
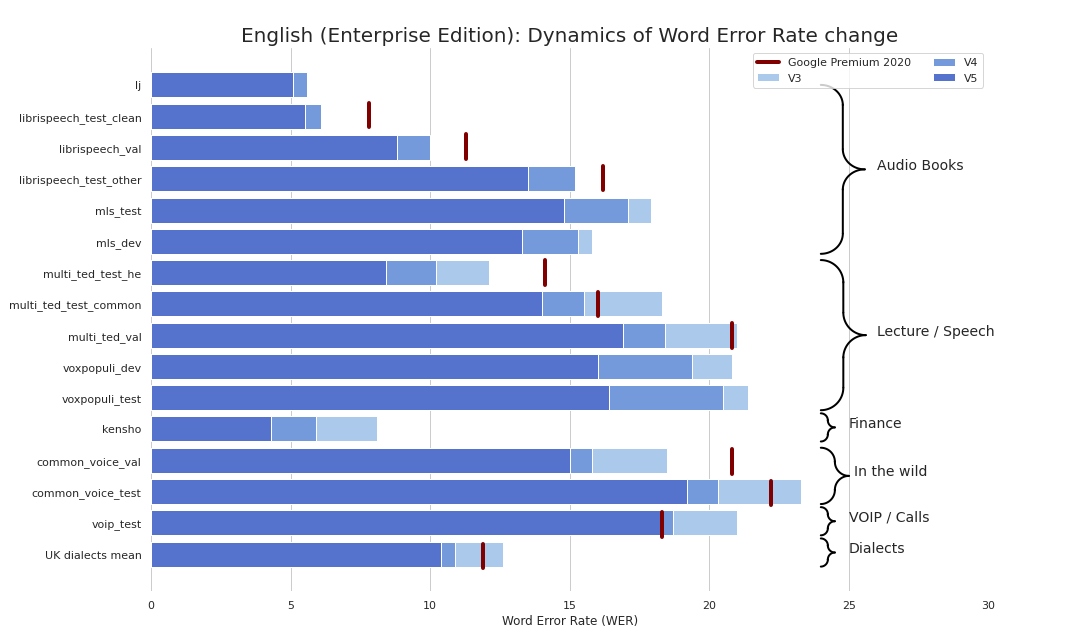
Мы опубликовали уже пятую версию наших моделей для распознавания английского языка и четвертую — для немецкого. На картинке выше — прогресс роста качества для английского языка.
В этот раз мы можем порадовать вас:
- Как большими, так и маленькими моделями;
- Постоянным ростом качества на всех доменах аудио, снижением размера и ускорением моделей;
- Как обычно — качество на уровне премиум моделей Google (причем в этот раз к премиум моделями 2020 года подобрались уже даже маленькие Community Edition модели);
- Супер компактными моделями (
smallи скоро ожидаетсяxsmall) и их квантизованными версиями;
| jit | jit | jit | jit | jit_q | jit_q | onnx | onnx | onnx | |
|---|---|---|---|---|---|---|---|---|---|
| xsmall | small | large | xlarge | xsmall | small | small | large | xlarge | |
Английский en_v5
|
⌛ | ✅ | ✅ | ⌛ | ✅ | ✅ | ✅ | ||
Немецкий de_v4
|
✅ | ✅ |
Вы можете найти наши модели в нашем репозитории вместе с примерами и метриками качества и скорости. Мы также постарались сделать начало работы с нашими моделями как можно более простым — мы выложили примеры на Colab и чекпойнты для PyTorch, ONNX (TensorFlow мы перестали поддерживать).
Проект silero-models почти набрал на Github тысячу звездочек, помогите нам преодолеть эту психологическую планку!
Достигнутые вершины, дальнейшие планы и чего мы не сделали
Для начала распишу, чего сделать не получилось:
- Сделать модели такого же качества для ряда других планируемых языков (ряд славянских языков, французский язык). На самом деле французский и обновления для испанского были более менее готовы, но нам не хватило фокуса их опубликовать и довести до конца. Плюс на эти языки мы не видели спроса заказчиков, в отличие от русского, английского и немецкого;
- Сделать такую же широкую палитру моделей не только для английского языка;
А вот эти вещи получилось сделать:
- Создать палитру моделей для английского языка разных размеров;
- Постоянно улучшать качество и скорость моделей с каждым релизом на всех доменах;
- Существенно ускорить модели и снизить их размер (за деталями — прошу в вики проекта или просто протестируйте модели сами);
- Довести размер самой маленькой модели до 26 мегабайт и снизить количество параметров менее 20М;
В ближайших планах:
- Продолжать работать над качеством;
- Плановый статус апдейт по синтезу речи;
- Опубликовать
xsmallмодель для английского языка; - Есть еще ряд идей, как сделать
xsmallмодель ее еще в 2-3 раза быстрее против прошлой (если считать на CPU) для английского языка без существенной потери качества. Она скорее всего будет примерно такого же размера; - Зарелизить модель для простановки знаков препинания и заглавных букв для четырех языков (русский, английский, немецкий, испанский);
- Возможно еще получится снизить размер
xsmallмодели еще в 2 раза;
Почему это важно и почему сделать просто так сложно
Тут не хотел бы повторяться, я довольно подробно все расписал в первой статье на Хабре тут, с тех пор мало что поменялось.
Ссылки
Вы всегда можете поддержать наш проект, поставив звезду на Github или прямыми донатами:
Проект silero-models почти набрал на Github тысячу звездочек, помогите нам преодолеть эту психологическую планку!