
Меня зовут Илья Булгаков, я программист отдела извлечения информации в ABBYY. В серии из двух постов я расскажу вам наш главный секрет – как работает технология Извлечения Информации в ABBYY Compreno.
Ранее мой коллега Даня Скоринкин DSkorinkin успел рассказать про взгляд на систему со стороны онтоинженера, затронув следующие темы:
- Деревья семантико-синтаксического разбора и создание онтологий
- Написание правил извлечения информации
В этот раз мы опустимся глубже в недра технологии ABBYY Compreno, поговорим про архитектуру системы в целом, основные принципы ее работы и алгоритм извлечения информации!

О чем это вы вообще?
Напомним задачу.
Мы анализируем тексты на естественном языке с использованием технологии ABBYY Compreno. Нашей задачей является извлечение важной для заказчика информации, представленной сущностями, фактами и их атрибутами.
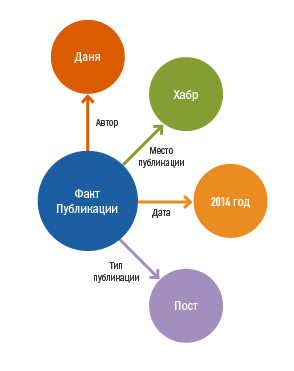
Онтоинженер Даня в 2014 году написал пост на Хабр
На вход системе извлечения информации поступают деревья разбора, полученные семантико-синтаксическим парсером, которые выглядят вот так:

После полного семантико-синтактического анализа системе необходимо понять, что же необходимо извлечь из текста. Для этого потребуется модель предметной области (онтология) и правила извлечения информации. Созданием онтологий и правил занимается специальный отдел компьютерных лингвистов, которых мы называем онтоинженерами. Пример онтологии, моделирующей факт публикации:

Система применяет правила к разным фрагментам дерева разбора: если фрагмент удовлетворяет шаблону, то правило генерирует утверждения (например, создать объект Персона, добавить атрибут-Фамилию и т.п.). Они добавляются в «мешок утверждений», если не противоречат уже содержащимся в нём утверждениям. Когда больше ни одно правило применить нельзя, система строит RDF-граф (формат представления извлеченной информации) по утверждениям из мешка.
Сложность системе добавляет то, что шаблоны строятся для семантико-синтаксических деревьев, существует большое разнообразие возможных утверждений, правила можно писать, почти не заботясь о порядке их применения, выходной RDF-граф должен соответствовать определенной онтологии и еще много других особенностей. Но давайте обо всем по порядку.
Система извлечения информации
В работе системы можно выделить два этапа:
- Подготовка онтологий и компиляция моделей
- Анализ текста:
- Семантико-синтаксический разбор текстов на естественном языке
- Извлечение информации и генерация финального RDF-графа
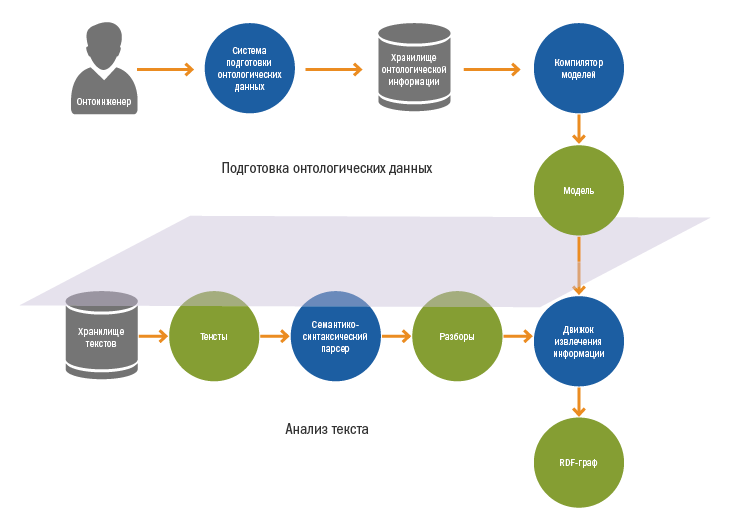
Подготовка онтологических данных и компиляция модели
Подготовка онтологических данных выполняется онтоинженерами в специальной среде. Помимо проектирования онтологий онтоинженеры занимаются созданием правил извлечения информации. Про процесс написания правил мы подробно говорили в прошлой статье.
Правила и онтологии хранятся в специальном хранилище онтологической информации, откуда они попадают в компилятор, который собирает из них бинарную модель предметной области.
В модель попадают:
- Онтологии
- Правила извлечения информации
- Правила идентификации
Скомпилированная модель поступает на вход «движку» извлечения информации.
Семантико-синтаксический разбор текстов
В самых глубинах технологии ABBYY Compreno лежит Семантико-синтаксический парсер. Рассказ о нем достоин отдельной статьи, сегодня мы обсудим только его самые важные особенности для нашей задачи. При желании вы можете изучить статью с конференции Диалог.
Что нам важно знать про парсер:
- Парсер генерирует деревья семантико-синтаксических разборов предложений (по одному дереву на одно предложение). Поддеревья мы называем составляющими. Как правило, узлы дерева соответствуют словам входного текста, но бывают и исключения: иногда несколько слов группируются в одну составляющую (например, текст в кавычках), иногда появляются и нулевые узлы (вместо опущенных слов). Узлы и дуги размечены.

- Узлы опираются на семантическую иерархию. Семантическая иерархия представляет собой дерево родо-видовых отношений, промежуточными узлами которого являются не зависящие от языка семантические классы (например, «HABRAHABR»), а «листьями» – специфичные для каждого языка лексические классы («Хабр:HABRAHABR»). Информация о синтаксической и семантической сочетаемости соотнесена с узлами иерархии. Работает принцип наследования – все, что верно для родительского класса, оказывается верным для дочернего, если в дочернем классе нет явного уточнения.
Пример семантического класса и лексических классов, специфичных для разных языков.


- Помимо семантико-синтаксических деревьев парсер ABBYY Compreno возвращает информацию о недревесных связях между их узлами (дополнительные связи между узлами, которые не могут быть представлены в древесной структуре). Это, прежде всего, связи, выражающие кореферентность (один и тот же объект реального мира упоминается в тексте несколько раз). Например, для фразы «Онтоинженер Даня сидел и писал пост» для глагола «писать» будет восстановлен нулевой субъект, который будет связан недревесной связью с узлом «Онтоинженер». В ABBYY Compreno используются и некоторые другие типы недревесных связей. В ряде случаев недревесные связи могут соединять узлы из разных предложений. Так часто бывает, например, при разрешении местоименной анафоры. Про местоименную анафору мы подробно рассказывали в этом посте и в отдельной статье на конференции Диалог.
Пример восстановленного субъекта (к нему ведет стрелка розового цвета).
Онтоинженер Даня сидел и писал пост.

- Снятие омонимии. В одной из прошлых статей в качестве примера синтаксической омонимии мы предлагали рассмотреть фразу «Эти типы стали есть на складе», которая может иметь совершенно разный смысл в разных контекстах.
Снятие омонимии происходит благодаря двум факторам:
- Учитываются все ограничения, заложенные в семантическую иерархию.
Узлы деревьев, порождаемые парсером, всегда привязаны к некоторому лексическому классу семантической иерархии. Это означает, что в процессе анализа парсер снимает лексическую многозначность.
- Используется статистика сочетаемости, собранная на корпусах параллельных текстов (это такие коллекции текстов, в которых тексты на одном языке идут вместе с их переводами на другой язык). Идея подхода состоит в том, что, имея двуязычный парсер, работающий над единой семантической иерархией, можно собрать качественную статистику сочетаемости на выровненных параллельных корпусах без дополнительной разметки.
При сборе статистики учитываются только те выровненные пары предложений, для которых итоговые семантические структуры оказываются сопоставимы. Последнее означает успешность разрешения омонимии, поскольку омонимия в подавляющем числе случаев несимметрична в разных языках.
Отсутствие необходимости дополнительной разметки позволяет использовать корпуса большого размера.
- Учитываются все ограничения, заложенные в семантическую иерархию.
Слово об информационных объектах
Внутри нашей системы мы работаем не с RDF-графом, а с некоторым внутренним представлением извлеченной информации. Извлеченную информацию мы рассматриваем как множество информационных объектов, где каждый объект представляет собой некоторую сущность/факт и набор ассоциированных с ним утверждений. Внутри системы извлечения информации мы оперируем именно информационными объектами.
Информационные объекты выделяются системой с помощью правил, написанных онтоинженерами. Объекты можно использовать в правилах для выделения других объектов.
Над объектами можно проводить следующие операции:
- Создавать
- Аннотировать фрагментами текста
- Привязывать к классам онтологии
- Заполнять атрибуты
- Связывать с составляющими с помощью механизма «якорей»
Первые четыре пункта интуитивно понятны, и мы уже говорили о них в предыдущей статье. Остановимся подробнее на последнем.
Механизм «якорей» занимает очень важное место в системе. Один информационный объект может быть, в общем случае, связан «якорями» с некоторым набором узлов семантико-синтаксических деревьев. Привязка к «якорям» позволяет повторно обращаться к объектам в правилах.
Рассмотрим пример.
Онтоинженер Даня Скоринкин написал хороший пост

Приведенное ниже правило создает персону «Даня Скоринкин» и связывает ее с двумя составляющими.
name "PERSON_BY_FIRSTNAME" [ surname "PERSON_BY_LASTNAME " ]
=>
Person P(name),
Anchor(P, surname);
Первая часть правила (до знака => ) представляет собой шаблон на дерево разбора. В шаблоне участвуют две составляющие с семантическими классами «PERSON_BY_FIRSTNAME» и «PERSON_BY_LASTNAME». С ними сопоставились две переменные – name и surname. Во второй части правила в первой строке создается персона P на составляющей, которая сопоставилась с переменной name. Эта составляющая связывается «якорем» с объектом автоматически. Второй строчкой
Anchor(P, surname) мы явно связываем c объектом вторую составляющую, которая сопоставилась с переменной surname.В итоге получается информационный объект-персона, связанный с двумя составляющими.

После этого появляется принципиально новая возможность в шаблонной части правил – проверить, что к определенному месту дерева уже привязан информационный объект.
name "PERSON_BY_LASTNAME" <% Person %>
=>
This.o.surname == Norm(name);
Данное правило сработает только в том случае, если к составляющей с семантическим классом «PERSON_BY_LASTNAME» был приякорен объект класса Person.
Почему данная техника важна для нас?
- Вся система выделения фактов опирается на уже извлеченные информационные объекты.
Например, при заполнении атрибута «автор» у факта публикации, правило опирается на созданный ранее объект-персону.
- Техника помогает при декомпозиции правил и улучшает их поддержку.
К примеру, одно правило может только создавать персону, а несколько других могут выделять отдельные свойства (имя, фамилия, отчество и т.п.).
Концепция механизма «якорей» близка понятию референции, однако не в полной мере соответствует принятой лингвистами модели. С одной стороны, якорями часто помечаются разные референты одного и того же извлеченного субъекта. С другой же, на практике так происходит далеко не всегда, и расстановка якорей порой используется как технический инструмент для удобства написания правил.
Расстановка якорей в системе является довольно гибким механизмом, позволяющим учитывать кореференциальные (недревесные) связи. С помощью специальной конструкции в правилах есть возможность связать объект якорем не только с выбранной составляющей, но и с составляющими, связанными с ней кореференциальными связями.
Эта возможность очень важна для повышения полноты выделения фактов – выделяемые информационные объекты автоматически связываются со всеми узлами, которые парсер счел кореферентными, после чего правила, выделяющие факты, начинают «видеть» их в новых контекстах.
Ниже приведен пример на кореференцию. Анализируем текст «Вопросы любви и смерти не волновали Ипполита Матвеевича Воробьянинова, хотя этими вопросами, по роду своей службы, он ведал с 9 утра до 5 вечера ежедневно, с получасовым перерывом для завтрака».
Парсер восстанавливает семантический класс «IPPOLIT» для узла «Он». Узлы связаны кореференциальной недревесной связью (обозначена фиолетовой стрелкой).
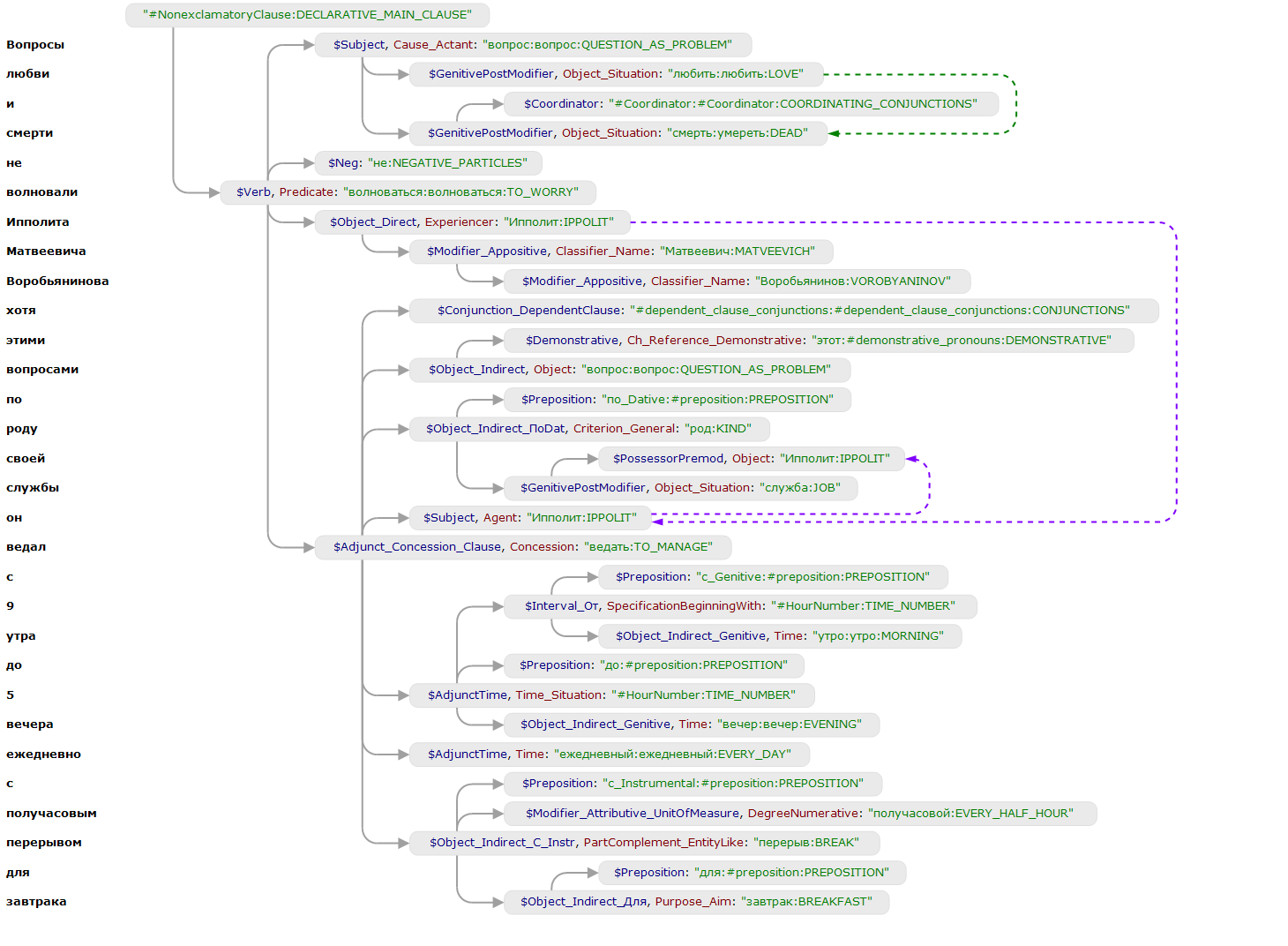
Следующая конструкция в правилах позволяет связать якорем объект P не только с узлом, который сопоставился с переменной this, но и с теми узлами, которые связаны с ним кореференциальной связью (т.е. пройти по фиолетовым стрелкам).
// Утверждаем, что экземпляр P привязан так же к узлу, соотнесенному с
// переменной this. Служебное cлово Coreferential означает, что экземпляр
// автоматически будет привязан ко всем узлам, связанных с данным
// недревесными связями, обозначающими кореференцию.
anchor( P, this, Coreferential )
На этом первая часть подошла к концу. В ней мы рассказали про общую архитектуру системы и подробно остановились на входных данных алгоритма извлечения информации (разборы, онтологии, правила).
Следующий пост, который выйдет завтра, мы сразу начнем с обсуждения того, как устроен «движок» извлечения информации и какие идеи в него заложены.
Спасибо за внимание, оставайтесь с нами!
Update: вторая часть
Комментарии (11)

Ares_ekb
21.10.2015 13:14+1Очень клево! Казалось бы это совершенно естественное направление развития подобных программ, но лично у меня почему-то онтологии всегда ассоциировались с поисковыми системами или интеграционными шинами.

rimsleur
21.10.2015 14:11+1Интересно, почему в последнем дереве узел «9» является подузлом для «5»?

bulgak0v
21.10.2015 17:39+1По ряду причин временные интервалы («с 9 до 5») удобнее представлять цельным поддеревом, а не двумя независимыми друг от друга параллельными поддеревьями.
Например, это удобнее для извлечения информации. При таком способе представления в разборе предложения «Вася работал с 9 до 12 и с 13 до 18» будет два поддерева, по одному на каждый интервал. Если же не группировать каждый интервал в единое поддерево, то по структуре намного сложнее понять, с 9 до 12 работал Вася или с 9 до 18.
Почему вершиной назначен конец интервала, а не начало? Это техническое решение, глубокого смысла в нём нет.



samodum
22.10.2015 11:46Можете назвать какие-нибудь системы, проекты, где это используется?

luciana
22.10.2015 12:33+2Мы планируем в ближайшие пару недель выпустить пост о проектах, где это уже используется, и других возможных сценариях.
Пока, если интересно, можете почитать на сайте о продуктах на основе этой технологии (там, правда, коротко)
ABBYY Smart Classifier
ABBYY Intelligent Search SDK
ABBYY InfoExtractor SDK


Maccimo
25.10.2015 21:09>> Парсер генерирует деревья семантико-синтаксических разборов предложений (по одному дереву на одно предложение).
…
>> Помимо семантико-синтаксических деревьев парсер ABBYY Compreno возвращает информацию о недревесных связях между их узлами (дополнительные связи между узлами, которые не могут быть представлены в древесной структуре).
Почему деревья, а не графы?
Разве последние не более удобны в данном случае?
Или в действительности это графы, маскирующиеся под деревья для удобства онтоинженеров?
aTwice
Разбор реаьлного текста Ильфа и Петрова поражает!