
Наша команда контроллинга получает несколько тысяч отчётов с фотографиями, по которым проверяет качество продуктов и сервисов в Додо Пицце. Это рутинная работа, которую можно автоматизировать с помощью компьютерного зрения.
В этой статье мы вместе с Евгением Биккининым @Xneg расскажем, как создали и обучили модель на Databricks, запустили её в продакшен и какие результаты получили.

Привет, меня зовут Кристина, я занимаюсь задачами компьютерного зрения в Dodo. У нас это направление зародилось совсем недавно и только начинает развиваться, но уже есть первые результаты, о которых я хочу рассказать в этой статье, да и вообще о том, для чего нам это нужно.
У нас есть команда контроллинга, чьей основной задачей является обеспечивать высокое качество продуктов и сервисов всех ресторанов Додо Пиццы. Для этого существуют определённые стандарты и критерии, по которым проходят проверки. В процессе участвуют тайные покупатели: присылают отчёты с фотографиями заказа, помещения (если проверяют непосредственно ресторан) и ответы на вопросы об обслуживании. Ориентируясь на эти отчёты, команда контроллинга выявляет нарушения.

При этом есть целый ряд дефектов пиццы, которые можно выявлять с помощью компьютерного зрения — и это может сильно облегчить ручную проверку. Для начала мы сосредоточились на самых часто встречающихся дефектах (дальше много фотографий):
белое дно;

белый борт;

горелый борт;

дно плохо прорезано;

деформирована.

Подготовка данных
Для обучения нейросети необходимы размеченные данные, в нашем случае это был набор изображений с метками классов (названиями дефектов), собранный за полтора года. Оставалось только отобрать нужные данные и обучить модель.
Короткая справка о свёрточных нейросетях
О том, что такое нейросети и как они работают написано множество статей. Если коротко — нейросеть представляет собой набор весовых коэффициентов, которые корректируются во время обучения таким образом, чтобы минимизировать функцию ошибки. Более подробно можно почитать, например, здесь.
Для работы с изображениями хорошо зарекомендовали себя архитектуры свёрточных нейросетей. В общем-то, так они называются благодаря своей ключевой операции — свёртке. Чисто с математической точки зрения свёртка — это сумма произведений матрицы входных сигналов и весовых коэффициентов ядер свёрток, которые являются обучаемыми параметрами. Применяя операцию свёртки к изображению мы извлекаем из него определённые признаки. На первых свёрточных слоях извлекаются самые простейшие признаки, чем глубже в нейросеть, тем признаки сложнее.
Высокоуровневые признаки уже поступают на полносвязный слой, где, собственно, и формируется предсказание модели.
Обучение модели на DataBricks
Для обучения модели мы воспользовались платформой Azure Databricks, основанной на возможностях Spark (не стали долго думать и просто взяли инструмент, который уже используется в компании). Она позволяет разрабатывать и развёртывать решения в области ML.
Первоначально наши данные были представлены в виде CSV-таблицы, в которой указаны путь к изображению в BLOB storage и наличие того или иного дефекта. Но поскольку мы имеем дело с изображениями, такой формат не особо подходил. Тут на помощь пришёл Parquet — бинарный колоночно-ориентированный формат хранения больших данных, изначально созданный для экосистемы Hadoop. Parquet гораздо быстрее для чтения, нежели CSV. Также он поддерживается Spark.
Следующий шаг — подать данные из этого датасета на вход модели. Для этого мы использовали Petastorm.
Petastorm — это библиотека доступа к данным с открытым исходным кодом. Она позволяет выполнять одноузловое или распределённое обучение и валидацию моделей глубокого обучения из наборов данных в формате Apache Parquet. Также Petastorm дружит c PyTorch.
О том, как загружать данные с помощью Petastorm, можно почитать здесь.
Поскольку запуск модели на обучение обычно не является однократным, да и вообще таких моделей может быть несколько для разных задач, то необходимо где-то хранить информацию о каждом запуске. А если эксперименты проводились месяц назад, то вспоминать, что там было, покажется самой настоящей пыткой.
В идеале мы хотели:
иметь информацию о каждом запуске модели;
версионировать модели;
удобно выводить новые модели в продакшен.
Для этого подходит MLFlow — платформа, предназначенная для управления жизненным циклом моделей машинного обучения. Она состоит из четырёх компонентов:
MLFlow Tracking позволяет записывать параметры и результаты экспериментов;
MLFlow Models позволяет хранить и публиковать модели;
MLFlow Projects позволяет сохранять код для его дальнейшего воспроизведения;
MLFlow Registry управляет жизненным циклом моделей, поддерживает версионирование.
Версионирование в MLFlow
Время от времени возникает необходимость в дообучении моделей. И если удаётся улучшить метрики, то мы хотели бы использовать новую модель на продакшене. С помощью MLFlow это можно сделать за пару кликов.
Первым делом нужно зарегистрировать модель и присвоить ей название:

После этого у неё появится версия. При каждой последующей регистрации модели с таким же названием её версия будет обновляться.
Список всех зарегистрированных моделей в Databricks можно увидеть во вкладке Models. А при клике на любую из них можно увидеть все её версии.

Там же можно выбрать для модели одно из трёх состояний: Staging, Production, Archived.
Staging — тестовая среда, максимально приближенная к условиям на продакшене;
Production — эксплуатационная среда;
Archived — архивирование модели.
Впоследствии, чтобы получить самую новую версию модели, нам необходимо только задать её имя и состояние:
model_name = 'WhiteBottom' model_stage = 'Staging' model = mlflow.pytorch.load_model(f"models:/{model_name}/{model_stage}", map_location=torch.device("cpu"))

Выводим модель в продакшен (чуток про MLOps)
Итак, у нас была готова модель в регистре MLFlow, которая умела предсказывать дефект. Чтобы она начала приносить пользу, нужно задеплоить её в продакшен.
В первую очередь нужно было выбрать сценарий использования предсказания. Есть два варианта использования: онлайн — когда пользователь вводит свои данные и ему моментально приходит ответ от веб-сервиса, и асинхронный режим — когда обработка данных происходит в определённые промежутки времени и обычно сразу пачкой событий.
Нам подходил второй вариант. Тайные покупатели и клиенты отправляют анкеты с проверками, которые ребята из команды контроллинга не проверяют мгновенно. То есть сценарий, что раз в час запускается джоба, обрабатывает все поступившие на этот момент проверки и отправляет в сервис контроллинга, нас устраивал.
Во-вторых, нужно было выбрать инструмент. Так как наши дата пайплайны построены на стеке Databricks, то и ML-решение логично делать на нём.
За основу взяли код джобы с сайта Databricks.
Первая версия выглядела примерно так:

События проверок собираются в топике Azure EventHubs (это аналог Kafka от Microsoft). Раз в час запускается джоба и вычитывает все события, которые накопились и ещё не были обработаны за это время. Из набора событий формируется DataFrame, в котором фильтруются только те изображения, которые нужны для дефекта. Точнее, не сами изображения, а пути к ним, потому что PyTorch ImageDataset использует свой механизм загрузки и батчинга изображений.
Потом этот массив прогоняется через модель, мы получаем DataFrame с определением наличия дефекта для каждой из проверок и для каждой же из проверок формируем событие в выходной топик EventHubs. Далее уже сервис контроллинга использует на своей стороне данные этих событий.
В качестве POC это оказался вполне рабочий вариант, который реально запустили в продакшен. Но буквально на следующий день после запуска ребята из контроллинга пришли с новым запросом: они хотели добавлять произвольное количество новых проверок и моделей и желательно без или с минимальным участием дата-инженера.
Появилось ещё одно требование: на одну проверку должен возвращаться один результат предсказаний моделей. Если будет обнаружено несколько дефектов, они должны отправляться не отдельными сообщениями, а упаковываться в массив в одном сообщении. Это требование привело к появлению в схеме джобы, которая собирает результаты предсказаний моделей.

В итоге получилась схема, представленная на рисунке. В её основе всё ещё можно разглядеть ядро предыдущей схемы, но теперь одна джоба разбилась на четыре:
Landing. Эта джоба получает события из EventHubs и складывает их в DeltaLake as is. То есть, по сути, она просто персистит входные данные.
Bronze. Джоба берёт данные из landing-слоя, преобразует их из формата EventHub по схеме в понятный DataFrame и записывает в DeltaLake. В принципе, без этой джобы можно обойтись, делая преобразование на следующем этапе, но мы решили добавить немного гранулярности в разделение ответственности.
Infer. Это те же самые джобы из первого решения, только теперь они не общаются с EventHubs напрямую, а получают входные данные и записывают результаты в DeltaLake.
Result. Это самая интересная часть нового решения. Как упоминалось выше, сервис контроллинга ждёт только одно сообщение о том, что проверка завершена и найден список дефектов. А у нас джобы Infer отрабатывают каждая в своё время с разной скоростью и нужно как-то собрать результаты их обработки.
Тут мы воспользовались особенностью Delta Lake. Таблицы в Delta Lake могут вести себя как таблицы и как стримы. Для того чтобы определить, какие строки уже обработаны, а какие нет, мы пользуемся чекпоинтом стрима (это примерно как offset в Kafka). Все строки, которые есть после чекпоинта — ещё не обработанные.
Мы берём необработанные строки и выбираем из них только CheckupId – по сути получаем список проверок, по которым пришли результаты работы моделей. Затем мы делаем join списока ID и той же самой таблицы результатов и проверяем, все ли модели отработали. Если нет, то дальше игнорируем эту проверку, а если да, то собираем результаты проверок в массив и отправляем в EventHubs.
Ниже приведён основной код этой джобы.
yesterday = datetime.date.today() - datetime.timedelta(days=1)
struct_col = F.when(F.col("Infer") != 0, F.col("DefectType")).otherwise(None)
table_df = (
spark.read.format("delta")
.options(**reader_options)
.load(source_path)
.where(F.col("EventDate") >= yesterday)
.withColumn("Struct", struct_col)
)
def process_microbatch(microbatch_df, batch_id):
(
microbatch_df
.select("CheckupId")
.distinct()
.join(table_df, "CheckupId")
.groupBy("CheckupId")
.agg(
F.collect_set("DefectType").alias("Infers"),
F.collect_list("Struct").alias("Defects"),
)
.withColumn("Diff", F.array_except(infered_defects, "Infers"))
.where(F.size(F.col("Diff")) == 0)
)
spark.readStream.format("delta")
.options(**reader_options)
.load(source_path)
.writeStream.foreachBatch(process_microbatch)Как это выглядит в бэкофисе
Теперь дефекты, распознанные моделью, отображаются в бэкофисе команды контроллинга. При открытии проверки менеджер может согласиться с предсказанием, либо, в случае ложного срабатывания, убрать его.

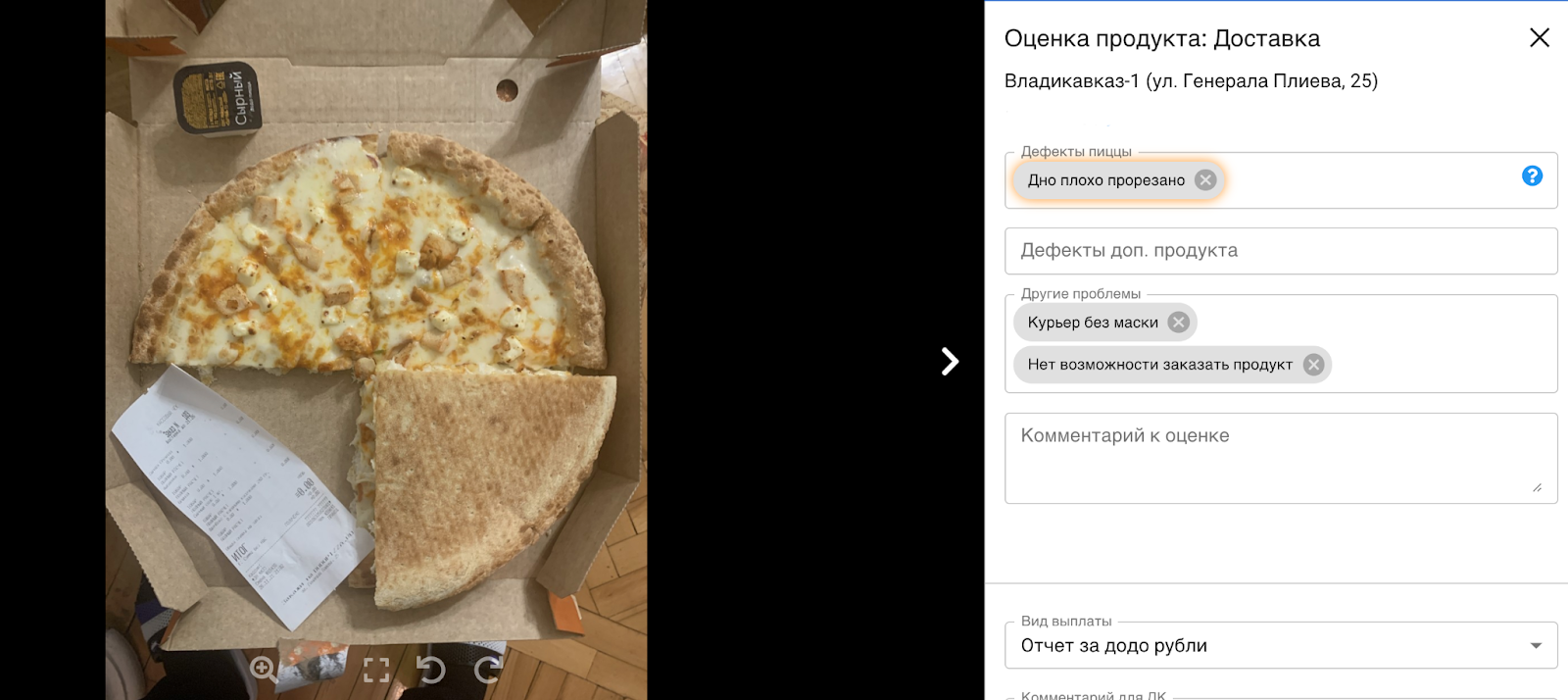



Бывают и такие проверки, на которых выявляется сразу несколько дефектов:

Сейчас мы выявляем с помощью компьютерного зрения небольшую часть дефектов пиццы, но это позволяет обратить внимание ребят из команды контроллинга на те дефекты, которые ранее они могли пропустить.
По метрикам:
белое дно (Precision=0.85, Recall=0.94);
белый борт (Precision=0.76, Recall=0.77);
горелый борт (Precision=0.80, Recall=0.82);
дно плохо прорезано (Precision=0.84, Recall=0.88);
деформирована (Precision=0.80, Recall=0.83).
Ещё раз подчеркну, что всё это — лишь первые шаги, впереди нас ждут задачи по распознаванию оставшихся дефектов пиццы. Например, хотим с помощью CV определять толщину борта, нанесён ли соус на пиццу по стандартам, а также заняться определением рецепта пиццы. В будущем планируем выявлять дефекты не только в рамках проверок тайных покупателей, но и по камерам, установленным в пиццериях.
Но об этом — уже в следующих статьях.
Комментарии (9)

ZlodeiBaal
16.12.2021 19:44+3Хммм…
habr.com/ru/company/ods/blog/422873
Надо сказать что в прошлый раз у вас модель была сильно лучше и адекватнее, судя по той статье:)
Оно конечно, не продуктовое небось было (в 2018 году в CV ещё не было удобного инженеринга моделей через MLFlow и Azure). Но делать для явных задач детекции классификацию — ну такое. Или у вас все же не чистая классификация, а какие-то детекторы?
capwat Автор
16.12.2021 20:39Собственно, почему мы и решали эти задачи с помощью классификации:
1) потому что эти задачи действительно можно решить таким путем;2) первоначально у нас не было датасета для детекции. Как я и писала выше, наши данные представляли собой изображения пицц с наименованием дефектов, которые на них были обнаружены. Дополнительно готовить разметку мы не стали, для начала решив попробовать решить эту задачу при помощи классификации. В случае неуспеха, безусловно, мы бы попробовали иной подход.
Также у нас остались дефекты, для обнаружения которых классификацией не обойтись, но об этом мы расскажем уже в следующий раз.ZlodeiBaal
16.12.2021 21:09+4Про решение задач таким путем. Классификаторы дают хорошую иллюзию того что задача решается. В реальности она решается лишь на используемом датасете, и куда хуже решается на живом проде:
1) Дебаг классификатора и поиск его проблем и ошибок куда сложнее чем у детекционной модели. Вы видите что возрастает число ошибок на проде — но нет адекватного варианта посмотреть что вызывает эти ошибки. Остается два подхода: переобучить бездумно или угадать. И то и то не продуктовое решение.
Конечно, если у вас классификация на трансформерах, и есть нормальная attention map, то там чуть проще. Но все равно криво будет.
Если обобщить этот пункт — используя классификацию вы теряете прозрачность пайплайна работы.
2) Точность классификатора намного ниже если вы его используете для поиска мелкого дефекта, чем когда вы его используете к кропу найденной целевой области. На некоторых задачах я видел ухудшение метрик почти на порядок (например распознавание каких-нибудь деталей одежды/частей машин, и.т.д.). Да, эта разница будет минимальная если у вас обучающий датасет на много миллионов примеров, а используются в качестве бекбонов трансформеры, либо очень жирные сети. Но у меня сомнение что оно у вас так.
Ваши метрики это хорошо подтверждают, чем меньше площадь дефекта — тем хуже метрика. А уж сколько вы на этом теряете — это второй вопрос. Проще всего оценить сравнив с кроссразметкой людьми.
3) Обычно в задачах вашего плана один из основных источников ошибок — некорректные данные. Неправильный угол съемки/недостаточная видимость и.т.д.
И тут вам либо надо будет ещё один классификатор бахнуть, либо из нормального детектора/сегментатора оценивать набор параметров для работы.
Теперь что касается «не было датасета для детекции».
Сделать детекционную разметку/контейнеризировать её через какую-нибудь Толоку/MechanicalTurk — неделя (и потом просто поднимать нужные задачи по мере подхода новых данных, можно даже автоматом). Есть много фирм которые это очень дешево под заказ делают (или размечают, беря на себя ещё боль поддержания всего и вся).В случае неуспеха, безусловно, мы бы попробовали иной подход.
Что было мерилом неуспеха?:)
И да, если не секрет, у вас работает ещё тот алгоритм который описан в статье habr.com/ru/company/ods/blog/422873? Вы сравнивали точность с ним?
bazzi
А почему не пошли по пути улучшения технологии выпекания? Ну, что бы как надо зажаривалось. Контроль рецептуры, температуры и времени - должен помочь или нет?
Xneg
Привет! Технология выпекания на самом деле прописана в стандартах и периодически меняется и улучшается в зависимости от потребности.
Тут проблема в масштабировании. При более 700 точек с различными партнерами могут быть по каким-то причинам выставлены не те настройки, либо по каким-то причинам общие стандарты не подходят, либо же просто человеческий фактор.
Собственно для этого и нужен контроллинг, чтобы отслеживать такие ситуации *по конкретным пиццериям*, разбираться, что не так и помогать партнёру делать качественный продукт.
bazzi
Меня всегда устраивал уровень запекания ваших пицц, поэтому я думал что все технологии выпечки уже отшлифованы. Думал что печи умные у вас, сами температуру нужную и время поддерживают.
Xneg
Ну, мы стараемся) Но косяки случаются. Дело не только в пропекании, а в том числе, как раскатано тесто, как положили начинку и т.д.
И да, печи не настолько умные, скорее как кофе-машины, их надо уметь настраивать.
beskaravaev
Зачастую да, всё хорошо и тоже нравится качество додо, но пару раз были случаи, когда пицца было жесткой, т.к. её пережарили. Такое случается и совсем от этого не избавиться, но можно уменьшать количество «брака» разными путям и в статье один из них. И да, нужен комплексный подход. Было бы глупо отбраковывать половину товара, из-за не стандартизированного процесса приготовления.
Archemagus
Так одно другому не мешает, нет? К тому же человеко-фактор все равно может напортачить в конечном результате, а все этапы создания пиццы ты не проработаешь.
Например то же "дно не прорезано". Это либо в каждую пиццерию завозить автоматы для нарезки пиццы (что звучит мягко говоря как перебор), либо как в статье - с фото быстренько прогнать через нейронку