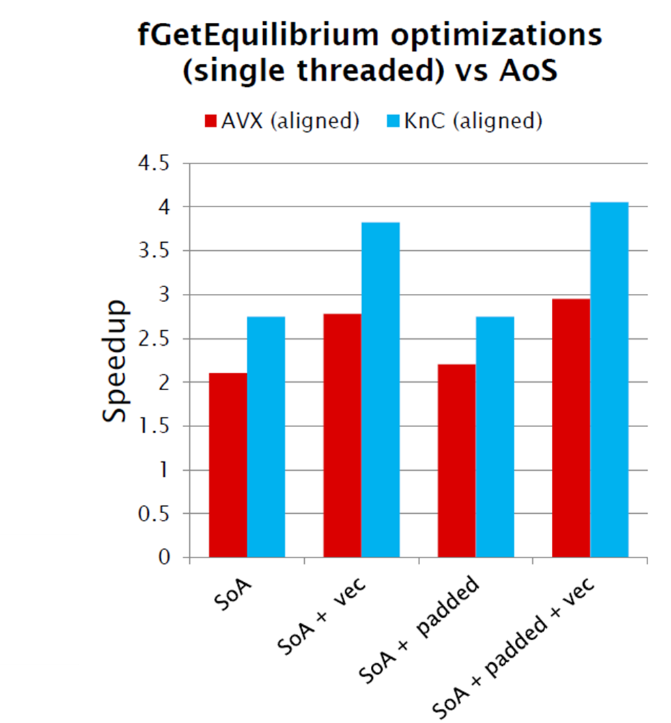
Ниже продемонстрировано ускорение, полученное на обычном сервере (помечено AVX) и карте Xeon Phi (помечено KnC). На Xeon CPU ускорились в 2.5 раза, на Xeon Phi – в 4.1 раза:
Цитата разраобтчика DL_MESO: “I'm already sold on this tool what we now need is a version for the Xeon Phi!” (Luke Mason, computational scientists in Daresbury lab).
Этот пост является переводом статьи Захара Матвеева (Intel Corporation).
DL_MESO – научный пакет для симуляции конденсированных сред на мезоскопическом уровне (да простят меня химики и физики, если не совсем корректно перевёл). Пакет разработан в лаборатории Дарсбери и широко применяется как в исследовательском сообществе, так и в индустрии (компаниями Unilever, Syngenta, Infineum). С помощью этого ПО ищутся оптимальные формулы для шампуней, удобрений и топливных присадок. Этот процесс называют “Computer Aided Formulation” (CAF) – я перевёл как «САПР в области разработки химических формул».
Симуляция CAF – очень ресурсоёмкие вычисления, поэтому разработчики были сразу заинтересованы в максимально производительном дизайне. И DL_MESO был выбран одним из совместных проектов в “Intel Parallel Computing Center” (IPCC) между Intel и Hartree.
Разработчики DL_MESO хотели воспользоваться аппаратными возможностями векторного параллелизма, ведь грядущие технологии вроде AVX-512 потенциально могут сделать код в 8 раз быстрее на числах с двойной точностью (по сравнению с не векторизованным кодом).
В этом посте мы расскажем, как учёные из Дарсбери использовали Vectorization Advisor для анализа кода Lattice Boltzmann Equation в DL_MESO, какие конкретно проблемы они нашли, и как исправили свой код, чтобы разогнать его в 2.5 раза.
Профиль Survey
Что такое Vectorization Advisor, читайте в первой статье. Здесь перейдём сразу к профилю Survey компонента Lattice Boltzman. Около половины всего времени исполнения приходится на десять «горячих» циклов, среди которых нет явных лидеров, каждый тратит не более 12% общего времени программы. Эта картина близка к «плоскому профилю» (flat profile), что обычно плохо для программиста. Ведь для достижения заметного ускорения, придётся оптимизировать каждый из циклов в отдельности.
Но, к счастью для разработчиков из Дарсбери, Vectorization Advisor может быстро охарактеризовать циклы следующим образом:
- Векторизуемые, но не векторизованные циклы, которые требуют минимальных изменений кода (обычно используя OpenMP4.x) для включения генерации SIMD кода. Первые 4 цикла (по времени ЦПУ) попадают в эту категорию.
- Векторизованные циклы, производительность которых может быть улучшена простыми манипуляциями.
- Векторизованные циклы, производительность которых ограничена структурой расположения данных. Оптимизация таких циклов требует более серьёзной переработки кода. Как мы увидим позже, после устранения проблем с первыми двумя категориями, двумя самыми нагруженными циклами станут именно такие.
- Векторизованные циклы, которые уже работают хорошо.
- Все другие случаи (включая не векторизуемые циклы).
Vectorization Advisor не только выдаёт информацию по циклам. Вкладки Recommendations и Compiler Diagnostic Details позволяют узнать о специфичных проблемах и путях их решения.
В нашем случае, третий хотспот («горячий» цикл, да простят меня блюстители чистоты языка) в fGetSpeedSite не смог векторизоваться, потому что компилятор не смог оценить, сколько в нём будет итераций. Compiler Diagnostic Details описывает суть проблемы с примером и предложениями по её решению – добавить директиву «#pragma loop count». Следуя совету, данный цикл был быстро векторизован и переместился из категории 2 в категорию 4.
Даже когда код может быть векторизован, это не обязательно сразу ведёт к росту производительности (категории 2 и 3). Поэтому важно исследовать уже векторизованные циклы на предмет их эффективности.
Простая оптимизация: padding в вычислительном ядре “equilibrium distribution”
int fGetEquilibriumF(double *feq, double *v, double rho)
{
double modv = v[0]*v[0] + v[1]*v[1] + v[2]*v[2];
double uv;
for(int i=0; i<lbsy.nq; i++)
{
uv = lbv[i*3] * v[0]
+ lbv[i*3+1] * v[1]
+ lbv[i*3+2] * v[2];
feq[i] = rho * lbw[i]
* (1 + 3.0 * uv + 4.5 * uv * uv - 1.5 * modv);
}
return 0;
}
Массив lbv хранит скорости для пространственной решётки по всех измерениях. Переменная lbsy.nq содержит количество скоростей. Модель представляет трёхмерную 19-скоростную решётку (схема D3Q19). Т.е. значение lbsy.nq равно 19. Результирующее равновесие хранится в массиве feq[i].
При первом анализе цикл был скалярным, не векторизованным. Простым добавлением "#pragma omp simd" перед циклом, он был векторизован, и его доля в общем времени ЦПУ упала с 13% до 9%. Но даже с этими изменениями, здесь ещё есть возможности для улучшений.
Новый результат Advisor XE показал, что компилятор сгенерировал не один, а два цикла:
- Векторизованное тело цикла с длинной вектора (Vector Length – VL) равным 4 – 4 числа типа double в 256-битном регистре AVX.
- Скалярный remainder, потребляющий 30% времени этого цикла.
Этот Скалярный remainder – ненужный накладной расход. Его наличие наносит ущерб параллельной эффективности. Такой большой «вес» remainder-а вызван тем, что количество итераций не делится на VL (длину вектора) ровно. Компилятор генерирует векторные инструкции для итераций 0-15, а оставшиеся итерации с 16 по 18 выполняются в скалярном remainder. 3 итерации, да ещё и медленно последовательно исполняющиеся, и составляют 30% времени выполнения цикла. В идеале все итерации должны быть исполнены в векторном коде, и remainder вообще не должно быть.
Мы может применить технику «подбивки» (data padding) к нашему циклу. Увеличим количество итераций до 20, что будет кратно VL (4). Advisor XE явно советует это сделать на вкладке Recommendations:
Чтобы «подбить» данные, нужно будет увеличить размеры массивов feq[], lbv[] и lbw[], чтобы не получить segmentation fault. В таблице в конце статьи показаны изменения в коде. Значение lbsy.nqpad является суммой оригинального количества итераций и значения padding (NQPAD_COUNT).
Кроме того, разработчики DL_MESO добавили директиву “#pragma loop count” перед циклом. Явно видя, что количество итераций кратно VL, компилятор генерирует векторный код, и remainder не исполняется.
В коде DL_MESO есть много таких же конструкций, которые можно улучшить тем же способом. Мы исправили три другие цикла в том же исходном файле и получили 15% ускорения каждого из них.
Балансировка накладных расходов и компромиссы оптимизации
Техника подбивки, использованная для первых двух циклов, имеет свою цену:
- С точки зрения производительности, мы устраняем накладные расходы в скалярном remainder, но привносим дополнительные вычисления в векторную часть.
- С точки зрения поддержки кода, мы переделали аллокацию структур данных и потенциально внесли в директивы компилятора значения, зависящие от размера входных данных и типа нагрузки.
В нашем случае положительный эффект на производительность перевесил минусы, и усложнение кода было приемлемым.
Оптимизируем расположение данных: структуры массивов
Векторизация, data padding и выравнивание данных улучшили производительность хотспота №1 на 25-30%, эффективность векторизации по оценке Advisor XE выросла до 56%.
Т.к. 56% всё ещё далековато от 100%, разработчики решили исследовать, что блокирует рост производительности. Посмотрев ещё раз на “Vector Issues/Recommendation”, они обнаружили новую проблему – “Possible inefficient memory access patterns present”. Соответствующая рекомендация советует запустить анализ “Memory Access Pattern” (MAP). Такой же совет был в колонке Traits:
Для запуска MAP анализа, разработчик отмечает нужные циклы и нажимает кнопку запуска MAP на панели Workflow.
Распределение страйдов в результате MAP показывает наличие unit-stride (последовательного доступа) и non-unit “constant” stride – обращений к памяти с постоянным шагом:
Данные MAP в исходном коде говорят о наличии обращений со страйдом 3 (для оригинальной скалярной версии) и страйдом 12 (для векторизованной версии с паддингом) при обращении к массиву lbv (см. таблицу в конце).
Обращение с шагом 3 происходит к элементам массива скоростей lbv. Каждая новая итерация смещается на 3 элемента массива. Откуда берётся 3 понятно из выражения lbv[i*3+X], к которому аттрибутируются наши обращения к памяти.
Такой непоследовательный доступ не очень хорош для векторизации, потому что не даёт загрузить все элементы в векторный регистр за одну инструкцию типа mov («упакованный» её вариант называется иначе). Но обращения с постоянным шагом зачастую можно преобразовать в последовательный доступ, применив преобразование из «массива структур» в «структуру массивов». Заметим, что после MAP анализа окно рекомендаций советует именно это (AoS->SoA) для решения проблемы неэффективного обращения к памяти – см. скриншот выше.
Разработчики применили такое преобразование к массиву lbv. Для этого массив lbv, изначально содержащий скорости для X, Y и Z, разбили на три массива: lbvx, lbvy и lbvz.
Разработчики DL_MESO говорят, что преобразование структуры массивов было трудозатратным по сравнению с паддингом, но результат оправдал усилия – цикл в fGetEquilibrium стал в 2 раза быстрее, и подобные улучшения случились ещё с несколькими циклами, работающими с массивом lbv.
Результаты трансформации структур данных и оптимизации циклов (padding, выравнивание), вместе с метриками эффективности и шаблонов доступа к памяти Advisor XE:
Эволюция исходного кода рассматриваемого цикла – директивы векторизации, выравнивание, паддинг, трансформация AoS -> SoA, вместе с результатами MAP из Advisor XE:
Резюме
С помощью анализа DL_MESO в Vectorization Advisor и добавив в код несколько директив, удалось уменьшить время трёх самых горячих циклов на 10-19%. Все оптимизации основывались на рекомендациях Advisor-а. Была проделана работа по «включению» векторизации и улучшения производительности цикла с помощью «подбивки данных» (padding). Применив подобные техники к ещё нескольким циклам, было получено ускорение всего приложения на 18%.
Следующее серьёзное улучшение было получено при трансформации данных: «массива структур» в «структуру массивов». Опять же, исходя из рекомендации Advisor XE.
Кроме того, работа и тесты изначально проводились на серверах с процессорами Xeon (Advisor пока не работает на сопроцессоре). Когда то же самое было сделано для кода, работающего на сопроцессоре Xeon Phi, был получен примерно такой же выигрыш – заоптимизировали сопроцессор без дополнительных усилий.
Ниже продемонстрировано ускорение, полученное на обычном сервере (помечено AVX) и карте Xeon Phi (помечено KnC). На Xeon CPU ускорились в 2.5 раза, на Xeon Phi – в 4.1 раза:
Цитата разраобтчика DL_MESO: “I'm already sold on this tool what we now need is a version for the Xeon Phi!” (Luke Mason, computational scientists in Daresbury lab).
Этот пост является переводом статьи Захара Матвеева (Intel Corporation).