


Дмитрий Дорофеев
Автор перевода
Вступительное слово переводчика: Разрыв между смыслом оригинала и перевода
Думаю, многие согласятся, что современный русский язык находится под постоянным давлением со стороны английского в части заимствований. Мы уже обыденно произносим и понимаем фразы типа «когда юзер пытался залогиниться через АДэ, в браузере что-то заглючило, надо винду ребутнуть, наверное». Так получается короче, быстрее, но, кажется, это может плохо кончиться в итоге. Эллочка-людоедка, новояз Оруэлла и бейсик-инглиш Огдена, ю ноу. Корень проблемы в корнях. И мы теряем корни в буквальном смысле слова. Свои корни теряем, а чужие нам не позволяют правильно понимать смысл слов. Поясню на примере.
О чём говорят люди, когда обсуждают Data Governance и Data Management на русском? Давайте разбираться.
Есть в английском два слова примерно об одном и том же: «governance» и «management». При этом «governance» однокоренное с «government» (правительство). Аналогично, в русском языке есть два самых употребляемых слова на эту тему: «управление» и «руководство». При этом, «управление» — однокоренное со словом «правительство». Кроме того, слово «management» восходит к латинскому «manus» (рука), а «руководство» прямо содержит в себе корень слова «рука».
С точки зрения корней, логично переводить «governance» как «управление» (отсылка к «правительству»), а «management» как «руководство» (отсылка к «руке»).
А с точки зрения взаиморастворения культур не всё так однозначно, ибо у них есть «data management» и отдельно «data governance», и всем понятно, что это разные вещи. Там люди чётко понимают, что «governance» выше, чем «management». А у нас редкий человек объяснит, чем «управление» отличается от «руководства». Вот и получается, что использовать Data Governance и Data Management в русском очень трудно, особенно так, чтобы тебя поняли.
И это не только у меня трудности:

Хочу отметить, что «Распорядитель» — это достойный перевод для «Steward», а вот пояснения про «data governance» и даже ссылки на сам DMBOK2 меня не убедили, как впрочем и большинство докладчиков на семинарах АПУД, которые переводят «data governance» как «управление данными», либо оставляют Data Governance вообще без перевода.
Раннюю стадию становления лексикона в области управления данных наблюдаю я, и, равняясь на пример Петера Наура, хочу возглавить движ поучаствовать в этом. Петер ещё в 1966 году подумал, как мы там в 2021-ом будем общаться, и предложил новое слово - Datalogy. Жаль, что оно не прижилось и мы пользуемся двумя словами Data Science из бейсик-инглиш, а могли бы обойтись одним.
Naur, P. (1966). The science of datalogy. Communications of the ACM, 9(7), 485. doi:10.1145/365719.366510

А я в 2021 году предлагаю ввести в оборот слово «Датавед», означающее «Data Scientist». Корень «дат» — это калька с латинского «data» (мн.ч. от «datum»), а корень «вед» не нужно объяснять русскому читателю. Также предлагаю новое слово — «Датецкий», созданное по аналогии со словом «дворецкий» и это перевод для «Data Steward». Надеюсь, получилось коротко, понятно и с сохранением исконного смысла. Если у вас эти слова вызывают улыбку, то добро пожаловать в подвал статьи, к опросникам. Посмеёмся и поплачем вместе.
Терминология
Citizen Data Scientist — Гражданский Датавед
Data Scientist — Датавед
Data Analyst — Аналитик Данных
Data Discovery — Разведка (поиск) Данных
Data Governance — Управление Данными
Data Steward — Датецкий (по аналогии с «дворецкий»)
Слово Марку Гроверу
Все последние инновации в области работы с данными произошли в двух направлениях: помощи инженерам данных в производстве данных и помощи потребителям данных (в первую очередь, Аналитикам данных и Датаведам) в обработке данных. Данные в хранилищах и озерах данных переливаются через край, но потребители до сих пор не знают, какая именно информация доступна и каким данным можно доверять. Это незнание превращает озёра данных в болота данных.
Однако наибольшие затруднения в организациях, использующих большие объемы данных, связаны не с производством или потреблением, а с разведкой и обработкой данных. Пользователи постоянно терзают инженеров данных вопросами, а тем надо успевать предоставлять данные вовремя и с надлежащим качеством. Аналитики данных и Датаведы тратят очень много времени, отвечая на вопросы о надежности источников данных, о том, как они обычно используются, как они производятся, подтверждая, что это именно тот источник, который нужен пользователям. В компании Lyft аналитики тратили более 30% своего рабочего времени на разведку и проверку достоверности данных. Аналогичная ситуация наблюдается во многих других компаниях.
Эта проблема настолько масштабна и не изучена, что я ушел из Lyft, чтобы помочь другим компаниям найти верное решение. Далее я подробно расскажу о причинах моего поступка.
Как мы оказались в этой ситуации?
Инновации в приеме, обработке и хранении данных привели к упрощению процесса производства исходных и производных данных. Конечный результат: ещё больше данных для потребления, управления и защиты.
Что касается потребления, то организации демократизируют доступ к данным для пользователей, которым ранее потребовалось бы для этого больше специальных знаний. Все больше и больше сотрудников, работа которых не основывалась на обработке данных или которым для использования данных приходилось обращаться в разрозненные хранилища, теперь могут работать с (сырыми) данными напрямую. По мере того, как все больше организаций проходят через процесс цифровизации, число таких пользователей будет только увеличиваться. Данную категорию пользователей можно назвать Гражданскими Датаведами.

Источник картинки — журнал Gartner, автор статьи — Carlie Idoine
Во всех современных технологических компаниях, использующих большие объемы данных, таких как Lyft, Airbnb, Uber, Google, работают Гражданские Датаведы. Будущее за Гражданским Датаведением! (Citizen Data Science).
Простота производства данных и демократизация доступа к данным привели к возникновению двух новых проблем, которых раньше не существовало.
Две новые проблемы в разрыве между производством и потреблением данных
Если к постоянно растущим данным организации обращается большее число Гражданских Датаведов, то это приводит к возникновению двух новых проблем:
Разведка данных и доверие к ним
Управление данными
Проблема 1. Разведка данных и доверие к ним
В мире, где данные используются постоянно растущим количеством людей, встречаются пользователи, которые не используют эти данные изо дня в день. В таких случаях контекст, необходимый для доверия данным, гораздо шире, что приводит к возникновению огромного барьера, который необходимо преодолеть.
Возьмем, к примеру, современную организацию по обработке данных, такую как Lyft. Когда Датавед создает новую версию модели ETA (ожидаемого времени прибытия), он должен проверить ее производительность в сравнении с существующей моделью. В такой компании, как Lyft, существует от 50 до 100 столбцов (если не больше), связанных с ETA, часто разбросанных по разным хранилищам данных. Поиск ответов на вопросы о том, что является источником правды для ETA, заполняется ли он на постоянной основе, как он вычисляется, кто или что еще использует его, как часто он обновляется, как он обычно используется и т. д., — это большая потеря времени. И это только вопросы поверхностного уровня, не говоря уже о том, что одни и те же данные могут поступать из разных источников (например, ETA от разных поставщиков геоданных), означают разные вещи в разных контекстах (ETA измеряется перед запросом на поездку, во время поездки или по факту) или имеют разное использование (ETA, отображаемое для водителей/пассажиров, в сравнении с алгоритмически используемым для принятия решений). Это серьезный барьер для Гражданских Датаведов и огромный отвлекающий фактор для инженеров данных.
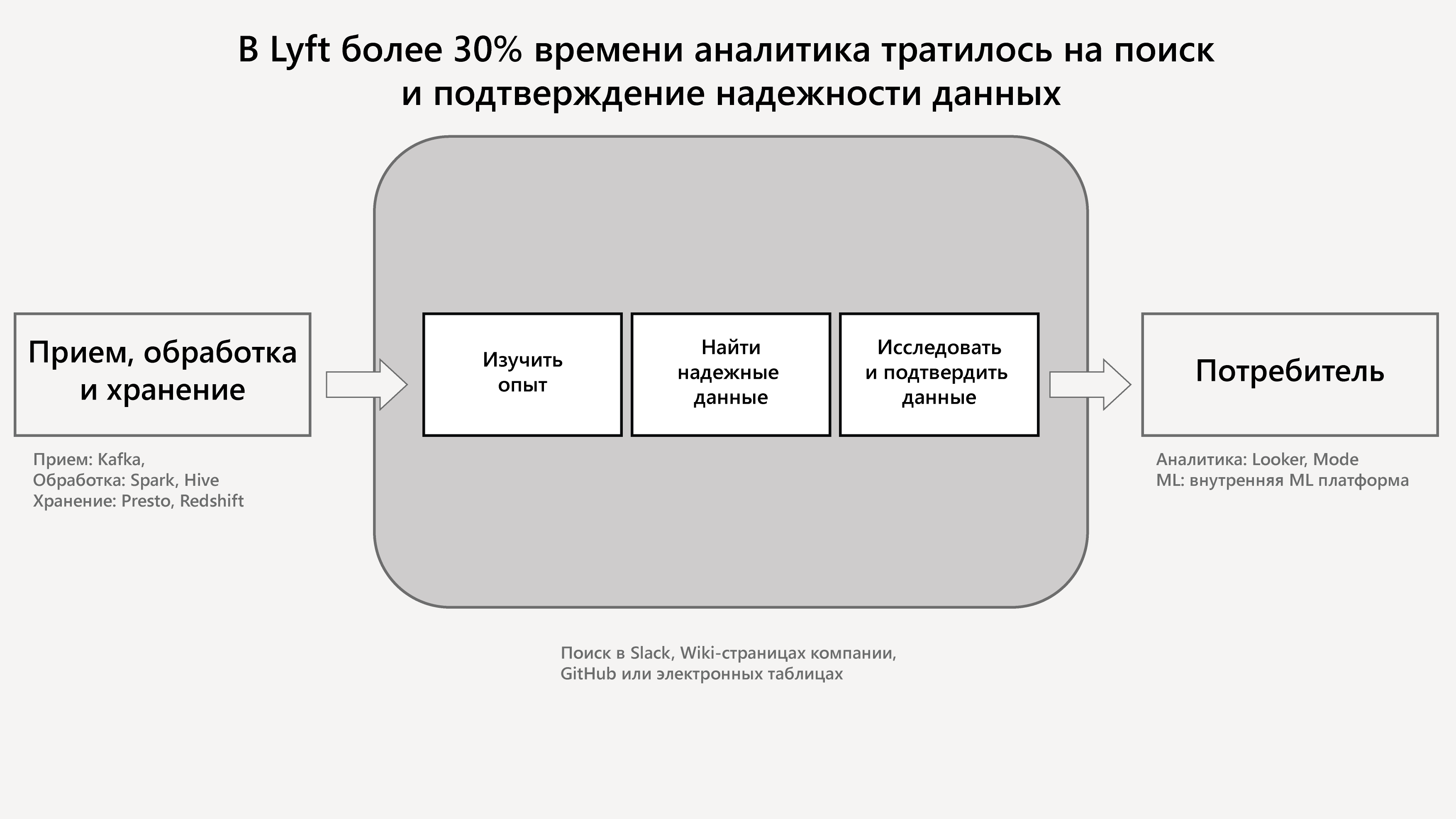
Для разведки данных и проверки их достоверности не нужны идеальные данные. Нужен контекст, поясняющий недостатки.
Так что же это за недостатки и каков их контекст? К примерам можно отнести проверку того, что данные всё ещё поступают из источника, проверку отсутствия слишком большого количества нулей или противоречивых значений, более широкое понимание того, что содержит таблица или столбец, как он формируется, используется и т. д.
Как пользователи находят контекст, поясняющий недостатки? Они используют устаревшие страницы корпоративной Wiki, расспрашивают коллег, угадывают самостоятельно, просматривают лог-файлы, выполняют специальные запросы по данным, чтобы найти достоверные данные. В конечном итоге пользователи пишут и повторяют одни и те же специальные запросы, тратя драгоценное время и ресурсы. Исторически для решения этой проблемы полагались на сотрудников. Иногда для таких сотрудников вводились официальные должности, например Датецкий. Иногда это просто добровольцы. Как показывает практика, такое решение крайне малоэффективно, потому что либо пользователи отвлекаются от своих основных задач, чтобы документировать наборы данных, либо у них нет контекста для всех видов использования данных, либо и то, и другое. Плюс к тому, документация, конечно, устаревает.
Ключом к решению этой проблемы является платформа метаданных, которая автоматически захватывает эти метаданные и является основой для построения других систем. Такая платформа должна соответствовать основным принципам работы с метаданными (ABC):
Контекст использования (Application Context) — что из себя представляют данные, где они находятся, какова их форма или параметры и т. д.;
Поведение (Behavior) — кто производит и потребляет эти данные (люди и программы);
Изменение (Change) — история изменений данных и кода, который производит данные.
Для более полного погружения в основы метаданных, можете посмотреть основополагающую работу Джо Хеллерштейна и Викрама Стриканти.
Тем временем на сцену выходит новый стек данных. Этот стек использует Stitch/Fivetran и Kafka для приема данных, Airflow для оркестрации, озеро данных для обработки, облачное хранилище данных (например, Snowflake или BigQuery) для обслуживания запросов, а также Looker/Tableau для конечного потребления.
Хорошая новость заключается в том, что этот новый стек данных позволяет автоматически получать метаданные, что дает возможность Гражданским Датаведам эффективно искать нужные данные и быть уверенными в их достоверности.
Чтобы находить данные и быть уверенными в их достоверности, вам нужна платформа метаданных, которая бы автоматически захватывала метаданные о данных и предоставляла контекст, поясняющий недостатки данных.
Проблема 2. Управление данными
Второй проблемой в организациях с большим количеством пользователей является обеспечение безопасности и конфиденциальности данных компании, а также соблюдение правил, включая, в частности, правила защиты данных (например, GDPR, CCPA), а также отраслевые правила (например, в секторе здравоохранения или финансовых услуг). Более того, крупным организациям недостаточно просто соблюдать правила. Они несут более высокие обязательства по поддержанию высокой репутации бренда и выполнению программы социальной ответственности.
Текущие процедуры Управления Данными в организациях, как правило, характеризуются избыточной работой в ручном режиме или состоят из высокоуровневых общих политик. По мере того, как регуляторные нормы становятся более строгими, как, например, в Калифорнии, где был принят проект Prop 24 в качестве дополнения к Закону о защите персональных данных потребителей (ССРА), текущие практики Управления Данными требуют серьезных изменений.
Помните, мы упоминали датецкого и армию добровольцев? Изначально продукты в области метаданных были построены на этих концепциях. Неудивительно, что у них крайне низкий индекс потребительской лояльности (NPS), низкий уровень внедрения и использования, и они, как правило, осуждаются разработчиками и пользователями за то, что создают больше проблем, чем решают.
Будущее управления данными заключается в более глубоком понимании того:
какие данные есть у организации и где они хранятся
кто смотрел эти данные, зачем и когда
Кто смотрел данные, зачем и когда.
Хорошая новость заключается в том, что это те же самые метаданные, которые были описаны в предыдущем разделе и которые помогают нам искать данные и оценивать степень их достоверности. Мы можем использовать одни и те же метаданные, чтобы помочь организациям получить более глубокое понимание своих данных и облегчить им защиту доступа к ним, а также обеспечить соответствие нормативным требованиям. Более подробно об этом читайте в следующей публикации.
Для того, чтобы управлять данными, с учетом постоянно меняющихся потребностей, конечно, очень важно более глубокое понимание, что именно находится в ваших данных и где находятся те данные, что вам нужны, когда, кем и почему они подготовлены. Ответы на все эти вопросы с технической точки зрения входят в категорию метаданных и должны использоваться для того, чтобы пользователь мог не только найти данные, но и доверять им.
Что дальше?
Мы создали Amudsen как раз для того, чтобы решить обозначенные выше две проблемы — проблема конечного пользователя (разведка нужных данных и доверие к данным), а заодно и задачу любой организации (Управление Данными). В настоящее время Amudsen используют более 700 сотрудников Lyft каждую неделю, а также он используется в 28 других компаниях, среди которых ING, Square и Instacart, сообщество Slack с более чем 1000 пользователей. Заслуга в этом конечно и команды разработчиков Amudsen и многих людей в десятках компаний, которые вносят свой вклад в развитие Amudsen. Мы бы перечислили их имена, но не делаем этого из-за боязни забыть кого-то, кто тоже внес свой существенный вклад.
Amudsen явился первым большим шагом в появлении платформы метаданных на рынке. Lyft как компания имеет прекрасную культуру управления данными и много инвестировал в решение проблем с данными, которые не уникальны для Lyft и типичны для многих компаний. Чем больше я работал над Amudsen, тем яснее мне становилось, что эти проблемы с данными широко встречаются также и в других корпорациях.
Я принял решение покинуть Lyft, чтобы помочь решить эти проблемы всех других компаний.
Я благодарен руководству Lyft которое дало мне возможность и ресурсы глубже понять проблему и создать Amudsen. Также я благодарен кросс-функциональной команде Amudsen, которая без устали трудилась, чтобы сделать проект таким, какой он есть сегодня.
Мы вместе с Дорианом создали Stemma, чтобы помочь пользователям эффективно искать нужные данные и доверять данным, а также, чтобы помочь организациям обеспечить защиту, приватность и безопасность данных. Stemma и лично я привержены принципам открытого исходного кода и нацелены на развитие Amundsen. Мы продолжим инвестировать время и ресурсы в развитие Amundsen, чтобы дать производителям и потребителям данных новые возможности в работе с данными. Я с нетерпением жду будущего и того, как Amundsen сможет помочь организациям лучше управлять данными, обеспечивая при этом конфиденциальность и безопасность.
Вы можете получить больше информации про Amundsen в этом блоге.
Комментарии (5)

GospodinKolhoznik
04.10.2021 21:55+2Давно уже думаю о том, что приставка ист в слове программист тоже не очень то русская. Програмарь гораздо лучше.


citizen55
Вы из разряда редких людей, к сожалению большинство людей участвует а превращении родного языка в суржик, не особо задумываясь над этим. Насчет, Data Steward, на мой взгляд все варианты не очень.
deem0n Автор
Я сам не в восторге от вариантов, используем лучших из худших ;-) Но может быть, кто-то из хабражителей предложит стоящий вариант? Призываю коллективный разум!
citizen55
Русский язык искалечен, в этом плане. В современной версии языка словообразование затруднено. Вы не можете как раньше, только для примера, используя слово воз(вз)(аналог английского up) легко изменять значение. Смотрите как раньше это было легко и просто возраст, воспитать, возврат, взрыв, воздух и так далее. Сейчас почему то в слове воздух, воз входит в корень, в в слове взлет, в приставку. Слова постарались жестко зафиксировать в определенной форме, выхолостить значение особо часто употребляющихся слов, служивших для придания новых смыслов.