

Некоторое время назад у нас назрела необходимость в разработке нового push-сервера для сервиса «Битрикс24». Предыдущий вариант, реализованный на базе модуля для Nginx, имел ряд особенностей, которые доставляли нам немало хлопот. В результате мы поняли — пора делать push-сервер. Здесь мы хотим рассказать о том, как это происходило.
Push-сервер (он же pulling-сервер, он же сервер мгновенных сообщений) предназначен для быстрого обмена сообщениями между пользователями, которые заходят на портал через браузер или подключаются с помощью настольного или мобильного приложений. И браузеры, и приложения устанавливают и держат постоянное соединение с push-сервером. Обычно это делается с помощью WebSocket, а если эта технология не поддерживается браузером, то используется Long Polling — постоянный долгий опрос. Это Ajax-запрос, который в течение 40 секунд ждет ответа от сервера. В случае получения ответа или при наступлении таймаута, запрос повторяется. Сейчас большинство наших клиентов сидят на WebSocket.
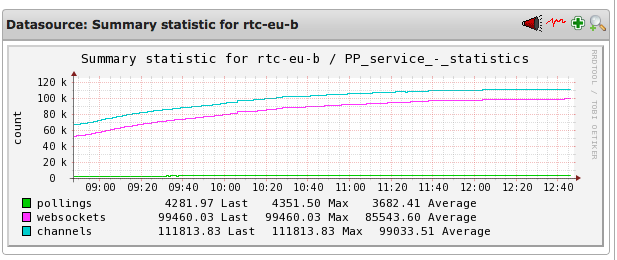
Pollings — количество соединений по технологии long-polling.
Websockets — количество соединений по технологии WebSockets.
Channels — количество каналов.
Что нас не устраивало
Предыдущий сервер работал следующим образом: система публиковала в nginx-модуль сообщения для пользователей, а он уже отвечал за их хранение и отправку адресатам. Если нужный пользователь был в онлайне, то получал послание сразу же. Если же пользователь отсутствовал, то push-сервер ждал его появления, чтобы переслать накопившиеся сообщения. Однако nginx-модуль часто падал, и при этом терялись все неотправленные сообщения. Это было бы полбеды, но после каждого падения модуля сильно возрастала нагрузка на PHP-бэкенд.
Связано это был с особенностями архитектуры push-сервера. Когда клиент устанавливает соединение, то ему присваивается уникальный идентификатор канала. То есть пользователь слушает некий канал, а порталы пишут в него сообщения. Причем таким правом обладают только порталы, это сделано ради безопасности, чтобы снаружи никто не мог писать в этот канал.
Чтобы канал был создан, портал должен его инициализировать, отправив сообщение. И когда nginx-модуль падал, то все каналы обнулялись и все порталы начинали одновременно создавать новые каналы в push-сервере. Получался своеобразный DDoS: PHP на бекенде, где работают порталы, переставал отвечать. Это была серьезная проблема.
Обнуление накопленных на push-сервере сообщений было не слишком большой проблемой, ведь они дублируются на порталах, и пользователь все равно их получал при обновлении страницы. А вот DDoS была проблемой куда серьезнее, ведь из-за него могли оказаться недоступны порталы.
Новый push-сервер
Новый сервер решено было написать с нуля. В качестве среды разработки мы решили взять Node.js. До этого мы не работали с этой платформой, но нас подкупило то, что с ее помощью можно создать сервис, который будет держать очень много соединений. Кроме того, у нас много разработчиков, использующих JavaScript, поэтому было кому поддерживать новую систему.
Важным условием было сохранение совместимости с протоколом, по которому работали с предыдущим сервером. Это позволяло не переписывать исполняемую в браузере клиентскую часть, реализованную на JavaScript. Также можно было оставить нетронутой и PHP-часть бэкенда, которая транслирует сообщения в push-сервер.
Сначала был сделан небольшой прототип, чтобы проверить работоспособность. Функциональность его была ограничена, и все сообщения он хранил прямо в памяти процесса Node.js. Поскольку push-сервер должен держать десятки тысяч соединений одновременно, мы внедрили в свою разработку поддержку кластеризации. Сейчас в российском сегменте работает push-сервер, состоящий из шести процессов нашего Node.js-приложения, обслуживающих входящие соединения, и двух процессов, отвечающих за публикацию сообщений.
Хранить сообщения в памяти, как это было сделано в прототипе, в готовом продукте было нельзя. Допустим, на портале находятся несколько пользователей, чьи запросы обрабатываются разными процессами. Если эти пользователи находятся в общем чате, то все сообщения из него должны одновременно рассылаться всем участникам. А поскольку область памяти каждого процесса изолирована, то хранить сообщения в памяти push-сервера нельзя. Конечно, можно было бы сделать что-то наподобие shared memory, но этот подход не слишком надежен и удобен в реализации, поэтому мы решили хранить все сообщения в Redis. Это NoSQL key-value хранилище, наподобие memcache, только более продвинутое. В нем могут храниться не только ключ-значение, но и ключ-словарь, ключ-список, то есть более сложные структуры данных. Поэтому мы используем Redis для хранения всех сообщений, статистики по каналам и состояние онлайна.
Также в Redis есть полезная функция — подписка на канал. То есть все наши восемь процессов Node.js-приложения имеют постоянное соединение с Redis. И если в него записывается какое-то сообщение, то оно потом приходит всем процессам, подписанным на добавление сообщений. Общая схема такая: пользователь пишет какое-то сообщение на портале, оно идет на бэкенд в PHP, там оно сохраняется, а потом отправляется в Node.js-приложение. В самом сообщении содержатся все атрибуты данных, то есть автор, адресат и т.д. Один из двух процессов, отвечающих за публикацию сообщений, принимает этот запрос, обрабатывает его и публикует в Redis. Тот записывает сообщение и сообщает другим шести процессам о том, что поступило новое сообщение и его можно разослать подписчикам.
Для работы с WebSocket мы использовали open source модуль Node.js под названием ws.
Возникшие трудности
У нас не возникло каких-то особых затруднений на этапе разработки. На этапе тестирования мы сделали упор на эмулирование высокой нагрузки, тесты показали хорошие результаты. При развертывании новой системы мы подстраховались, оставив на первое время в работе старый сервер. Все сообщения дублировались, чтобы в случае падения нового сервера можно было переключиться на старый.
Как выяснилось, подстраховались мы не зря. После развертывания выяснилось, что в ряде случаев, когда нагрузка существенно возрастала, происходило падение системы. С одной стороны, тесты подтвердили способность нашего сервера держать очень большую нагрузку. Но все же это не «настоящая» нагрузка: пользователи заходят с разных IP, каналов, браузеров, у них по-разному реализована поддержка WebSocket.
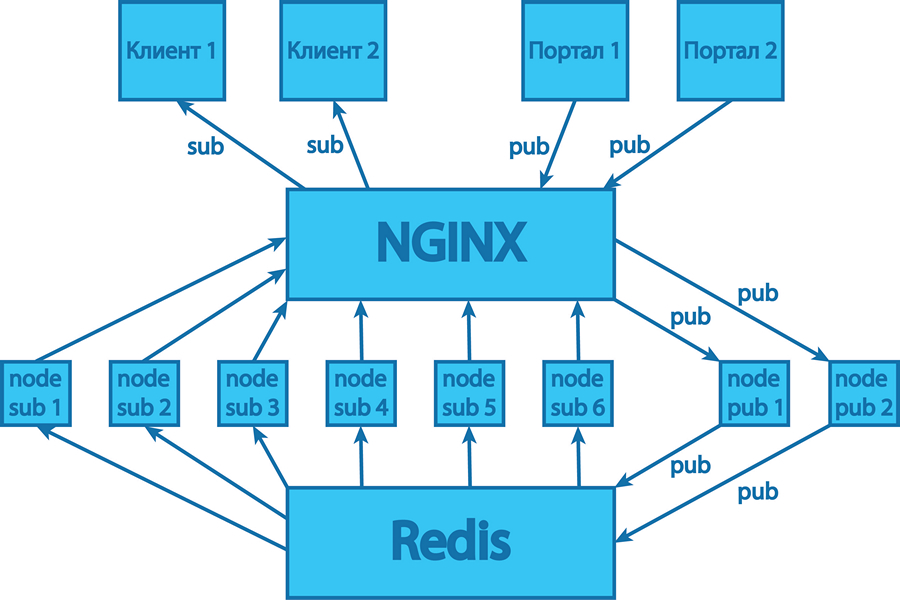
Нам так и не удалось выяснить, почему происходило падение. Проблема возникала на этапе установки TCP-соединения, поэтому решили перевести его обработку на хорошо знакомый и умеющий держать очень много соединений nginx-сервер. При этом Node.js-процессы стали выступать в роли backend-серверов. В новой схеме мы убрали несколько звеньев, а именно:
- Утилиту PM2, использовавшуюся для запуска процессов Node.js-приложения в кластерной конфигурации. Она следит за состоянием процессов, показывает красивые графики использования СPU и памяти, умеет перезапускать упавшие процессы. Эту утилиту мы заменили собственными скриптами.
- Модуль кластера, входящий в Node.js и помогающий запускать несколько процессов одного приложения. Балансировкой запросов теперь занимается сам nginx.
- Модуль обработки HTTPS-соединений. Сейчас этот протокол обрабатывается самим nginx.
В результате схема работы сервера стала выглядеть следующим образом:
Внесенные улучшения
После реализации сервиса стало видно, что можно улучшить. Например, мы оптимизировали протокол и стали экономить ресурсы на некоторых операциях.
В частности, ограничили срок хранения разных типов сообщений. Раньше у нас все сообщения хранились достаточно долго, например, сутки. Но не все сообщения стоило держать на сервере столько времени. Например, сервисные сообщения о том, что кто-то начал писать в чате, не должны жить больше двух минут, потому что они теряют актуальность.
А вот личные сообщения нужно хранить достаточно долго, чтобы доставить их адресату даже спустя несколько часов после отправки. Например, пользователь закрыл ноутбук и ушел с работы, с утра открыл и сразу получил накопившиеся сообщения. Или свернул приложение в мобильном телефоне, а вечером развернул и увидел комментарии, которые подтягиваются без перезагрузки страницы. А вот сообщения о том, что кто-то вошел в онлайн или том, что кто-то начал писать, не должны жить дольше считаных минут. Так мы сэкономили на количестве сообщений, хранящихся в памяти.
Также мы улучшили безопасность работы с push-сервером. Когда пользователь присоединяется, то получает уникальный идентификатор канала — это случайная строка из 32 символов. Но если ее перехватить, то можно слушать чужие сообщения. Поэтому мы добавили специальную подпись, уникальную для этого конкретного идентификатора канала. Сами каналы регулярно меняются, как и их идентификаторы.
Сам канал хранится на сервере 24 часа, но запись в него осуществляется не более 12 часов. Остальное время хранения необходимо для того, чтобы пользователь смог получить ранее отправленные сообщения. Ведь если вечером ноутбук уснул с одним идентификатором канала, то утром он проснется с ним же и обратится на сервер. После отправки сообщений сервер закрывает старый канал и создает для этого пользователя новый.
* * *
После всех проведенных доработок и оптимизаций мы получили новый стабильно работающий push-сервер, выдерживающий высокие нагрузки. Однако его доработка на этом не закончена, есть еще ряд вещей, которые мы планируем реализовать и оптимизировать. Но это уже история на будущее.
Комментарии (41)

aleks_raiden
15.07.2015 11:35А как теперь в этой схеме работает Nginx с нодой? Или там простое транслирование запросов? Или терминирует на себя вебсокеты и http, а к нодам ходит по другому протоколу?

compote
15.07.2015 11:53+1Да, Nginx просто проксирует запросы на node-процессы, выступая в роли балансировщика. Плюс берет на себя обработку TLS.
erlyvideo
15.07.2015 11:42Ничего удивительного: выбрали плохую технологию (Node.js) и потом успешно боролись с её непригодностью для программирования: невозможность использования памяти для обработки данных.
В итоге вы не непригодной нодой пользуетесь, а редисом.
n1ce22rus
15.07.2015 12:13+4Чем плох Node.js?
erlyvideo
15.07.2015 14:35-4во-первых, как верно подметил автор текста, Node.js не годиться для хранения и обработки данных в памяти из-за мультипроцессной архитектуры.
Писали бы на Erlang, Java или Go, можно было бы обойтись _одним_ демоном, а это проще отлаживать, развертывать и контролировать.
Во-вторых, Nodejs — это беспощадные коллбеки или промисы, которые не много чем лучше. Отследить, куда утекла память невозможно, да и не нужно, потому что в отличие от эрланга, который может не поперхнувшись использовать 200 гигабайт, а потом обратно сдуться до 500 мегабайт, у Node есть ограничения в памяти по лимиту.
А память — это один из самых быстрых способов хранить и обрабатывать информацию. Просто люди из мира PHP это боятся и не привыкли к этому, ведь в PHP надо всегда пользоваться внешней работающей БД из-за непригодности самого языка.
Плюс, конечно, никакой интроспекции работающей системы в рантайме, как в Эрланге нет и не планируется.
mayorovp
15.07.2015 13:05+2С использованием памяти для обработки данных в ноде все хорошо, проблемы у автора начались при использовании памяти для хранения данных. Но эта же проблема присутствует и в других языках — так для того СУБД и изобрели.
erlyvideo
15.07.2015 14:36нет, у него проблемы именно с оперативным обменом данными.
mayorovp
15.07.2015 14:49Что вы понимаете под «оперативным обменом данными»? Кто и с кем обменивается?
erlyvideo
15.07.2015 16:04источник данных с клиентами.
Плюс я так и не понял, умеют ли они pollmayorovp
15.07.2015 17:04Не понимаю. В статье про него ничего не говорилось. Нельзя ли подробнее?
erlyvideo
15.07.2015 18:58Если пуш сервер поддерживает только веб-сокеты, то дела очень плохи, потому что вебсокеты до сих пор не везде проходят. В некоторых местах их режут, где-то даже кешируют плохой ответ. Одни лишь вебсокеты не очень подходят для пуша.
mayorovp
16.07.2015 19:41Вы начали с утверждения, что у node.js есть проблема оперативного обмена данными между источников данных с клиентами — и вдруг перескочили на poll… я все еще не понимаю, что вы пытаетесь сказать.



bertmsk
15.07.2015 11:57Это ничего что WebSocket допускает только 1 коннект на сайт? Т.е. открыв вторую вкладку, например в Хроме, получим пресловутое «ожидание свободного сокета»
aleks_raiden
15.07.2015 12:08Это сильно зависит от браузера. Ну и обходится одной строкой в DNS-настройках поддомена и одно строкой на клиенте — заодно получаем DNS-балансировку
erlyvideo
15.07.2015 14:37конечно наплевать. Равно как и то, что одними вебсокетами жив не будешь: их режут DPI системы у глупых провайдеров.

rustem_ck
15.07.2015 12:10+1Хотелось бы больше деталей увидеть. Например,
— почему ws, а не socket.io?
— почему всё-таки ушли от pm2?
— c чем именно связано равное к-во использования клиентами long polling & websocket?
ainu
15.07.2015 12:30Тоже интересует первый вопрос. Предполагаю, что вместо использования клиентского готового socket.io написан клиентский велосипед.
compote
15.07.2015 12:45Клиентская часть уже была написана. И велосипедов там нет. Обработка Ajax-запросов и вебсокет-событий — это минимум кода. Основная часть клиентской библиотеки занимается обработкой данных, которыми обмениваются клиент и сервер.
compote
15.07.2015 12:34+1почему ws, а не socket.io?
Socket.io сам внутри себя использует ws. По статистике npm, ws самый популярный модуль для вебсокетов. Плюс ряд тестов показывают, что он еще и самый быстрый.
почему всё-таки ушли от pm2?
Отказались, как от возможной причины внезапных зависаний системы. PM2 запускало приложение в режиме кластера и выполняло роль балансировщика.
c чем именно связано равное к-во использования клиентами long polling & websocket?
Видимо не совсем понятный график получился :). На нем изображено 100 тысяч вебсокетов и 5 тысяч lp-запросов.rustem_ck
15.07.2015 12:36Нет, всё ясно, спасибо за ответы.
Но разве WS поддерживает longpolling?
Насколько мне известно socket.io поддерживает всё, а вот WS, только websocket?
поправьте если ошибаюсь.
Спасибо за ответы :)

martovsky
16.07.2015 10:23у socket.io навернуто сверх нативного websocket очень много. мы его не используем по этой причине — есть сервисы на C#, которым тоже нужно общаться с сервером сообщений, и придется эмулировать «протокол» socket.io, и если они что-то поменяют — все просто может перестать работать. erinarios ws — это нативный websocket.
а так конечно socket.io очень удобный и в нем много чего из коробки есть.aleks_raiden
16.07.2015 10:43Можно было SockJS использовать тогда.
Но все уже написано — socketio4net.codeplex.commartovsky
16.07.2015 11:35Released: Jun 26, 2012
по-моему наши как раз его и использовали (ребята тогда нашли только одну либу для этого), но автор на него давно забил. либа работает только с версией socket.io 0.9 и младше, а в 1.x они уже сильно поменяли протокол. поэтому и решили нативный брать, без наворотов.
я когда писал comet-сервер перебрал много разных компонентов — у каких-то на тот момент wss был криво реализован, кто-то не мог проксировать запросы по части урла на одном ip на upgrade
var httpProxy = require('http-proxy'); var proxy = httpProxy.createProxyServer({}); function proxyWebsocketResponse(req, res, head) { try { var pathname = url.parse(req.url).pathname; if ( (config.comet.websocket.proxy) && (pathname === config.comet.websocket.path) ) { var options = { target: 'ws://' + config.comet.websocket.host + ':' + config.comet.websocket.port + '/', ws: true }; proxy.ws(req, res, head, options); proxy.on('error', function(e) { console.error('WebSocket error: ' + e.message); res.end(); }); } else { res.statusCode = 501; res.end('Not Implemented'); } } catch (e) { console.error('Error: ' + e.message); } } httpServer.addListener('upgrade', proxyWebsocketResponse);
поэтому был выбран ws
mayorovp
16.07.2015 14:35А вариант отдельного протокола для связи с сервисами на C# не рассматривался?..
martovsky
16.07.2015 15:13незачем. ui, comet и различные сишные демоны — это отдельные распределенные компоненты продукта.
mayorovp
16.07.2015 18:28Не почему же «незачем»? Чтобы свой велосипед вместо socket.io не писать…
martovsky
16.07.2015 19:37кому «велосипед», а кому успешно и понятно уже год работающий компонент в составе продукта используемого ведущими сотовыми операторами.
я не пионер и не склонен писать «велосипеды», это была осознанная необходимость, в том числе и по безопасности.


GHostly_FOX
15.07.2015 14:08+1Дааа я тоже ждал более технического описания, примеров, аналитики по скорости работы по сравнению с предидущим решением… :(
dgstudio
15.07.2015 21:03Почему Redis, а не Rabbit?
Rabbit как-то более предназначен для каналов (очередей) сообщений, да и с роутингом значительно интереснее.
Alexeyco
Выходит, у вас новый push-сервер? Все достаточно тривиально — node, redis, websockets. То есть, он у вас просто… есть? И все? И это в «разработке»?
AlexSerbul
Ну, я могу также сказать — взяли с++, компилятор и написали. Что тут особенного? :-)
Дело в том, что когда дело дошло до production-ready сервера быстрых коммуникаций, оказалось, что на рынке нет ничего адекватного, кроме глючного модуля для nginx, внутри которого был необновляемый копипаст ядра nginx :-)
Писать большой плагин для nginx, исходники которого недокументированы — пустая трата времени и сил. Аналогом модели nginx является, с небольшой натяжкой — NodeJS. Имхо решение получилось сбалансированное как по выбору технологии, так и по отдаче.
Alexeyco
Заходя в статью из хаба «разработка», кто как, но вот лично я рассчитываю увидеть какое-то решение, либо какой-то вывод. Мы все взрослые люди, давайте посмотрим правде в глаза.
1. Было как-то не очень
2. Запилили на ноде
3. Чуть подрихтовали молоточком и напильником
4. ????
5. Стало, в общем, ничего
Если бы были приведены какие-то решения в виде библиотек или статистика. Или примеры.
> Также мы улучшили безопасность работы с push-сервером. Когда пользователь присоединяется, то получает уникальный идентификатор канала — это случайная строка из 32 символов. Но если ее перехватить, то можно слушать чужие сообщения.
Так-то теорию-то мы все знаем.