

В 2012 году мы запустили первую версию сервиса «Битрикс24», который с тех пор успешно растёт и развивается. Сегодня его надежную работу обеспечивает обширная инфраструктура, разбросанная по 17 дата-центрам по всему миру. Наши команды регулярно проводят митапы, на которых делятся друг с другом всевозможными знаниями и накопленным опытом. О многом из этого будет интересно почитать и вам, поэтому мы подготовили цикл статей об истории развития нашего сервиса.

Как всё начиналось
До 2011 года мы — компания «1С-Битрикс» — выпускали только коробочные продукты. То есть сервисного обслуживания не предлагали совсем. Из инфраструктуры у нас было всего два сайта — 1с-bitrix.ru и bitrixsoft.com, которые жили на выделенном сервере в американском дата-центре. И в январе 2011 года там сломался RAID-контроллер. Провайдер сказал, что на ремонт и замену уйдёт три дня. Мы начали думать, где срочно развернуть сайты. Поинтересовались, удастся ли переехать на российский хостинг, однако из-за долгих новогодних праздников нам не могли быстро предложить даже серверы типовых конфигураций, а у нас ещё и были нестандартные потребности по количеству ядер, памяти и дискам — приходилось обрабатывать уже довольно большой объем данных.
Это сегодня, 11 лет спустя, рынок предлагает выделенные серверы с развёртыванием за считанные часы, и облака на любой вкус, которые можно получить за несколько минут. А в те годы был дефицит дата-центров, а ещё и январские каникулы на дворе. Лучшее, что нам предлагали, это за день-два собрать типовой сервер, а о быстром переезде речи вообще быть не могло. Тогда мы решили перебраться в Amazon, о котором мало что знали.
Идём в облако
В том же 2011 году мы начали проектировать облачный «Битрикс24». Было сложно предугадать точные темпы роста, поэтому нам нужно было научиться быстро масштабироваться. Но чтобы не вылететь в трубу, мы хотели избежать серьёзных капиталовложений в инфраструктуру. Вторым важным критерием была надёжность сервиса. Кроме того, всё это нужно было обеспечить с учётом выхода на несколько рынков: в том же месяце мы зарегистрировали домены bitrix24.com, bitrix24.de и bitrix24.ru.
Задачи были понятные, но немного противоречивые. Дело в том, что мы хотели предлагать наш сервис в том числе и бесплатно, но чтобы он оставался функциональным и удобным для маленьких компаний. Поэтому нам было важно минимизировать себестоимость. Облачная инфраструктура подходила нам как нельзя лучше: не нужно вкладываться в капитальные затраты на старте проекта, можно автоматически масштабироваться при любых колебаниях нагрузки.
У Amazon было очень много полезных дополнительных сервисов и важных для нашего бизнеса зон доступности, что позволило нам многое не делать самим с нуля, а использовать готовые решения для быстрого старта. И 3 февраля 2011 года мы развернули в этом облаке прототип «Битрикс24». Скорее даже не прототип, а демо-лабораторию для проверки концепции облачного развёртывания.
Погоняв её какое-то время, мы составили целый список доработок в продукт. В течение года написали модуль clouds для работы с облачными файлами и модуль кластера для распределения нагрузки на мастер и слейвы.
Новая архитектура
В августе 2011 года случилась одна из самых крупных аварий в истории Amazon: обесточился ирландский дата-центр. Всё наше условное резервирование разом рухнуло. Мы поняли, что нужно разрабатывать архитектуру, которая позволит резервировать информацию на уровне целых дата-центров. И в итоге пришли к такой схеме в рамках одного региона:
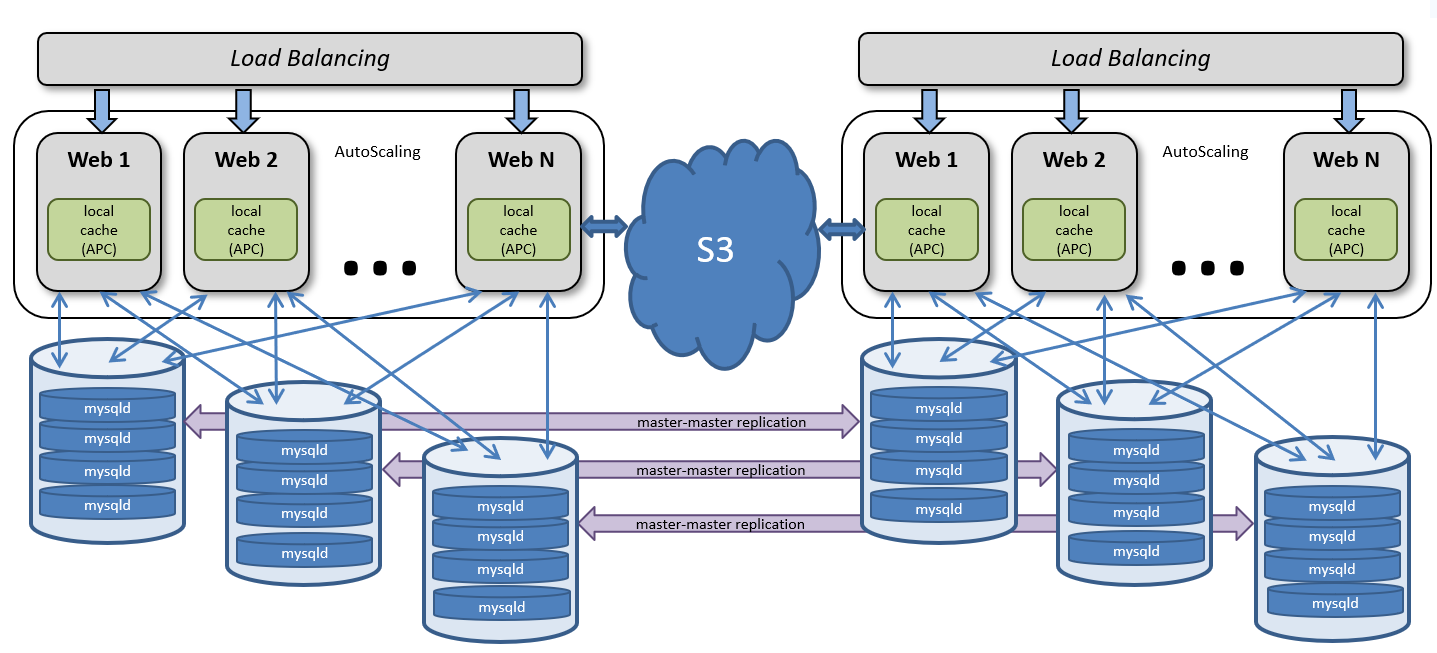
Получается своеобразное горизонтальное масштабирование машин с базами данных клиентов. На каждой виртуальной машине работает четыре экземпляра MySQL, хотя так было не всегда. Эту практику мы ввели, когда обнаружили, что на мощном сервере несколько экземпляров MySQL работают гораздо эффективнее одного огромного с кучей БД: ресурсы используются полнее, можно гибче подключать диски, каждый экземпляр работает на своём порту, и так далее.
Файлы содержатся в объектном хранилище, это позволяет не хранить на серверах приложений пользовательские данные. И мы можем работать с любыми виртуальными машинами, которые выполняют код PHP, как с расходным материалом — в любой момент удалять и добавлять.
Какие сценарии мы отрабатываем? Если выходит из строя один из серверов приложений, мы автоматически или вручную убираем его из группы балансировки, и балансировщик начинает распределять нагрузку на оставшиеся машины. Если выходит из строя сервер БД, то мы переводим трафик на другой сервер и останавливаем в этой паре репликацию master-master. После восстановления базы снова включаем её в работу и восстанавливаем репликацию.
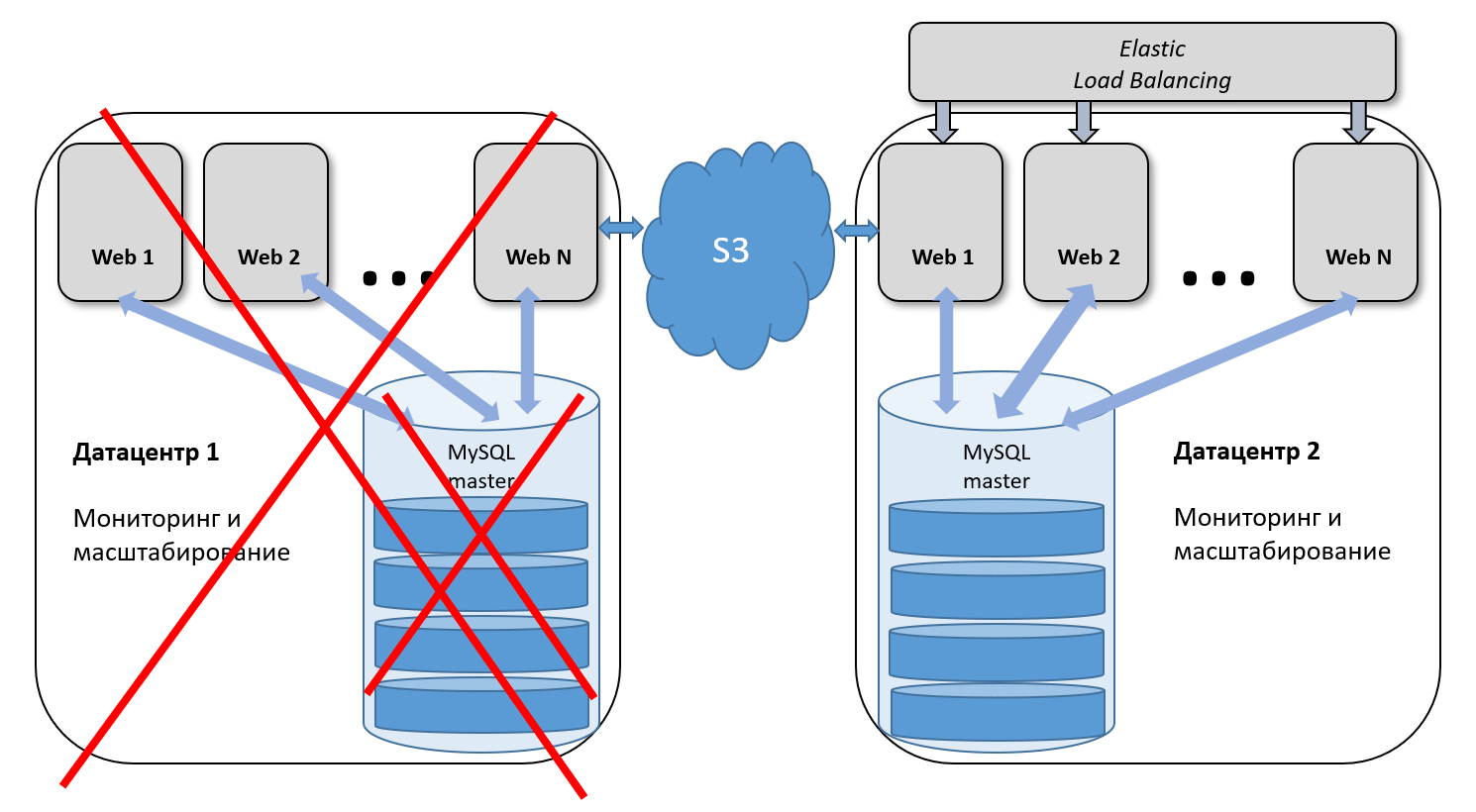
Так мы не только отрабатываем аварийные ситуации, но и незаметно для клиентов проводим плановые работы, которые, конечно же, происходят чаще, чем аварии.
Наши дата-центры
Сегодня у нас 17 дата-центров, и все они очень разные по своему наполнению и функциям. В каких-то развёрнута обширная инфраструктура с многочисленными данными, в других дата-центрах может стоять один-единственный сервер с балансировщиком. Основные наши ресурсы размещены в США, Европе и России. По одному дата-центру развёрнуто в Южной Америке, Индии и Сингапуре. В отдельных странах развернута полноценная инфраструктура для соответствия местным законам.

В следующей статье мы расскажем о том, как у нас организована работа с MySQL, почему в нашем сервисе использована именно такая схема реплиции и какие проблемы она решает.
v_kalmykov
Познавательно)