
Меня зовут Миша Лиз, я специалист по анализу данных в 2ГИС. Вместе с ML-командой мы применяем машинное обучение в продуктовых задачах — от построения оптимального маршрута для пользователя до распознавания дорожных знаков и типов дорожных покрытий с видео. Я в основном занимаюсь задачами, связанными с компьютерным зрением.
Осенью мы участвовали в конкурсе в рамках AI Journey, который организовали ребята из Сбера. Команды соревновались в решении ML-задач разных сервисов — Ситимобила, Sber AR/VR, Neurolab, Работы.ру. От нас задачки тоже были. Про финальную задачу и её результаты как раз и расскажу.
Конкурс
AI Journey — серия мероприятий, посвящённых науке о данных. Они призваны объединять разработчиков и специалистов в области машинного обучения по всему миру.
В конкурсе соревновались ребята, учащиеся в школах и интересующиеся машинным обучением. Они смогли попробовать свои силы в 10 задачах разных направлений — Nature Language Processing (NLP), Computer Vision (CV), Reinforcement Learning (RL), а также в классическом машинном обучении.
Как проходило соревнование
Два этапа — отборочный и финальный. На отборочном можно было заняться сразу несколькими задачами и понять, какая нравится больше (на этом этапе наша задача оказалась одной из самых популярных).
По итогам отборочного этапа мы выбрали шесть команд с лучшими решениями. При оценке решений учитывалось как качество алгоритма, так и продуктовое решение.
В финале было фиксированное число участников, а команда могла участвовать только в одной задаче. Этот этап длился 5 дней — за это время участники решали задачу с нуля. В финал прошли команды из России, Вьетнама и стран СНГ.
Помимо ML-решения командам нужно было разработать сервис, в который они это решение завернут — например, сайт или телеграм-бот.
Сервисы-участники составляли задачи, предоставляли данные и разбирали с командами задачи и оценивали решения.
Задача
ML-часть нашей задачи из финального этапа — научиться распознавать направления движения по полосам на дорожных знаках 5.15.1 и 5.15.2. Это реальная задача, которую мы в 2ГИС решаем, чтобы делать точнее наш дорожный граф.

На этих знаках может быть как одна полоса движения, так и несколько. Максимальное число полос на знаке по условию — пять.
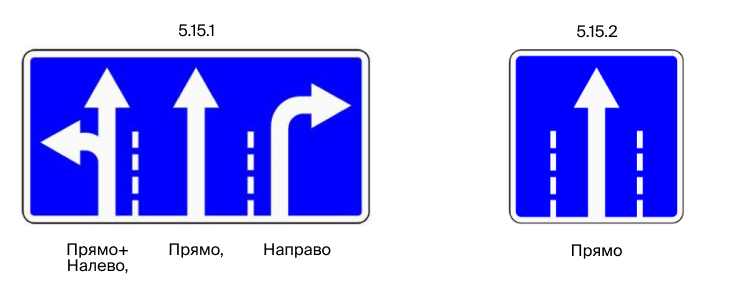
Для удобства изложения введём обозначения: будем отделять разные полосы движения на знаке через запятую. А разные стрелки на одной полосе отделяем плюсом. Например, для знака 5.15.1 с изображения выше метка будет «Прямо+Налево, Прямо, Направо».
Целевая метрика задачи — accuracy:

Что в этом сложного
Да, задача выглядит простой. Но только на первый взгляд. Есть несколько трудностей, с которыми сталкиваешься, если копнуть глубже.
Дисбаланс классов
Знаки собирались с реальных дорог. А на дорогах направления на полосах движения распределены неравномерно. Есть частые направления, например, «Прямо», а есть редкие, например, «Направо с последующим поворотом налево». Хочется правильно распознавать все направления, поэтому этот дисбаланс нужно учитывать при обучении модели.
Комбинации стрелок
Всего в данных было 7 стрелок (на самом деле их больше, некоторые мы убрали из соревнования).

Каждая полоса на знаке может содержать как одну стрелку, так и несколько. Поэтому мы имеем не 7 вариантов ответа на каждую полосу движения, а гораздо больше. Плюс некоторые стрелки несовместимы друг с другом, поэтому задача требует нетривиального подсчёта.
Комбинации полос движения
В конкурсе максимальное число полос на знаке было 5 — в жизни редко встречается больше. То есть полос движения на знаке может быть от 1 до 5. А с учетом того, что каждая полоса имеет множество вариаций стрелок, то и различных комбинаций полос движения со стрелками получается много.
Примеры необычных комбинаций стрелок:

Условия съёмки
Кадры получили с разных видеорегистраторов в разное время суток и разное время года. Поэтому у снимков может быть:
разное качество,

разные ракурсы,

разное освещение,

помехи.

Архитектурные решения участников
За пять дней в среднем каждая команда отправила по 23 решения финальной задачи. Дальше расскажу про архитектурные идеи, которые команды попробовали в финале конкурса.
Классический CV + классификация
Идея
С помощью классических CV алгоритмов искать стрелки, а потом распознавать их классификационной сеткой.

Стоит отметить, что для распознавания стрелок можно использовать как обычную классификацию, так и мультилейбл (на схеме ниже). В данной задаче лучше использовать мультилейбл, чтобы сделать сеть более устойчивой к распознаванию комбинаций стрелок.

Плюсы
Устойчивость к новым комбинациям стрелок в полосах движения. В случае мультилейбл классификации сеть учится выделять отдельные стрелки из комбинации стрелок. Например, если сеть выучила стрелки «Прямо» и «Направо», она выдаст правильное предсказание на их комбинацию — «Прямо+Направо».
Минусы
Настройка CV алгоритмов. Классические алгоритмы компьютерного зрения непросты в настройке, на это можно потратить много времени. А его у участников было немного.
Неустойчивость к качеству снимков. Классические CV алгоритмы неустойчивы к изменениям условий съёмки. А в данной задаче это одна из основных сложностей.
Детекция + классификация
Идея
Для детекции стрелок использовать нейронную сеть вместо классических CV алгоритмов. Это могут быть архитектуры как для сегментации, так и для детекции.

Плюсы
Те же, что у архитектуры «Классический CV + классификация». Ведь основная идея та же — сначала отделить полосы движения, а потом распознать каждое направление на каждой полосе независимо.
Качество детекции. По сравнению с детекцией классическими CV алгоритмами, сети выдают лучшее качество и более устойчивы к изменениям условий съёмки.
Минусы
Доразметка тренировочных данных. В данных на знаке не было разметки полос, которые нужны для обучения детекции. Но мы не запрещали доразмечать тренировочные данные. Стоит помнить, что времени у участников было немного, и важно было правильно распределить свои ресурсы, чтобы всё успеть.
Медленный инференс. Как правило, модели для детекции толстые, поэтому время предсказания может быть медленным.
Только мультилейбл классификация
Идея
Мы знаем, что у нас максимум 5 полос, на каждой из которых могут быть разные варианты из 7 стрелок. Тогда можно закодировать эти 5 полос движения с 7 возможными стрелками в матрицу 5x7, а потом эту матрицу вытянуть в один вектор, который и будет учить модель.
Задача сводится к мультилейбл классификации.
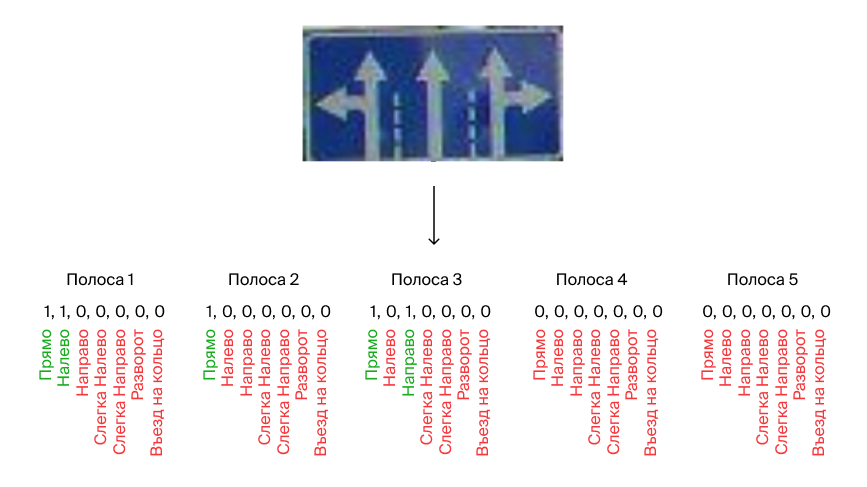
Плюсы
Быстрый инференс. Классификационные сети в глубоком обучении самые шустрые, поэтому время предсказания быстрое.
Устойчивость к новым комбинациям стрелок в полосах движения. Сеть учится выделять отдельные стрелки из комбинации стрелок. Например, если сеть выучила стрелки «Прямо» и «Направо», то она выдаст правильное предсказание на их комбинацию «Прямо+Направо».
Минусы
Неустойчивость к новым комбинациям полос движения. По факту мы кодируем полосы движения в один вектор — значит, их распознавание не независимо. С оговорками можно сказать, что мы привязываемся к комбинациям полос движения. Есть риск, что если, например, сеть научилась хорошо распознавать знак «Прямо, Направо», то так же хорошо распознать «Направо, Прямо» она не сможет.
Многоголовая классификация
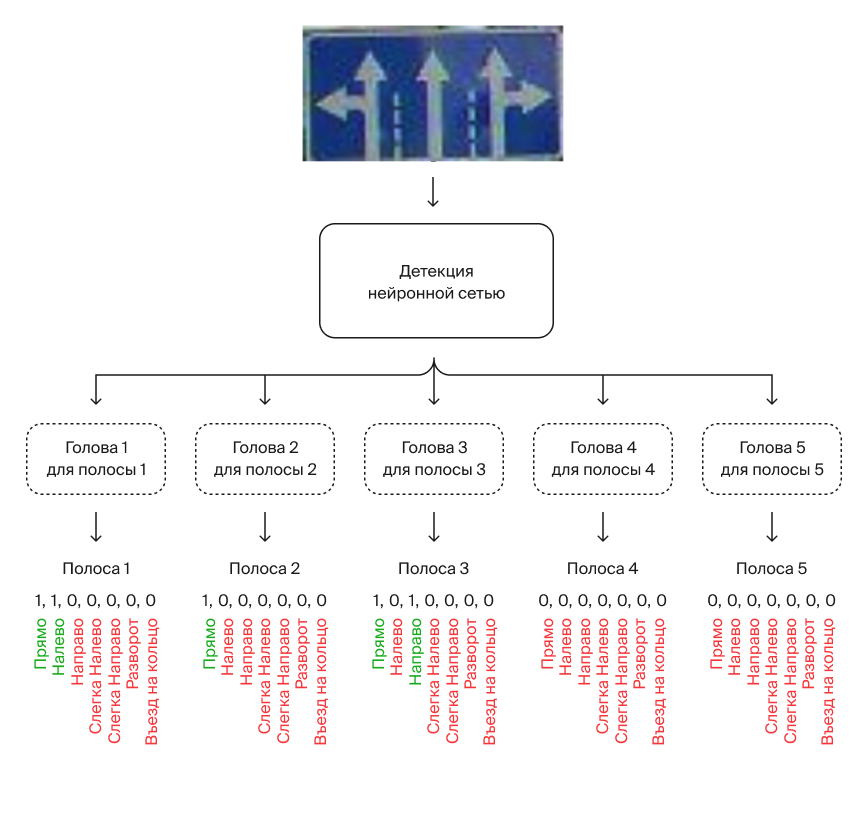
Идея
Под каждую полосу на знаке сделать отдельную классификационную голову, которой будем распознавать стрелки на этой полосе. В итоге получается 5 голов, в каждой из которых 7 выходов.
Плюсы и минусы
Те же, что и у идеи «Только мультилейбл классификация». Идеи похожи, только в этой происходит явное разделение полос движения.
Tips and tricks от участников
Помимо необычных архитектур команды также предлагали интересные способы работы с данными. Вот разные трюки, которые подняли их на лидерборде.
Расширение датасета за счет аугментаций, меняющих метки классов
Некоторые аугментации, такие как горизонтальные развороты, меняют метку изображения. Но можно не отказываться от них, а определить, какие стрелки куда переходят при аугментациях, меняющих метки. Таким образом мы боремся с дисбалансом на зеркальных классах.

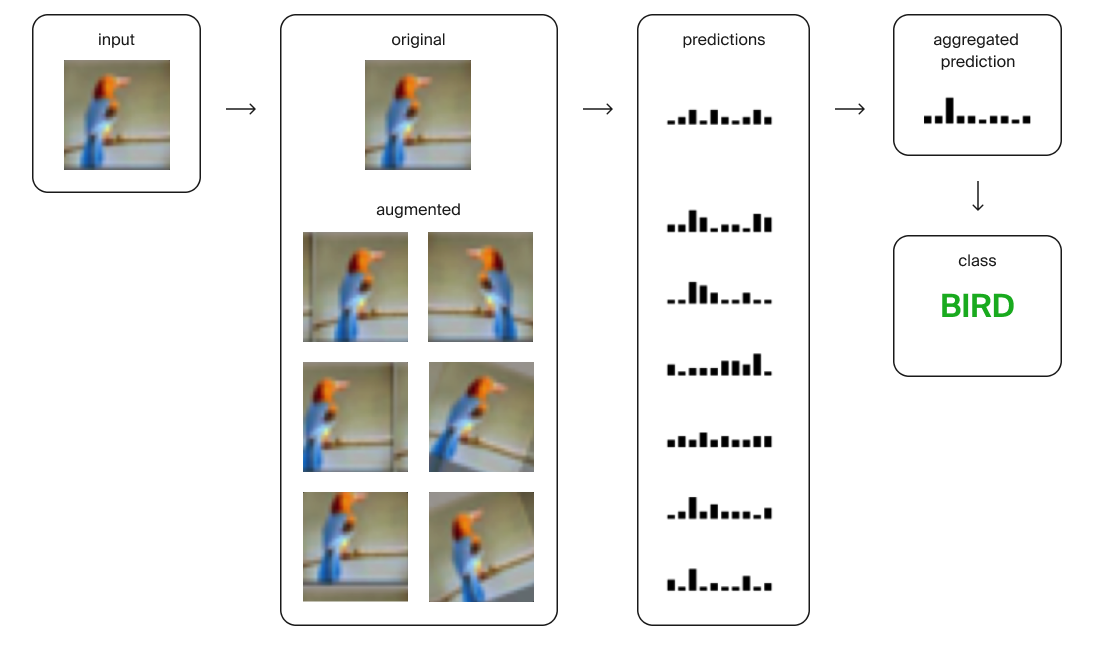
Test Time Augmentation (TTA)
При предсказании тестовой выборки тоже можно аугментировать изображение. Тогда получится несколько похожих изображений с одинаковой меткой. Потом мы усредняем вероятности предсказаний для каждого варианта изображения и получаем итоговую вероятность.
Генерация синтетических данных
Чтобы сгладить дисбаланс классов, одна из команд использовала синтетические данные. Обычно синтетические данные отличаются от реальных. Если учиться только на них, то модель будет хуже ожидаемого (в сравнении с синтетическим тестом или валидацией) предсказывать реальный данные, так как домен смещён. Однако синтетика хорошо походит для предобучения модели.

Стоит также отметить, что эти данные генерировались не отдельной сетью (например, генеративной), а вручную. То есть сама задача генерации такой синтетики требует опыта не только в ML, но и в разработке.
Склейка несколько знаков
Для увеличения числа комбинаций направлений в тренировочных данных участники склеивали два или несколько изображений в одно.

Таким трюком можно получать новые многополосные знаки и увеличивать устойчивость к комбинациям, которых не было в тренировочных данных.
Повышение качества изображений
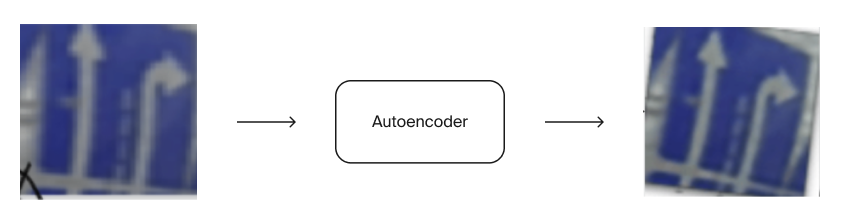
Одна из основных проблем при решении — качество изображений. Поэтому одна из команд решила повышать его перед тем, как распознать направления движения по полосам с помощью претренированного автокодировщика (autoencoder). Команда утверждает, что это подняло качество их модели примерно на 1%. Сама задача в классической постановке называется «задачей повышения разрешения» (super-resolution).
Осталось за кадром
Многие действия при решении ML соревнования кажутся само собой разумеющимися. Мы не стали заострять на них внимание в статье, однако отметим, что участники их выполняли.
Это перебор (grid search) по архитектурам моделей, различным оптимизаторам, скоростям обучения (learning rate), шедулерам (scheduler), порогам и прочим параметрам обучения. Ещё за кадром осталось ансамблирование сеток, которое участники тоже использовали.
В общем, видеокарты работали, вентиляторы крутились, параметры мутились.
Чем мы решаем эту задачу
У нас было гораздо больше времени на эксперименты с различными архитектурами, чем у ребят. Попробовали классификационные модели (без многоголовой классификации) с детекцией полос движения и без неё. Помимо этого экспериментировали с моделями для оптического распознавания символов (OCR). Мы делали свой выбор исходя из соотношения качество/скорость инференса — и в итоге мы остановились на OCR модели.
Идея
Стрелки для полос движения можно считать символами. Тогда используем специальную OCR модель, задача которой — распознавать символы. В конечном итоге мы используем архитектуру, которая показана на схеме ниже.

Плюсы
Устойчивость к новым комбинациям полос движения. Сначала мы выделяем фичи из изображения, а потом передаём их последовательно в RNN сеть. За счёт этого RNN модель не просто заучивает комбинации, а учится определять стрелку на конкретном участке изображения, беря в расчёт предыдущий контекст. Значит, например, комбинация «Прямо, Направо» должна распознаваться также хорошо, как комбинация «Направо, Прямо», даже если второй не было в тренировочных данных.
Средняя скорость инференса. Такой подход работает быстрее, чем детекция вместе с классификацией, однако медленнее, чем просто классификация.
Качество. В наших экспериментах такая модель дала наилучшее качество.
Минусы
Неустойчивость к новым комбинациям стрелок в полосах движения. Алфавит модели состоит из стрелок и их комбинаций. Поэтому если каких-то комбинаций стрелок мало (при том, что стрелок из этих комбинаций может быть достаточно), то эти комбинации могут плохо предсказываться. Эта проблема решается синтетикой и добавлением недостающих данных с боя.
Финал конкурса и статьи
Мы поздравляем команду FTL из Минска, которая одержала победу в AI Journey! Ребята использовали в своём решении модель многоголовой классификации и все трюки на данных, описанные выше (кроме повышения качества изображений).

Спасибо всем, кто принял участие в конкурсе. Было интересно общаться с каждой командой, и смотреть на задачу с новых сторон. Ребята показали очень высокий уровень подготовки. Меньше чем за неделю они не просто создали качественные ML-решения, но ещё сделали для них сервис с публичным API, подготовили и представили своё продуктовое решение.
Мы с командой не ожидали такого от ребят, которые ещё даже школу не закончили! Это очень круто. Желаю им продолжать и дальше развиваться и развивать область машинного обучения. Ребята, если вы читаете Хабр, передаём привет!