

Сначала DSS LAB делает голос-текст, потом LSTM-классификаторы, сущности Spacy + Yargy (Natasha), лемматизация Pymorphy2, правки Fasttext и Word2Vec, 3 разных суммаризатора и наши решения. Мы можем анализировать ваш голос не только для того, чтобы понимать, о чём ведётся диалог, но и для того, чтобы искать места улучшений банковских продуктов после диалога.
Например, по распознаванию некоторых ключевых слов в речи вроде «аккредитив» или «эскроу» оператору показывается справка, по названиям депозитов — их точные тарифы и так далее. Нажимать при этом ничего не надо. Возможность сейчас обкатывается в бете.
Пример:
На входе: «…почему мне откапывает банкомат с переводом в другой банк».
Коррекция: «почему мне отказывает банкомат с переводом в другой банк».
Выделенное ключевое сообщение: «отказывает банкомат».
Действие: оператору предлагается маршрутизация звонка, звонок классифицируется для статистики.
Само распознавание устроено следующим образом:
- Голос раскладывается на фонемы. Фонемы собираются в слова тем же решением.
- Из собираемых данных удаляются различные клиентские данные: номера карт, кодовые слова и так далее.
- Затем полученный поток слов снабжается пунктуацией (точками и запятыми) и заглавными буквами: это нужно для нейросетей, очень чувствительных к такому. Исправляются опечатки, корректируются термины (география).
- И на выходе получаются текстовые диалоги, как в чате: их анализирует уже нейросеть, пытающаяся привязать смысл в реальном времени.
- После окончания звонка тексты также анализируются нейросетями, отвечающими за сбор разных метрик по голосовой и чат-поддержке.
Давайте покажу реальные (обезличенные) примеры диалогов, чтобы было понятнее.
Первое и главное применение постаналитики — получать оценки фич, которые нужны в приложении. Что на первом месте в колл-центре по количеству вопросов или обращений автоматизируется или допиливается по интерфейсу быстрее всего.
Вторая по важности возможность — автоматически выделять ключевые вещи в диалогах и формировать историю общения в виде коротких суммаризаций вроде «клиент хотел курьером», «живёт в деревне» и так далее, а не страниц текста.
Практическое применение
Главное практическое применение — это видеть картину происходящего с продуктами в реальном времени. То есть мы условно после раскатки на весь контакт-центр (сейчас это в бете на нескольких десятках операторов) увидим следующее:
- по каким вопросам прямо сейчас обращаются клиенты;
- где узкие места в продукте;
- где что-то идёт не так.
Естественно, операторы это и так знают, но не всегда верно и быстро могут оценить массовость проблемы (поскольку каждый видит только свои обращения). Плюс не всегда можно сделать нормальную постаналитику по какому-то новому разрезу. Если же у нас есть тексты всех звонков, то можно просто запустить анализ заново и довольно быстро получить результат.
Практическое применение в оценке ценности фич приложения для автоматизации (чтобы разгружать контакт-центр и давать клиенту возможность лучше решать свои задачи).
Что на входе: «… только дело в том что в нашем мы живем в поселке ну самый ближний магазин в городе у нас курчатова рядом рядом у нас нет вашего банка поэтому я получить не смогу такую карту».
Выделенное ключевое сообщение: «рядом у нас нет вашего банка».
Когда клиент по какой-то причине отказывается от продукта, маркетологи хотят знать, почему так: это нужно, чтобы понимать, что продукт конкурентен. Здесь речь шла про получение карты. Продуктологу будет важно узнать: дело в том, что поблизости нет отделений и банкоматов. Соответственно, после распознавания принимается решение о пополнении классификатора причин отказа от продукта. Про то, что это отказ, нейросеть узнаёт по тому, что не выделила ключевые сообщения, характерные для подтверждения того, что клиент хочет получить карту.
Далее: у нас есть нейросетка, которая строит суммаризацию диалога. Благодаря этому оператор за 10 секунд может разобраться в истории звонков клиента, а не читать диалоги целиком. Эти суммаризации неидеальны, но всё же помогают понять, что произошло. Это потенциально убирает одну из самых неприятных вещей в телефонной поддержке, когда каждому оператору надо заново объяснять, что же произошло и что было в предыдущих звонках. Либо просто позволяет сохранять много умолчаний. Например, хорошо, если предыдущий диалог в суммаризации выглядит так: «Клиент взял дебетовую карту для жены». Вот пример:
Что на входе: «да что они верно угу угу а карьера лучше угу угу да а лучше допустим с утра и там до 4 где-то вот так так а если допустим завтра но она оборот после 6 угу да нет ниче ребенка школа довезу…»
Корректировка после распознавания: «да что они верно угу а курьером лучше угу да лучше допустим с утра и там до 4 где-то вот так так а если допустим завтра но она оборот после 6 угу да нет ниче ребенка школа довезу…»
Выделенное ключевое сообщение: «курьером лучше».
Если мы уже знаем, что клиенту удобнее курьером, то ему в следующий раз в первую очередь предложат именно такой способ получения карты. Для таких записей не нужно обучать оператора: эти теги формируются автоматически роботом.
А вот не совсем хороший пример суммаризации:
На входе: «Э да здравствуйте угу, А как потом отключить СмС информирования Ещ клиент может быть да ключ поняла хорошо. Да нет, да нет. Да в принципе это такой выходной наверно будет ника с какой вечно будет. Да можно за проспект ленина 15 ну, который (фамилия) скажи. Да да ну. Да, конечно, угу Угу Угу. Да хотел 1000 н по карте с этой карты допустим ну на другие и кому то другому переводить можно будет бесплатно или с комиссией. Так ну да на любые банки. Угу все хорошо спасибо, угу до свидания».
Ключевые сообщения: «Так ну да на любые банки Угу все хорошо спасибо».
Здесь тематика была определена как «переводы на любые банки» (правильно), а вот в суммаризацию диалога робот положил: «Угу все хорошо спасибо».
Можно делать контекстные подсказки.
На входе: «…скажите было когда то видел такой в приложение банка вопрос хотел уточнить какие условие сейчас по моему предложению по рассрочке...»
Выделенное ключевое сообщение: «какие условие предложению по рассрочке».
Это пока в планах, когда доделаем, оператор в реальном времени будет видеть конкретные условия именно для этого клиента. Для получения подсказки ничего нажимать не нужно: она похожа на всплывающие уведомления. То есть можно просто ею воспользоваться, а можно проигнорировать. Раньше оператор пошёл бы вручную искать эти условия в интерфейсе либо, если запрос сложный, пошёл бы на портал разбираться. Сейчас примерно в 70 % случаев подсказка верна. Это уменьшает ожидание на линии, то есть оставляет клиента более довольным.
Наконец, можно контролировать операторов.
На входе: «да минутку пожалуйста ждем одобрения по продукта что там готово вам одобрена заявка на сумма 400000 рублей с процентной ставкой…»
Выделенное ключевое сообщение: «400000 рублей».
Возможно, вы слышали истории, когда клиенту называют одну сумму предложения по кредиту (и какие-то конкретные условия), а в банк он приходит и получает другой результат. Чтобы этого не случалось, нужно чётко контролировать, какие числа какому клиенту были названы и как они соотносятся с тем, что показал софт оператору из предварительной оценки по кредиту. Здесь ключевое сообщение автоматически уезжает наверх с числом из ПО, и, если они совпадают, — всё в порядке. Если они разные, то диалог прослушает человек и примет решение.
Ещё одна особенность контроля — отследить, подтвердил ли клиент, что это он, сверить с его учётными данными и дальше, если эти показатели не совпадают, проверить, не звучали ли суммы в диалоге. Оператор не имеет права называть, к примеру, сумму долга третьим лицам, включая жену и детей, а они часто очень уговаривают.
Особенности распознавания
Распознавание голос — текст — модель от DSS LAB. Для классификации текстов используем LSTM-модели на Keras, а также модели fine-tune Bert. Перед классификацией «тяжёлыми» моделями для оценки качества тренировочных данных делаем оценку быстрыми моделями — логистическая регрессия, наивный байес и т. д. — с целью выявить возможные спорные моменты, например, когда два класса плохо различимы, т. е. когда предоставленные примеры не покрывают тематику с достаточной полнотой. Такие случаи могут попадаться довольно часто, и причём для классов с редкой встречаемостью, например, когда продукты банка имеют схожий смысл и название. В таких случаях для лучшей их разделимости пробуем использовать мета-информацию о клиенте (какие продукты есть у клиента, предыдущие диалоги с клиентом), а также полуручной подход с выставлением трешхолдов для таких классов.
Для выделения сущностей (Ф. И. О., города, улицы, валюты) применяются Spacy, а также Yargy-парсеры (библиотека Natasha), для лемматизации (приведение слов к начальной форме) — Pymorphy2.
Клиентские данные (персональные данные и платёжные данные, секретные слова) вырезаются нашим собственным решением до начала анализа.
Для исправления критичных опечаток (города, имена, адреса, названия продуктов банка) используются модели Fasttext и Word2Vec, а также статистические подходы, например, расстояние Левенштейна, словари/правила.
Для исправления грамматики (знаки препинания) используется BERT-модель, описанная здесь.
Для суммаризации текстов используем python-библиотеки Sumy, Summa, а также T5 на основе трансформеров — вот пост.
Диалоги пишутся в два канала: оператор банка — в один, клиент (абонент) — в другой, то есть мы всегда можем различать речь каждого, даже если она накладывается. Диалог у оператора достаточно структурирован, чтобы разметить очень много ключевых точек: фактически каждый диалог представляет собой скрипт с фиксированными ветвлениями, и его можно забирать чуть ли не из CRM. Например, когда собираются причины того, почему клиент выбрал наш банковский продукт среди других на рынке, оператор обычно говорит что-то вроде: «Почему вы нас выбрали?» Ещё чаще встречаются бинарные выборы: в скриптах выбора продуктов есть вещи вроде: «Чего вам больше хочется — получать кешбэк или беспроцентно пользоваться деньгами банка?» Клиент достаточно чётко совершает выбор на каждом этапе, из чего оператор понимает, что лучше всего предложить, а мы получаем очень хорошо классифицируемые наборы данных.
Естественно, оператор не говорит строгими фиксированными фразами, клиенты — тоже. Нейросеть должна уметь одинаково хорошо классифицировать и «Меня устраивает ваш кешбэк», и «Угу, да», анализируя контекст.
Сейчас мы обрабатываем 100 % диалогов таким образом. Раньше, когда автоматизации не было, прослушивалось 10 % диалогов выборочно, и на них вручную отмечалась статистика происходящего. Сейчас есть конкретные числа вроде «70 % диалогов распознано с качеством выше 95 %, в них 793 раза сказали «карта Польза», значит, предположительно всего 1 132 клиента выбрали продукт по этой причине».
Конкретное качество распознавания — 86 %. Из 100 символов текста, который набрал бы человек, прослушивающий разговор, 86 будет совпадать с результатом работы первого слоя модели до корректировок. Модель корректировок даёт ещё примерно пять процентных пунктов к качеству. Далее: русский язык богат, и тот же смысл можно восстановить из контекста достаточно точно, а вот числа и фамилии — уже нет. Практический результат в том, что 80 % диалогов поддаётся автоматизации — это именно результаты беты, где клиент может находиться на улице, фоном могут разговаривать другие люди или будет кричать грудной ребёнок, у абонента может быть акцент или дефект дикции. До 97 % диалогов поддаётся автоматизации в плане контроля каких-то важных ключевых точек.
Дополнительные применения
На основании корпуса текстов и результатов диалогов мы можем достаточно быстро вычислять в них те вещи, которые ведут к негативу клиента либо срабатывают хорошо. Это прямо влияет на изменение скриптов операторов и масштабирование хороших практик.
Понимание распределения обращений клиентов в моменте даёт возможность реагировать правильно на эту самую ситуацию. Есть предсказуемый период, когда клиентам банка нужно сдать отчётность: в этот момент запрос справок возрастает на 300 %. Этот период предсказуем, но если вдруг произойдёт что-то неожиданное, что резко повысит важность какого-то функционала, то он, к примеру, сможет на основании потребности «всплыть» вверху в интерфейсе, чтобы клиент не звонил, а сразу сделал всё сам.
Кстати, о нештатном: совсем недавно, в острый период конца февраля — начала марта, когда ситуация менялась постоянно, мы на основе речевой аналитики смогли быстро выделить топовые вопросы, которые беспокоили наших клиентов (а это не только курс валют и оформление продуктов, но и переживания за свои сбережения, за дальнейшую работу компании и т. п.). И с учётом этих данных оперативно готовили своих операторов отвечать на новые непростые вопросы, снабжали их всей необходимой информацией.
Или вот раньше у клиентов были вопросы с составом платежа по кредиту. Чаще всего их интересовала декомпозиция: почему он такой? Что туда входит? Мы увидели на основании речевой аналитики, насколько это волнует, и сразу сделали детализацию платежа в приложении, причём именно так, как люди спрашивают. Не просто сумма и когда внести, а чётко компоненты: какая часть в основном долге и доступна для покупок, какая часть — на комиссии, на проценты и т. п. Естественно, могли бы сделать и без аналитики, но когда статистика собирается сама и есть точные числа, это куда проще обосновать.
Можно отслеживать непрофессиональное поведение операторов. Например, есть стоп-лист жаргонных выражений и внутренних терминов (которых клиент не понимает), которые можно распознавать и потом отправлять результаты аналитики старшему команды в контакт-центре. Про «правильно поздоровался» я даже не говорю: у нас одни из лучших NPS по рынку по вежливости, но автоматика всё равно это распознаёт и продолжает отслеживать.
Из ошибок — мы пробовали делать следование чек-листу звонка (соблюдению скрипта) на лету по мере хода самого звонка. Оказалось, что коллеги из Яндекса тоже пробовали, и у них тоже не очень получилось. Они же дали рекомендацию: не нужно оператору показывать статус прохождения по всем этапам скрипта. Нужно только главное вроде следующего шага, иначе оператор сбивается.
Ещё нас, конечно же, волновал вопрос, не станут ли операторы бета-группы менять свою речь в сторону большей разборчивости и более «протокольных» фраз, зная, что их слушает не самый умный в мире робот. Мы анализировали темп речи — он не изменился за время эксперимента, то есть все продолжают говорить, как говорили.
Итоги беты
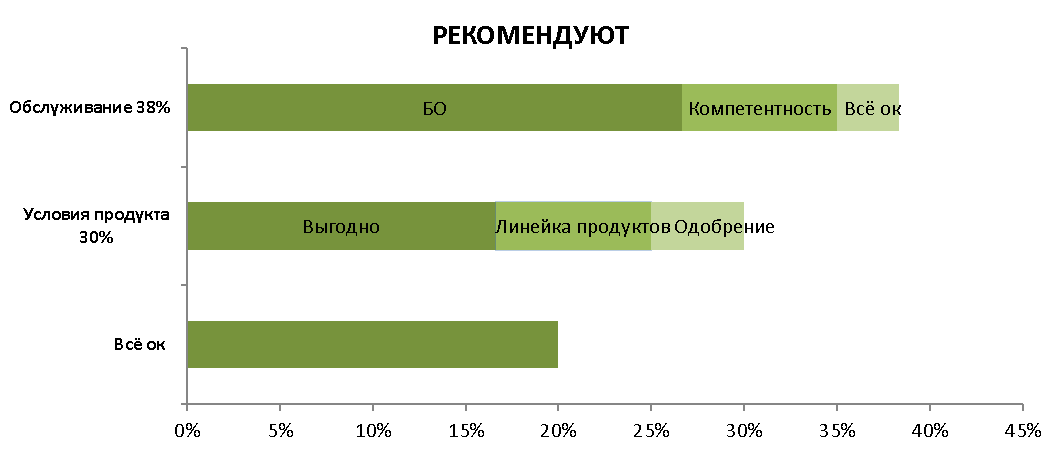
Постаналитика собирает 20 NLP-отчётов: анализ качества взаимодействия с клиентами, классификаторы обращений клиентов, оценка предложений продуктов банка, выявление причин отказа, следование/соблюдение ФЗ, разработка онлайн-подсказок и так далее. По итогам обработки данных с помощью ML-моделей или python-скриптов на стороне бизнеса формируются финальные отчёты по каждой из задач. Классификатор рекомендательных отзывов может выглядеть вот так:
Обрабатываем 1,5 миллиона звонков ежемесячно, 100 % преобразуются в текст.
Комментарии (24)

snakers4
22.04.2022 05:08+33Для исправления грамматики (знаки препинания) используется BERT-модель, описанная здесь.
Данная модель из нашего репозитория (привожу ссылку, если вы потрёте ссылку в статье - https://github.com/snakers4/silero-models) опубликована под лицензией GNU Affero General Public License v3.0:

То есть простыми словами де-юре - вы должны опубликовать все свои системы, где ее используете под такой же лицензией, чего вы очевидно не сделали и не сделаете. Де-факто - эта лицензия по сути для некоммерческого использования.
Поэтому у меня простой вопрос, пожалуйста поясните мне лично и всему сообществу Хабра, почему вы используете нашу модель для коммерческих целей, нарушая текущую лицензию, без нашего согласия, не купив лицензию у нашей компании?
Я конечно догадываюсь, какой ответ, но хочу услышать его от вас.
Предлагаю вам решить данный вопрос в досудебном порядке просто купив лицензию у нас. Связаться с нами можно по контактам, указанным в репозитории - hello@silero.ai

SergeyDeryabin
22.04.2022 10:31+3Лучше бы конечно сделать нотариально заверенный скрин, но пока статью не поправили и обычный скриншот лучше сделать

AIring
22.04.2022 12:01+1Но ведь на приведенном же вами скриншоте написано, что частное использование допускается и публикация исходников требуется только при предоставлении сервиса по сети. Кажется в статье не идет речь о том, чтобы распространять сервис речевой аналитики как пакет ПО или предоставлять его как сервис в интернете. А остальное не запрещено.
snakers4
22.04.2022 12:05Все почему-то читают с конца, а начало пропускают:
Permissions of this strongest copyleft license are conditioned on making available complete source code of licensed works and modifications, which include larger works using a licensed work, under the same license. Copyright and license notices must be preserved. Contributors provide an express grant of patent rights. When a modified version is used to provide a service over a network, the complete source code of the modified version must be made available.
AIring
22.04.2022 12:18+1Смотрите: обычный GPL не заставляет вас делиться модифицированными программами. Это ваше право а не обязанность. Вы можете изучать, модифицировать, использовать, в т.ч. для коммерческих целей и не с кем ни чем не делиться. Но вот если решили поделиться, то обязаны поделиться под той же лицензией, а так же полными исходными кодами. Тут есть "слабое" место, что само ПО можно не распространять, а предоставлять как публичный сервис в интернете, зарабатывать на этом деньги и не открывать исходных кодов. Именно поэтому и появилась Affero. Собственно GNU Affero только одно условие добавляет - что если предоставляете ПО как сервис, то должны делиться исходниками. А любое частное, в т.ч. коммерческое использование не под запретом.
snakers4
22.04.2022 12:32AIring
22.04.2022 12:43Ну я специально не затрагивал тему линковки и "виральности". Мы можем рассуждать о том должны ли быть остальные части ПО лицензированы под AGPL или нет, где та грань, но пока ПО не публикуется и не предоставляется как сервис - это не имеет практического смысла. Ничто не мешает банку формально отлицензировать свое ПО для речевой аналитики под AGPL и продолжить им пользоваться не опасаясь юридических последствий. Мы этого ПО все равно не увидим и исходников не получим.
snakers4
22.04.2022 12:48-1В статье есть упоминания, что это ПО содержит большое количество решений третьих сторон ... в том числе как проприетарных, так и под MIT
Никто не спорит, что можно до бесконечности делать любую оптику и кабалистику (равно как и мне в лицензию что-то дописать), но более правильными действия банка от этого не становятся.
AIring
22.04.2022 12:54+1Тогда более корректно будет вам формулировать свои претензии о несовместимости лицензий и попросить прояснить аспекты линковки разных программ в продукте. А вы влетаете в комментарии с ноги с обвинениями и требуете купить у вас лицензию. При этом вводите в заблуждение читателей хабра, что GNU Afferro нельзя использовать для коммерческих целей. Видимо для пущего эффекта. С банком-то все понятно, но ваши действия тоже трудно назвать правильными.
Общение в конструктивном ключе лучше поможет разъяснить ситуацию.
snakers4
22.04.2022 12:57Мне кажется я достаточно конкретно сформулировал свои претензии.
AIring
22.04.2022 13:24Не могу говорить за всех и вся, но как-минимум в некоторых банках весьма щепетильно относятся к вопросу лицензий. Как мы уже выяснили, о фактах прямого нарушения лицензии из статьи говорить нельзя. Можно только додумывать детали.
И вместо того, чтобы эти детали вытянуть из автора статьи вы, да, достаточно конкретно сформулировали, что хотите от банка денег, а не то суд. Просто на основании того, что по вашему мнению, банк плохой априори, а значит не может и не будет соблюдать условия лицензий. Вот только доказать это будет проблематично, особенно теперь, когда вы сразу начали с прямых обвинений.snakers4
22.04.2022 13:27Вот только доказать это будет проблематично, особенно теперь, когда вы сразу начали с прямых обвинений.
Можно еще сразу встать на колени и начать стыдиться.
Как мы уже выяснили, о фактах прямого нарушения лицензии из статьи говорить нельзя.
Мы такого не выясняли.
AIring
22.04.2022 13:33+5Мы такого не выясняли.
А о чем же был предыдущий разговор? Давайте еще раз по пунктам:
1. AGPL не запрещает частное и коммерческое использование
2. AGPL обязывает делиться исходниками только при распространении ПО или предоставлении его как сервиса
3. Способы использования и линковки разных частей ПО под разными лицензиями не уточнялись. Не зная деталей, мы не можем однозначно утверждать что там есть нарушения.

sergey_serov Автор
22.04.2022 13:28+2Конечно, давайте отвечу на все вопросы.
Мы уважаем чужой труд, соблюдаем законодательство и всегда придерживаемся лицензионных требований. При использовании этой модели банк ни в коем случае их не нарушил.
Мы не применяли модель (напомню, она расставляет знаки препинания в тексте) для коммерческих целей.
Мы никак не модифицировали исходный код, размещенный на условиях безвозмездной открытой лицензии. Мы использовали эту модель крайне непродолжительное время. С сегодняшнего дня мы от нее отказались – будем рассматривать другие варианты, в том числе собственную разработку.
snakers4
22.04.2022 13:34+4Ну, я и не ожидал никакого иного ответа.
Не совсем понимаю, как банк может использовать модели для целей прослушки звонков со своими клиентов в некоммерческих целях.
Спасибо, что сами подтвердили факт использования, и не стали задним числом подчищать историю, будет проще готовить материалы =)

Andchir
23.04.2022 15:30Не так давно я лично обращался к Вам в Телеграме с вопросом о цене на лицензию с коммерческим использованием. Но не получил никакого внятного ответа. На вашем сайте тоже информации нет. Всё покрыто мраком. Однако, при любом упоминании использования ваших разработок, Вы сразу бежите к нотариусу и т.п. Может просто разместите информацию с ценами у себя на сайте? Этим Вы сэкономите нервы себе и другим.
snakers4
23.04.2022 15:41По нику @Andchir в телеграме у меня пусто. По нику с похожей аватаркой - @andchir_t тоже пусто.
Andchir
23.04.2022 15:54Ник не обязательно должен совпадать, логично? Здесь тоже ответ о многом говорит. Я про цены и нервы, Вы про ник.
snakers4
23.04.2022 16:26Если будет желание пообщаться про какую-то конкретику - пишите. Пока опять очередной FUD.
Мне в телеграме пишет много людей (включая неадекватных) и чтением мыслей я к сожалению не занимаюсь.


priwelec
А есть ли анализ обратной связи от клиента (его оценки качества обслуживания) или не используете такое?
sergey_serov Автор
Да, среди прочего есть автоматическая оценка качества работы оператора с клиентом. Выведены отдельные блоки с учетом обратной связи от клиента, например в части решения его вопроса на этапе консультации. Ещё в проработке задача по выведению оператору прогнозной оценки (nps) в момент диалога с клиентом с рекомендациями и пояснениями.