

Это всегда была одна из лучших систем распознавания речи, особенно она удобна при поиске с использованием смартфонов. Теперь функция голосового поиска стала еще более развитой чем когда-либо. Блог Google Research описывает в общих чертах улучшения, которые были приняты в обновленной системы.
С 2012 года поисковый гигант отошел от использования Метода Гауссовых Смесей (МГС) тридцатилетней давности в распознавании речи. В новых системах стали применятся глубокие нейронные сети (Deep Neural Networks). ГНС могут лучше распознавать какие звуки произносит пользователь в определенный момент времени, что значительно повысило точность распознавания.
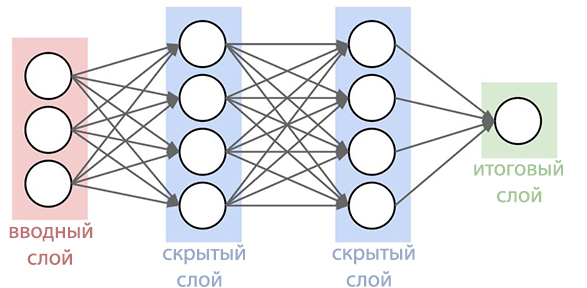
Теперь специалисты компании Google объявили, что им удалось создать более совершенную нейронную сеть акустических моделей, которые используют алгоритмы коннекционистской временной классификации и дискриминационного обучения. Эти модели представляют собой особое расширение периодических нейронных сетей, которые являются более точными, особенно в шумном окружении, и невероятно быстрыми!
В традиционном распознавании речи голосовая форма, которую заполнил пользователь, разделялась на последовательные фреймы (отрезки) по 10 миллисекунд. Каждый фрейм проходил частотный анализ и полученный после вектор с характеристиками был пропущен через акустические модели, такие как ГНС, которые выдают вероятности по всем звуковым совпадениям. Скрытая Марковская Модель (СММ) помогает разгадать неизвестные детали на основе уже полученных, это дает возможность ввести своего рода структурирование этой последовательности вероятностных распределений. Эта модель в дальнейшем сочетается с другими источниками знаний, такими как Модель Произношения, которая связывает последовательности звуков с определенными словами, выбранного языка и Языковой Модели, которая в свою очередь выражает насколько данное слово относится к выбранному языку.
Распознаватель далее согласовывает всю эту информацию, дабы определить предложение, которое произносит пользователь. Если пользователь произносит, например, слово «museum» (mju:’z??m — фонетическая форма), то может быть сложно определить, когда звук «j» заканчивается и начинается звук «u». Однако, по правде говоря, определителю все равно когда происходит этот переход. Единственное, что его беспокоит, это именно те звуки, которые были произнесены.
Новая улучшеная акустическая модель основана на Периодических Нейронных Сетях (ПНС). В топологии ПНС существуют петли обратной связи, которые позволяют смоделировать временную зависимость. Когда пользователь произносит / U / в предыдущем примере, артикуляционный аппарат человека плавно переходит от звука /J/ до звука /М/ прежде всего. Попробуйте произнести слово «museum», для людей, свободно владеющим английским языком, это не составит труда и слово произнесется легко на одном дыхании, ПНС способна уловить этот момент.
Типом периодических нейронных сетей в данной система является длинная кратковременная память, которая с помощью ячеек памяти и сложного механизма стробирования запоминает информацию лучше чем другие ПНС. Стробирование — это метод выделения некоторого временного интервала для увеличения вероятности обнаружения полезных сигналов на фоне помех. Принятие в работу таких моделей уже значительно повысило качество распознавания голоса.
Следующим шагом было обучение акустической модели распознавать фонемы (звуки) в произнесенной речи, не делая прогноз на каждый фрейм. Модели с Ассоциативной Временной Классификацией подготавливают график с последовательностью «шипов", которые отображают последовательность звуков в полученном сигнале. Они могут это делать до тех пор, пока последовательность не будет нарушена.
По сути система распознавания голоса Google теперь может рассмотреть контекст, в котором было произнесено слово, отстраняясь от фоновых звуков.

Совсем другой вопрос: как сделать это все доступным и удобным в режиме реального времени? После большого количества итераций, программистам Google удалось создать однопотоковые стриминговые модели, которые обрабатывают входящие сигналы блоками, которые превышают по размеру блоки в стандартных акустических моделях, но при этом совершают меньшее число фактических вычислений. Уменьшение количества вычислительных операций значительно ускоряет процесс распознавания сказанного. Так же в программу обучения системы были добавлены искусственные шумы и реверберации (искусственное уменьшение звуков), что бы сделать систему распознавания более устойчивой к постороннему шуму. На видео ниже вы можете наблюдать, как система изучает предложение.
Тем не менее, оставалось решить еще одну проблему: система производит меньшее число прогнозов, но при этом они задерживаются приблизительно на 300 миллисекунд. Выдавая результат после полного завершения предложения, повышался уровень распознания, но при этом создавались дополнительные задержки для пользователей, что совсем неприемлемо для специалистов Goolge. Что бы решить проблему, система была обучена производить анализ и выдавать результат по каждой фразе до того, как она будет завершена. Это сделало процесс распознавание более синхронизированным с нормальным темпом произношения человека. Пользователю более не требуется ожидать, пока программа выдаст свой вариант произнесенной фразы.
Новые акустические модели уже используются для голосового поиска и команд в приложении Google (на Android и iOS) и для диктовки на устройствах на базе Android. Новые модели стали требовать меньшее количество ресурсов, стали более устойчивы к окружающему шуму и способны выдавать результат гораздо быстрее предшественников. Это делает голосовой поиск более приятным для пользователя
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (14)

HostingManager
01.10.2015 15:34+12Где вариант «никогда не использовал»?

KOLANICH
01.10.2015 16:23-9Вариант убран намеренно, чтобы не провоцировать майора на допрос очень подозрительных гиков, его выбравших.

zv347
01.10.2015 15:52Окей, гугл, придется все-таки обновить поиск на Андроиде и попробовать привыкнуть к омерзительной белесой панели шторки…
Но вот удивительное дело: вроде бы голосовой поиск и быстрее, и удобнее, и я это знаю — а пользовался реально всего «пару раз». Видимо, какое-то подсознательное неприятие — вроде того как многим людям неприятно слышать запись своего голоса или эхо по телефону.
Danov
01.10.2015 18:30+1Это подсознательное неприятие нового. Просто экономия ресурсов. Нужно напрячься, получить первый опыт. Затем сформировать навык.

goodic
01.10.2015 18:03+2Но речь содержащую слова на двух разных языках сразу распознавать пока не может. Запросы вроде «Окей, Гугл. Перевод table» воспринимает как "… Перевод таблет" или "… Перевод таблетка".

Black_Shadow
01.10.2015 18:05+16Вместо «Окей, Гугл», можно говорить «отлей в угол», тоже срабатывает :-)



morfeusys
02.10.2015 13:14-2Вообще-то например Ассистент Дуся под Android уже давно работает и в офлайне. Те команды, которые не требуют интернета, нормально отрабатываются.
kAIST
Пользуюсь голосовым поиском в машине очень часто, особенно в сочетании с google now. Кому то позвонить, написать, проложить маршрут, открыть приложение. Ну и дома иногда — поставить будильник, создать напоминание.
Единственное, что бесит — почему то упорно не хочет работать без интернета. Языковой пакет скачен, но все равно упорно лезет в интернет и без него отказывается распозновать
goodic
Недавно анонсировали работу простых команд и в оффлайне. Что-то вроде «уменьши громкость» и тому подобное. У меня на Nexus 5 пока не работает
kAIST
Вот это то как раз понять не могу, зачем так сделано. Ну может же распознать «открой калькулятор», зачем без интернета то не сделать…