

Привет, друзья!
Недавно (где-то в конце августа) у MDN появился новый (крутой, по заявлению разработчиков) поиск.
Речь идет об этом виджете на главной странице:

Основной код виджета находится здесь, а все остальное, кроме данных для поиска, можно найти здесь.
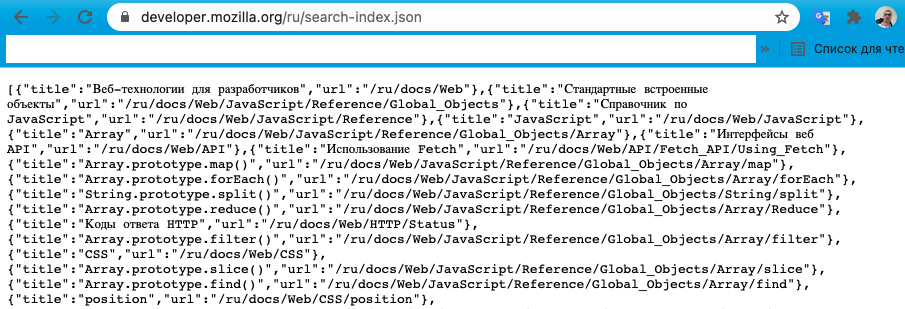
Данные для поиска также найти не сложно — для этого достаточно добавить к https://developer.mozilla.org локаль, например, /ru и /search-index.json:
Код поиска написан на React и TypeScript. Что это означает? Это означает, что мы с вами можем провести его обратную разработку.
Если вам это интересно, прошу следовать за мной.
Обратите внимание: данная статья рассчитана на разработчиков, которые имеют некоторый опыт работы с React. Желательно также иметь хотя бы общее представление о TypeScript.
Для удобства я вынес весь код, связанный с поиском в отдельный проект, исходный код которого находится здесь.
Практически каждая строка кода проекта снабжена подробным комментарием.
Скриншот проекта:
Команды для локального запуска проекта:
git clone https://github.com/harryheman/mdn-search-clone.git
cd mdn-search-clone
yarn
yarn startОбщая логика поиска MDN такова:
- Когда пользователь заходит на главную страницу сайта, мы показываем ему упрощенную версию поискового виджета (болванку). Это избавляет пользователя от загрузки лишних данных в случае, когда он не будет пользоваться поиском
- Когда пользователь выражает намерение воспользоваться поиском, мы выполняем инициализацию поискового индекса и заменяем болванку на настоящий виджет
- Намерение пользователя воспользоваться поиском определяется по наведению курсора на виджет или установке фокуса на инпут с помощью клавиатуры или при нажатии
/ - Инициализация поискового индекса начинается с получения данных для поиска с помощью хука
useSWRизSWRна основе локали пользователя, которая содержится вURI(например,https://developer.mozilla.org/ru) - Файл с данными для поиска называется
search-index, имеет форматJSONи представляет собой массив объектов с двумя полями — заголовком и адресом статьи, например,{ title: 'Веб-технологии для разработчиков', url: '/ru/docs/Web' } - Сам поиск выполняется после нажатия пользователем клавиши
Enterи может быть двух видов:- поиск по
url— для этого используетсяFzf(я перевел "fuzzy search" как "неточный поиск", но не уверен, что это правильно). Данный поиск выполняется, когда строка для поиска начинается с/и не содержит пробелов - поиск по
title— для этого используетсяFlexSearch(полнотекстовый поиск)
- поиск по
- После получения результатов поиска мы рендерим их с помощью хука
useComboboxиз [Downshift] — это обеспечивает доступность выпадающего списка - При наведении пользователем курсора на результат поиска, мы начинаем загрузку данных для соответствующей статьи (
prefetching) - При клике пользователем по результату поиска, мы перенаправляем его на страницу соответствующей статьи
- Статья для предварительной загрузки и перенаправления определяется с помощью
Downshift - При нажатии пользователем
Enterпосле ввода строки для поиска, мы перенаправляем его на страницу поиска - Если для строки поиска не найдено совпадений, мы сообщаем об этом пользователю и предлагаем ему перейти на страницу поиска
Отличия проекта от оригинала состоят в следующем:
- Отсутствует получение локали пользователя для формирования адреса статьи, поскольку мы работаем только с одной локалью —
ru - Вместо переключения страниц выполняется открытие страницы на сайте
MDNв новой вкладке браузера - Отсутствует предварительная загрузка данных для статей, поскольку у нас нет этих данных
- Я не стал скрывать кнопку для очистки инпута, предоставляемую
Donwshift, под иконкой лупы (синий крестик), как это сделано в оригинале - Я добавил обработчик нажатия кнопки для отправки формы (лупа) (в оригинале эта кнопка не работает)
Вместе с тем, я сохранил оригинальный код в закомментированном виде (и комментарии разработчиков поиска), кроме кода для prefething.
Рассмотрим, как работает поиск.
С вашего позволения, я немного упрощу оригинальный код.
Сначала мы получаем данные:
// Индикатор начала инициализации
const [shouldInitialize, setShouldInitialize] = useState(false)
// Поисковый индекс
const [searchIndex, setSearchIndex] = useState(null)
// Адрес данных для поиска
const url = `/search-index.json`
const { error, data } = useSWR(
shouldInitialize ? url : null,
async (url) => {
// Получаем ответ
const response = await fetch(url)
if (!response.ok) {
// Если возникла ошибка, выбрасываем исключение
// с сообщением в виде текста
throw new Error(await response.text())
}
// Возвращаем ответ в формате `JSON`
return await response.json()
},
// Отключаем повторную валидацию - выполнение повторного запроса при возвращении фокуса
{ revalidateOnFocus: false }
)Такая сигнатура хука включает режим ожидания — useSWR ждет начала инициализации. Другими словами, он запустится автоматически, как только shouldInitialize получит значение true. К слову, для отключения повторной валидации (revalidation) при возвращении фокуса и в некоторых других случаях в последних версиях SWR предназначен хук useSWRImmutable из swr/immutable.
Далее с помощью полученных данных инициализируется поиск:
// Мы подробно рассмотрим каждый вид поиска ниже
const flex = new FlexSearch.Index({ tokenize: 'forward' })
data.forEach(({ title }, i) => {
flex.add(i, title)
})
// Обертка над `fzf`
const fuzzy = new FuzzySearch(data)
setSearchIndex({ flex, fuzzy, items: data })Логика инициализации поискового индекса инкапсулирована в хуке useSearchIndex:
function useSearchIndex() {
// Получение данных и инициализация индекса
return useMemo(
() => [
searchIndex,
error || null,
() => setShouldInitialize(true)
],
[searchIndex, error, setShouldInitialize]
)
}Как мы видим, хук возвращает массив, состоящий из поискового индекса, ошибки, которая может иметь значение null, и функции для запуска инициализации.
Остановимся на том, как работает каждый вид поиска.
Для определения того, какой поиск следует использовать (неточный или полнотекстовый) применяется такая функция:
function isFuzzySearchString(str: string) {
// Данная функция возвращает `true`,
// если строка начинается с `/` и не содержит пробелов
return str.startsWith('/') && !/\s/.test(str)
}Рассмотрим работу fzf и flexsearch на практических примерах.
Предположим, что у нас имеются такие данные для поиска:
const data = [
{
title: 'Веб-технологии для разработчиков',
url: '/ru/docs/Web'
},
{
title: 'Стандартные встроенные объекты',
url: '/ru/docs/Web/JavaScript/Reference/Global_Objects'
},
{
title: 'Справочник по JavaScript',
url: '/ru/docs/Web/JavaScript/Reference'
},
{
title: 'JavaScript',
url: '/ru/docs/Web/JavaScript'
},
{
title: 'Array',
url: '/ru/docs/Web/JavaScript/Reference/Global_Objects/Array'
}
]И мы хотим выполнять поиск по url объектов.
Для этого отлично подойдет fzf:
import { useState } from 'react'
// yarn add fzf
import { Fzf } from 'fzf'
const data = [
{
title: 'Веб-технологии для разработчиков',
url: '/ru/docs/Web'
},
{
title: 'Стандартные встроенные объекты',
url: '/ru/docs/Web/JavaScript/Reference/Global_Objects'
},
{
title: 'Справочник по JavaScript',
url: '/ru/docs/Web/JavaScript/Reference'
},
{
title: 'JavaScript',
url: '/ru/docs/Web/JavaScript'
},
{
title: 'Array',
url: '/ru/docs/Web/JavaScript/Reference/Global_Objects/Array'
}
]
// Форматируем данные подобно тому, как это сделано в оригинале
const formattedData = data.map(({ title, url }) => ({
title,
url: url
.split('/')
.slice(1)
.filter((i) => i !== 'docs')
.join(' / ')
}))
/*
Было, например, `/ru/docs/Web/JavaScript`,
стало `ru / Web / JavaScript`
*/
// Создаем экземпляр `fzf`
// Конструктор принимает данные для поиска и объект с настройками
const fzf = new Fzf(formattedData, {
// Количество возвращаемых (лучших) результатов
limit: 3,
// Поле для поиска
selector: (item) => item.url
})В документации fzf имеется пример реализации подсветки совпадения:
// `url` - это совпавшая строка
// `positions` - набор индексов совпавших символов
const HighlightChars = ({ url, positions }) => {
const chars = url.split('')
const nodes = chars.map((char, i) => {
if (positions.has(i)) {
return <b key={i}>{char}</b>
} else {
return char
}
})
return <>{nodes}</>
}Простой компонент для поиска:
export const FzfSearch = () => {
// Строка для поиска
const [value, setValue] = useState('')
// Результаты
const [results, setResults] = useState([])
const search = (e) => {
e.preventDefault()
// Выполняем поиск
const results = fzf.find(value.trim())
// console.log(results)
/*
[
{
item: {
title: 'Стандартные встроенные объекты',
url: 'ru / Web / JavaScript / Reference / Global_Objects'
},
positions: Set(4) { 14, 13, 12, 11 },
start: 11,
end: 15,
// чем выше `score`, тем лучше
score: 104
},
// ...
]
*/
// Обновляем результаты
setResults(results)
}
return (
<>
<form onSubmit={search}>
<input
type='text'
value={value}
onChange={(e) => setValue(e.target.value)}
/>
<button>Search</button>
</form>
<ul>
{results.map((result, i) => (
<li key={i}>
<HighlightChars
url={result.item.url}
positions={result.positions}
/>
</li>
))}
</ul>
</>
)
}Если ввести в инпуте java и нажать Enter, результат будет таким:

Почему бы для такого поиска не воспользоваться методом String.prototype.includes()? Хороший вопрос.
Насколько я понимаю, fzf выигрывает в производительности при большом количестве объектов для поиска и при больших (длинных) значениях строки для поиска. Кроме того, он умеет определять наличие в строке искомых символов, которые находятся в разных местах строки. Например, предположим, что у нас имеется строка aaYbbbbXccc и мы ввели в инпуте yx. Такая строка будет обнаружена fzf, но не методом includes(), поскольку символы y и x не следуют друг за другом.
Но, если наши объекты отсортированы по популярности, как в search-index.json, то при длине строки для поиска менее 4 символов (<= 3), как утверждают разработчики поиска, выборка подходящих объектов с помощью метода includes() будет более быстрой, чем исследование каждого объекта с помощью fzf.
Вот почему для поиска используется "оптимизирующая" обертка над fzf. Оптимизация заключается в том, что мы сокращаем список объектов, передаваемых в конструктор fzf.
import { Fzf, FzfResultItem } from 'fzf'
// Тип для результата поиска
export interface Doc {
url: string
title: string
}
// Класс-обертка для поиска
export class FuzzySearch {
// Данные для поиска
docs: Doc[]
constructor(docs: Doc[]) {
// Инициализация данных для поиска
this.docs = docs
}
// Метод для поиска
// Принимает строку для поиска и объект с настройками:
// настройкой по умолчанию является
// ограничение на 10 элементов (см. ниже)
search(needle: string, { limit = 10 }): FzfResultItem<Doc>[] {
// Use `let` because we might come up with a new list (aka. shortlist)
// that makes the haystack search much simpler to send to `Fzf()`.
// Используем `let`, поскольку список переданных объектов (данных для поиска)
// в случае, когда строка состоит менее чем из 4 символов,
// будет сокращен
let docs = this.docs
// The list of docs is possible over 10,000 entries (in 2021). If the
// search input is tiny, don't bother with the overhead of Fzf().
// Because we don't even need it when the test is so easy in that
// it just needs to contain a single character.
// Количество объектов для русской локали по состоянию на 24.10.2021 составляет 2910.
// Если строка для поиска состоит менее чем из 4 символов
if (needle.length <= 3) {
const needleLowerCase = needle.toLowerCase()
// The reason this works and makes sense is because the `this.docs` is
// already sorted by popularity.
// So if someone searches for something short like `x` we just take
// the top 'limit' docs that have an `x` in the `.url`. This is
// faster than going through every doc with Fzf.
// Причина, по которой это работает, состоит в том,
// что объекты `this.docs` уже отсортированы по популярности.
// Поэтому если строка для поиска состоит, например, из `x`,
// мы просто берем 10 первых документов, в которых встречается `x`.
// Это быстрее, чем исследование каждого документа с помощью `Fzf`.
// Создаем переменную для сокращенного списка
const shortlistDocs: Doc[] = []
// Перебираем данные для поиска
for (const doc of this.docs) {
// Если в документе встречается строка для поиска (без учета регистра)
if (doc.url.toLowerCase().includes(needleLowerCase)) {
// Помещаем документ в сокращенный список
shortlistDocs.push(doc)
// Прекращаем перебор при достижении лимита
if (shortlistDocs.length === limit) {
break
}
}
}
// Suppose the needle was `yx` and the `limit` as 10, then if we only found
// 9 (which is less than 10) docs that match exactly this, then we might
// be missing out, so we can't use the shortlist.
// For example, there might be more docs like `aaYbbbbXccc` which
// will be found by Fzf() but wouldn't be find in our shortlist because
// the two characters aren't next to each other.
// Предположим, что строка имеет значение `yx`, а `limit` - 10,
// если мы обнаружили только 9 (т.е. менее 10) подходящих документов,
// то не можем использовать сокращенный список.
// Предположим, что в документе имеется строка `aaYbbbbXccc`.
// Такая строка будет обнаружена `Fzf`, но ее не будет в нашем сокращенном списке,
// поскольку символы `y` и `x` не следуют друг за другом.
// Используем сокращенный список, только если его
// длина превышает или равняется лимиту
if (shortlistDocs.length >= limit) {
docs = shortlistDocs
}
}
// Создаем экземпляр поиска
const haystack = new Fzf(docs, {
// Лимит
limit,
// Поле для поиска
selector: (item: Doc) => item.url
})
// All longer strings, default to using the already initialized `Fzf()` instance.
// Для более длинных строк используется существующий экземпляр поиска
return haystack.find(needle)
}
}Отлично. С fzf разобрались.
В остальных случаях (когда строка запроса начинается не с / или содержит пробелы) выполняется поиск по title. Для этого используется полнотекстовый поиск.
import { useState } from 'react'
// yarn add flexsearch
import { Index } from 'flexsearch'
const data = [
{
title: 'Веб-технологии для разработчиков',
url: '/ru/docs/Web'
},
{
title: 'Стандартные встроенные объекты',
url: '/ru/docs/Web/JavaScript/Reference/Global_Objects'
},
{
title: 'Справочник по JavaScript',
url: '/ru/docs/Web/JavaScript/Reference'
},
{
title: 'JavaScript',
url: '/ru/docs/Web/JavaScript'
},
{
title: 'Array',
url: '/ru/docs/Web/JavaScript/Reference/Global_Objects/Array'
}
]
const flex = new Index({ tokenize: 'forward' })
data.forEach(({ title }, i) => {
flex.add(i, title)
})
// Реализация подсветки совпадения из оригинала
const HighlightMatch = ({ title, q }) => {
const words = q.trim().toLowerCase().split(/[ ,]+/)
const regexWords = words.map((s) => s.replace(/[.*+?^${}()|[\]\\]/g, '\\$&'))
const regex = `\\b(${regexWords.join('|')})`
const parts = title.split(new RegExp(regex, 'gi'))
return (
<>
{parts.map((part, i) => {
const key = `${part}:${i}`
if (words.includes(part.toLowerCase())) {
return <mark key={key}>{part}</mark>
} else {
return <span key={key}>{part}</span>
}
})}
</>
)
}
// Компонент поиска
export const FlexSearch = () => {
const [value, setValue] = useState('')
const [results, setResults] = useState([])
const search = (e) => {
e.preventDefault()
const indexes = flex.search(value, {
limit: 3
})
// console.log(indexes) // [3, 2]
const results = indexes.map((i) => data[i])
setResults(results)
}
return (
<>
<form onSubmit={search}>
<input
type='text'
value={value}
onChange={(e) => setValue(e.target.value)}
/>
<button>Search</button>
</form>
<ul>
{results.map((result, i) => (
<li key={i}>
<HighlightMatch title={result.title} q={value} />
</li>
))}
</ul>
</>
)
}При создании экземпляра в конструктор Index может передаваться объект с настройками. В данном случае мы определяем режим индексации tokenize: 'forward'. forward означает инкрементальную (частичную) индексацию в прямом направлении, т.е. вперед. Подробнее об этом можно почитать здесь.
Затем мы перебираем объекты данных для поиска и записываем их заголовки в индекс под идентификаторами (индексами объектов).
Метод flex.search() принимает строку для поиска и опциональный объект с настройками и возвращает массив индексов совпадений. Мы перебираем этот массив и извлекаем из данных для поиска соответствующие объекты.
Если ввести в инпуте java и нажать Enter, результат будет таким:

К слову, в документации flexsearch имеется ссылка на хук useFlexSearch, однако он не совместим с новым синтаксисом flexsearch. Если его немного причесать, получится следующее:
import { useState, useMemo, useEffect } from 'react'
import { Index } from 'flexsearch'
export const useFlexSearch = (query, providedIndex, store, searchOptions) => {
const [index, setIndex] = useState(null)
useEffect(() => {
if (!providedIndex && !store)
console.warn(
'A FlexSearch index and store was not provided. Your search results will be empty.'
)
else if (!providedIndex)
console.warn(
'A FlexSearch index was not provided. Your search results will be empty.'
)
else if (!store)
console.warn(
'A FlexSearch store was not provided. Your search results will be empty.'
)
}, [providedIndex, store])
useEffect(() => {
if (!providedIndex) {
setIndex(null)
return
}
if (providedIndex instanceof Index) {
setIndex(providedIndex)
return
}
// Если `providedIndex` - это строка,
if (typeof providedIndex === 'string') {
const importedIndex = new Index(searchOptions)
// Данные для поиска импортируются из локального хранилища
importedIndex.import(providedIndex, localStorage.getItem(providedIndex))
setIndex(importedIndex)
return
}
}, [providedIndex, searchOptions])
return useMemo(() => {
if (!query || !index || !store) return []
const rawResults = index.search(query, searchOptions)
return rawResults.map((id) => store[id])
}, [query, index, store, searchOptions])
}Пример использования данного хука:
import { useState, useRef } from 'react'
import { Index } from 'flexsearch'
import { useFlexSearch } from 'hooks'
const data = [
{
title: 'Веб-технологии для разработчиков',
url: '/ru/docs/Web'
},
{
title: 'Стандартные встроенные объекты',
url: '/ru/docs/Web/JavaScript/Reference/Global_Objects'
},
{
title: 'Справочник по JavaScript',
url: '/ru/docs/Web/JavaScript/Reference'
},
{
title: 'JavaScript',
url: '/ru/docs/Web/JavaScript'
},
{
title: 'Array',
url: '/ru/docs/Web/JavaScript/Reference/Global_Objects/Array'
}
]
const flex = new Index({ tokenize: 'forward' })
data.forEach(({ title }, i) => {
flex.add(i, title)
})
const HighlightMatch = ({ title, q }) => {
const words = q.trim().toLowerCase().split(/[ ,]+/)
const regexWords = words.map((s) => s.replace(/[.*+?^${}()|[\]\\]/g, '\\$&'))
const regex = `\\b(${regexWords.join('|')})`
const parts = title.split(new RegExp(regex, 'gi'))
return (
<>
{parts.map((part, i) => {
const key = `${part}:${i}`
if (words.includes(part.toLowerCase())) {
return <mark key={key}>{part}</mark>
} else {
return <span key={key}>{part}</span>
}
})}
</>
)
}
export const FlexSearchHook = () => {
const [value, setValue] = useState('')
const inputRef = useRef()
const results = useFlexSearch(value, flex, data)
// console.log(results)
const search = (e) => {
e.preventDefault()
setValue(inputRef.current.value.trim())
}
return (
<>
<form onSubmit={search}>
<input type='text' defaultValue='' ref={inputRef} />
<button>Search</button>
</form>
<ul>
{results.map((result, i) => (
<li key={i}>
<HighlightMatch title={result.title} q={value} />
</li>
))}
</ul>
</>
)
}Замечательно. С flexsearch тоже все более-менее понятно.
Примеры использования поисков и хука находятся в директории basic-search-examples.
В основном файле с кодом поиска происходит еще много интересных вещей.
import React, { useEffect, useMemo, useRef, useState } from 'react'
// Хуки для маршрутизации на стороне клиента -
// здесь не используются
// import { Link, useHistory } from 'react-router-dom'
// Хук для формирования выпадающего списка,
// соответствующего всем критериям доступности
import { useCombobox } from 'downshift'
// Полнотекстовый поиск по `title`
import FlexSearch from 'flexsearch'
// Хук для выполнения HTTP-запросов
import useSWR from 'swr'
// Тип и класс для "неточного" поиска по `url`
import { Doc, FuzzySearch } from './fuzzy-search'
// Хук для определения текущей локали -
// здесь не используется
// import { useLocale } from './hooks'
// Утилиты для получения плейсхолдера и
// установки фокуса на инпут при нажатии `/`,
// а также тип для пропов для поиска
import { getPlaceholder, SearchProps, useFocusOnSlash } from './search-utils'
const SHOW_INDEXING_AFTER_MS = 500
// Типы
// Для объекта данных
type Item = {
url: string
title: string
}
// Для поискового индекса
type SearchIndex = {
flex: any
fuzzy: FuzzySearch
items: null | Item[]
}
// Для объекта результатов поиска
type ResultItem = {
title: string
url: string
positions: Set<number>
}
// Хук для работы с поисковым индексом
function useSearchIndex(): readonly [
null | SearchIndex,
null | Error,
() => void
] {
// Состояние инициализации
const [shouldInitialize, setShouldInitialize] = useState(false)
// Состояние индекса
const [searchIndex, setSearchIndex] = useState<null | SearchIndex>(null)
// const locale = useLocale()
// Default to 'en-US' if you're on the home page without the locale prefix.
// По умолчанию локаль имеет значение 'en-US',
// если мы находимся на главной странице без префикса локали
// const url = `${locale}/search-index.json`
// Поиск файла выполняется в директории `public`
const url = `/search-index.json`
// Если состояние инициализации имеет значение `true`,
// вызываем хук `useSWR`:
// первый аргумент - `url`, он же ключ для кеша,
// второй - так называемый `fetcher`, функция
// для запроса-получения данных,
// третий - настройки (в данном случае мы отключаем
// выполнение повторного запроса при установке фокуса).
// Такая сигнатура означает, что хук ожидает инициализации
// https://swr.vercel.app/docs/conditional-fetching
const { error, data } = useSWR<null | Item[], Error | undefined>(
shouldInitialize ? url : null,
async (url: string) => {
// Получаем ответ
const response = await fetch(url)
if (!response.ok) {
// Если возникла ошибка, выбрасываем исключение
// с сообщением в виде текста
throw new Error(await response.text())
}
// Возвращаем ответ в формате `JSON`
return await response.json()
},
// Отключаем повторную валидацию
{ revalidateOnFocus: false }
)
// Количество объектов для русской локали
// console.log(data?.length) // 2910
// Выполняем побочный эффект
useEffect(() => {
// Ничего не делаем при отсутствии данных
// или наличии поискового индекса
if (!data || searchIndex) {
return
}
// Создаем поисковый индекс
// `tokenize` - это режим индексации (в данном случае
// используется инкрементальная индексация в прямом направлении, т.е. вперед)
// https://github.com/nextapps-de/flexsearch#tokenizer-prefix-search
const flex = new FlexSearch.Index({ tokenize: 'forward' })
// Данными является массив объектов с заголовками и адресами статей -
// `{ title: 'Заголовок', url: 'https://...' }`
// Перебираем объекты и помещаем заголовок и его индекс (в массиве) в поисковый индекс
data!.forEach(({ title }, i) => {
flex.add(i, title)
})
// Создаем экземпляр неточного поиска
const fuzzy = new FuzzySearch(data as Doc[])
// Обновляем состояние поискового индекса
setSearchIndex({ flex, fuzzy, items: data! })
}, [searchIndex, shouldInitialize, data])
// Хук возвращает мемоизированный массив из 3 элементов:
// поискового индекса, ошибки (которая может иметь значение `null`)
// и функции для обновления состояния инициализации
return useMemo(
() => [searchIndex, error || null, () => setShouldInitialize(true)],
[searchIndex, error, setShouldInitialize]
)
}
// The fuzzy search is engaged if the search term starts with a '/'
// and does not have any spaces in it.
// Неточный поиск используется в случае, когда строка для поиска
// начинается с `/` и не содержит пробелов.
// Данная утилита определяет, должен ли использоваться такой поиск
function isFuzzySearchString(str: string) {
return str.startsWith('/') && !/\s/.test(str)
}
// Утилита для подсветки совпадения
// при выполнении полнотекстового поиска
// `title` - это подходящий (совпавший) заголовок
// `q` - совпадение
function HighlightMatch({ title, q }: { title: string; q: string }) {
// FlexSearch doesn't support finding out which "typo corrections"
// were done unfortunately.
// See https://github.com/nextapps-de/flexsearch/issues/99
// `FlexSearch`, к сожалению, не умеет исправлять опечатки
// Split on higlight term and include term into parts, ignore case.
// Разделяем совпадение на части без учета регистра
const words = q.trim().toLowerCase().split(/[ ,]+/)
// $& means the whole matched string
// `$&` означает совпавшую строку целиком
const regexWords = words.map((s) => s.replace(/[.*+?^${}()|[\]\\]/g, '\\$&'))
const regex = `\\b(${regexWords.join('|')})`
// Разделяем заголовок на части по совпадению
const parts = title.split(new RegExp(regex, 'gi'))
return (
<b>
{/* Перебираем части */}
{parts.map((part, i) => {
const key = `${part}:${i}`
// Если часть является совпадением
if (words.includes(part.toLowerCase())) {
// Подсвечиваем ее
return <mark key={key}>{part}</mark>
} else {
return <span key={key}>{part}</span>
}
})}
</b>
)
// Если ввести в поиске `query`, то данная утилита вернет такую разметку
/*
<b>
<span>Document.</span>
// совпадение
<mark>query</mark>
<span>Selector()</span>
</b>
*/
}
// Утилита для генерации "хлебных крошек" для адреса статьи
// и подсветки совпадения
function BreadcrumbURI({
uri,
positions
}: {
uri: string
positions?: Set<number>
}) {
// Если имеется совпадение
// `positions` - набор индексов совпавших символов
if (positions && positions.size) {
// Разбиваем строку на массив символов
const chars = uri.split('')
return (
<small>
{chars.map((char, i) => {
// Если символ имеется в совпадении
if (positions.has(i)) {
return <mark key={i}>{char}</mark>
} else {
return <span key={i}>{char}</span>
}
})}
</small>
)
}
// Форматирование `url`
// В оригинальном файле `search-index.json`
// адреса статей начинаются с `/`, который удаляется.
// Также удаляется `docs`
const keep = uri
.split('/')
// .slice(1)
.slice(3)
.filter((p) => p !== 'docs')
// При объединении элементы массива разделяются ' / '
return <small className='search-item-uri'>{keep.join(' / ')}</small>
// Было, например: `https://developer.mozilla.org/ru/docs/Web`,
// стало: `ru / Web`
}
// Тип для поискового виджета
type InnerSearchNavigateWidgetProps = SearchProps & {
onResultPicked?: () => void
defaultSelection: [number, number]
}
// Хук для определения изменения значения инпута
function useHasNotChangedFor(value: string, ms: number) {
// Состояние для изменений
const [hasNotChanged, setHasNotChanged] = useState(false)
// Предыдущее значение
const previousValue = useRef(value)
// Побочный эффект для определения наличия изменений
useEffect(() => {
// Если предыдущее значение равняется текущему,
// ничего не делаем
if (previousValue.current === value) {
return
}
// Обновляем предыдущее значение текущим
previousValue.current = value
setHasNotChanged(false)
// while timeouts are not accurate for counting time there error is only
// upwards, meaning they might trigger after more time than specified,
// which is fine in this case
// Здесь речь идет о том, что таймеры не являются
// хорошим средством для точного измерения времени,
// поскольку могут срабатывать по истечении времени,
// больше указанного, но в данном случае такой подход является приемлемым
const timeout = setTimeout(() => {
// Если значение инпута в течение указанного времени не изменилось,
// значит, изменений не было :)
setHasNotChanged(true)
}, ms)
// Очистка побочного эффекта во избежание утечек памяти
return () => {
clearTimeout(timeout)
}
// Хук запускается повторно при изменении значения инпута или задержки
}, [value, ms])
// Возвращаем состояние
return hasNotChanged
}
// Виджет для поиска
function InnerSearchNavigateWidget(props: InnerSearchNavigateWidgetProps) {
// Пропы:
// значение инпута
// функция для обработки изменения этого значения
// индикатор того, находится ли инпут в фокусе
// функция для обработки изменения состояния фокуса
// функция для сохранения результатов поиска
// выделение по умолчанию
const {
inputValue,
onChangeInputValue,
isFocused,
onChangeIsFocused,
onResultPicked,
defaultSelection
} = props
// Объект истории браузера и текущая локаль -
// здесь не используются
// const history = useHistory()
// const locale = useLocale()
// Получаем поисковый индекс, ошибку и функцию для запуска инициализации поискового индекса
const [searchIndex, searchIndexError, initializeSearchIndex] =
useSearchIndex()
// Ссылка на ипнут
const inputRef = useRef<null | HTMLInputElement>(null)
// Ссылка на форму
const formRef = useRef<null | HTMLFormElement>(null)
// Переменная для выделения
const isSelectionInitialized = useRef(false)
// Отображение результатов зависит от состояния изменений
const showIndexing = useHasNotChangedFor(inputValue, SHOW_INDEXING_AFTER_MS)
// Побочный эффект для инициализации выделения
useEffect(() => {
// Если отсутствует инпут или выделение не инициализировано, ничего не делаем
if (!inputRef.current || isSelectionInitialized.current) {
return
}
// Если инпут находится в фокусе
if (isFocused) {
// Выделение по умолчанию имеет значение `[0, 0]`
inputRef.current.selectionStart = defaultSelection[0]
inputRef.current.selectionEnd = defaultSelection[1]
}
// Инициализируем выделение
isSelectionInitialized.current = true
}, [isFocused, defaultSelection])
// Мемоизированные результаты поиска
const resultItems: ResultItem[] = useMemo(() => {
// Если отсутствует поисковый индекс или инпут, или при инициализации индекса возникла ошибка,
// ничего не делаем
if (!searchIndex || !inputValue || searchIndexError) {
// This can happen if the initialized hasn't completed yet or
// completed un-successfully.
// Это может произойти, если инициализация еще не завершилась
// или завершилась неудачно
return []
}
// The iPhone X series is 812px high.
// If the window isn't very high, show fewer matches so that the
// overlaying search results don't trigger a scroll.
// Данное ограничение позволяет избежать появления
// полосы прокрутки на экранах с маленькой высотой
const limit = window.innerHeight < 850 ? 5 : 10
// Если строка начинается с `/` и не содержит пробелов,
// выполняется неточный поиск
if (isFuzzySearchString(inputValue)) {
// Если значением инпута является `/`
if (inputValue === '/') {
// Возвращаем пустой массив
return []
} else {
// Выполняем поиск,
// удаляя начальный `/`
const fuzzyResults = searchIndex.fuzzy.search(inputValue.slice(1), {
// Возвращается 5 или 10 лучших результатов
limit
})
// Возвращаем массив объектов
return fuzzyResults.map((fuzzyResult) => ({
// Адрес статьи
url: fuzzyResult.item.url,
// Заголовок статьи
title: fuzzyResult.item.title,
// Набор индексов совпавших символов
positions: fuzzyResult.positions
}))
}
} else {
// Full-Text search
// Выполняем полнотекстовый поиск
const indexResults: number[] = searchIndex.flex.search(inputValue, {
// Ограничение
limit,
// Предположения
suggest: true // This can give terrible result suggestions
// Это может приводить к ужасным результатам :)
})
// Возвращаем массив оригинальных объектов
return indexResults.map(
(index: number) => (searchIndex.items || [])[index] as ResultItem
)
}
// Результаты вычисляются повторно при изменении
// значения инпута, поискового индекса или возникновении ошибки
}, [inputValue, searchIndex, searchIndexError])
// Базовый адрес для выполнения HTTP-запроса
// const formAction = `/${locale}/search`
const formAction = `https://developer.mozilla.org/ru-RU/search`
// Формируем полный путь для поиска
const searchPath = useMemo(() => {
// Новая строка запроса
const sp = new URLSearchParams()
// Получается `?q=inputValue`
sp.set('q', inputValue.trim())
// Возвращаем полный путь
// Если ввести в инпуте `qwerty`,
// вернется `https://developer.mozilla.org/ru/search?q=qwerty`
return `${formAction}?${sp.toString()}`
}, [formAction, inputValue])
// Пустой результат - когда ничего не найдено
const nothingFoundItem = useMemo(
() => ({ url: searchPath, title: '', positions: new Set() }),
[searchPath]
)
// Формируем выпадающий список, отвечающий всем критериям доступности
const {
getInputProps,
getItemProps,
getMenuProps,
getComboboxProps,
// Индекс элемента, на которого наведен курсор или который находится в фокусе
highlightedIndex,
// Индикатор того, находится ли меню в открытом состоянии
isOpen,
reset,
toggleMenu
} = useCombobox({
// Результаты поиска или пустой результат в виде массива из одного элемента
items: resultItems.length === 0 ? [nothingFoundItem] : resultItems,
// Значение инпута
inputValue,
// Список по умолчанию будет находится в открытом состоянии
// только при фокусировке на инпуте
defaultIsOpen: isFocused,
// При клике по выделенному (highlightedIndex) результату
onSelectedItemChange: ({ selectedItem }) => {
if (selectedItem) {
// history.push(selectedItem.url)
// Открывается новое окно с соответствующей статьей на MDN
window.open(selectedItem.url, '_blank')
// Значение инпута обнуляется
onChangeInputValue('')
// Выполняется сброс меню
reset()
// Меню скрывается
toggleMenu()
// Расфокусировка
inputRef.current?.blur()
// Если передана функция для сохранения результатов,
// вызываем ее
if (onResultPicked) {
onResultPicked()
}
// Плавная прокрутка в верхнюю часть области просмотра
window.scroll({
top: 0,
left: 0,
behavior: 'smooth'
})
}
}
})
// При нажатии `/` на инпут устанавливается фокус
useFocusOnSlash(inputRef)
// Побочный эффект для инициализации поискового индекса
useEffect(() => {
// Если инпут находится в фокусе
if (isFocused) {
// Выполняем инициализацию
initializeSearchIndex()
}
}, [initializeSearchIndex, isFocused])
// Результаты поиска - рендеринг
// значением переменной является `IIFE` - автоматически вызываемое функциональное выражение
const searchResults = (() => {
// Если меню закрыто, т.е. инпут не находится в фокусе,
// или значение инпута является пустая строка (без учета пробелов),
// ничего не делаем
if (!isOpen || !inputValue.trim()) {
return null
}
// Если при инициализации поискового индекса возникла ошибка
if (searchIndexError) {
return (
// <div className='searchindex-error'>Error initializing search index</div>
<div className='searchindex-error'>
При инициализации поискового индекса возникла ошибка
</div>
)
}
// Если инициализация индекса еще не завершилась
if (!searchIndex) {
// и не было изменений значения инпута на протяжении 500 мс
return showIndexing ? (
<div className='indexing-warning'>
{/* <em>Initializing index</em> */}
<em>Инициализация индекса</em>
</div>
) : null
}
return (
<>
{/* Если отсутствуют результаты поиска и значением инпута не является `/` */}
{resultItems.length === 0 && inputValue !== '/' ? (
<div
{...getItemProps({
className:
'nothing-found result-item ' +
(highlightedIndex === 0 ? 'highlight' : ''),
// Возвращаем пустой результат
item: nothingFoundItem,
index: 0
})}
>
{/* No document titles found. */}
Подходящих статей не найдено.
<br />
{/* <Link to={searchPath}>
Site search for `{inputValue}`
</Link> */}
{/* Используется полный адрес статьи, сформированный ранее */}
<a href={searchPath} target='_blank' rel='noopener noreferrer'>
Искать на сайте MDN `{inputValue}`
</a>
</div>
) : (
// Перебираем результаты поиска
resultItems.map((item, i) => (
<div
{...getItemProps({
key: item.url,
className:
'result-item ' + (i === highlightedIndex ? 'highlight' : ''),
item,
index: i
})}
>
{/* Выполняем подсветку совпадения */}
<HighlightMatch title={item.title} q={inputValue} />
<br />
{/* Формируем хлебные крошки для адреса статьи */}
<BreadcrumbURI uri={item.url} positions={item.positions} />
</div>
))
)}
{/* Если выполняется неточный поиск */}
{isFuzzySearchString(inputValue) && (
// <div className='fuzzy-engaged'>Fuzzy searching by URI</div>
<div className='fuzzy-engaged'>Выполняется поиск по URI</div>
)}
</>
)
})()
// Рендеринг
return (
<form
action={formAction}
{...getComboboxProps({
// Ссылка на форму
ref: formRef as any, // downshift's types hardcode it as a div
// для `downshift` все есть `div` с точки зрения типов :)
className: 'search-form',
id: 'nav-main-search',
role: 'search',
// Обработчик отправки формы
onSubmit: (e) => {
// This comes into effect if the input is completely empty and the
// user hits Enter, which triggers the native form submission.
// When something *is* entered, the onKeyDown event is triggered
// on the <input> and within that handler you can
// access `event.key === 'Enter'` as a signal to submit the form.
// Здесь речь идет о том, что если инпут является пустым и
// пользователь нажимает `Enter`, выполняется нативная отправка формы.
// Если же инпут не является пустым, отправку формы можно перехватить
// с помощью`event.key === 'Enter'` в обработчике
// события нажатия клавиши `onKeyDown`.
// Отключаем дефолтную обработку отправки формы
e.preventDefault()
// Это сломало кнопку для отправки формы в виде лупы (см. ниже)
}
})}
>
<div className='search-field'>
<label htmlFor='main-q' className='visually-hidden'>
{/* Search MDN */}
Поиск MDN
</label>
<input
{...getInputProps({
type: 'search',
className: isOpen
? 'has-search-results search-input-field'
: 'search-input-field',
id: 'main-q',
name: 'q',
// Формируем плейсхолдер с помощью утилиты
placeholder: getPlaceholder(isFocused),
// При наведении курсора на инпут
// запускается инициализация поискового индекса
onMouseOver: initializeSearchIndex,
// Метод для обновления состояния фокуса
onFocus: () => {
onChangeIsFocused(true)
},
// и здесь
onBlur: () => onChangeIsFocused(false),
// Обработчик нажатия клавиш
onKeyDown(event) {
// Если нажата клавиша `Escape` и имеется инпут
if (event.key === 'Escape' && inputRef.current) {
// Меню скрывается, инпут очищается
toggleMenu()
} else if (
// Если нажата клавиша `Enter`, инпут не является пустым и отсутствует выделенный результат поиска
event.key === 'Enter' &&
inputValue.trim() &&
highlightedIndex === -1
) {
// Убираем фокус с инпута
inputRef.current!.blur()
// Отправляем форму
// formRef.current!.submit()
// Переходим на страницу поиска MDN
window.open(searchPath, '_blank')
}
},
// обработчик изменения значения инпута
onChange(event) {
if (event.target instanceof HTMLInputElement) {
onChangeInputValue(event.target.value)
}
},
// Ссылка на инпут
ref: (input) => {
inputRef.current = input
}
})}
/>
{/* Кнопка для отправки формы, которая не работала */}
{/* создал пулреквест :) */}
<input
type='submit'
className='search-button'
value=''
aria-label='Поиск'
onClick={() => {
if (inputValue.trim() && inputValue !== '/') {
// history.push(searchPath)
window.open(searchPath, '_blank')
}
}}
/>
</div>
{/* Выпадающий список с результатами */}
<div {...getMenuProps()}>
{searchResults && <div className='search-results'>{searchResults}</div>}
</div>
</form>
)
}
// Предохранитель - обработчик ошибок
class SearchErrorBoundary extends React.Component {
// Состояние ошибки
state = { hasError: false }
// Регистрация ошибки
static getDerivedStateFromError(error: Error) {
// console.error('There was an error while trying to render search', error)
console.error('В процессе рендеринга поиска возникла ошибка', error)
// Обновляем состояние ошибки
return { hasError: true }
}
render() {
return this.state.hasError ? (
// <div>Error while rendering search. Check console for details.</div>
<div>
В процессе рендеринга поиска возникла ошибка. Загляните в консоль за подробностями.
</div>
) : (
this.props.children
)
}
}
// Экспорт виджета для поиска, обернутого в предохранитель
export default function SearchNavigateWidget(
props: InnerSearchNavigateWidgetProps
) {
return (
<SearchErrorBoundary>
<InnerSearchNavigateWidget {...props} />
</SearchErrorBoundary>
)
}С тем, как работает хук useCombobox, я предоставлю вам возможность разобраться самостоятельно (вот более чем подробная документация).
Пожалуй, это все, чем я хотел поделиться с вами в этой статье.
Теперь в вашем распоряжении имеется готовый к использованию продвинутый компонент для поиска, который легко приспособить для нужд конкретного приложения.
Что касается моего личного мнения по поводу "крутости" поиска, безусловно, он очень хорош. Я бы немного упростил код, поскольку нахожу несколько вещей лишними. Также я убрал бы парочку оптимизаций, поскольку они стоят дороже повторного рендеринга, который в любом случае происходит из-за большого количества постоянно меняющихся зависимостей. Также в оригинале, судя по всему, отключена проверка на неявный тип any ("noImplicitAny": false), что, на мой взгляд, не есть правильно.
Надеюсь, вам было также интересно, как и мне.
Приветствуется любая форма обратной связи.
Благодарю за внимание и хорошего дня!

Комментарии (4)

demimurych
01.11.2021 17:21это все прекрасно, только бесполезно чуть более чем полностью, по той простой причине, что адекватность запросу, выдаваемой информации, стремиться к нулю. Как следствие все равно пользуешься поиском от корпорации бобра.
интересно, когда на mdn найдут ресурс починить сломаные к чертям локализации переводов?
или вернут виджет выбора языка на свое место. А то люди уже устали придумывать версии, накой черт его перенесли вниз страницы
nin-jin
Отлично, давайте сделаем то же самое на $mol..
Сперва, нам потребуется тип для модельки страницы:
Теперь опишем кастомное поле поиска страниц:
Добавляем немного логики:
Добавляем немного красоты:
Поле поиска готова. Давайте теперь воспользуемся им. Создадим демку:
Опишем типизированный валидатор ответа от сервера.
Загрузим данные с сервера и провалидируем их:
Вуаля:
laatoo
давайте
читер!
nin-jin
Да, на $mol не обязательно изобретать велосипеды с нуля, ибо всегда можно взять похожий компонент и допилить его под свои нужны.