
Я слышал ошибочные утверждения о том, что сервер может принять только 65 тысяч соединений или что сервер всегда использует по одному порту на каждое принятое подключение. Вот как они примерно выглядят:
Адрес TCP/IP поддерживает только 65000 подключений, поэтому придётся назначить этому серверу примерно 30000 IP-адресов.
Существует 65535 номеров TCP-портов, значит ли это, что к TCP-серверу может подключиться не более 65535 клиентов? Можно решить, что это накладывает строгое ограничение на количество клиентов, которые может поддерживать один компьютер/приложение.
Если есть ограничение на количество портов, которые может иметь одна машина, а сокет можно привязать только к неиспользуемому номеру порта, как с этим справляются серверы, имеющие чрезвычайно большое количество запросов (больше, чем максимальное количество портов)? Эта проблема решается распределением системы, то есть кучей серверов на множестве машин?
Поэтому я написал эту статью, чтобы развеять данный миф с трёх сторон:
- Мессенджер WhatsApp и веб-фреймворк Phoenix, построенный на основе Elixir, уже продемонстрировали миллионы подключений, прослушивающих один порт.
- Теоретические возможности на основе протокола TCP/IP.
- Простой эксперимент с Java, который может провести на своей машине любой, если его всё ещё не убедили мои слова.
Если вы не хотите изучать подробности, то перейдите в раздел «Итоги» в конце статьи.
Эксперименты
Фреймворк Phoenix достиг 2000000 одновременных подключений websocket. В статье разработчики демонстрируют приложение для чата, в котором симулируются 2 миллиона пользователей, а для пересылки сообщений на всех пользователей требуется 1 секунда. Они также рассказывают подробности о технических сложностях, с которыми они столкнулись в фреймворке, пытаясь добиться этого рекорда. Некоторые из изложенных в их статье идей я использовал для написания своего поста, например, назначение множественных IP, чтобы преодолеть ограничение в 65 тысяч клиентских соединений.
WhatsApp тоже достиг показателя в 2000000 подключений. К сожалению, разработчики почти не делятся подробностями. Они рассказали только о «железе» и операционной системе.
Теоретический максимум
Кто-то думает, что предел равен 216=65536, потому что это все порты, доступные по спецификации TCP. Этот предел справедлив для одного клиента создающего исходящие соединения с одной парой IP и порта. Например, мой ноутбук сможет создать только 65536 соединений с 172.217.13.174:443 (google.com:443), но, вероятно, Google заблокирует меня ещё до того, как я установлю 65 тысяч соединений. Итак, если вам нужна связь между двумя машинами с более чем 65 тысяч одновременных подключений, то клиенту нужно будет подключиться со второго IP-адреса или сервер должен сделать доступным второй порт.
У сервера, слушающего порт, каждое входящее подключение НЕ забирает порт сервера. Сервер может использовать только один порт, который он слушает. Кроме того, соединения будут поступать от нескольких IP-адресов. В лучшем случае сервер сможет прослушивать все IP-адреса, поступающие со всех портов.
Каждое TCP-подключение уникальным образом задаётся следующими параметрами:
- 32-битным исходного IP (IP-адресом, с которого поступает подключение);
- 16-битным исходным портом (портом исходного IP-адреса, с которого поступает подключение);
- 32-битным IP получателя (IP-адресом, к которому выполняется подключение);
- 16-битным портом получателя (портом IP-адреса получателя, к которому выполняется подключение).
Значит, теоретический предел, который может поддерживать сервер на одном порту — это 248, то есть около 1 квадриллиона, потому что:
- Сервер различает подключения от IP-адресов клиентов и исходных портов;
- [количество исходных IP-адресов]x[количество исходных портов];
- 32 бита на адрес и 16 бит на порт;
- Соединяем всё вместе: 232 x 216 = 248;
- Это примерно равно квадриллиону (log(248)/log(10)=14,449)!
Практический предел
Чтобы определить оптимистический практический предел, я провёл эксперименты, пытаясь открыть как можно больше TCP-соединений и заставить сервер отправлять и получать сообщение в каждом соединении. По сравнению с нагрузкой Phoenix или WhatsApp эта нагрузка совершенно непрактична, однако её проще реализовать, если вы захотите попробовать сами. Чтобы провести эксперимент, нужно справиться с тремя трудностями: операционной системой, JVM и протоколом TCP/IP.
Эксперимент
Если вам интересен исходный код, его можно изучить здесь.
Псевдокод выглядит так:
Поток 1:
открыть сокет сервера
for i from 1 to 1 000 000:
принять входящее подключение
for i from 1 to 1 000 000
отправить число i на сокет i
for i from 1 to 1 000 000
получить число j на сокете i
assert i == j
Поток 2:
for i from 1 to 1 000 000:
открыть сокет клиента серверу
for i from 1 to 1 000 000:
получить число j на сокете i
assert i == j
for i from 1 to 1 000 000
отправить число i на сокет iМашины
В качестве машин я использовал свой Mac:
2.5 GHz Quad-Core Intel Core i7
16 GB 1600 MHz DDR3
и свой десктоп с Linux:
AMD FX(tm)-6300 Six-Core Processor
8GiB 1600 MHz
Дескрипторы файлов
Первым делом нам придётся сразиться с операционной системой. Параметры по умолчанию сильно ограничивают дескрипторы файлов. Вы увидите подобную ошибку:
Exception in thread "main" java.lang.ExceptionInInitializerError
at java.base/sun.nio.ch.SocketDispatcher.close(SocketDispatcher.java:70)
at java.base/sun.nio.ch.NioSocketImpl.lambda$closerFor$0(NioSocketImpl.java:1203)
at java.base/jdk.internal.ref.CleanerImpl$PhantomCleanableRef.performCleanup(CleanerImpl.java:178)
at java.base/jdk.internal.ref.PhantomCleanable.clean(PhantomCleanable.java:133)
at java.base/sun.nio.ch.NioSocketImpl.tryClose(NioSocketImpl.java:854)
at java.base/sun.nio.ch.NioSocketImpl.close(NioSocketImpl.java:906)
at java.base/java.net.SocksSocketImpl.close(SocksSocketImpl.java:562)
at java.base/java.net.Socket.close(Socket.java:1585)
at Main.main(Main.java:123)
Caused by: java.io.IOException: Too many open files
at java.base/sun.nio.ch.FileDispatcherImpl.init(Native Method)
at java.base/sun.nio.ch.FileDispatcherImpl.<clinit>(FileDispatcherImpl.java:38)
... 9 more
Каждому сокету сервера нужно два дескриптора файлов:
- Буфер для отправки.
- Буфер для получения.
То же относится и к клиентским подключениям. Поэтому для запуска этого эксперимента на одной машине потребуется:
- 1000000 подключений для клиента;
- 1000000 подключений для сервера;
- По 2 дескриптора файлов на каждое подключение;
- = 4000000 дескрипторов файлов.
На Mac с bigSur 11.4 увеличить ограничение на дескрипторы файлов можно так:
sudo sysctl kern.maxfiles=2000000 kern.maxfilesperproc=2000000
kern.maxfiles: 49152 -> 2000000
kern.maxfilesperproc: 24576 -> 2000000
sysctl -a | grep maxfiles
kern.maxfiles: 2000000
kern.maxfilesperproc: 1000000
ulimit -Hn 2000000
ulimit -Sn 2000000
как рекомендовано в этом ответе на StackOverflow.
В Ubuntu 20.04 быстрее всего будет сделать так:
sudo su
# 2^25 должно быть более чем достаточно
sysctl -w fs.nr_open=33554432
fs.nr_open = 33554432
ulimit -Hn 33554432
ulimit -Sn 33554432
Пределы дескрипторов файлов Java
Мы разобрались с операционной системой, но JVM тоже не понравится то, что мы будем делать в этом эксперименте. При его проведении мы получим такую же или похожую трассировку стека.
В этом ответе на StackOverflow указано решение в виде флага JVM:
-XX:-MaxFDLimit: отключает попытки установки программного ограничения на аппаратное ограничение количества открытых дескрипторов файлов. По умолчанию эта опция включена на всех платформах, но в Windows игнорируется. Отключать её стоит только в Mac OS, где её использование накладывает ограничение в 10240, что меньше, чем действительный максимум системы.java -XX:-MaxFDLimit Main 6000
Как написано в этой цитате из документации Java, отключить флаг нужно только на Mac.
В Ubuntu мне удалось провести эксперимент без этого флага.
Исходные порты
Но эксперимент всё равно не работает. Я нашёл следующую трассировку стека:
Exception in thread "main" java.net.BindException: Can't assign requested
address
at java.base/sun.nio.ch.Net.bind0(Native Method)
at java.base/sun.nio.ch.Net.bind(Net.java:555)
at java.base/sun.nio.ch.Net.bind(Net.java:544)
at java.base/sun.nio.ch.NioSocketImpl.bind(NioSocketImpl.java:643)
at
java.base/java.net.DelegatingSocketImpl.bind(DelegatingSocketImpl.java:94)
at java.base/java.net.Socket.bind(Socket.java:682)
at java.base/java.net.Socket.<init>(Socket.java:506)
at java.base/java.net.Socket.<init>(Socket.java:403)
at Main.main(Main.java:137)Последняя битва нам предстоит со спецификацией TCP/IP. На данный момент мы зафиксировали адрес сервера, порт сервера и IP-адрес клиента. При этом у нас остаётся лишь 16 бит свободы, то есть мы можем открыть только 65 тысяч соединений.
Нашему эксперименту этого совершенно недостаточно. Мы не можем поменять ни IP сервера, ни порт сервера, потому что это проблема, которую мы исследуем в этом эксперименте. Остаётся возможность изменить IP клиента, что даёт нам доступ ещё к 32 битам. В результате мы обойдём ограничение, консервативно присваивая клиентский IP-адрес для каждых 5000 клиентских подключений. Ту же технику использовали в эксперименте с Phoenix.
В bigSur 11.4 можно добавить серию фальшивых адресов замыкания на себя (loopback address) следующей командой:
for i in `seq 0 200`; do sudo ifconfig lo0 alias 10.0.0.$i/8 up ; done
Чтобы протестировать работу IP-адресов, их можно попинговать:
for i in `seq 0 200`; do ping -c 1 10.0.0.$i ; done
Чтобы удалить, используем такую команду:
for i in `seq 0 200`; do sudo ifconfig lo0 alias 10.0.0.$i ; done
В Ubuntu 20.04 вместо этого потребуется использовать инструмент
ip:for i in `seq 0 200`; do sudo ip addr add 10.0.0.$i/8 dev lo; done
Чтобы удалить, используем команду:
for i in `seq 0 200`; do sudo ip addr del 10.0.0.$i/8 dev lo; done
Результаты
На Mac мне удалось достигнуть 80000 соединений. Однако спустя несколько минут после завершения эксперимента мой бедный Mac каждый раз загадочным образом вылетал без отчётов о сбое в
/Library/Logs/DiagnosticReports, поэтому я не смог диагностировать, что случилось.Буферы TCP отправки и получения на моём Mac имеют размер 131072 байта:
sysctl net | grep tcp | grep -E '(recv)|(send)'
net.inet.tcp.sendspace: 131072
net.inet.tcp.recvspace: 131072
Поэтому, возможно, это произошло из-за того, что я использовал
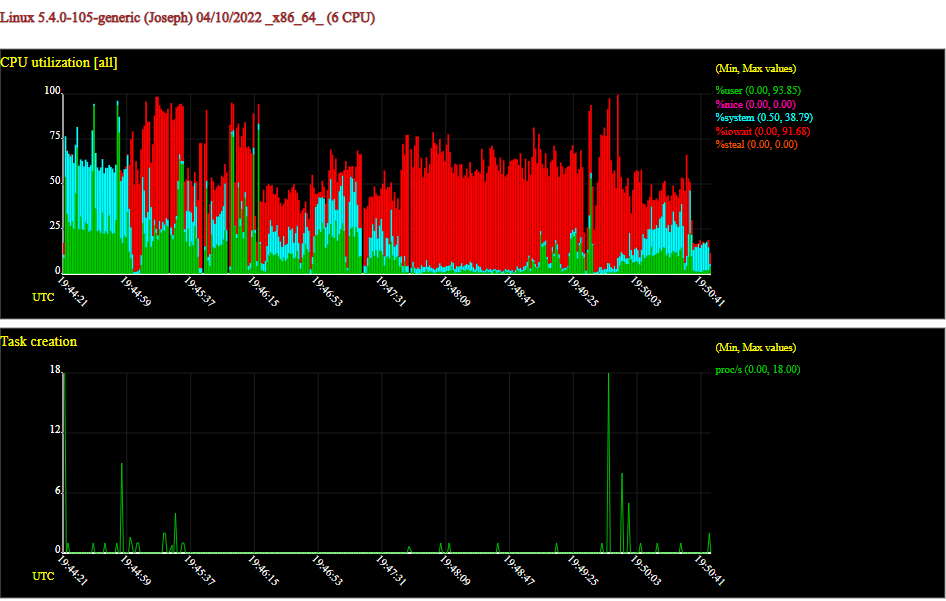
80000 подключений *131072 байт на буфер * 2 буфера ввода и вывода * 2 клиентских и серверных подключения байт, что равно примерно 39 ГБ виртуальной памяти. Или, может быть, Mac OS не нравится, что я использую 80000*2*2=320000 дескрипторов файлов. К сожалению, я незнаком с отладкой на Mac без отчётов о сбоях, поэтому если кто-то знает информацию по теме, напишите мне.В Linux мне удалось достичь 840000 подключений! Однако в процессе проведения эксперимента для регистрации перемещения мыши по экрану требовалось несколько секунд. При увеличении количества подключений Linux начинал зависать и переставал реагировать.
Чтобы понять, какой ресурс вызывает проблемы, я воспользовался sysstat. Посмотреть на сгенерированные sysstat графики можно здесь.
Чтобы sysstat фиксировал статистику по всему оборудованию, а затем генерировал графики, я использовал такую команду:
sar -o out.840000.sar -A 1 3600 2>&1 > /dev/null &
sadf -g out.840000.sar -- -w -r -u -n SOCK -n TCP -B -S -W > out.840000.svg
Любопытные факты:
-
MBmemfreeпоказывал меньше всего памяти, 96 МБ; -
MBavailпоказывал 1587 МБ; -
MBmemusedпоказывал всего 1602 МБ (19,6% от моих 8 ГБ); -
MBswpusedна пике показывал 1086 МБ (несмотря на то, что свободная память ещё была); - 1680483 сокета (840 тысяч серверных сокетов и 840 тысяч клиентских подключений плюс то, что работало на моём десктопе);
- Спустя несколько секунд после начала эксперимента операционная система решила задействовать swap, хотя у меня ещё была память.
Чтобы определить стандартный размер буферов отправки и получения в Linux, можно использовать такую команду:
# минимальное, стандартное и максимальное значения размера памяти (в байтах)
cat /proc/sys/net/ipv4/tcp_rmem
4096 131072 6291456
cat /proc/sys/net/ipv4/tcp_wmem
4096 16384 4194304
sysctl net.ipv4.tcp_rmem
net.ipv4.tcp_rmem = 4096 131072 6291456
sysctl net.ipv4.tcp_wmem
net.ipv4.tcp_wmem = 4096 16384 4194304
Для поддержания всех подключений мне бы потребовалось 247 ГБ виртуальной памяти!
131072 байта для получения
16384 для записи
(131072+16384)*2*840000
=247 ГБ виртуальной памяти
Я подозреваю, что буферы запрашивались, но поскольку из каждого нужно всего по 4 байта, использовалась лишь небольшая доля буферов. Даже если бы загрузил 1 страницу памяти, потому что мне нужно записать лишь 4 байта для записи integer в буфер:
getconf PAGESIZE
4096
Размер страницы 4096 байт
(4096+4096)*2*840000
=13 ГБ
то использовалось бы 13 ГБ, задействуя
2*840000 страниц памяти. Понятия не имею, как всё это работает без сбоев! Однако мне вполне хватает 840000 одновременных подключений.Вы можете улучшить мой результат, если у вас есть больше памяти или вы ещё сильнее оптимизируете параметры операционной системы, например, уменьшив размеры буферов TCP.
Итоги
- Фреймворку Phoenix удалось достичь 2 000 000 подключений.
- WhatsApp удалось достичь 2 000 000 подключений.
- Теоретический предел примерно равен 1 квадриллиону (1 000 000 000 000 000).
- У вас закончатся исходные порты (всего 216).
- Это можно исправить, добавив клиентские IP-адреса замыкания на себя.
- У вас закончатся дескрипторы файлов.
- Это можно исправить, изменив ограничения на дескрипторы файлов операционной системы.
- Java тоже ограничит количество дескрипторов файлов.
- Это можно исправить, добавив аргумент JVM
-XX:MaxFDLimit. - На моём Mac с 16 ГБ практический предел составил 80 000 подключений.
- На моём Linux-десктопе с 8 ГБ практический предел составил 840 000 подключений.
Комментарии (23)


dmitryvolochaev
15.04.2022 21:45+6Теоретический предел немного меньше указанного. Портов не 65536, а только 65535, потому что нулевого порта нет.
Кроме того, если доверить операционной системе выбор клиентского порта, то Windows выбирает только номера, начиная с 1024.
В коде для эксперимента connectionsPerAddress по умолчанию 5000, а не 65536 и даже не 65535

A1EF
16.04.2022 02:24Кстати, а в Linux клиентский порт и вовсе с 32768 начинается:
~ $ sysctl net.ipv4.ip_local_port_range
net.ipv4.ip_local_port_range = 32768 60999

vinrom
16.04.2022 14:51+1для window dynamic port range: 49152-65535 для post-vista (https://docs.microsoft.com/en-us/troubleshoot/windows-server/networking/default-dynamic-port-range-tcpip-chang), xp - 1025-5000.

mvv-rus
16.04.2022 19:10Кроме того, если доверить операционной системе выбор клиентского порта, то Windows выбирает только номера, начиная с 1024.
Старая информация, верная только для Windows NT/2K/XP/2K3


unC0Rr
15.04.2022 23:10+4Возможно, проще было не назначать алиасы лупбэку, а просто использовать другие адреса из подсети 127.0.0.1/8

{kind=link}

aleks_raiden
16.04.2022 11:14+1Было уже раньше, на Хабре тоже (целый цикл): https://habr.com/ru/post/212885/

vasyakolobok77
16.04.2022 14:02+2Немного непонятны некоторые моменты.
Если сервер и клиенты на одной машине, зачем 10.* подсеть, чем 127.* не устроила?
Если суть поставить рекорд, то стоило уменьшить до минимума буферы под TCP, а на стороне сервера увеличить backlog очередь соединений до максимума.

agorshkov23
16.04.2022 14:51Интересно, сколько сможет пройти соединений через NAT. Около 65к?

amarao
16.04.2022 17:49+1Сколько в настройках conntrack сделаете, столько и будет. Больше миллиона записей conntrack точно выдерживает.

Firelander
18.04.2022 14:43а есть какие-то способы отслеживания соединений кроме порта? Потому что если все клиенты за NAT будут стучаться к одному и тому же серверу по одному айпи, то как раз теоретический предел меньше этих 65к соединений. По tcp там возможно есть какие-то механизмы, а с udp вопрос

prefrontalCortex
16.04.2022 14:54+2Спасибо за статью, очень интересно!
Hidden text
серию фальшивых адресов замыкания на себя (loopback address)
Я чаще наталкивался на вариант перевода "петлевой интерфейс" или "петлевой адрес".
amarao
16.04.2022 17:53+2На самом деле проблема нехватки портов обычно касается апстримов у проксирующих серверов (собственно, исходящие соединения). На практике "открытый порт" - это фикция ОС, формализм в её базе. Сколько можно реалистично обслуживать соединений? Чаще всего этот показатель ограничен числом pps, которые может обработать сетевой стек (последний раз, когда я серьёзно занимался бенчмарками - около миллиона на сетевую карту, наверное, сейчас больше).

eigrad
17.04.2022 10:05Забавно что автор статьи тоже упёрся в исходящие соединения, но почему-то не пришел к выводу что ноги этого "мифа" растут как раз из исходящих соединений на балансере :-).

Paul_Arakelyan
16.04.2022 21:28+4Смешались кони и люди, а потом распутались :).
Изначально перепутаны понятия "сокет" (суть дескриптор соединения) и "порт", на чём и построена интрига.
Всю статью можно уместить в пару абзацев:
"Клиент в сторону одной пары server ip:port с одного IP может открыть до 65535 tcp-соединений, с той стороны они потребуют 65535 сокетов, которых можно завести - на сколько памяти и проца хватит. Ибо в tcp-пакетах прописана пары (изменяемый) client IP/port и (неизменный) server ip/port. Кому хочется большего - делает NAT с помощью пула адресов и соединяется с пулом адресов сервера. Хочется странного - можете делать свой протокол поверх UDP или вообще свой протокол.
Обработать дофигища входящих подключений - можно, если у сервера достаточно памяти и проца, и в ОС возможно задать нужные лимиты по сокетам и прочим дескрипторам, но иногда это потребует усилий мозгом - если нужно это сделать быстро."

Spicker
17.04.2022 11:00У меня сервера на RHEL с 64GB оперативы начинают уходить в себя при ~14500 входящих сессий TWAMP (perfSONAR). Каждая сессия резервирует ~4KB виртуальной памяти. Много ковырял всякие конфиги но ничего внятного добиться не смог. Так что считаю перечитаю несколько раз. Если у кого-то есть готовый рецепт, буду весьма благодарен.

dimuska139
17.04.2022 12:33+1Спустя несколько секунд после начала эксперимента операционная система решила задействовать swap, хотя у меня ещё была память.
Это нормальное поведение. Регулируется с помощью параметра
vm.swappinessв файле /etc/sysctl.conf (после сохранения надо перезагрузиться). Он определяет процент оставшейся свободной оперативной памяти, при котором начинается задействоваться swap. Текущее значение этого параметра можно посмотреть с помощью команды cat /proc/sys/vm/swappiness.
morijndael
18.04.2022 04:07+2Не совсем
vm.swappinessопределяет баланс между файловыми и анонимными страницами, что системе предпочтительнее высвобождать
Если система решит, что оптимальнее будет скинуть что-то в своп вместо сброса файловых кешей, то она имеет полное право так сделать
Вот тут есть перевод классной статьи, где очень подробно разбирается механизм работы swap
gdt
Круто, действительно интересно, спасибо за перевод. Однако я бы еще пару выводов для себя сделал в этом контексте — macOS не нужен, jvm не нужен
Типа если уж принимать миллионы клиентов — можно и заточиться под конкретное железо и ос, и тут jvm скорее мешает чем помогает, а мак очевидно не лучший выбор по итогам тестов :)
thatsme
Что-то мне не кажется, что это "круто". Это такой приём "распространено заблуждение что ...", и дальше идёт его опровержение. А на самом деле это заблуждение не так уж и распространено.
Вот 12 миллионов сокетов: https://habr.com/ru/post/460847/
Можно и 20 ... Весь вопрос в ресурсах (ЦПУ/ОЗУ).