
Вступление
Привет! Меня зовут Максим Бондарев, я работаю младшим разработчиком в компании Digital Design и заканчиваю обучение на математико-механическом факультете СПбГУ. В рамках своей исследовательской работы я занимался решением задачи по автоматической генерации протоколов совещаний в составе команды научной лаборатории (aka Конструкторское Бюро) под руководством Максима Панькова. Что из этого получилось, и над чем еще предстоит поработать, расскажу в этой статье.
SumMeet
В крупных организациях в течение одного дня могут проходить десятки собраний, в процессе которых формируется множество бумаг, в том числе протоколов. Это осложняет работу как самих участников совещаний, так и секретарей-референтов: материалы по итогам заседаний формируются несколько дней, замедляется исполнение задач и поручений. Как следствие – недовольные руководители и сотрудники, замученные и уставшие секретари. А если совещание проходит без секретаря, то часть информации может быть просто утеряна.
Для решения этой проблемы мы с коллегами работаем над виртуальным ассистентом для подготовки итогов совещаний - SumMeet. Он может расшифровать аудиозапись встречи и выделить ключевые моменты по итогам онлайн и оффлайн собраний при помощи технологий искусственного интеллекта.

Формирование итогов происходит в 3 этапа:
Распознавание речи в аудиозаписи совещания
Разбиение транскрипта по спикерам
Извлечение из полученной стенограммы наиболее важных моментов совещания
В этой статье мы сфокусируемся на нашем подходе к реализации третьего этапа.
О задаче
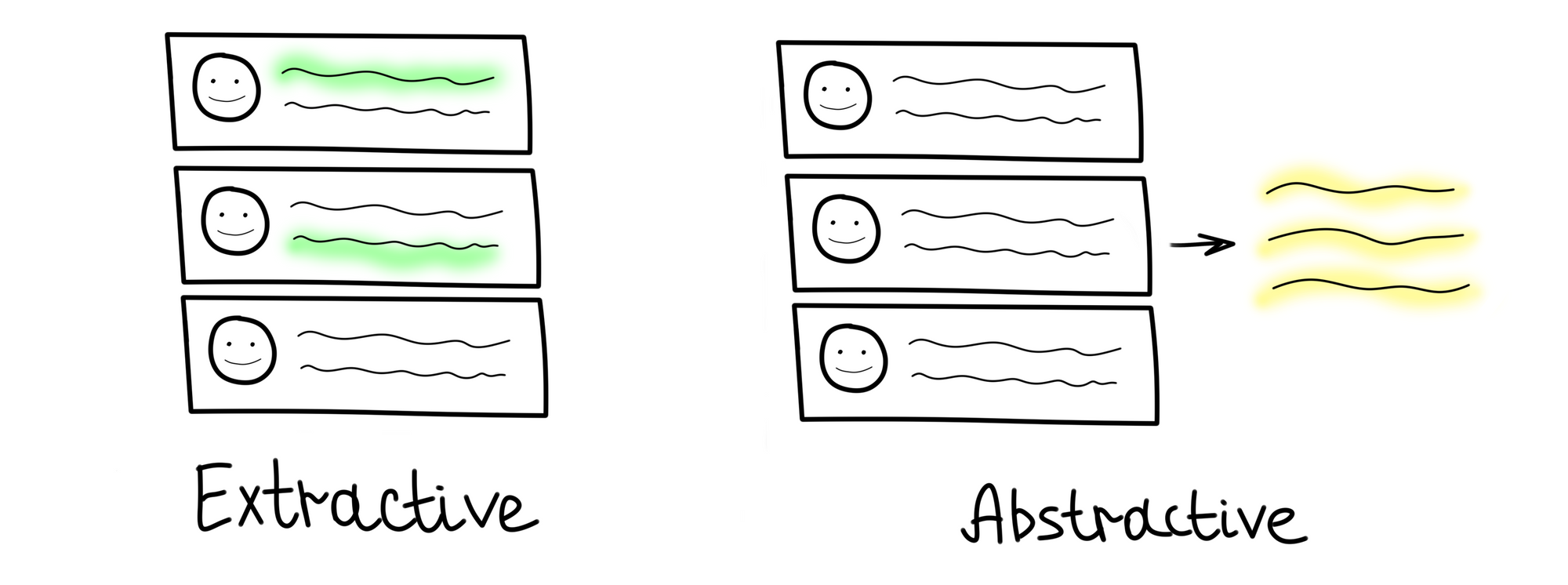
Автоматическое формирование итогов собрания можно назвать задачей суммаризации. Существует два разных подхода к автоматической суммаризации: экстрактивный и абстрактивный.
Экстрактивная суммаризация направлена на выявление важной информации, ее извлечение и группирование для формирования краткого резюме.
Абстрактивная суммаризация предполагает генерацию новых предложений на основе информации, извлеченной из корпуса.
Задача была нетривиальной, и сначала мы отдали предпочтение экстрактивному подходу к суммаризации. То есть нам нужно было предсказывать, к какому классу относится каждая реплика из стенограммы. В терминах машинного обучения эту задачу можно представить как классификацию текстов.
В нашем случае, изучив итоги, составленные вручную коллегами, мы приняли решение остановиться на трёх классах, а именно «Дальнейшие шаги», «Основные моменты» и «Остальное». Класс «Дальнейшие шаги» включает в себя: задачи, призывы к действию и планы, а в класс «Основные моменты» попадают скорее формулировки обсуждаемых вопросов, идеи и решения, принятые на собрании.
Данные
СОЗДАНИЕ СОБСТВЕННОГО ДАТАСЕТА
Чтобы решать задачу классификации, необходимы размеченные данные. Готовых корпусов для суммаризации диалогов на русском языке нет. Поэтому мы начали записывать собственные митинги, используя для получения стенограммы сторонние ASR (Automatic Speech Recognition) решения. Также на этом этапе происходит разбиение стенограммы на высказывания.
Разметка митингов производилась силами двух человек (чаще всего это один из участников митинга) и происходила примерно так: каждое высказывание с митинга относили к одному из классов. Для разметки использовали инструмент для аннотации с открытым исходным кодом - doccano.

АУГМЕНТАЦИЯ ДАННЫХ
Разметка митингов — достаточно трудоемкий процесс, а данные для нас очень важны. Поэтому мы также пытались расширить датасет другими способами.
ПЕРЕВОД
Один из вариантов борьбы с нехваткой данных для обучения — автоматический перевод размеченного англоязычного датасета. На английском языке существует как минимум три корпуса для суммаризации митингов: ICSI, AMI и QMSum. Мы решили, что один из этих корпусов можно попробовать перевести с помощью Google-переводчика и добавить к нашим данным. Выбор пал на AMI Corpus, как на самый популярный из имеющихся.
Мы сравнивали результаты моделей на двух датасетах. Один из них включал только наши митинги, во втором присутствовали наши митинги и переведенные. При обучении только на наших митингах мы получали значение F1-меры в среднем на 15% выше, чем при обучении с использованием AMI Corpus. Возможно, это связано с другой структурой совещаний, а также с ошибками переводчика.
АРХИВНЫЕ ИТОГИ ВСТРЕЧ
До того как мы начали записывать свои митинги, коллеги отправляли итоги совещаний друг другу на почту. Мы решили, что их также можно собрать и попробовать использовать в обучении. Эксперименты показали, что значение F1-меры увеличилось примерно на 10% после добавления "архивных итогов встреч" в обучающую выборку. Они также использовались при обучении актуальной модели.
АВТОМАТИЧЕСКАЯ РАЗМЕТКА
Также были проведены эксперименты по автоматической разметке. Мы использовали написанное человеком резюме, и с помощью него пытались автоматически собрать экстрактивное резюме. Делали мы это с помощью сравнения значений метрики ROUGE-1 каждой реплики из стенограммы с каждым пунктом из протокола встречи, составленного человеком. Такая разметка сильно расходилась с ручной разметкой аннотаторов, и добавление этих данных не дало положительного влияния на результаты модели.
СОСТОЯНИЕ ДАТАСЕТА В ДАННЫЙ МОМЕНТ
400 записанных совещаний (аудиодорожка + стенограмма)
72 совещания с написанным участником протоколом (аудиодорожка + стенограмма + резюме)
28 размеченных совещаний (аудиодорожка + стенограмма + резюме + разметка)
Модели
В этом разделе хотелось бы рассказать о подходах, которые мы пробовали для решения нашей задачи. Подходы разбили на два класса: классические и нейросетевые.
КЛАССИЧЕСКИЕ МЕТОДЫ
Классические модели иногда показывают себя лучше, чем нейронные сети, особенно в случаях когда данных для обучения слишком мало. Именно по этой причине мы не могли их не попробовать.
BOW + Naive bayes
Для начала мы взяли самый простой статистический подход, Bag-of-words с Naive bayes, чтобы использовать его в качестве бейзлайна.
Модель Bag-of-words проста: она строит словарь из корпуса высказываний и подсчитывает, сколько раз в каждом высказывании встречается каждое слово. В результате все высказывания представляются вектором, длина которого равна количеству слов в словаре.
Наивные байесовские классификаторы - это линейные классификаторы, которые известны своей простотой и в то же время эффективностью. Вероятностная модель наивных байесовских классификаторов основана на теореме Байеса, а прилагательное наивный исходит из предположения, что признаки в наборе данных взаимно независимы.
BOW(TF-IDF) + SVM и Logistic Regression
Частота использования слов — не лучшее представление текста. Какие-то слова могут встречаться в высказываниях очень часто, но не нести смысла, например, предлоги. Для решения этой проблемы существует расширенный вариант bag-of-words, в котором вместо простого подсчета используется TF-IDF ("частота слова - обратная частота документа"). В нем соответствующее слову значение увеличивается пропорционально частоте в текущем высказывании, но также уменьшается пропорционально количеству высказываний, в которых встречается слово.
В качестве классификатора мы попробовали один из популярнейших, используемых для текста — SVM и Logistic Regression.
Метод опорных векторов (Support Vector Machine) — это простой алгоритм машинного обучения, используемый для классификации и регрессии.
Основная идея метода заключается в построении гиперплоскости, разделяющей объекты выборки оптимальным способом. Алгоритм работает на предположении: «чем больше расстояние между разделяющей гиперплоскостью и объектами разделяемых классов, тем меньше будет средняя ошибка классификатора».
Логистическая регрессия (Logistic Regression) — модель машинного обучения, используемая для задачи классификации. Логистическая регрессия является частным случаем линейной регрессии: для прогнозирования вероятности принадлежности каждому из классов она использует взвешенную линейную комбинацию входных признаков и передает их через сигмовидную функцию.
Нейронные сети
RNN
RNN (Recurrent neural network) - вид нейронных сетей, элементы которой связаны друг с другом последовательно. Принцип работы рекуррентных сетей очень похож на естественный для человека способ обработки текста: подобно человеку они «читают» последовательность слов одно за другим.
Мы используем усовершенствованную версию RNN — LSTM. Она лучше справляется с главной проблемой рекуррентных сетей, а именно с «забыванием» более ранних фрагментов текста из-за затухания градиентов.
По причине того что у нас небольшой датасет, он может не очень подходить для обучения RNN с нуля. Поэтому мы решили попробовать инициализировать embedding-слои модели предобученными весами Word2Vec.
Word2Vec — это метод для построения векторных представлений слов на основе неразмеченных данных. Word2Vec каждому уникальному слову в корпусе сопоставляет некоторый вектор, обычно размерностью порядка 100. В получившемся векторном пространстве слова, имеющие общий контекст в корпусе, располагаются рядом друг с другом. Для обучения Word2Vec существует 2 разных подхода: предсказывать контекст по каждому слову (Skip-gram), или предсказывать каждое слово по контексту (Continuous Bag-of-Words).
Мы использовали для инициализации весов embedding-слоев предобученные вектора FastText. FastText — это расширение Word2Vec, которое работает на уровне «подслов» (символьных n-грамм), что, в свою очередь, позволяет лучше интерпретировать редкие и неправильно распознанные слова.
BERT-based
BERT
BERT — это языковая модель, основанная на энкодере из архитектуры Transformer. Она превзошла предыдущие SOTA методы во многих NLP задачах, а где-то и человеческие показатели.
В отличие от прежних методов построения векторных представлений, BERT предоставляет контекстно-зависимые представления. Например, Word2vec генерирует единственное представление для одного слова, даже если слово многозначное, и его смысл зависит от контекста. Использование BERT же позволяет учитывать окружающий контекст предложения и генерировать различные представления.
DistillBERT
Помимо обычного BERT мы решили попробовать модель поменьше. Для этого мы использовали DistillBERT, полученный методом дистилляции. Дистилляция использует большую модель в качестве учителя для меньшей модели, которая пытается повторить ее результаты.
RoBERTa
Также в качестве более новой альтернативы BERT мы попробовали модель RoBERTa от Facebook. RoBERTa основана на той же архитектуре, но отличается методикой обучения и затраченными вычислительными мощностями.
Чтобы улучшить процедуру обучения, RoBERTa удаляет задачу предсказания следующего предложения (Next Sentence Prediction) из предварительного обучения BERT и вводит динамическое маскирование, так что маскируемый токен меняется в течение эпох обучения.
Все три варианта моделей мы дообучили под нашу задачу на собственных данных, взяв их предварительно обученные версии для русского языка.
Ссылки на предобученные BERT-based модели, которые мы использовали:
Результаты экспериментов
Результаты проведенных экспериментов с перечисленными выше моделями представлены в табличке ниже. Модели упорядочены по F1-мере (макро и без учета фонового класса) от лучшего результата к худшему. Данную метрику использовали из-за сильного дисбаланса классов.

Лучшей оказалась модель DistillBERT от DeepPavlov, которая была предобучена на разговорной речи в большей степени на социальных сетях и субтитрах к фильмам.
Также мы провели исследование, в ходе которого участников митингов попросили сравнить протокол, составленный моделью, с протоколом, составленным человеком, оценив важность каждого из пунктов протокола. В процессе исследования использовалась модель, которая сейчас занимает только 7 строчку в таблице. И участники в среднем оценивали важность добавленного итога совещания на 3.5 из 5.

Проблемы экстрактивной суммаризации
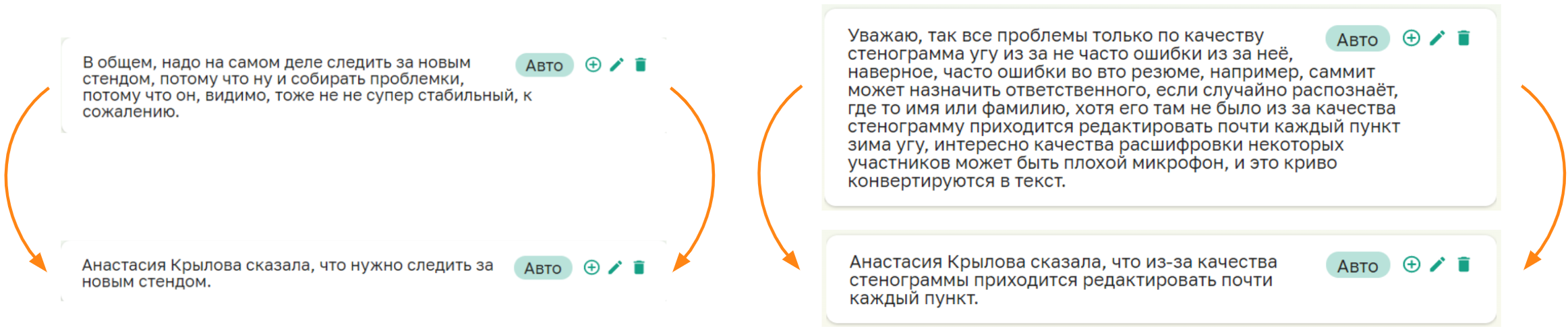
Результаты экспериментов нас порадовали, но экстрактивный подход сам по себе не позволяет достичь уровня качества, сравнимого с человеческим. Здесь хорошо подходит комментарий одного из участников исследования по оценке качества резюме: "Почти каждый фрагмент из итогов необходимо отредактировать перед тем, как занести его в протокол". И вызвано это следующими тремя проблемами:
Реплика вырвана из контекста. Итог может не включать в себя некоторую важную информацию, потому что о ней говорилось либо в другое время совещания, либо только подразумевалось.
Ошибки ASR. Произнесенная информация может сильно исказиться из-за ошибок распознавания речи.
Устная речь отличается от письменной. Как мы заметили, произнося свои мысли на митингах, люди формулируют их совершенно иначе, чем при записи в протокол.

Если все перечисленные проблемы встречаются в одном пункте протокола, мы получаем "набор слов", по которому не всегда можно понять, о чем именно говорил человек.
Планы
ГОЛОСОВОЙ ПОМОЩНИК
В связи с выше перечисленными проблемами мы решили, что стоит добавить возможность явно обращаться к модели. Такую функциональность мы подсмотрели у одного из иностранных конкурентов.
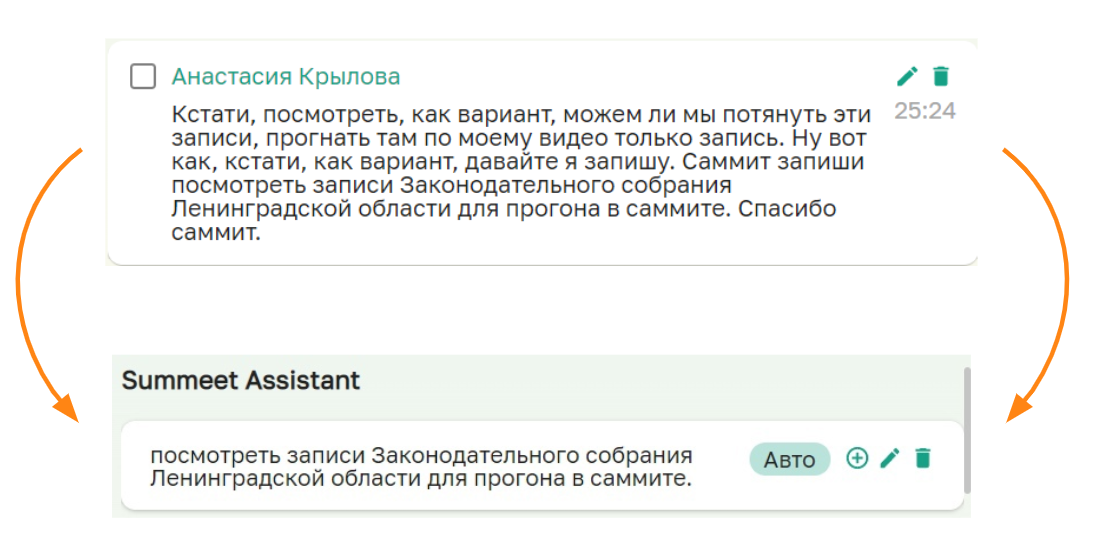
На совещании человек может произнести "Саммит, запиши" или "Саммит, поставь задачу", после этого сказать важную информацию, которую ему не хотелось бы потерять, и, наконец, завершить свою мысль словами "Саммит, спасибо", чтобы дать понять, где именно она заканчивается.
Если участник митинга попросил ассистента что-то записать, это попадет в отдельный блок протокола, и человек может быть уверен, что эта информация не будет утеряна. Если же на совещании попросили поставить задачу, а также произнесли имя исполнителя и срок выполнения, то её можно отправить в задачник автоматически с использованием Named Entity Recognition. На данный момент мы уже тестируем обращение к модели на наших митингах.
Этот подход помогает нам решить проблемы №1 и №3 из предыдущего раздела. Самое интересное, что решаются они не из-за улучшения модели (модель используется та же), а скорее из-за того, что спикер начинает формулировать свои мысли иначе после обращения к боту.

Главная проблема данного подхода в том, что не все форматы совещаний допускают обращения к боту по ходу заседания, и не все люди готовы менять свое поведение. Кроме того, мы не избавляемся с помощью этого подхода от ошибок ASR.
АБСТРАКТИВНАЯ СУММАРИЗАЦИЯ
В то же время мы начали работы по применению абстрактивного подхода к суммаризации. На данный момент мы используем предобученную модель T5 от Сбера для перефразирования полученных с помощью экстрактивного подхода минуток. Протоколы стали более читаемыми, но их информативность все еще сильно зависит от качества экстрактивной суммаризации.
С помощью абстрактивной суммаризации мы способны решить все проблемы, перечисленные в прошлом разделе, но пока наши эксперименты находятся на начальном этапе и требуют доработок.
У нас есть много дальнейших планов по решению этой задачи. Приведу несколько примеров:
Перевод англоязычных корпусов под задачу абстрактивной суммаризации.
Адаптация новостного датасета под формат митингов (как в HMNet).
Продолжение сбора своего датасета под задачу абстрактивной суммаризации.
Дополнительные эксперименты по перефразированию экстрактивных минуток.
Декомпозиция задачи на более мелкие части, такие как разбиение митинга на топики, их классификация, и только уже потом суммаризация этих частей.
Заключение
Разработка решения еще ведется, поэтому мы будем очень рады услышать любые советы, предложения, а также критику. Постараемся по мере продвижения выкладывать новые статьи по суммаризации и по другим аспектам нашего продукта.
Комментарии (3)

kochetkov-ma
27.12.2021 08:03Очень круто! Правда у меня с первого абзаца возникло чувство, что без голосового помощника не обойтись. Даже, если человек ведёт протокол, пока ему явно не скажешь, на что-то обратить внимание и проговоришь это повторно ничего не получится. Неплохо было бы проконсультироваться с опытными людьми из бизнеса, у которых множество митингов в день. Если у вас цель не само исследование, а создание приложения, то это было бы эффективно.
LuchS-lynx
Это локальное решение или облачное через личный кабинет на Вашем сайте/обернутое в приложение WEB-страница?