

Это важное событие для всех пользователей Apache Spark Structured Streaming. RocksDB теперь доступен как state store бэкенд, поддерживаемый ванильным Spark!
Инициализация
Чтобы начать использовать хранилище состояний (state store) RocksDB, вы должны явно определить класс провайдера в конфигурации Apache Spark: .config("spark.sql.streaming.stateStore.providerClass", "org.apache.spark.sql.execution.streaming.state.RocksDBStateStoreProvider"). Позже метод createAndInit объекта-компаньона StateStore инициализирует инстанс провайдера и вызовет метод init в RocksDBStateStoreProvider, где провайдер:
запоминает схемы ключа и значения состояния
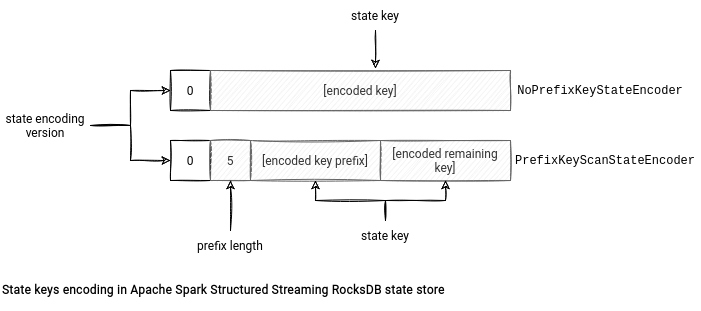
создает соответствующий RocksDBStateEncoder - в настоящее время есть два энкодера: PrefixKeyScanStateEncoder и NoPrefixKeyStateEncoder.Почему два? Потому что Apache Spark 3.2.0 принес нам еще одну интересную фичу, называемую сканированием префиксов (prefix scan), которая оптимизирует сканирование определенного диапазона ключей (подробнее об этом я напишу через пару недель). Эта функция не является обязательной, и только один из энкодеров поддерживает ее. Присутствует поддержка этой фичи или отсутствует - зависит от формата хранения ключа. NoPrefixKeyStateEncoder хранит ключ целиком, в то время как PrefixKeyScanStateEncoder разделяет ключ на две части: префикс и остальную часть. Этот формат также хранит длину префикса ключа, а длину остальной части - нет, поскольку она динамически генерируется при десериализации из результата
keyBytes.length - 4 - prefixKeyEncodedLen.
возвращает лениво создаваемый инстанс базы данных RocksDB; фактически он будет создан после первого вызова.
Что касается инициализации - на этом пока все. Но гораздо больше всего интересного произойдет позже, когда Apache Spark наконец задействует хранилище состояний в операции, фиксирующей состояние.
Операции CRUD (Create, Read, Update, Delete)
Хранилище состояний RocksDB использует тот же API чтения-записи, что и версия с поддержкой HDFS. Вначале с помощью метода load(version: Long) загружается соответствующая версия хранилища. Версия соответствует порядковому номеру последнего микробатча, и функция начинается со сравнения версии для загрузки актуальной версии приложения. Если они разные, это означает, что контекст выполнения, вероятно, затрагивает репроцессинг, и локальной информации нет. Следовательно, хранилище состояний восстановит базу данных из контрольной точки с помощью RocksDBFileManager. Поскольку я раскрою тему восстановления в последнем разделе, давайте перейдем непосредственно к чтению/записи.
По вполне понятным причинам, для их выполнения Apache Spark задействует RocksDB API. В описании хранилища состояний вы можете найти такие классы RocksDB как:
ReadOptions - использует все параметры по умолчанию для чтения данных из инстанса RocksDB. Это может стать для вас сюрпризом, но Apache Spark использует его не только при возврате состояний вызывающей стороне, но и при их записи в методах put и remove. Зачем? Для отслеживания количества ключей в данной версии. Таким образом, операция put увеличивает счетчик, а операция remove его уменьшает:
def put(key: Array[Byte], value: Array[Byte]): Array[Byte] = {
val oldValue = writeBatch.getFromBatchAndDB(db, readOptions, key)
writeBatch.put(key, value)
if (oldValue == null) {
numKeysOnWritingVersion += 1
}
oldValue
}
def remove(key: Array[Byte]): Array[Byte] = {
val value = writeBatch.getFromBatchAndDB(db, readOptions, key)
if (value != null) {
writeBatch.remove(key)
numKeysOnWritingVersion -= 1
}
value
}
WriteOptions - устанавливает значение флага sync в true, что означает, что должна быть произведена запись на диск (flush) из буферного кэша ОС перед тем, как операция записи будет считаться завершенной. Это замедляет процесс записи, но гарантирует отсутствие потери данных в случае отказа машины. Apache Spark использует его в коммите в хранилище состояний.
FlushOptions - позволяет waitForFlush блокировать операцию flush, пока он не будет уничтожен. Также используется в коммите в хранилище состояний.
WriteBatchWithIndex - сконфигурирован с включенным overwriteKey для замены любых существующих ключей в базе данных. Это интерфейс записи для RocksDB, но, поскольку он допускает возможность поиска (searchable), он также участвует в операциях получения данных, включая упомянутые выше в контексте записи.
BloomFilter - используется как политика фильтрации (filter policy) для уменьшения количества операций чтения с диска при поиске ключей.
Если сравнивать с хранилищем состояний по умолчанию, реализация с RocksDB очень похожа в плане CRUD операций. За исключением одной важной разницы. Напомним, что операция удаления в дефолтном хранилище состояний реализуется через контрольные точки (checkpoints) и delta-файл. В RocksDB это работает не так - состояние просто удаляется из базы данных. Разница также есть в элементах, для которых создаются контрольные точки, представленных чуть ниже.
Хранилище
На следующей схеме вы можете увидеть файлы, которыми оперирует хранилище состояний RocksDB:

В ней есть два “пространства”. В самой левой части хранятся все файлы, используемые действующим инстансом базы данных RocksDB. В рабочем каталоге (working directory) находятся файлы данных инстанса, SSTables и журналы. Пространство контрольных точек (checkpoint) - это каталог, созданный Apache Spark при коммите версии актуального микробатча (см. ниже). В нем хранятся все файлы, для которых будут создаваться контрольные точки. Наконец, пространство файлового менеджера (file manager) - это каталог, зарезервированный для активности RocksDBFileManage. Менеджер использует его в основном на этапе клинапа для хранения несжатого содержимого файлов, для которых создаются контрольные точки.
Что касается пространства контрольных точек, то вы найдете там файлы RocksDB (журналы, SST, каталог архивных журналов), некоторые метаданные со схемой хранилища состояний и zip-файлы, в которых хранятся другие файлы, необходимые для процесса восстановления, такие как параметры RocksDB или сопоставление между файлами, для которых создаются контрольные точки, и их локальными именами.
Отказоустойчивость
Коммит из state store API запускается после обработки всех входных строк для нужной партиции, чтобы материализовать хранилище состояний до версии актуального микробатча. В RocksDB эта операция включает следующие этапы:
создание пустого и временного каталогов контрольных точек в пространстве RocksDB
запись всех обновлений версии в базу данных RocksDB - этот шаг вызывает метод write из RocksDB API. Но погодите-ка минутку, CRUD-часть использует функции вставки и удаления из API. В чем тогда разница? Хранилище состояний использует режим Write Batch With Index, в котором операции записи сериализуются в WriteBatch вместо того, чтобы воздействовать непосредственно на базу данных. Вызов операции записи гарантирует их атомарность записи в базу данных.
запись на диск (flushing) всех данных из памяти - записи сначала попадают в структуру памяти, называемую memtable. Когда memtable заполняется, RocksDB записывает ее содержимое в sstfile’ы, хранящиеся на диске. Благодаря этому процесс создания контрольной точки покроет весь датасет.
сжатие хранилища состояний, если оно включено - этот процесс состоит из очищения от удаленных или перезаписанных привязок “ключ-значение” в целях организации данных для повышения эффективности запросов. Он также объединяет небольшие файлы с записанными данными в более крупные.
остановка всех текущих фоновых операций, чтобы избежать несогласованности файлов во время фиксации из-за одновременных действий с одними и теми же файлами,
создание контрольной точки (checkpoint) RocksDB - это встроенная возможность RocksDB для создания моментального снапшота запущенного инстанса в отдельном каталоге. Если контрольная точка и база данных используют одну и ту же файловую систему, как в нашем случае с Apache Spark, контрольная точка будет создавать только жесткие ссылки на SSTable-файлы базы данных.
инстанс RocksDBFileManager принимает все файлы контрольных точек и копирует их в пространство контрольных точек. В этом копировании есть несколько хитрых моментов. Для начала, есть два типа файлов: не архивируемые и архивируемые. Первая категория касается архивных log и актуальных sst-файлов. Процесс создания контрольных точек копирует только их в пространство контрольных точек. Отсюда следует еще один интересный факт. RocksDB может повторно использовать файлы sst из предыдущего микробатча. Когда это происходит и эти файлы совпадают с уже скопированными, процесс создания контрольной точки не копирует их. Вместо этого она только будет ссылаться на них в файле метаданных, в котором перечислены все sst-файлы, относящиеся к данному микробатчу. Вы можете найти содержимое этого файла ниже:
v1
{"sstFiles":[{"localFileName":"000009.sst","dfsSstFileName":"000009-1295c3cd-c504-4c1b-8405-61e15cdd3841.sst","sizeBytes":1080}],"numKeys":2}В дополнение к этим sst-файлам и журналам процесс создания контрольной точки принимает метаданные (MANIFEST, CURRENT, OPTIONS), файл журнала и вышеупомянутый файл метаданных, которым оперирует Spark, и сжимает их в один zip-архив. Краткую схему этого процесса можно посмотреть на схеме ниже:

Когда дело доходит до восстановления хранилища состояний в методе load, хранилище состояний RocksDB делегирует это действие RocksDBFileManager. Во время восстановления менеджер загружает заархивированный файл и распаковывает его в локальный рабочий каталог RocksDB. Позже он проходит по всем sstFiles из метаданных и возвращает их из пространства контрольной точки в каталог RocksDB. Стоит отметить, что все скопированные файлы хранятся локально с правильными именами, т.е. UUID-имя заменяется атрибутом localFileName.
После завершения этой операции копирования у Apache Spark будут все необходимые файлы для перезапуска предыдущего инстанса RocksDB. Это делается через ссылку на рабочий каталог в вызове инициализации: NativeRocksDB.open(dbOptions, workingDir.toString).
RocksDB - интересная альтернатива дефолтной реализации хранилища состояний на основе кучи, оптимизированная для оперирования большим количеством состояний. Однако разобраться в ней немного сложнее, поскольку требуется понимание новых технологий. К счастью, как конечному пользователю, возможно, вам и не нужно знать все эти подробности, но если все-таки нужно, я надеюсь, что эта статья вам поможет!
Перевод подготовлен в преддверии старта курса Spark Developer.