
В последнее время я полюбил слушать аудиокниги. Однако те книги, которые я хочу слушать никто не озвучивает. Не думаю что кому то будет интересна моя драматичная история о выборе лучшего tts, проблемы в процессе написания, солнце в монитор и т.п., так что я просто представлю вам уже готовое решение.
Возможно, кто то раскритикует мои навыки, но опережу всех вас - я в курсе своих проблем, но до сих пор у меня не возникало проблем с ориентированием в своих детищах, и пока все работает как нужно, я полностью доволен проделанной работой, а значит нет и необходимости что то исправлять. Тем более пока что я ни с кем не делился своими программами, не для кого делать дружелюбный код.
Учение о получении токена
Для использования нужен токен. Его можно получить на сайте https://gstatic.com/cloud-site-ux/text_to_speech/text_to_speech.min.html используя демо форму.
Для этого есть два варианта.
Легкий вариант.
После захода на сайт ввести в адресную строку
javascript: void window.addEventListener("cloud-demo-captcha-solved", function(ev){document.write(ev.detail.token)})После чего нажать на кнопку SPEAK IT и решить капчу. Если же у вас во весь экран напечаталась абракадабра - поздравляю, это и есть ваш токен, можете его спокойно использовать, остальные варианты можно пропустить.
Если у вас после этих манипуляций ничего не произошло то обновляйте страницу и открывайте консоль сочетанием клавиш Ctrl+Shift+I. После чего кликнуть на поле с синей стрелкой в самом низу и вставить туда следующий текст код:
void window.addEventListener("cloud-demo-captcha-solved", function(ev){document.write(ev.detail.token)})
После чего у вас во весь экран опять же напечатается токен, который можно использовать.
Сложный вариант.
Нужно после захода на страницу нажать сочетание клавиш Ctrl+Shift+I. После, в открывшемся меню нажимаете или сразу на вкладку Network, или нажимаете на две стрелочки вправо и выбираете этот пункт там:

После чего вы нажимаете на синюю кнопку "SPEAK IT". Скорее всего вас попросят решить капчу. Если же вас остановит отладчик, не отчаивайтесь. Достаточно всего лишь в открывшемся окне консоли нажать кнопки в такой последовательности:
Когда машина заговорит, нажмите еще раз на ту же синюю кнопку, что бы она заткнулась. Если описанное в абзаце выше произошло и вас перебросило на другую вкладку, возвращаемся на вкладку Network и вводим в поле фильтра, которое активно изначально, фразу "cxl-services" (естественно без кавычек). У вас останется единственный пакет, кликаем на него и сворачиваем в открывшемся поле все лишние заголовки кроме Query String Parameters, что бы не мешали (но вы можете и ручками пролистать до нужного поля). Ищем в Query String Parameters поле token, и копируем его значение.
Отступление. Я бы не стал так извращаться, если бы у меня получилось запустить сервисный аккаунт гугла. Но, к сожалению, для использования озвучки им необходима кредитка и много чего еще. Нет, спасибо.
Токен действует не вечно, через некоторое время его придется заменить, но на озвучку не одной книги должно хватить. Так же предупреждаю, если прогнать слишком много текста, google не будет отвечать некоторое продолжительное время на запросы с вашего ip, так что знайте меру. Куда вводить токен я расскажу далее.
Для работы боту требуется, как не странно, сама книга в текстовом формате без всяких украшений, чистый txt. Моя читалка спокойно позволяет экспортировать книгу в такой формат. Название самой книги задается в конфиге.
Где скачать
Так же прилагаю словарь ударений, позаимствованный с 4pda для одной из модификаций google tts. С некоторыми моими дополнениями. Небольшой неожиданный камень в огород хабра - почему нельзя загрузить файлы напрямую в статью? Почему я должен извращаться с загрузкой файла на сторонние сервисы? Ладно.
Продолжим. Все четыре файла должны лежать в одной директории со скриптом примерно так:
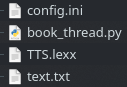
Если у вас что то не заработало, отправьте лог, возможно я исправлю. Использовался python 3.9.7.
Все четыре файла находятся на гитхабе, скачивайте оттуда: https://github.com/iron-blooded/book-voiceover
как скачать

После загрузки обязательно распакуйте. Так же в config.ini вам будет необходимо указать свой токен.
P.S. Если у вас в веб-форме невозможно выбрать язык, значит с вашего ip было слишком много текста. Вам остается только ждать, возможно даже день(я не замерял, просто вечером появлялось ограничение, а уже следующим вечером когда руки доходили, ограничения не было). У гугла есть какие то лимиты, но они нигде не указываются.
Комментарии (32)

ZodDZverev
04.10.2021 15:32+1Ого! Как раз мне прилетела задача озвучивать видосы разными языками по сгенеренным ранее субтитрам.
Спасибо, мил человек!
Можно твой код взять основу и немного переделать? Лицензия у него какая?

warm-blooded Автор
04.10.2021 15:37+2Лицензия свободная, писал сам с нуля, взять можно.
Но если намечается что то серьезное советую изменить метод запросов с костыля в виде пробной версии с недолговечным токеном на запросы с использованием токена своего собственного приложения. Сам я это не сделал потому что гугл хотел от меня слишком много лишних (на мой взгляд) данных.ZodDZverev
04.10.2021 16:47+1Дада, сегодня ночью буду гонять и ковырять. Я ничерта не знаю про Google TTS и никогда им не пользовался, хотел сегодня ночером начать погружаться в тематику.
Твой код прям супер в тему! Земной тебе поклон!
ZodDZverev
04.10.2021 16:50Слушай, маленький вопрос на счёт файла с ударениями.
А ты не видал где подобных же, но под разные другие языки, типа хинди, например?

Emelian
04.10.2021 19:48А сохранение перевода книги средствами Google и python мы умеем делать? Я могу, безо всяких токенов, но статью оформлять пока лень, да и есть опасения, что прикроют лавочку, если все начнут злоупотреблять ею.
Что до озвучки текста, то есть голосовые движки, которые можно найти в Интернете. Есть программы озвучки, типа «Балаболка». Для изучения иностранных языков, в принципе, неплохо. Вот мои некоторые эксперименты:
https://youtu.be/MWCMmgTUlDs
https://youtu.be/F4mD-2vf0k4
warm-blooded Автор
04.10.2021 21:10Пока что у меня не возникало потребности в переводе книг, так что нет. И если у вас есть способ использовать именно google tts без токена - прошу описать хотя бы принцип, буду благодарен.
Насчет голосовых движков - я пробовал другие, но мне больше всего зашел именно вариант от гугла, так что про него и статья.
Emelian
05.10.2021 08:41Речь шла об отсутствии токена для перевода текстов, хотя для больших объемов перевода он нужен. Выход был в автоматизации запросов, типа:https://translate.googleapis.com/translate_a/single?client=gtx&sl=auto&tl=ru&dt=t&tbb=1&ie=UTF-8&oe=UTF-8&q=СТРОКА_ТЕКСТА_В_URL_КОДИРОВКЕ, с помощью Питон.
Размер одного (get) запроса не более 10-15 КБ (я брал 7-8 КБ). Время паузы между запросами должно быть более 10 секунд (у меня было – 11).
На Питоне был написан бот, который считывает запросы из файлов (их может быть сотни, сами файлы формируются другим скриптом из текста оригинала) и отправляет их на сайт, с помощью «import requests», с определенной задержкой («import time»). Результаты приходят в формате json, с которыми можно работать через пакет, загружаемый «import json». Далее мы формируем вывод переведенного текста, так, как нам удобно.
Переводит этот сервис Гугла очень неплохо, поэтому я понимаю ваш интерес именно к Гугловскому инструментарию, хотя лично я сторонник живого звука.
Вполне допускаю, что озвучку коротких текстов Гугл может делать и без токена, так, как он делает перевод. Если это так, то можно воспользоваться предложенной идеей – посылкой автоматизированных запросов, с достаточными задержками между ними и обработкой полученных результатов. По крайней мере, 5000 символов Гугл озвучивает бесплатно, в браузере. Остается найти только соответствующую ссылку на API-сервис, как для перевода текста.warm-blooded Автор
05.10.2021 10:38+1Да, переводчиком гугл позволяет пользоваться без токена. Однако с tts ситуация иная, без токена он возвращает Bad Request. Как вы заметили, у гугла существует демо форма, но именно на основе того, что гугл позволяет озвучивать 5000 символов просто так, и функционирует мой код. Текст разбивается по 5000 символов и отправляется в ту демо-форму, откуда уже и получает результат, с последующим кодированием в звук.
Сама же ссылка на api выглядит так texttospeech.googleapis.com/v1test1/text:synthesize, и к ней обязательно поле токена, если оно будет например пустое выдаст Unauthorized. Совсем без него Bad Request. Как с переводчиком здесь никак не получается.
Emelian
05.10.2021 12:30Ну, в принципе, вы свою проблему решили, как и я свою. Но, что мне нравиться в переводе Гугла, то, что можно переводить художественные книги, например, французских авторов. Иногда существующий литературный перевод, например, для «Красной лилии», Анатоля Франса местами выглядит хуже, чем перевод от Гугла. Для изучения языка это самое то. А живой озвучки более, чем достаточно на Ютубе.

ruraic
05.10.2021 07:07А годится ли это решение для озвучки ходожественных книг? Можно ли пример послушать?
warm-blooded Автор
05.10.2021 07:21Как по мне, для художественных книг подходит только если улучшать словарь. Да и подавляющее большинство уже озвучены, не обязательно использовать tts. Но тройку книг залил - скачать.
ruraic
05.10.2021 12:18Послушал ваши примеры - по-моему очень хорошо. Во всяком случае - сильно лучше, чем читают некоторые "декламаторы"-любители. Разве что, на мой вкус, темп немного увеличить.
Если можно, выложите сам файл скрипта куда-нибудь, на тот же гугл-диск. Возникли пробемы с кодировками, писал Вам в ЛС. Возможно, если не перегонять его через буфер этих проблем не будет.

boojum
05.10.2021 12:28+1Немного более простой путь получения токена:
Открываем в браузере https://gstatic.com/cloud-site-ux/text_to_speech/text_to_speech.min.html
-
в строку url вводим
javascript: void window.addEventListener("cloud-demo-captcha-solved", function(ev){document.write(ev.detail.token)})(на странице после этого ничего не меняется)
Жмем "SPEAK IT", после решения капчи на странице отображается токен.
ruraic
05.10.2021 12:47Сработало после вставки в Консоль. Со строкой url не получилось. (Пробовал в Chromium 93)
boojum
05.10.2021 13:58В строку url нельзя вставить из буфера обмена "javascript:" - оно удаляется при вставке по соображениям безопасности. Надо его вручную дописывать.
Думаю из за этого не получилось.
warm-blooded Автор
05.10.2021 15:12Смотря где. Например у меня в браузере для этого есть настройка, так что код работает.
KobaWhite
05.10.2021 13:11nameBook=str(configF['book']['nameBook'])getitem raise KeyError(key) KeyError: 'book'
выдает ошибку
warm-blooded Автор
05.10.2021 13:13У вас в папке со скриптом присутствует файл конфига? Возможно в нем вы стёрли первую строку? Посмотрите в конце статьи скриншот, в нем видно какие файлы должны быть в одной папке.
KobaWhite
05.10.2021 13:16config.ini на месте и [book] в начале файла присутствует
warm-blooded Автор
05.10.2021 14:33+2Залил файлы на гитхаб, попробуйте использовать их: https://github.com/iron-blooded/book-voiceover
ZodDZverev
05.10.2021 23:32Еще замечание, бро.
Перед вызовом малтипроцессинга куда-то в район строки 172 нехудо бы сунуть родное
if __name__ == '__main__', а то оно будет свинить.
ZodDZverev
06.10.2021 15:56Слушай, бро. Ну, получается относительно неплохо, хотя не хватает в тексте пауз порой.
Однако, у меня на выходе звуковое файло почему-то крякает порой. У тебя такое было? Это на моей стороне косяк, или так гугль работает?
warm-blooded Автор
06.10.2021 16:55Такого у себя не замечал. Возможно, у вас в тексте какие то лишние символы? Попробуйте так же сгенерировать аудио под тем же порядковым номером, в конфиге можно указать откуда начинать, и послушать на наличие посторонних звуков.
ruraic
06.10.2021 17:21У меня проблема с паузами возникает в диалогах. Почему-то при наличии тире, после точки паузы нет совсем. Но если тире нет, а просто после точки идет новая строка - все паузы расставляет корректно. Удалил регуляркой все тире в прямой речи - паузы появились и диалоги читает хорошо.
Еще движок путается с е/ё - пришлось пройтись поиском и руками заменить где надо черт/чёрт и подобные слова.
У меня файлы не крякают - хотя не все могут их открыть. vlc, mpv открывает нормально, а вот audacious - нет. Вместо звука дикий писк
Javian
Предполагается, что проект размещается где-то на GitHub, например.
mikprin
Можно было действительно оформить в виде репозитория на github. Прибавить установочный или requerments файл, снабдить немного документацией там (хотя бы пример базового использования функций) и уже глядишь готовый полезный тул, чтобы упрощать людям жизнь!
MentalBlood
А если еще в pypi залить, можно будет вообще
Не хочу быть душным, просто это реально максимально упрощает установку и использование
warm-blooded Автор
Спасибо за совет, но у меня особо функций и нет, все выполняется сразу после запуска и не спрашивает пользователя.
Возможно, когда нечем будет занять руки я опубликую код и на гитхабе.