

Если обновляешься со старой Java на LTS-версию Java 17, как разобраться сразу во всех фичах за несколько лет? Чтобы помочь с этим, мы уже публиковали расшифровку доклада tagir_valeev с нашего IT-фестиваля TechTrain. Но доклад такой подробный, что разделили его на два текста: в предыдущем была основная часть про языковые изменения, а теперь представляем вам завершающую часть про API.
И напоминаем, что следующий TechTrain состоится уже 14 мая (онлайн, бесплатно), а в июне будет много Java-докладов на JPoint (онлайн + офлайн).
Далее повествование идёт от лица спикера.
Давайте посмотрим интересные новые API, которые появились после Java 11. Кстати, в документации Java 17 появилась вкладочка New, где перечислено всё новое со времён Java 11: новые модули, пакеты, интерфейсы и так далее. Можно сесть вечерком и спокойно почитать. Я расскажу про то, что мне самому понравилось.
String.indent
В Java 12 в строках появился новый метод для отбивки её пробелами после каждого перевода строк. В качестве примера вот можно красиво форматировать наше синтаксическое дерево для отладочного вывода:

Здорово, что в строках много разных новых интересных методов, и вам не нужны всякие странные классы типа StringUtils.
String.stripIndent
Появился несколько обратный метод String.stripIndent, который позволяет вам убрать общее выравнивание. Здесь будет удалено по два пробела в каждой строчке:

Его основное предназначение — это помощь в реализации text blocks. В спецификации прямо так и написано, что в блоках лишнее выравнивание убирается этим методом. Если вы вдруг пишете свой парсер Java-файлов, вам не надо греть голову, как их правильно обрезать, можно просто вызвать этот метод.
String.translateEscapes
Часть этой же истории — это метод translateEscapes, который в соответствии с семантикой языка Java переводит escape characters в соответствующие символы.
String str = "\\tHello\\n\\tWorld";
System.out.println(str);
System.out.println(str.translateEscapes());
\tHello\n\tWorld
Hello
WorldЯ завёл строчку, транслировал и получил нормальную табуляцию и нормальный перевод строки.
Math.absExact
В математике появился долгожданный метод absExact для int и long. В отличие от обычного abs, этот метод никогда не возвращает отрицательного результата. Вместо этого у него другая крутая фича — если в него пришел MIN_VALUE, то он просто кидает исключение.

Очень удобно, обязательно пользуйтесь.
Stream.teeing
В Stream API после Java 11 появился метод toList, мы про него уже говорили. Ещё появился новый коллектор teeing, — его я, кстати, сам написал. Он позволяет в один проход пропустить стрим через два коллектора и потом объединить их результаты.

Например, вы хотите усреднить стрим BigDecimal. Для усреднения нам нужна сумма и нужно количество. Одним коллектором вы суммируете, другим считаете количество, а в мёрджере просто делите одно на другое и создаете новый коллектор. Просто и понятно.
Stream.mapMulti
Ещё в стримах появился немного странный метод mapMulti. Это альтернатива flatMap, который позволяет не создавать вложенный стрим, а пушить новые элементы. В него приходит элемент стрима (в данном случае это строка) и sink (слив, в который можно сливать элементы, которые мы генерируем).
Stream.of("hello", "world")
.<Character>mapMulti((str, sink) -> {
for (char c : str.toCharArray()) {
sink.accept(c);
}
})
.forEach(System.out::printIn);
Тут я просто разбиваю строку на символы и эти символы туда пихаю. Тут даже короткое замыкание по API не сделаешь, потому что если у нас там был стрим с каким-нибудь findFirst, то этот цикл продолжал бы пихать элементы, которые никому уже не нужны. Если у вас нет короткого замыкания, то таких проблем нет.
Stream.of("hello", "world")
.<Character>mapMulti((str, sink) -> {
for (char c : str.toCharArray()) {
sink.accept(c);
}
})
.forEach(System.out::printIn);
Stream.of("hello", "world")
.flatMap(s -> s.chars().mapToObj(c -> (char) c))
.forEach(Syatem.out::printIn);В данном случае то же самое можно сделать с flatMap, потому что есть API-метод chars. Но может оказаться, что когда-то вам это пригодится — хотя мне кажется, что спорно. Говорят, самое правильное — использовать этот метод, когда у вас немного элементов во внутреннем стриме (например, ноль или один), потому что если вы во flatMap будете создавать вложенный стрим, то Hotspot не умеет его полностью уничтожать, у вас на каждый элемент внешнего стрима будет создаваться элемент внутреннего стрима, и это — гора мусора.
Классический пример — это размотка optional. Например, создадим такой список, где тысяча optional: половина из них пустые, половина не пустые. Допустим, мы хотим посчитать общую длину всех непустых optional, а пустые проигнорировать.
List<Optional<String>> optionals =
IntStream.range(0, 1000)
.mapToObj(i -> Optional.of(i).filter(v -> v%2 == 0).map(String::valueOf))
.toList();Классическое решение в стиле Java 8 — это вызвать последовательно фильтры Optional::isPresent, а потом map(Optional::get). Это два шага — неудобно.
В Java 9 появился метод stream прямо в optional, который создаёт стрим из нуля и одного элемента. Стало удобнее — можно сделать это в один шаг. Но на каждый элемент внешнего стрима мы создаём внутренний стрим, и это медленно.
Теперь можно взять mapMulti с той же целью. На удивление, сюда удачно мэпится Optional::ifPresent. Единственное — тип всё же не выводится, поэтому его надо явно указать в угловых скобках.


Какой же доклад без бенчмарков. Что же будет быстрее? Выясняется, что mapMulti побеждает всех. И памяти тоже требует меньше, где FlatMap отстаёт вообще на два порядка.

Но мне кажется, что если ваш код со стримами действительно вас не устраивает с точки зрения производительности, то уж проще на цикл переписать, наверное?

Императивно, без всяких лямбд и стримов. Получается ещё быстрее, аллокаций нет вообще. В общем, мне не очень понятно, зачем нужен mapMulti, если найдёте крутое применение, то расскажите!
HexFormat
HexFormat format = HexFormat
.ofDelimiter(":")
.withUpperCase()
.withPrefix("[")
.withSuffix("]");
byte[] input = {(byte) 0xCA, (byte) 0xFE, (byte) 0xBA, (byte) 0xBE};
String asString = format.formatHex(input);
System.out.printIn(asString);
// [CA]:[FE]:[BA]:[BE]
byte[] output = format.parseHex(asString);
assert Arrays.equals(input, output);Ещё один классный метод, который появился в Java 17, это HexFormat. Он вам позволяет отформатировать, например, массив байтов в виде шестнадцатеричной строчки. Причём вы её можете очень круто настраивать: использовать всякие разделители, префиксы, суффиксы, заглавные или строчные буквы.
А главное — можно не только форматировать, но и парсить. Такой красивый и современный API. А ещё он супербыстрый, внешняя библиотека вряд ли сможет работать так же быстро.
ByteBuffer absolute positioning
ByteBuffer.slice(index, length);
ByteBuffer.get(index, byteArray);
ByteBuffer.get(index, byteArray, offset, length);
ByteBuffer.put(index, byteArray);
ByteBuffer.put(index, byteArray, offset, length);
Bytebuffer.put(index, byteBuffer, offset, length);
CharBuffer/DoubleBuffer/FloatBuffer/IntBuffer/LongBuffer/ShortBufferПрокачали ByteBuffer. Если вы хотите кусок из массива Byte скопировать в ByteBuffer или наоборот, то теперь вам не надо это заранее позиционировать, мы можете сделать это одним методом.
Objects.check для long
Objects.checkIndex(long index, long length);
Objects.checkFromToIndex(long fromIndex, long toIndex, long length);
Objects.checkFromIndexSize(long fromIndex, long size, long length);Всё чаще появляется необходимость работать с массивами данных, количество элементов в которых превышает два миллиарда и не влазит в int. Если вы пропустили, то в Java 9 появились удобные быстрые методы для проверки того, попадает ли индекс в диапазон индексов. Если вы пишете, например, свою реализацию List или InputStream, то их очень удобно использовать для валидации входных параметров.
А если вы вдруг работаете с огромными данными, они в int не влазят, и у вас всех на long, то в Java 16 появились соответствующие методы для них. Специалисты по Big Data могут радоваться — теперь вы можете обрабатывать очень много данных в Java.
RandomGeneratorFactory
RandomGenerator generator = RandomGeneratorFactory
.of("L128X1024MixRandom")
.create();
int randomNumber = generator.nextInt(1, 100);
System.out.printIn("Extremely good random number between 1 and 100: "
+ randomNumber);Кстати, о бигдате: если вам нужно очень много хороших случайных чисел, появился дополнительный повод обновиться до Java 17. В ней кардинально переработали всю историю со случайными числами — был добавлен целый пакет java.util.random, в котором появился и интерфейс генератора случайных чисел, и фабрика генераторов случайных чисел, и в ней ещё фабричный метод — то есть это фабрика фабрик генераторов случайных чисел. Очень круто, по-джавовски.
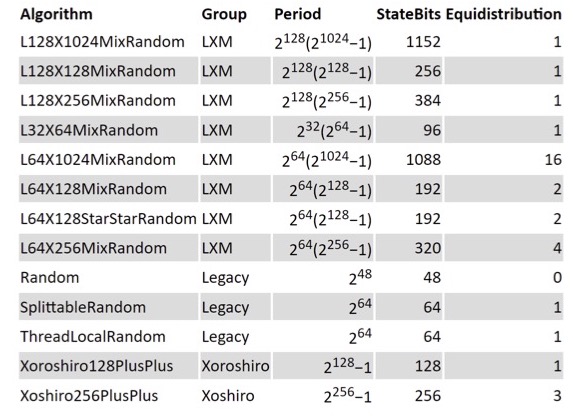
Кроме того, туда напихали целую кучу алгоритмов, потому что генератор, который существует в Java с незапамятных времен, java.util.Random — это легаси, он очень плохой, в нём состояние всего 48 бит, вы из него даже всех возможных long получить не можете. Его метод nextLong на самом деле выдаёт только 1/65000 от всевозможных long.
В Java 8 появились SplittableRandom и ThreadLocalRandom, у них уже состояние 64 бита, они получше. Но наука случайнология не стоит на месте, там много чего интересного происходит. Сейчас есть много интересных генераторов случайных чисел, которые довольно быстрые, у них огромное состояние и хорошее распределение чисел.
Кстати, подобную табличку можно сгенерировать прямо из API в вашей JVM, если там есть какие-то новые генераторы, то вы всех их можете увидеть, потому что можно просто получить стрим всех генераторов и читать про разные их свойства.

Вот я сделал табличку, в неё SecureRandom тоже попадает. У него нет никакого периода, там числа никогда не повторяются, но он страшно медленный, потому что ему нужна внешняя энтропия. У каких-то из этих генераторов длина периода значительно превышает размеры элементарных частиц во вселенной, так что есть надежда, что числа будут неплохие.
interface RandomGenerator
DoubleStream doubles(...)
IntStream ints(...)
LongStream longs(...)
boolean next Boolean()
void nextBytes(byte[])
float nextFloat(...)
double nextDouble(...)
int nextInt(...)
long nextLong(...)
double nextGaussian(...)
double nextExponential()А самая классная вещь, что над всеми генераторами случайных чисел появился общий интерфейс, и именно его теперь нужно использовать в сигнатурах методов, которым для нормального функционирования нужна случайность. Тогда вы снаружи контролируете, какой генератор можно передать.
В интерфейсе есть всё, что необходимо: все привычные методы, которые мы видели раньше в java.util.Random, и даже больше. Там также есть всякие специализированные подинтерфейсы, которые позволяют дробить генераторы на несколько и по-разному прыгать в новое состояние. Это уже суперспециальные штуки, если вам интересно, то читайте Javadoc в пакете java.util.random.
Reference.refersTo

Иногда возникает задача проверить, указывает ли данная ссылка на конкретный объект. Старый способ был просто сделать get и сравнить с объектом, но у вызова get был побочный эффект: если это слабая ссылка, и там на самом деле другой объект, вызов get мог продлить жизнь того объекта. Это могло быть нежелательно.
refersTo лишён этого побочного эффекта, и к тому же работает даже с фантомными ссылками, у которых get всегда возвращает null.
Process + Reader

В классе Process появились методы, которые позволяют вам подключиться к процессу через Reader и Writer, а не через InputStream или OutputStream. Можно также параметром ему задавать charset. Удобные обёртки, чтобы самому не париться с созданием соответствующих классов.
Заметьте, кстати, что это новый API, у них нет префикса get — ещё в records мы видели, что префиксы get и is вышли из моды. Не используйте их, это кринж, молодёжь будет над вами рофлить.
Кое-что для японцев
Ну и конечно, если среди вас есть японцы, поздравляю вас с началом новой эры REIWA, которую добавили в Java 13. Впрочем, это изменение не совсем в тему нашего доклада, потому что это одно из немногих добавлений в API, которую бэкпортировали не только в Java 11, но и в Java 8.
Зато, когда этот вопрос обсуждался, я неожиданно понял, что среди всех правителей земного шара император Японии оказывает наибольшее влияние на Java.

Если вы думаете, что добавить новую эру — это просто пара строчек, то ой нет. Там около 20 тикетов, связанных с этим. Так что не надо недооценивать Японию.
На этом у меня всё.
Надеемся, этот и предыдущий хабрапосты оказались вам полезны. А тем временем вслед за Java 17 вышла уже и 18 — значит, пора следить за развитием Java-мира дальше. 14 мая на нашем бесплатном онлайн-фестивале TechTrain джависты смогут услышать доклад «Меняем Spring Data JPA на Spring Data JDBC», а в июне проведём большую Java-конференцию JPoint (онлайн + офлайн). Будем рады вас там видеть!
Комментарии (4)

GerrAlt
01.05.2022 11:08короткое замыкание по API
подскажите пожалуйста, у вас тут "короткое замыкание" это вы имели ввиду "bug" или "closure" небольшой длины ?

mayorovp
01.05.2022 11:16Имелось в виду именно короткое замыкание. Коротким замыканием в программировании называется отключение вычисления части сложного выражения (со всеми побочными эффектами) в ситуации когда она не влияет на результат.
Например, короткозамкнутыми (т.е. способными к короткому замыканию) являются операторы && и ||.
В процитированном вами фрагменте автор жалуется на отсутствие возможности прервать цикл
for (char c : str.toCharArray())потому что API не предоставляет никакого флага для этой цели.
Bakuard
Спасибо за статью. Если не сложно, могли бы сделать обзор нового API из JEP 424?