

Одной из новых функций, анонсированных на WWDC в этом году, стал Live Text. Она позволяет пользователям выбирать, переводить и искать текст в любом изображении. На демонстрации во время основного доклада была показана доска для совещаний с рукописным текстом. Когда открыли приложение камеры на iPhone и направили его на доску, в правом нижнем углу появился небольшой индикатор, показывающий, что текст распознан в видоискателе.
Пользователи Android могут заметить, что функция Live Text работает так же, как и Google Lens. Однако она не так интегрирована в интерфейс Android, как Live Text на iOS. На iPhone функцию Live Text можно вызвать из любого поля ввода текста. В этом посте я хочу показать вам, как создать простую версию Live Text с помощью Android Jetpack compose и CameraX. Вот несколько скриншотов из демонстрационного приложения. Код демонстрационного приложения вы можете найти здесь.
Требования
Прежде чем перейти к реализации, давайте сначала определим, каковы основные функциональные возможности Live Text. Если вы видели демонстрацию Live Text или пользовались объективом Google, то порядок действий такой:
Распознает текст из изображения или кадра камеры.
Обрабатывает выделение текста.
Понимает содержание текста и предлагает потенциальные действия, такие как адрес, номер телефона, электронная почта и т.д.
Вы можете заметить, что это может быть просто базовый процесс оптического распознавания символов (OCR) с предложениями, учитывающими контекст. Однако, когда я начал копать глубже и реализовывать функции, возникли трудности, особенно с точки зрения пользовательского опыта.
Структура приложения
При использовании ViewModel и других библиотек Jetpack в демоверсии, структура демонстрационного приложения очень проста. На следующей диаграмме показаны компоненты и потоки данных:

Активность содержит три компонуемых представления (composable views), которые отображают предварительный просмотр, обнаруженное текстовое содержимое и кнопку действия.
Для обработки предварительного просмотра и анализа кадров изображения используется библиотека CameraX. Интерфейс анализа предоставляет доступное процессору изображение чтобы выполнить обработку на каждом кадре. Анализатор настроен на работу в неблочной модели (с использованием флага STRATEGY_KEEP_ONLY_LATEST), которая всегда пытается получить последний кадр изображения и проверить в нем наличие текста.
В этом демонстрационном приложении для обработки процесса OCR используется библиотека Huawei OCR. Вы также можете использовать другие библиотеки OCR, например Firebase ML kit. Служба OCR может работать в облаке или на устройстве. Служба распознавания текста, работающая в облаке, распознает текст с более высокой точностью и поддержкой большего количества языков. Но версия на устройстве может обеспечить процесс в реальном времени, который представляет собой небольшой ML-алгоритм, который можно добавить в ваше приложение. Он имеет ограниченную языковую поддержку, более подробную информацию вы можете найти здесь. Следующие шаги распознавания очень похожи на большинство библиотек OCR, поэтому вы можете заменить их на ту, которая вам больше нравится.
TextAnalyzer:
class TextAnalyzer(private val onTextDetected: (MLText) -> Unit) : ImageAnalysis.Analyzer {
private val setting = MLLocalTextSetting.Factory()
.setOCRMode(MLLocalTextSetting.OCR_TRACKING_MODE)
.setLanguage("en")
.create()
private val analyzer = MLAnalyzerFactory.getInstance().getLocalTextAnalyzer(setting)
@SuppressLint("UnsafeOptInUsageError")
override fun analyze(imageProxy: ImageProxy) {
imageProxy.image?.let { image ->
analyzer.asyncAnalyseFrame(MLFrame.fromMediaImage(image, imageProxy.imageInfo.rotationDegrees))
.addOnSuccessListener { mlText ->
mlText?.let {
onTextDetected.invoke(it)
}
imageProxy.close()
}.addOnFailureListener {
imageProxy.close()
}
}
}
}Создайте экземпляр текстового анализатора MLTextAnalyzer для распознавания текста в кадре камеры. Вы можете использовать MLLocalTextSetting, чтобы указать языки поддержки и режим обнаружения OCR. Существует два режима, один из которых предназначен для обнаружения текста в отдельном изображении (OCR_DETECT_MODE), а другой - для обнаружения текста в видеопотоке (OCR_TRACKING_MODE). Результат сканирования предшествующего фрейма используется в качестве основы для быстрого определения положения текста в кадре камеры.
Создайте объект MLFrame с помощью MLFrame.fromMediaImage. При создании MLFrame необходимо передать значение угла поворота, но если вы используете CameraX, классы ImageAnalysis.Analyzer вычисляют его за вас (imageProxy.imageInfo.rotationDegrees).
Передайте объект MLFrame в метод asyncAnalyseFrame для распознавания текста. Результат распознавания определяется массивом MLText.Block.
Отображение текста и действие
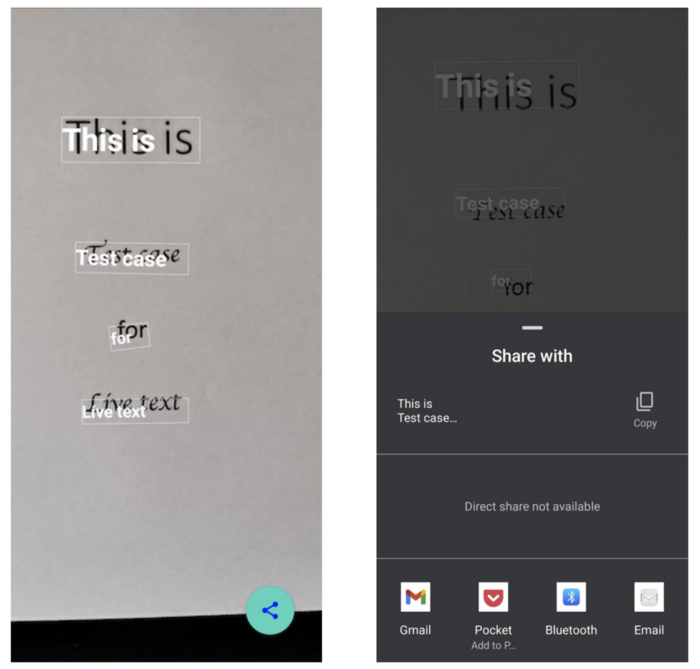
Как только текст будет распознан, библиотека вернет содержимое обнаруженного текста и вершины ограничивающей его рамки. Отобразится кнопка "Поделиться", а также обнаруженный текст над изображением. После нажатия на текст он будет скопирован в буфер обмена. Вы также можете нажать кнопку "Поделиться", чтобы передать все тексты, обнаруженные в рамке изображения.
При получении обнаруженного текста я думал использовать компонент Text и поместить его над превью, но это заметно снижает производительность, особенно когда у вас много текстовых блоков. Пришлось перейти к рисованию текста на холсте, что смотрелось лучше, но действие при нажатии требует больше кода для обработки, вам потребуется проверить, чтобы точка касания находилась в любой области текстового блока. Конечный результат будет выглядеть следующим образом:

Заключение
После завершения этой простой демонстрации я думаю, что самой сложной частью остается распознавание текста. Демо-приложение распознает только английские символы. Если в потоке камеры присутствует более одного языкового символа или символы распознаются с трудом, производительность демонстрационного приложения резко упадет. При использовании OCR только на устройстве можно улучшить защиту конфиденциальности, но это увеличит сложность, в особенности если вы хотите одновременно работать с несколькими языками. Я думаю, возможно, именно поэтому Live Text на iOS 15 распознает только семь языков в первоначальном выпуске.
Второе - это пользовательский опыт, особенно когда пользователи пытаются выделить обнаруженный текст. Рисование текста на холсте делает его отображение точнее, но выделение будет более сложным. Как я уже упоминал, Live Text интегрирован в систему iOS, поэтому он должен быть быстрым и легковесным. Моя текущая реализация занимала около 130 МБ памяти при запуске и 18 МБ установленного пространства. Сюда входит модель OCR размером около 500 КБ.
Еще один аспект, которого я не коснулся в этой демонстрации, - это машинное обучение устройства. От обнаружения содержания текста до понимания контекста. Когда происходит все больше и больше действий, локальная модель может быть улучшена на основе обратной связи. Вы можете свободно форкнуть repo и создать свой собственный Live Text.
Материал подготовлен в рамках курса «Android Developer. Professional». Если вам интересно узнать подробнее о формате обучения и программе, познакомиться с преподавателем курса — приглашаем на день открытых дверей онлайн. Регистрация здесь.

goodvin1709
Спасибо за материал, местами перевод не очень точный, например:
1. "пользовались объективом Google" - пользовались Google Lens.
2. рисованию текста на холсте - рисованию с помощью Сanvas API.