
Использовать Guid.NewGuid() в качестве первичного ключа в базе данных — плохая с точки зрения производительности идея. Это связано с тем, что в SQL Server, MySQL и некоторых других БД для первичных ключей создаются кластерные индексы, которые определяют, как строки будут храниться на диске. GUID — это по сути случайное значение, поэтому новая строка может попасть в начало, середину или конец таблицы. Серверу БД в этом случае придётся перемещать другие строки, что приведёт к фрагментации данных, а их извлечение может занять больше времени, если вам нужно извлечь несколько добавленных последовательно записей (например, когда вы добавляете набор связанных сущностей, которые потом будут извлекаться вместе — БД понадобится прочитать данные из разрозненных страниц вместо последовательного чтения набора данных).
Поэтому, чаще всего, лучше пользоваться сгенерированными БД первичными ключами. В SQL Server, например, есть функция NEWSEQUENTIALID(), которая генерирует последовательные GUIDы. Зачем может понадобиться генерировать ключи именно на клиенте и как это правильно сделать?
Проблема
Для создания первичных ключей сущности большинство людей прибегают к одному из следующих подходов:
Использование в качестве первичного ключа int и генерация таких ключей базой данных при вставке новой строки.
Использование GUID и опции генерации на уровне БД.
Самостоятельная генерация GUID в своём приложении и вставка строки с этим идентификатором.
Чтобы дать немного контекста и выяснить, почему вам могут понадобиться последовательные GUID, рассмотрим плюсы и минусы каждого из вышеперечисленных подходов к созданию первичных ключей.
Генерируемый БД Integer в качестве идентификатора
Первый вариант, позволяющий базе данных автоматически генерировать целочисленный первичный ключ, является очень заманчивым подходом; долгое время, особенно в монолитных системах, это было подходом по умолчанию, который удобно интегрировался с ORM. Одна из его приятных особенностей — первичные ключи получают красивые, монотонно возрастающие (и обычно последовательные) идентификаторы.
Это упрощает работу с тестовыми данными и поддержку, когда идентификаторы используюстя в URL-адресах: можно запомнить ID нужной сущности, быстро получить её в коде или по адресу, вбив нужный идентификатор:
GET https://localhost/api/book/1
GET https://localhost/api/book/2
GET https://localhost/api/book/2/pages/112Какие недостатки у таких ключей?
Во-первых, подход с генерацией ключей в базе данных затрудняет или делает невозможным использование некоторых паттернов проектирования. Например, общий подход к идемпотентности заключается в создании идентификатора на клиенте и отправке его в запросе. Это позволяет легко устранять дублирование и гарантирует, что вы не вставите один и тот же объект дважды, так как легко обнаружить повторяющиеся запросы на вставку. Такой подход обычно невозможен с идентификаторами, сгенерированными базой данных.
Во-вторых, это усложняет код INSERT, поскольку вы должны убедиться, что возвращаете сгенерированные идентификаторы. EntityFramework под капотом назначает ID сущностям после вставки, но в случае с Dapper вам придётся делать это самим.
Третья проблема возникает только в высоконагруженных приложениях — при вставке большого количества строк БД должна блокировать генератор идентификаторов чтобы избежать использования одного ID несколькими сущностями, это может стать узким местом в приложении. Если БД масштабируется и используется master-master репликация, то всё становится ещё сложнее — в разных БД существуют разные настройки, которые могут генерировать записи с пропусками (например, первый сервер будет генерировать только нечетные идентификаторы, а второй только четные) или генерировать идентификаторы из разных подмножеств.
Резимуруя этот подход:
Читаемые и запоминаемые URL.
Проблемы с идемпотентностью.
В некоторых случаях нужно дополнительно озаботиться возвращением идентификаторов при вставке.
Снижение производительности в высококонкурентной среде.
Усложняет масштабирование.
Генерируемый БД GUID в качестве идентификатора
При использовании сгенерированных БД гуидов мы можем избавиться от части проблем — например, NEWSEQUENTIALID() использует для генерации значений данные оборудования (MAC-адрес сетевой карты и "идентификатор часов"), поэтому сгенерированный с помощью неё иденитфикатор остается глобально уникальным. Это избавляет от необходимости дополнительной настройки генерации последовательности иденификаторов при репликации.
Функция генерирует корректно сортируемые последовательности, так что данные будут вставляться последовательно, а при слиянии данных с нескольких реплик эти данные так же будут локально последовательными.
52DE358F-45F1-E311-93EA-00269E58F20D
53DE358F-45F1-E311-93EA-00269E58F20D
54DE358F-45F1-E311-93EA-00269E58F20D
55DE358F-45F1-E311-93EA-00269E58F20D
56DE358F-45F1-E311-93EA-00269E58F20DВ MySQL функция UUID() генерирует UUID версии 1, что делает их так же частично сортируемыми.
Стоит сразу заметить, что в PostgreSQL данные хранятся иначе, поэтому использование непоследовательных GUID не влияет катастрофически на производительность базы данных.
В случае генерируемых БД идентификаторов мы всё ещё вынуждены мириться с сложностью реализации идемпотентности в запросах и необходимостью заботиться о возвращении идентификаторов при вставке. Также тот факт, что гуиды являются 128-битными значениями по сравнению с 32-битными целыми числами, приводит к увеличению общего размера данных.
Генерируемый клиентом GUID в качестве идентификатора
Решение проблем генеририуемых БД первичных ключей заключается в использовании созданных клиентом идентификаторов. У этого подхода тоже есть различные плюсы и минусы!
Одним из преимуществ является то, что это просто. Все современные языки имеют доступные генераторы GUID; в .NET это метод Guid.NewGuid(), который возвращает случайный 128-битный идентификатор.
Вы можете установить это значение в качестве ID для добавляемой сущности, и вам не нужно беспокоиться о проверке, с каким идентификатором она была добавлена в БД. Используете ли вы EF Core или Dapper, Postgres или SqlServer, код будет одинаковым. Данные при запросе на вставку перемещаются только в одном направлении, от клиента к базе данных, а не в двух направлениях, как в случае с генерируемым БД первичным ключом.
Если вы создаете идентификаторы в своем клиентском коде, у вас теперь есть доступ к различным шаблонам идемпотентности. Например, представьте, что вы включаете GUID в запрос, но запрос завершается сбоем из-за ошибки сервера. Вы можете просто отправить тот же запрос еще раз, зная, что сервер сможет идентифицировать его как «дубликат», поэтому ему нужно только повторить часть действия, которое привело к ошибке или просто вернуть ответ об успешном создании сущности. Таким образом, вы можете избежать создания дубликатов.
Уникальность гуидов — это и их сильные стороны, и их слабость. С точки зрения разработчика и пользователя, с /book/55DE358F-45F1-E311-93EA-00269E58F20D работать не так просто, как с /book/1.
Тип Guid в .NET реализует UUID версии 4, то есть генерируемый полностью случайным образом идентификатор. С точки зрения базы данных эта случайность может вызвать большие проблемы. Случайность идентификаторов может привести к серьезной фрагментации индекса, что увеличивает размер вашей базы данных и влияет на общую производительность.
Если подводить итог для опции генерируемого на клиенте GUID, то получится следующее:
Легко использовать и код остаётся универсальным при переходе между разными БД.
Позволяет сделать запросы идемпотентными без дополнительного уровня абстракции.
Нет необходимости читать значения из БД после вставки.
Нечеловекочитаемые URL.
Больший объем данных по сравнению с целочисленными идентификаторами.
Могут вызвать проблемы с производительностью БД из-за фрегментации индекса.
Преимущества сортируемого GUID
У гуидов есть несколько преимуществ, и, кроме проблем с человекочитаемостью, один большой недостаток с фрагментацией индекса, вызванной их полной случайностью. А нам всего-то и нужен сортируемый последовательно-возрастающий глобально-уникальный идентификатор чтобы использовать его в качестве ключа. Где его взять?
Самый простой ответ — нам нужен тот самый UUID версии 1, который используется функциями БД для генерации идентификаторов. Но есть несколько проблем. В BCL нет полной реализации RFC 4211, и, судя по комментариям в github дотнета, такую поддержку прямо сейчас добавлять не планируется. Если поискать по nuget-пакетам, то какого-то одного стандарта де-факто, который бы активно использовался и поддерживался сообществом тоже нет. Я нашёл библиотеку Vlingo.Xoom.UUID, которая завляет поддержку RFC 4211. Ещё один способ из хабростатьи про GUID в качестве первичных ключей предлагает использовать DllImport к библиотеке, которая используется SQL Server для генерации идентификаторов — такой способ вызовет очевидную проблему с переносимостью.
internal static class NativeMethods
{
[DllImport("rpcrt4.dll", SetLastError = true)]
public static extern int UuidCreateSequential(out Guid guid);
}Но у UUID версии 1 на мой взгляд есть недостатки на уровне самого стандарта. Во-первых, для метки времени используется количество 100-наносекундных интервалов, прошедших с 15 октября 1582 года. Это совсем не то, как мы привыкли думать о timestamp в нашем повседневном программировнии. Во-вторых, в случае с UUID версии 1 метка времени внутри идентификатора частично перевернута, то есть старшие биты таймстампа сдвинуты к младшим битам в самом UUID. Это объясняет тот факт, что в примере с NEWSEQUENTIALID() менялись именно старшие разряды идентификатора. Такой порядок делает лексикографическое упорядочивание немного бессмысленным.

Мы могли бы просто переставить биты внутри UUID и вернуть время и упорядоченность к изначальному виду от старших бит к младшим, но это дополнительное усложение, которое всё ещё предполагает использовать непривычный timestamp совсеместно с дополнительной логикой защиты от коллизий (в случае, если в 100нс интервал генерируется несколько идентификаторов). Хочется чего-то более нативного.
Отличные новости — для решения этой задачи 31 марта 2022 года на сайте IETF был официально размещен текст рабочего документа с новыми форматами UUID, специально предназначенными для использования в высоконагруженных приложениях и базах данных — возрастающие по времени, создержащие timestamp, счетчик с инициализацией его сегментов нулем и псевдослучайным значением, а также собственно псевдослучайное значение. Стандарт ещё не принят, но уже сейчас можно найти первые реализации библиотек для UUID версии 7.
Ещё одна хорошая новость — есть библиотека NewId, которая позволяет генерировать лексикографически упорядоченные по времени создания идентификаторы и тоже создана как раз для первичных идентификаторов. Сама библиотека основана на Snowflake_ID, который разработан специально для использования в распределенных системах, и Flake, который развивает идеи UUID версии 1. Самый простой способ понять, что это значит, — показать, как выглядят идентификаторы, сгенерированные NewId.
foreach (var i in Enumerable.Range(0, 5))
{
Guid id = NewId.NextGuid();
Console.WriteLine(id);
}Пример результата работы программы:
d3630000-5d0f-0015-2872-08da3058ad5a
d3630000-5d0f-0015-4837-08da3058ad5b
d3630000-5d0f-0015-8f37-08da3058ad5b
d3630000-5d0f-0015-2fd8-08da3058ad5b
d3630000-5d0f-0015-ed68-08da3058ad5cNewId использует в качестве данных для создания идентификатора 3 источника:
Worker/process ID, который отвечает за уникальность между процессами/сервером — именно он отвечает за общую для всех идентификаторов часть, а идентификатор конкретного процесса можно включить дополнительно для избежания коллизий между процессами в рамках одной машины.
Timestamp, который обеспечивает сортируемость идентификатора.
Последовательно возрастающий идентификатор.
Объединив 3 части вместе, вы можете получить идентификатор, который будет частично отсортированным благодаря компоненту метки времени. Включив идентификатор процесса, можно избежать коллизий при генерации идентификаторов несколькими процессами. А использование части с последовательно возрастающим идентификатором позволяет генерировать 2^16-1 идентификаторов в миллисекунду в рамках одного процесса:

Код генерации идентификатора для самых любознательных
На сколько же NewId снижает фрагментацию индекса?
Сравнение фрагментации индекса при использовании разных генераторов UUID
В сравнительном эксперементе я решил сравнить степень фрагментации и плотность данных от несколько генераторов UUID в качестве первичных ключей:
Guid.NewGuid()[DllImport("rpcrt4.dll", SetLastError = true)]Vlingo.UUID.TimeBasedGenerator.GenerateGuidc опциейGuidGenerationMode.WithUniquenessGuaranteeMassTransit.NewId.NextGuid()UUIDNext.Uuid.NewDatabaseFriendly()
В тесте для простой таблицы с идентификатором и текстовым полем будет добавляться 10 тысяч записей, каждая с случайной задержкой 100-500 миллисекунд, таким образом в идентификаторе будут участвовать таймштампы за 50 минут одного дня.
NewId, по-видимому, в значительной степени ориентирован на сервер SQL Server. Поэтому, и потому, что для MySQL я не нашёл понятного способа измерить фрагментацию данных и эффективность использования дискового пространства, тесты проводились именно на SQL Server.
Развернем Docker-образ SQL Server:
docker run -d --name sql1 --hostname sql1 \
-e "ACCEPT_EULA=Y" \
-e "SA_PASSWORD=Passw0rd!" \
-p 1433:1433 \
mcr.microsoft.com/mssql/server:2019-latestСоздадим 5 простых таблиц для разных типов сгенерированных идентификаторов:
CREATE TABLE dbo.normal_guids (
Id uniqueidentifier PRIMARY KEY,
Dummy varchar(50) NOT NULL
);
CREATE TABLE dbo.dllimport_guids (
Id uniqueidentifier PRIMARY KEY,
Dummy varchar(50) NOT NULL
);
CREATE TABLE dbo.vlingouuid_guids (
Id uniqueidentifier PRIMARY KEY,
Dummy varchar(50) NOT NULL
);
CREATE TABLE dbo.newid_guids (
Id uniqueidentifier PRIMARY KEY,
Dummy varchar(50) NOT NULL
);
CREATE TABLE dbo.uuidv7_guids (
Id uniqueidentifier PRIMARY KEY,
Dummy varchar(50) NOT NULL
);Создадим в таблицах тестовые данные при помощи старого-доброго ADO.NET:
using System.Data;
using Vlingo.UUID;
using Microsoft.Data.SqlClient;
var connString = @"Server=127.0.0.1,1433;Database=Master;User Id=SA;Password=Passw0rd!;TrustServerCertificate=True";
using var connection = new SqlConnection(connString);
await connection.OpenAsync();
foreach (var i in Enumerable.Range(0, 10_000))
await InsertGuid(connection, "normal_guids", Guid.NewGuid());
foreach (var i in Enumerable.Range(0, 10_000))
{
NativeMethods.UuidCreateSequential(out var guid);
await InsertGuid(connection, "dllimport_guids", guid);
}
var vlingoGenerator = new Vlingo.UUID.TimeBasedGenerator();
foreach (var i in Enumerable.Range(0, 10_000))
await InsertGuid(connection, "vlingouuid_guids", vlingoGenerator.GenerateGuid(GuidGenerationMode.WithUniquenessGuarantee));
foreach (var i in Enumerable.Range(0, 10_000))
await InsertGuid(connection, "newid_guids", MassTransit.NewId.NextGuid());
foreach (var i in Enumerable.Range(0, 10_000))
await InsertGuid(connection, "uuidv7_guids", UUIDNext.Uuid.NewDatabaseFriendly());
async Task InsertGuid(SqlConnection sqlConnection, string table, Guid id)
{
await using var command = new SqlCommand($@"INSERT INTO dbo.{table} (Id, Dummy) VALUES (@ID, 'test')", sqlConnection);
command.Parameters.Add(new("ID", SqlDbType.UniqueIdentifier) { Value = id });
await command.ExecuteNonQueryAsync();
await Task.Delay(Random.Shared.Next(100, 500));
}Чтобы посмотреть размер каждого индекса и его фрагментацию, используем стащенный из этой статьи запрос:
SELECT OBJECT_NAME(ips.OBJECT_ID)
,avg_fragmentation_in_percent
,avg_page_space_used_in_percent
,page_count
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'SAMPLED') ips
INNER JOIN sys.indexes i ON (ips.object_id = i.object_id)
AND (ips.index_id = i.index_id)
ORDER BY avg_fragmentation_in_percent DESCРезультаты:
avg_frag_in_percent avg_page_space_used_in_percent page_count
normal_guids 97.53086419753086 71.66382505559672 81
dllimport_guids 5.084745762711865 98.3951321966889 59
vlingouuid_guids 3.389830508474576 98.3951321966889 59
newid_guids 5.084745762711865 98.3951321966889 59
uuidv7_guids 97.5 72.55992092908328 80Полученные данные легко объяснить из информации, которую мы уже знаем. Во-первых, сгенерированные случайно идентификаторы приводят к большой фрагментации данных поскольку новые элементы вставляются на случайную позицию. NewId вызвали только 5-процентную фрагментацию, а Vlingo.UUID всего 3-процентную фрагментацию. Ещё при использовании Guid остается больше пустого места на каждый странице с данными (возможно, из-за постоянных перемещений данных во время вставки), поэтому вам нужно больше страниц для хранения того же объема данных (81 против 59). Это тоже станет источником некоторого снижения производительности при использовании гуидов. Что касается UUID версии 7, то остается только думать, что способ, которым SQL Server сортирует ключи не совсем совместим с новым форматом.
Но на самом деле влияние фрагментации при чтении данных совсем не так велико, как может представляться — скорее можно назвать его незначительным. Вот пример замера производительности при чтении 10.000 записей и 100.000 записей в запросе:
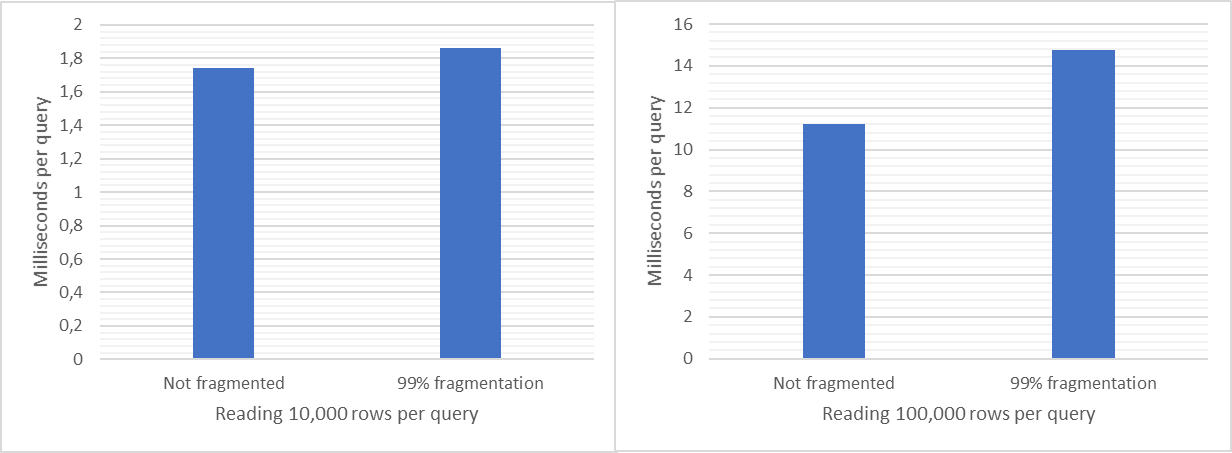
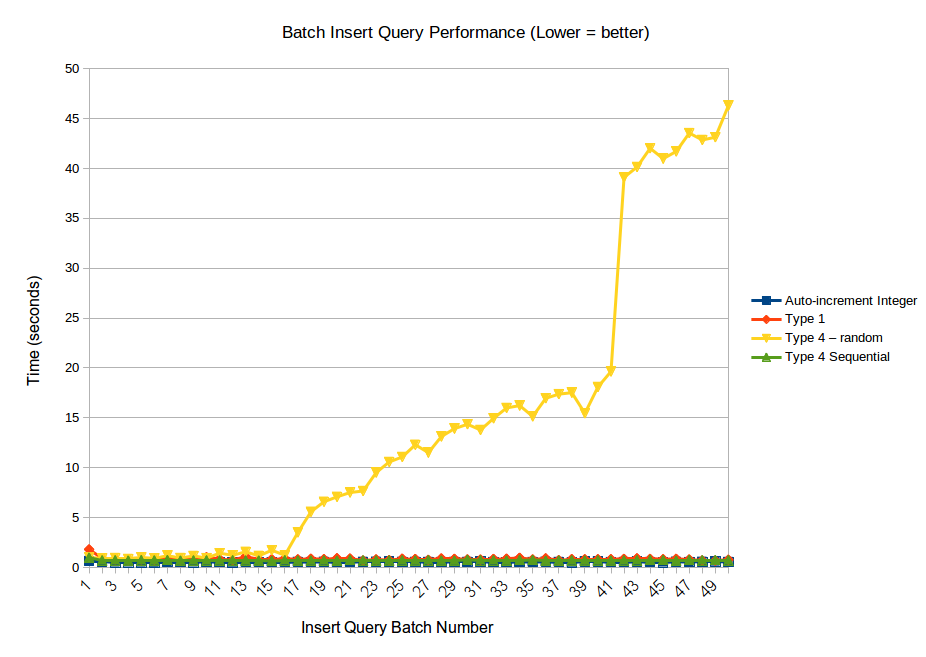
Настоящая проблема c производительностью гуидов начинается в больших таблицах при вставке данных — потому что индекс перестраивается случайным образом, а сервер БД не может сделать предсказания для следующего набора данных. Один из бенчмарков сравнивает производительность добавления 5 миллионов записей батч-запросами по 100.000 записей каждая в таблицу c автоинкрементным целым ключом, UUID версии 1, 4 или подхаченной "последовательной" версии 4 после манипуляции с битами. По результатам видно, что после полутора миллионов записей UUID версии 4 начинает деградировать, а время вставки быстро растет:
В другом бенчмарке сравнивается добавление записей в БД, где ключи генерируются разными функциями SQL: uuid_generate_v4(), uuid_time_nextval() и uuid_sequence_nextval() с разным набором параметров. Тесты проводятся в трёх условиях: на изначально пустой таблице, помещающейся в оперативную память таблице и явно не влезающей в оперативную память таблице. С ростом объёма данных тоже видно значительное снижение скорости добавления новых данных:

Выводы
Библиотеки NewId и Vlingo.UUID явно делают свою работу. Первая создана и развивается специально для решения проблемы с первичными ключами в базах данных, где данные строк хранятся в кластерных индексах. Вторая — утилитарный пакет платформы XOOM компании Vlingo и не имеет даже публичной документации.
Стоит ли его использовать? Ответ, как обычно — "зависит". Но это точно хорошая альтернатива, если вам нужно генерировать первичные ключи на клиенте и работать с MySQL или MS SQL Server.
Что почитать
"Generating sortable Guids using NewId", Andrew Lock | .NET Escapades
"MySQL Performance When Using UUID For Primary Key", Programster's Blog
"Sequential UUID Generators", Tomas Vondra in 2ndQuadrant blog
"Index fragmentation revisited", Tibor Karaszi's SQL Server blog
"Flake: A Decentralized, K-Ordered Unique ID Generator in Erlang", Dietrich Featherston
RFC 4122: A Universally Unique IDentifier (UUID) URN Namespace
"Встречайте UUID нового поколения для ключей высоконагруженных систем" @SergeyProkhorenko
Комментарии (34)

Bonio
10.05.2022 19:11+3А нам всего-то и нужен сортируемый последовательно-возрастающий глобально-уникальный идентификатор чтобы использовать его в качестве ключа. Где его взять?
Использовать ULID, вместо GUID.

AlexGorky
10.05.2022 19:44+1Я раньше не мог понять, почему в 1С guid элементов справочников при массовом создании из одного сеанса не совсем уникальные - они отличаются на 1.
С учетом того, что индекс по guid в 1С кластерный, всё встало на свои места.

edo1h
10.05.2022 20:46+1Такой порядок делает лексикографическое упорядочивание немного бессмысленным.
так ms sql и сортирует guid не лексикографически
https://stackoverflow.com/questions/7810602/sql-server-guid-sort-algorithm-why

gleb_l
10.05.2022 20:59Все прекрасно, если у вас простые плоские структуры. Что вы будете делать, если задача - скопировать N записей, скажем от одного родителя к другому? Будете на клиенте генерировать ключи по одному, и ходить в БД с каждой записью? Как будете работать с клиентскими ключами, если у вас, например, трехуровневвая иерархия (школа-класс-ученик ;) ) - вы утонете в цепочках гуидов при подобной операции. Дальше - идемпотентность. Тоже все просто, если операция плоская. А если сломались чилдовые сущности после вставки родительских? Сможете поддержать трехуровневый маппер и правильно его накатить снова (и главное, для чего?)
Затем, мы оптимально вставили записи с гуид-ключами в таблицу. А отдаем ли мы себе отчет, какой у нас индекс динамичности данных (отношение W / (R + W))? Ибо если наш кластерный индекс длинный - то все некластерные индексы будут ссылаться на этот длинный индекс, равно как все FK будут иметь такую же длину. В итоге, страницы данных и индексов будут большими, вычитка их будет медленной, так как среднее кол-во записей на страницу упадет. Вы уверены, что скорость вставки именно в вашем случае это перевесит?

Vadimyan Автор
10.05.2022 21:34Я, возможно, не совсем понял вопрос. Мне кажется, что здесь задачи и зоны ответственности могут делиться очень по-разному в зависимости от того, какой сервис сохраняет класс, а какой ученика, и чья зона ответственности генерировать идентификаторы учеников — сервиса, который сохраняет класс или клиента этого сервиса, который и инициировал эту операцию.
Это же касается идемпотентности — если операция "атомарная" в том плане, что клиент сервиса классов посылает в метод создания список учеников, то он вполне и сгенерирует идентификаторы, а сервис классов вполне обработает в таком случае повторный запрос. А вот при генерации на стороне БД будет больно.
В случае с вычиткой я упоминал в статье бенчмарк, который показывает, что вычитка из разрозненного набора страниц не такая большая проблема (подозреваю, что "в некоторых сценариях" типа hdd или отчаяной нехватки оперативной памяти и необходимости чтения с диска это будет не так), но в общем случае я согласен с проблемой, что надо очень хорошо понимать не только индекс динамичности, но и профили запросов — потому что выстрелить себе в ногу в хранилищах проще простого.
edo1h
10.05.2022 22:12я правильно понимаю, что вы против использования uuid и за использование
восьмибитныхint как идентификаторов?gleb_l
10.05.2022 22:26+2Я против попытки сделать просто сложные вещи в общем виде. Это невозможно, как невозможен перпетуум-мобиле.
В случае эффективной работы с БД проблема, как таковая, никуда не уходит - а просто перемещается с бакенда на фронтенд, либо с записи на чтение. Как воздушный пузырь в частично наполненном водой шарике. В каком-то частном случае вам удобнее иметь пузырь с одной стороны - да, это облегчает вашу частно-определенную задачу, но из этого совсем не следует, что вы нашли эффективное решение задачи общего вида.
edo1h
10.05.2022 23:12+2просто перемещается с бакенда на фронтенд
а в чём проблема на фронтенде? подключить библиотеку?
либо с записи на чтение
сомневаюсь, что на реальных данных вы увидите различие по производительности запросов на чтение между таблицами с 128-битным uuid и с 64-битным счётчиком.
ну а 32-битные счётчики и большие таблицы сегодня не очень совместимы, уже натыкался на переполнение.

mayorovp
11.05.2022 12:13Как будете работать с клиентскими ключами, если у вас, например, трехуровневвая иерархия (школа-класс-ученик ;) ) — вы утонете в цепочках гуидов при подобной операции.
А в чём, собственно, проблема, и чем цепочка гуидов принципиально отличается от цепочки каких-нибудь bigint?
Дальше — идемпотентность. Тоже все просто, если операция плоская. А если сломались чилдовые сущности после вставки родительских? Сможете поддержать трехуровневый маппер и правильно его накатить снова (и главное, для чего?)
Если вам нужна идемпотентность — то клиентская генерация идентификаторов как раз является единственным вариантом. Кстати, зачем тут вообще маппер?

Akina
10.05.2022 22:03+11Во-первых, подход с генерацией ключей в базе данных затрудняет или делает невозможным использование некоторых паттернов проектирования. Например, общий подход к идемпотентности заключается в создании идентификатора на клиенте и отправке его в запросе. Это позволяет легко устранять дублирование и гарантирует, что вы не вставите один и тот же объект дважды, так как легко обнаружить повторяющиеся запросы на вставку. Такой подход обычно невозможен с идентификаторами, сгенерированными базой данных.
Давайте не будем валить в одну кучу тёплое и мягкое. Есть ПОСТОЯННЫЙ идентификатор (с точки зрения хранящейся на сервере информации - идентификатор экземпляра сущности с неограниченным временем актуальности). Который отвечает за контроль уникальности. Есть ОДНОРАЗОВЫЙ идентификатор (с весьма ограниченным временем актуальности, для которого не возбраняется дублирование за пределами разумного периода времени). Который отвечает за одноразовость. Для первого - генерируем идентификатор на сервере и там же используем. Для второго - генерируем случайный идентификатор на клиенте (причём связанный с сеансом клиента, а не сеансом обращения клиента к серверу) и передаём серверу для контроля на предмет повторности выполнения. Так что такой подход невозможен с идентификаторами, сгенерированными базой данных потому, что базе данных в принципе не нужна генерация этого идентификатора. Её задача проверить обращение клиента на повторность - а для этого как раз нужен идентификатор от клиента, причём максимально вероятно обеспечивающий глобальную уникальность. Да, сервер может - но вот оно ему надо? да и затраты сервера на генерацию и передачу - не многовато ли за в общем никому не нужную унификацию этих идентификаторов?
Во-втроых, это усложняет код INSERT, поскольку вы должны убедиться, что возвращаете сгенерированные идентификаторы. EntityFramework под капотом назначает ID сущностям после вставки, но в случае с Dapper вам придётся делать это самим.
SQL-код INSERT не усложняется ни на копейку. И ему в принципе не надо в чём-то убеждаться - ну просто потому что СУБД (1) в принцип не может не сгенерировать идентификатор (2) в принципе не может сгенерировать повторно одно и то же значение. Да, возвращать ему тоже ничего не надо (ну за исключением случаев, когда текст запроса требует) - если клиенту потребуется, он спросит. А если какие-то там прослойки у себя под капотом содержат дополнительный код, который потенциально способен породить описанную проблему, или даже такого кода не содержат - то при чём тут СУБД-то? у неё как раз всё в порядке. Жалуйтесь на кривую прокладку.
Третья проблема возникает только в высоконагруженных приложениях — при вставке большого количества строк БД должна блокировать генератор идентификаторов чтобы избежать использования одного ID несколькими сущностями, это может стать узким местом в приложении.
Да, такая проблема частично есть. Но с ней вполне успешно борются, причём на уровне СУБД. Предзаказ идентификаторов, кэш идентификаторов... Кроме того, сравнивать по скорости/времени генерацию идентификатора, происходящую целиком и полностью в памяти сервера, и вставку записей, требующую достаточно медленных дисковых операций (да даже в случае SSD всё равно по сравнению с работой чисто в памяти - медленных, просто масштаб разницы не столь велик), надо с очень большой осторожностью.
Проблемы в репликации - да, тоже есть. Но тоже проблемы решаемые. А проблемы при масштабировании так и вовсе не проблемы. Особенно при наличии узла-координатора, пусть и динамического. Просто надо не вдруг в процессе эксплуатации обнаружить, что требуется описанное масштабирование и возникли проблемы. Для того же BIGINT раздавать диапазоны размером в INT можно до скончания века - и они не успеют кончиться.
Резюмируя - лично я так и остался не убеждённым в том, что GUID имеет ну хоть какое-то преимущество по сравнению с автогенерируемым INT / BIGINT значением.
Ну и, уж извините, вторая, экспериментальная, часть статьи оставила впечатление такое, что дано Вам утверждение, которое надо обосновать любой ценой - и Вы эту задачу решаете. Была тут недавно статья насчёт того, что играми со статистикой можно обосновать что угодно - ну очень похоже.
edo1h
10.05.2022 22:09Просто надо не вдруг в процессе эксплуатации обнаружить, что требуется описанное масштабирование и возникли проблемы
)
Есть ПОСТОЯННЫЙ идентификатор (с точки зрения хранящейся на сервере информации — идентификатор экземпляра сущности с неограниченным временем актуальности). Который отвечает за контроль уникальности. Есть ОДНОРАЗОВЫЙ идентификатор (с весьма ограниченным временем актуальности, для которого не возбраняется дублирование за пределами разумного периода времени). Который отвечает за одноразовость. Для первого — генерируем идентификатор на сервере и там же используем. Для второго — генерируем случайный идентификатор на клиенте (причём связанный с сеансом клиента, а не сеансом обращения клиента к серверу) и передаём серверу для контроля на предмет повторности выполнения.
честно говоря, не понимаю, зачем нужны две сущности, если можно на клиенте сразу генерировать глобально-уникальный идентификатор

BugM
10.05.2022 22:48+8честно говоря, не понимаю, зачем нужны две сущности, если можно на клиенте сразу генерировать глобально-уникальный идентификатор
Вы не контролируете клиента. Вообще. Клиенту нельзя доверять вообще ни в чем. Особенно в таком важном вопросе как глобально уникальный идентификатор сущности.
Локальный для контроля данных именно этого клиента - не вопрос. Он сломав его только сам себе навредит. Нас это устраивает.
Vadimyan Автор
10.05.2022 23:20Про идемпотентность — да, есть решения с отдельным идентификатором типа requestId/operationId, которые требуют дополнительного механизма, и иногда могут усложнять композитную операцию, которую можно перевыполнить частично. В общем случае такой отдельный идентификатор полезен хотя бы потому, что не во всех запросах могут быть реальные идентификаторы, при этом такой подход ведь не исключает поддержку возможности повтора на уровне БД, когда Upsert должен корректно сработать при повторе вставки.
Про SQL insert — видимо, я тут как-то неточно сформулировал предложение. Вставка не усложниться, клиент, если надо, попросит, проблема тут в том, что клиенту обычно надо и он обычно просит, на столько, что ORM типа EF Core это "попросит" включает в запрос вставки, сразу делая insert + select. И в случае с микроорм и абстркатным REST клиент ожидает на вставку или сущность с идентификатором целиком, или сам идентификатор.
С последней частью статьи как-то хотелось подвести к тому, что решение нужно, библиотеки сущетсвуют, но вот нет сейчас чего-то "стандартного" из коробки или почти из коробки где-нибудь в либах EF Core, в BCL хотя бы известной community-библиотеки про RFC 4122. Чаще всего задачу решают ULIDом (для которого есть несколького надежных либ), но, учитывая некоторую хитрую "частично лексикографическую" сортировку ключей в SQL Server, это возможно только с сменой типа данных для хранения, что может оказаться очень значительным переходом.
Изначально я смотрел именно на NewId и надеялся проверить результаты на MySQL как более распространенную (субъективно по моим ощущениям) БД, но так и не нашёл нужного инструмента под неё, зато решил поискать другие реализации для генерации UUID version 1 и был сильно озадачен небольшим выбором.

vanbukin
10.05.2022 22:55+1Проблема Guid в том что у него родовая травма в виде различия строкового и бинарных представлений.
Вот тут https://github.com/dodopizza/primitives/blob/main/src/Dodo.Primitives/Uuid.cs есть реализация (за моим авторством), с API которое «идентично натуральному», но при этом содержит прямой порядк байт как в строковом, так и в бинарном представлении. Алгоритмы генерации можно сбоку написать какие угодно.
BugM
10.05.2022 23:08+1Вы создали что-то что называется стандартно, но при этом никто кроме вас не сможет получить нужные бинарные данные из строкового представления и наоборот никто кроме вас не сможет сказать как этот бинарный массив выглядит в виде строки. А вероятность того что у двух людей строковое представление бинарных данных не совпадет в экстремальной ситуации стремится к 100% (Мерфи не даст соврать)
Пишите код так, как будто сопровождать его будет склонный к насилию психопат, который знает, где вы живёте.
Вот ничему людей история не учит. LE и BE. Ну сколько можно по тем же граблям ходить?
vanbukin
11.05.2022 00:55Вы создали что-то что называется стандартно, но при этом никто кроме вас не сможет получить нужные бинарные данные из строкового представления и наоборот никто кроме вас не сможет сказать как этот бинарный массив выглядит в виде строки.
Я как раз это унифицировал. Подробности можно посмотреть в комментарии соседнего треда с @edo1h
А вероятность того что у двух людей строковое представление бинарных данных не совпадет в экстремальной ситуации стремится к 100% (Мерфи не даст соврать)
Да да, ровно поэтому я эту библиотеку и написал.
Вот ничему людей история не учит. LE и BE. Ну сколько можно по тем же граблям ходить?
Задавался этим вопросом при написании каждой строчки кода. Оно корнями ещё в WinApi вростает.
edo1h
10.05.2022 23:21Вот тут https://github.com/dodopizza/primitives/blob/main/src/Dodo.Primitives/Uuid.cs есть реализация (за моим авторством), с API которое «идентично натуральному», но при этом содержит прямой порядк байт как в строковом, так и в бинарном представлении.
вы про этот guid?
Variant 2 UUIDs, historically used in Microsoft's COM/OLE libraries, use a mixed-endian format, whereby the first three components of the UUID are little-endian, and the last two are big-endian. For example, 00112233-4455-6677-c899-aabbccddeeff is encoded as the bytes 33 22 11 00 55 44 77 66 c8 99 aa bb cc dd ee ff.[11][12] See the section on Variants for details on why the '88' byte becomes 'c8' in Variant 2.а он где-то её используется? сейчас перепроверил,
select newid()в ms sql генерирует обычный uuid variant 1
Variant 1 UUIDs, nowadays the most common variant, are encoded in a big-endian format. For example, 00112233-4455-6677-8899-aabbccddeeff is encoded as the bytes 00 11 22 33 44 55 66 77 88 99 aa bb cc dd ee ffvanbukin
11.05.2022 00:51+1Вот такой незамысловатый пример
var input = new byte[] { 0x00, 0x11, 0x22, 0x33, 0x44, 0x55, 0x66, 0x77, 0x88, 0x99, 0xAA, 0xBB, 0xCC, 0xDD, 0xEE, 0xFF }; var guid = new Guid(input); byte* guidPtr = (byte*)&guid; var real = string.Concat(Enumerable.Range(0, 15) .Select(i => guidPtr[i]) .Select(x => x.ToString("X2"))) .ToUpper(); var bytesStr = string.Concat(guid.ToByteArray().Select(x => x.ToString("X2"))).ToUpper(); var toString = guid.ToString().Replace("-", "").ToUpper();realформируется путём последовательного чтения байт Guid'аbytesStrформируется изToByteArray()toStringформируется из вызоваToString()подали на вход в виде массива байт
00112233445566778899AABBCCDDEEFFи получаем такую картину:real = 00112233445566778899AABBCCDDEEbytesStr = 00112233445566778899AABBCCDDEEFFtoString = 33221100554477668899AABBCCDDEEFFА теперь подадим на вход не массив байт, а строку
var input = "00112233445566778899AABBCCDDEEFF"; var guid = new Guid(input); byte* guidPtr = (byte*)&guid; var real = string.Concat(Enumerable.Range(0, 15) .Select(i => guidPtr[i]) .Select(x => x.ToString("X2"))) .ToUpper(); var bytesStr = string.Concat(guid.ToByteArray().Select(x => x.ToString("X2"))).ToUpper(); var toString = guid.ToString().Replace("-", "").ToUpper();И теперь уже обратная картина
real = 33221100554477668899AABBCCDDEEbytesStr = 33221100554477668899AABBCCDDEEFFtoString = 00112233445566778899AABBCCDDEEFFТо есть строковое и бинарное представление различаются. Корни эта проблема берёт из самой структуры System.Guid, реализаций конструкторов, методов парсинга и представления в виде строки. Ровно эту проблему я и решал, чтобы все 3 переменных были равны.
edo1h
11.05.2022 06:49не верю, что для сишарпа нет готовых реализаций rfc 4122 и потребовалось изобретать велосипед
vanbukin
11.05.2022 11:45+1Теперь есть. Калькой послужили исходники самого Guid’а, только layout структуры правильный, как и все соответствующие методы. А способ сгенерировать 16 байт и положить в эту структуру, как я и писал выше - дело десятое.
P.S. - за велосипед обидно было. Там реализован весь API от System.Guid, полное покрытие тестами. По производительности оно эквивалентно System.Guid, причём как с точки зрения времени выполнения, так и с точки зрения аллоцируемой памяти. Проект с бенчмарками в том же солюшене, можете сами во всём убедиться.

SIMPLicity
11.05.2022 00:05Но быстрая выборка соседних записей - это же был один из главных аргументов за отход от NEWID ( ) в сторону NEWSEQUENTIALID ( )! И тут вдруг : "Но на самом деле влияние фрагментации при чтении данных совсем не так велико, как может представляться — скорее можно назвать его незначительным. Вот пример замера производительности при чтении 10.000 записей и 100.000 записей в запросе."
Замеры на шпиндельном рэйде? Но уже 2022 год на дворе. Где в высоконагруженных системах крутятся шпинделя?
Проблема латчей (коротких блокировок на страницах в памяти) при так желаемых "плотных" вставках с нескольких потоков одновременно,- кажется у Дм.Короткевича был семинар на эту тему,- как раз для высоконагруженных систем.
Ну и это, мне кажется стоит определиться,- мы пилим реально "высоконагруженную систему" или всё-таки делаем масштабируемое решение строя для таблиц primary key clustered на uniqueidentifier .
edo1h
11.05.2022 00:26по первому пункту ИМХО важнее случай когда таблица заметно больше кэша.
зачастую более активные обращения идут к последним данным, при неудачной генерации uuid после перестроения кластерного индекса данные окажутся перемешанными, то есть у нас не будет горячей области.SIMPLicity
11.05.2022 05:11зачастую более активные обращения идут к последним данным,
Но в случае нормализованной модели бд это (ИМХО) не сильно применимо по отношению к справочникам (объём коих может превышать объём центральных таблиц). А при поиске в справочных/нормативных/... базах - вообще мрак ;)
В случае секционирования таблицы, слабо представляю себе как это сделать по кластерному индексу на GUID-ах (хотя это и не является целью,- как правило).
... надо будет как-нибудь придумать тест и "погонять чертей" на IM-OLTP в плане "GUID-индекс V Bigint+Bigint-индекс" ...
edo1h
11.05.2022 06:55не сильно применимо по отношению к справочникам (объём коих может превышать объём центральных таблиц)
ну тут уже, как говорится, против лома нет приёма. если у нас в справочниках нет горячей области, помещающейся в память, то всё плохо.
В случае секционирования таблицы, слабо представляю себе как это сделать по кластерному индексу на GUID-ах (хотя это и не является целью,- как правило)
для таких задач как раз и придумывают упорядоченные uuid вроде описываемых в этой статье (а лучше ulid или планируемый uuidv7).
SIMPLicity
11.05.2022 13:58+1В случае секционирования таблицы, слабо представляю себе как это сделать по кластерному индексу на GUID-ах (хотя это и не является целью,- как правило)
для таких задач как раз и придумывают упорядоченные uuid вроде описываемых в этой статье (а лучше ulid или планируемый uuidv7).
Согласен. Но с оговоркой,- когда секционирование строится согласно порядку поступления данных,- тогда данные будут расти "в хвост" (например), а при слиянии баз записи, близкие по времени появления, будут группироваться рядом.

tmhba
11.05.2022 10:48+3Если отдавать генерацию на сторону клиента, то это порождает сценарии, которые сложно контролировать.
Требуется как-то заставить всех внешних пользователей вашего API применять строго определённую схему генерации условно-последовательных GUID, которые будут наилучшим образом подходить для конкретного используемого хранилища. Например, у MSSQL свой подход к сортировке кластеризованных PK типа 'uniqueidentifier' (по части байтов). У другой БД может быть другой подход. А если разные сущности хранятся в хранилищах разного типа, то для каждой сущности придётся описывать свой тип генерации ID. А если использовать полностью случайные GUID, то это может порождать описанные в начале статьи проблемы с производительностью хранилища.
При этом сервер не имеет возможности как-то контролировать корректность генерации, т.е. мы вынуждены верить клиенту. А если такую возможность и реализовать (под конкретный тип хранилища), то она всё равно будет работать с определёнными допущениями, т.к. для генерации последовательного ID в любом случае придётся применять системное время на клиентской машине, а оно (хотя, сейчас такое редко встречается), вполне может отставать/опережать время сервера на какую-то дельту. Ну и это так же дополнительно породит для клиентов весьма специфичную ошибку "плохой ID сущности".
Смена хранилища (целиком, или для отдельной группы сущностей) - необходимость во всех внешних клиентах API менять механизм генерации ID этих сущностей.

manyakRus
11.05.2022 11:35-1GUID часто случайно совпадает, например в двух разных базах 1С в случае случайного совпадения GUID обмен данными будет(бывает часто) неправильным. Может лучше вообще никогда не использовать GUID поэтому ?

andreymal
11.05.2022 14:26+3UUID/GUID изобретали специально для того, чтобы свести вероятность совпадений почти к нулю. Очень интересно, каким чудом вы умудряетесь получать совпадения «часто» — возможно, это реализация GUID в 1С принципиально неправильная или вы сами её как-то принципиально неправильно используете?

dmitryvolochaev
11.05.2022 17:16Если надо и ID от сервера, и идемпотентность, то почему бы не отделить получение ID от создания объекта?
Мне сразу Хабр приходит на ум. Мы сначала создаем черновик статьи. При этом сервер назначает ему ID. Это не идемпотентно, но лишний черновик - не проблема. Он может вечно жить своей тайной жизнью и никому не мешать. А на этапе публикации у нас уже есть ID.
Хотя такой забытый черновик всё же может вызвать некоторые сложности, если в таблице есть поля, которые FOREIGN KEY и при этом NOT NULL

Sing
12.05.2022 14:31+2Обсуждение наглядно иллюстрирует перегруженность понятий в IT. Под словом «клиент» в оригинале понимался клиент базы данных, то есть то, что напрямую общается с бд, отправляет ей запросы. В комментариях же закономерно решили, что имеется в виду клиент из клиент-сервисной архитектуры, и в итоге каждый обсуждает что-то своё. Так и живём
andreymal
UUIDv7
Vadimyan Автор
Оо, спасибо, добавлю в бенчмарк и опишу. Конечно, смущает, что у пакетов с реализацией этой версии количество загрузок на уровне экспериментов отдельных людей, но никак не продакшен-использования.
edo1h
так стандарт ещё не принят
https://habr.com/ru/post/658855/