
Самый простой Big Data проект сложнее проекта из мира привычного ПО. Имеется ввиду не сложность собственно алгоритмов или архитектуры, но анализа того, что представляет собой проект, как он работает с данными, как собирается та или иная витрина, какие для нее берутся данные.
Например, нужно решить такую задачу:
Набор инструментов будет выглядеть примерно так:
Простая задача неожиданно приводит к появлению проекта, включающего три независимых инструмента с тремя независимыми папками исходных файлов. И как понять – что происходит в проекте?
Если рассмотреть более типичный случай, то набор артефактов простого проекта в Big Data представляет собой:
Также, особенностью является то, что если пользоваться Cloudera или Hortonworks, то среда не предоставляет удобных средств разработки и отладки.
Облачные среды, такие как AWS или Azure, предлагают все делать в их оболочке, объединяющей все требуемые артефакты в удобном интерфейсе.
Вот, например, картинка с сайта Microsoft Azure:

Но это если есть AWS или Azure. А если есть только Cloudera?
Как ответить на вопрос – что, собственно, в проекте написано? При этом этот вопрос крайне интересует и заказчика тоже, так как в случае обычного ПО ему все равно то, как всё устроено внутри, а в случае с Big Data заказчику важно понимать, что данные получаются правильно.
В мире обычного программирования есть набор паттернов, подходов, применение которых позволяет структурировать код. А как структурировать код, представляющий из себя зоопарк независимых SQL-файлов, SH-скриптов вперемешку с Oozie Workflow?
Конечно, обычным решением является ведение подробной документации. Но документация устаревает в момент создания, а в случае авралов, разработка ведется вообще без обновления документов. Хочется автоматически собирать сведения о структуре данных, раскрывая Dataflow проекта.
Еще одним подходом является создание в компании Data Catalog, в котором будет регистрироваться каждый источник данных, и который будет являться единственным источником информации о датасетах, Source of Truth.
Существуют различные инструменты для создания Data Catalog:
Эти инструменты, например, с помощью Data Crawlers, мониторят события, происходящие в области данных и строят каталог объектов, пытаясь построить Lineage там, где это возможно. Например, подключаются к событиям Spark и вынимают оттуда данные об объектах. Это иногда позволяет не только записать в каталог объект, но и восстановить его Lineage. В результате появляется каталог как единый Source of Truth для данных, что сильно облегчает понимание их структуры и взаимосвязей.
Картинка с сайта Cloudera Navigator:

Вообще создание и поддержание каталога данных большая и сложная задача. Для этого нужна готовность заказчика, а также необходимы инструмент, команда и время. Требуется зарегистрировать все источники, написать регламенты работы с данными, внедрить – в целом это серьезная инфраструктурная задача для организации.
Мы в компании Neoflex разработали и применяем несколько другой подход, который реализовали в инструменте Datalog или, более полно – Data Topology. Инструмент предоставляет возможность раскрывать топологию объектов проекта в разрезе Dataflow, создавая автообновляемую документацию проекта в разрезе диаграм Dataflow на основе исходных кодов.
Проект Big Data представляет собой исходники для самых разных инструментов, но их объединяет одно – общая доменная модель. Имеется ввиду то, что все артефакты проекта – SQL-скрипты, SH-скрипты, исходники Spark и прочее описывают только одно – Dataflow.
Это значит, что если извлечь из артефактов (скриптов и исходников) данные о таблицах, которые используются в каждом из компонентов, то можно построить диаграмму Dataflow проекта. В большинстве случаев этого более чем достаточно, чтобы сделать содержимое проекта прозрачным и доступным анализу.
В этом месте тот, кто имеет хоть какое-то отношению к программированию, должен потерять интерес к статье. Почему? Потому что на ум сразу приходит соображение, что исходники могут быть написаны как угодно сложно и извлечь какую-то информацию из них в общем случае непросто. Вот простейший пример использования таблицы Table1 в Spark коде, который может описываться такими вариантами кода:
То есть название таблицы может быть прямо в коде, передаваться в виде параметра, а также весь запрос может передаваться в виде параметра. И такое встречается в любом из инструментов, поэтому кажется, что для извлечения информации о Dataflow, нужно писать собственный полноценный транслятор. Но это не так. На деле мы рассматриваем исходники как артефакты и нам не нужна вся цепочка использования объекта внутри компонента, так как достаточно лишь его упоминание в коде или файле параметризации. В этом случае задача написания транслятора превращается в простую задачу поиска токенов в текстовых файлах.
При таком подходе нельзя написать код, работающий в общем случае, но для каждого конкретного проекта можно.
Лучше всего это работает для больших Legacy проектов с долгой историей, про которые то, как они целиком устроены, обычно не может сказать ни один человек. Заказчик становится зависим от команды проекта, а после его передачи другим людям ситуация повторяется. В случае нашего подхода достаточно написать несколько простых правил извлечения данных из исходников, и становится возможным построение диаграммы Dataflow.
Как это выглядит на практике?
Допустим есть проект, который представляет из себя последовательность SQL -скриптов, исполняемые через hive и запускаемые через oozie. Сначала три скрипта готовят промежуточные данные, а последний – строит целевую витрину.
Запускающий файл выглядит так:
SQL -скрипты выглядят так:
Есть oozie workflow, запускающая последовательно такие задачи:
собственно, вот такой workflow:
Вся папка проекта выглядит так:

После анализа проекта составляются три простых правила извлечения информации о Dataflow:
После анализа структуры проекта правила извлечения данных из исходников условно можно записать так:
Это что-то типа DSL для описания проекта.
Такая запись утверждает, что все существенное для этого проекта надо искать только в папках с SQL. Для данного проекта этого достаточно.
Вот, что получается на выходе:
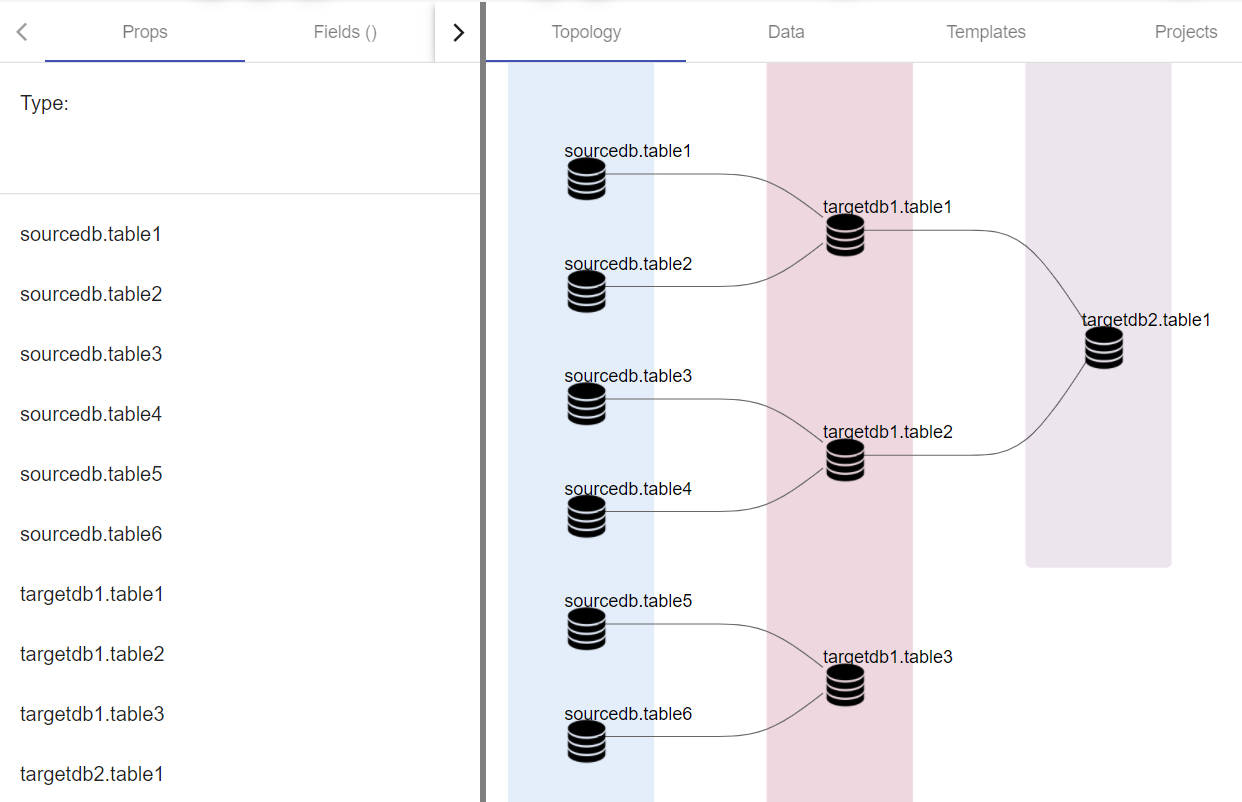
Как выяснилось, в проекте строятся две независимые витрины.
Та же самая информация может быть представлена по-другому, если она будет в виде in-out, а именно – какой компонент цепочки какие объекты данных потребляет и кому их дальше передает:
Итого: были применены простые правила, описывающие как трактовать исходные файлы и извлечь из них нужные токены. Информация была передана построителю графов и на выходе получилась диаграмма, раскрывающая Dataflow проекта. Важно, что инструмент опирается на исходные коды, то есть диаграмма создается автоматически на основе артефактов проекта.
Что дает такой подход:
Недостатки такого подхода тоже очевидны:
Этот проект можно рассматривать как своего рода замену или дополнение Data Catalog, раскрывающие процессы построения данных в разрезе проектов. Лучше всего применение Datalog показывает себя при анализе больших legacy-проектов с многолетней историей.
Например, нужно решить такую задачу:
- Загрузить таблицу из Oracle;
- Посчитать в ней сумму по какого-нибудь полю, сгруппировав по ключу;
- Результат сохранить в витрину в Hive.
Набор инструментов будет выглядеть примерно так:
- Oracle
- Apache Sqoop
- Oozie
- Apache Spark
- Hive
Простая задача неожиданно приводит к появлению проекта, включающего три независимых инструмента с тремя независимыми папками исходных файлов. И как понять – что происходит в проекте?
Если рассмотреть более типичный случай, то набор артефактов простого проекта в Big Data представляет собой:
- SH управляющие файлы;
- Sqoop скрипты;
- набор Airflow Dag или Oozie Workflow;
- SQL скрипты собственно преобразований;
- Исходники на PySpark или Scala Spark;
- DDL скрипты создания объектов.
Также, особенностью является то, что если пользоваться Cloudera или Hortonworks, то среда не предоставляет удобных средств разработки и отладки.
Облачные среды, такие как AWS или Azure, предлагают все делать в их оболочке, объединяющей все требуемые артефакты в удобном интерфейсе.
Вот, например, картинка с сайта Microsoft Azure:
Но это если есть AWS или Azure. А если есть только Cloudera?
Как ответить на вопрос – что, собственно, в проекте написано? При этом этот вопрос крайне интересует и заказчика тоже, так как в случае обычного ПО ему все равно то, как всё устроено внутри, а в случае с Big Data заказчику важно понимать, что данные получаются правильно.
В мире обычного программирования есть набор паттернов, подходов, применение которых позволяет структурировать код. А как структурировать код, представляющий из себя зоопарк независимых SQL-файлов, SH-скриптов вперемешку с Oozie Workflow?
Конечно, обычным решением является ведение подробной документации. Но документация устаревает в момент создания, а в случае авралов, разработка ведется вообще без обновления документов. Хочется автоматически собирать сведения о структуре данных, раскрывая Dataflow проекта.
Еще одним подходом является создание в компании Data Catalog, в котором будет регистрироваться каждый источник данных, и который будет являться единственным источником информации о датасетах, Source of Truth.
Существуют различные инструменты для создания Data Catalog:
- Cloudera Navigator;
- Alation;
- Colibra.
Эти инструменты, например, с помощью Data Crawlers, мониторят события, происходящие в области данных и строят каталог объектов, пытаясь построить Lineage там, где это возможно. Например, подключаются к событиям Spark и вынимают оттуда данные об объектах. Это иногда позволяет не только записать в каталог объект, но и восстановить его Lineage. В результате появляется каталог как единый Source of Truth для данных, что сильно облегчает понимание их структуры и взаимосвязей.
Картинка с сайта Cloudera Navigator:
Вообще создание и поддержание каталога данных большая и сложная задача. Для этого нужна готовность заказчика, а также необходимы инструмент, команда и время. Требуется зарегистрировать все источники, написать регламенты работы с данными, внедрить – в целом это серьезная инфраструктурная задача для организации.
Мы в компании Neoflex разработали и применяем несколько другой подход, который реализовали в инструменте Datalog или, более полно – Data Topology. Инструмент предоставляет возможность раскрывать топологию объектов проекта в разрезе Dataflow, создавая автообновляемую документацию проекта в разрезе диаграм Dataflow на основе исходных кодов.
Проект Big Data представляет собой исходники для самых разных инструментов, но их объединяет одно – общая доменная модель. Имеется ввиду то, что все артефакты проекта – SQL-скрипты, SH-скрипты, исходники Spark и прочее описывают только одно – Dataflow.
Это значит, что если извлечь из артефактов (скриптов и исходников) данные о таблицах, которые используются в каждом из компонентов, то можно построить диаграмму Dataflow проекта. В большинстве случаев этого более чем достаточно, чтобы сделать содержимое проекта прозрачным и доступным анализу.
В этом месте тот, кто имеет хоть какое-то отношению к программированию, должен потерять интерес к статье. Почему? Потому что на ум сразу приходит соображение, что исходники могут быть написаны как угодно сложно и извлечь какую-то информацию из них в общем случае непросто. Вот простейший пример использования таблицы Table1 в Spark коде, который может описываться такими вариантами кода:
val df = spark.sql(“select * from Table1”)
val df = spark.sql(“select * from ${source_table}”)
val df = spark.sql(“${sql}”)То есть название таблицы может быть прямо в коде, передаваться в виде параметра, а также весь запрос может передаваться в виде параметра. И такое встречается в любом из инструментов, поэтому кажется, что для извлечения информации о Dataflow, нужно писать собственный полноценный транслятор. Но это не так. На деле мы рассматриваем исходники как артефакты и нам не нужна вся цепочка использования объекта внутри компонента, так как достаточно лишь его упоминание в коде или файле параметризации. В этом случае задача написания транслятора превращается в простую задачу поиска токенов в текстовых файлах.
При таком подходе нельзя написать код, работающий в общем случае, но для каждого конкретного проекта можно.
Лучше всего это работает для больших Legacy проектов с долгой историей, про которые то, как они целиком устроены, обычно не может сказать ни один человек. Заказчик становится зависим от команды проекта, а после его передачи другим людям ситуация повторяется. В случае нашего подхода достаточно написать несколько простых правил извлечения данных из исходников, и становится возможным построение диаграммы Dataflow.
Как это выглядит на практике?
Допустим есть проект, который представляет из себя последовательность SQL -скриптов, исполняемые через hive и запускаемые через oozie. Сначала три скрипта готовят промежуточные данные, а последний – строит целевую витрину.
Запускающий файл выглядит так:
run-hive.sh:
hive -f $1SQL -скрипты выглядят так:
insert into targetdb1.table1
select f1, f2
from
sourcedb.table1 t1 inner join sourcedb.table2 t2 on t1.id = t2.idЕсть oozie workflow, запускающая последовательно такие задачи:
- Три параллельных скрипта, готовящих промежуточные данные;
- Финальная задача, строящая витрину на основе таблиц из задачи 1
собственно, вот такой workflow:
<workflow-app name="Hive1" xmlns="uri:oozie:workflow:0.5">
<start to="fork1"/>
<kill name="Kill" />
<fork name="fork-1"></fork>
<join name="join-1" to="Project2"/>
<action name="sql1">
<shell xmlns="uri:oozie:shell-action:0.1">
<exec>run-hive.sh</exec>
<argument>project1/sql/sql1.sql</argument>
<capture-output/>
</shell>
<ok to="join-1"/>
<error to="Kill"/>
</action>
<action name="sql2">
<shell xmlns="uri:oozie:shell-action:0.1">
<exec>run-hive.sh</exec>
<argument>project1/sql/sql2.sql</argument>
<capture-output/>
</shell>
<ok to="join-1"/>
<error to="Kill"/>
</action>
<action name="sql3">
<shell xmlns="uri:oozie:shell-action:0.1">
<exec>run-hive.sh</exec>
<argument>project1/sql/sql3.sql</argument>
<capture-output/>
</shell>
<ok to="join-1"/>
<error to="Kill"/>
</action>
<action name="Project2">
<shell xmlns="uri:oozie:shell-action:0.1">
<exec>run-hive.sh</exec>
<argument>project2/sql/sql1.sql</argument>
<capture-output/>
</shell>
<ok to="end"/>
<error to="Kill"/>
</action>
<end name="End"/>
</workflow-app>
Вся папка проекта выглядит так:
После анализа проекта составляются три простых правила извлечения информации о Dataflow:
- Workflow.xml и SH файл игнорируются, так как в них нет ничего существенного о Dataflow;
- project1 и project2 транслируются как этапы проекта, которые в терминах in-out передают один другому данные (project1->project2);
- Файлы SQL, лежащие в project1/ SQL и project2/ SQL транслируются через SQL-парсер.
После анализа структуры проекта правила извлечения данных из исходников условно можно записать так:
val dataflow = parseSqlFolder(path = "project1/sql/", componentName = "sample.project1")
dataflow ++= parseSqlFolder(path = "project2/sql/", componentName = "sample.project2")Это что-то типа DSL для описания проекта.
Такая запись утверждает, что все существенное для этого проекта надо искать только в папках с SQL. Для данного проекта этого достаточно.
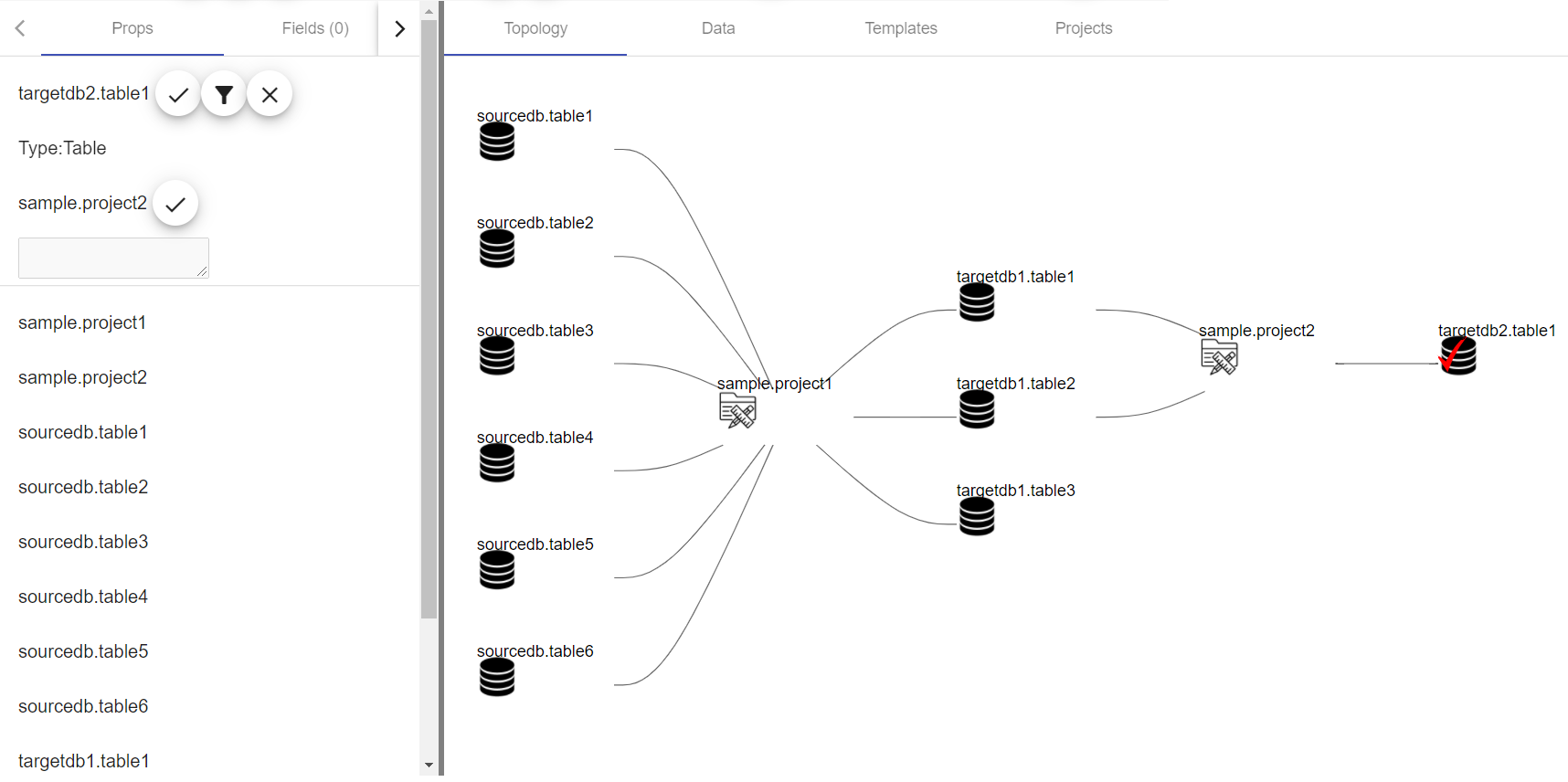
Вот, что получается на выходе:
Как выяснилось, в проекте строятся две независимые витрины.
Та же самая информация может быть представлена по-другому, если она будет в виде in-out, а именно – какой компонент цепочки какие объекты данных потребляет и кому их дальше передает:
Итого: были применены простые правила, описывающие как трактовать исходные файлы и извлечь из них нужные токены. Информация была передана построителю графов и на выходе получилась диаграмма, раскрывающая Dataflow проекта. Важно, что инструмент опирается на исходные коды, то есть диаграмма создается автоматически на основе артефактов проекта.
Что дает такой подход:
- Для создания Dataflow диаграмм не требуется переделка процессов у заказчика. Данные извлекаются из существующих проектов. Не нужно создавать каталог данных, можно создавать каталог проектов. Кроме того, для применения этого подхода не нужна разработка какого-то глобального регламента работы с данными, как было бы в случае создания Data Catalog;
- Построение диаграммы, описывающей проект, опирается только на исходные коды. Это значит, что такая диаграмма может показывать и те этапы, которые не попадают, например, в Data Catalog, так как происходят за границами, скажем, кластера;
- Полученная диаграмма не устареет, так как опирается на исходные коды проекта и создается заново при открытии;
- Так как основная работа в Big Data осуществляется через SQL, то простое подключение SQL-парсера (в данном случае Spark Catalyst) решает проблему поиска токенов, и после написания правил подключение второго, третьего и далее проектов происходит очень быстро;
- Для описания проекта применяются не документация, а ряд правил, помогающих транслятору разбирать проект. Такие правила всегда есть, но обычно остаются в голове разработчика, который отвечает за проект. Здесь же они записаны и сохраняются. Это похоже на DSL того, как переводить проект в описание.
Недостатки такого подхода тоже очевидны:
- Правила извлечения данных должны эволюционировать вместе с проектом;
- То, что получается, описывает данный конкретный проект и вряд ли подходит для проектов другой структуры;
- Это все-таки не Data Catalog, в котором есть много чего еще помимо построения диаграм Dataflow.
Этот проект можно рассматривать как своего рода замену или дополнение Data Catalog, раскрывающие процессы построения данных в разрезе проектов. Лучше всего применение Datalog показывает себя при анализе больших legacy-проектов с многолетней историей.
Комментарии (8)

ksr123
03.09.2021 16:56Ваш логотип в ленте постов выглядит как красный крестик. Ассоциация с чем-то удаленным или запрещенным.
sshikov
Я на это могу сказать только одно — что такое «правильно», обычно формулируется на естественном языке. Поэтому полностью автоматически проверить эту правильность не представляется возможным. Ну вот реально, как только в проекте появляется скажем курс обмена валюты (а это всего-лишь коэффициент, казалось бы — я уверен, что никто кроме авторов и аналитиков проекта вам точно не скажет, правильный ли вот этот курс для вот того случая — потому что курс этот обычно на какой-то момент (т.е. это спот, или что-то там еще), а значит включает в себя уже такие вещи, как календарь, биржу, где эту валюту продают и покупают, и так далее и тому подобное. Я не утверждаю, что попытки построить lineage не нужны — я скорее хочу сказать, что даже в одном проекте при наличии связей между данными зачастую черт ногу сломит. И все инструменты, что я видел, мало помогают.
Я еще могу сходу придумать пяток вариантов, хотите? Причем не просто с потолка придумать, а такие, которые у нас реально применяются, и как правило смогу рассказать, зачем конкретно.
neoflex Автор
Да, все правильно. Именно об этом и статья, что проект обычно получается сложный, и что делать с ним не ясно. Но в реальности, как показывает практика, эта сложность разбивается на 3-5 вполне себе прозрачных варианта, что и позволяет извлечь информацию и построить dataflow проекта. Да, такие диаграммы не описывают всю сложность, как и data catalog, но то, что получается, это набор диаграмм из реальных артефактов проекта, и это намного лучше, чем ничего отсутствие документации вообще.
Что касается вариантов представления информации о таблицах, я сам их могу привести штук 20 не из головы, а из реальных проектов.
И вот тут, как раз, и находится основание для такого проекта. Этих вариантов не 500 и не 5000, а намного меньше, то есть столько, что позволяет построить набор правил для парсинга исходников и извлечения из них информации о dataflow.
Как выглядит обычный проект развивавшийся года 3-4? Несколько сотен файлов исходников, несколько десятков таблиц. Что с этим делать? Да вот написать 5-6 правил, которые позволят построить диаграммы dataflow. Это и есть наш проект.
sshikov
>построить набор правил для парсинга исходников
Мне кажется, или вы пытаетесь построить статический анализ кода? В моем понимании, никакой статический анализ не может выйти за определенные пределы — а именно, как только появляются данные извне (файл, ну или там база), так статический анализ перестает понимать, что именно возможно, а что нет.
Вот у меня как раз такой легаси проект. Spark, Oozie, немножко груви вместо шелла, немножко шаблонов. При этом все имена артефактов в базах, таблицы, схемы, колонки — все это во внешних файлах. Ну т.е. не посмотрев во внешний файл (который частью проекта не является, и в том же самом Git не лежит, а лежит неизвестно где) мы даже не можем сказать, с какой таблицей данный сот будет работать.
Ну т.е. я может просто пессимист в данном случае. Так-то я даже свои Hive HQL запросы каталистом парсил, чтобы на их генератор юнит несты написать. То есть делал ну почти тоже самое, что вы предлагаете. Но чтобы в мой проект так залезть, придется парсить с десяток разных языков, три из которых — PL/SQL, T/SQL и PgSQL, помимо HQL, и еще пяток попроще. Просто потому что внешние СУБД имеют место. И для меня это выглядит как сильный перебор по трудозатратам, с непонятным выхлопом.
Но почитать все равно было интересно!
neoflex Автор
Все правильно. Те же самые опасения были и у нас. Вообще, всего в статье не опишешь, но проект начинался с немного другой архитектурой. Предполагалось, что мы для себя, для наших проектов, изобретем правила, когда логику будем выносить во внешний файл, где будут имена таблиц и логика обработки. Вот этот внешний файл и предполагалось парсить и отображать в виде диаграммы. Но постепенно выяснилось, что этого не требуется. Парсить с десяток языков для извлечения из них информации по датафлоу не так уж и страшно. Реальные трудозатраты на это вполне умеренные, особенно, по сравнению с трудозатратами на сам проект.
sshikov
>Реальные трудозатраты на это вполне умеренные
Я не уверен, что где-то есть честная грамматика свежего PL/SQL, например. Т.е. это может и возможно (с учетом того, что мы произвольные хранимки в проекте не пишем), но все же немного костыльно, если можно так выразиться.
neoflex Автор
Она и не нужна. Если подходить так, придется писать полноценный транслятор по каждому инструменту.
Но мы же решаем свою собственную задачу. Зачем нам полноценный транслятор?
Пример:
В проекте есть есть sqoop скрипты, которые выглядят так:
sqoop --query "select * from b1.t1 join b1.t2 on t1.id = t2.t1_id" --table b2.t3
То есть логика датафлоу запакована внутрь sqoop и там внутрь sql.
Но ведь для данного проекта, чтобы получить данные о датафлоу нужно всего лишь выполнить примерно такой условный скрипт:
val tables = sqoopScript.splitBy([' ', ',', '(', ')']).match('[a-z]/.[a-z]')
не уверен что синтаксис правильный, но суть в чем - разбить содержимое файла на токены и оставить из них только те, где токен это два слова разделенных символом точка. мы получим b1.t1, b2.t2, b2.t3
То есть мы проанализировали проект. Нашли в нем пачку скриптов, и для данного конкретного случая записали такое простое правила парсинга. Это правило для данного конкретного случая, а не общий парсер инструмента. В этом суть. И тогда это работает.
sshikov
У нас не все так просто. Поэтому иногда нужна. Может и не совсем полноценный парсер PL/SQL, но таки более-менее реальный (скажем, то что есть для ANTLR в примерах, какая-то версия типа 11g).