
До меня было написано 4 статьи по экспорту статей с хабра в FB2 и pdf:
- Экспорт избранного Хабра в FB2
- Экспорт избранного Хабра в FB2 — скоростная PHP-версия
- Экспорт Хабра в FB2
- Экспорт Избранного на Хабре в PDF
Я захотел получить исходники своих статей. Поскольку для написания на хабре пользуюсь старым редактором и пишу в markdown, то и основная цель была получить исходник markdown. HTML пошел прицепом, т.к. статьи с хабра получаю в нем, а затем с помощью библиотеки markdownify и некоторых танцев с бубном получаю md.
Как пользоваться
Скрипт написан на python3, скачиваем с github, устанавливаем зависимости и запускаем:
git clone https://github.com/dvjdjvu/habrArticleSrcDownloader
cd habrArticleSrcDownloader
apt-get install python3-lxml libomp-dev
pip3 install -r requirements.txtСкачиваем статьи пользователя:
./src/main.py -u jessy_jamesСкачиваем закладки пользователя:
./src/main.py -f jessy_jamesСкачиваем одиночную статью:
./src/main.py -s 665634Вместо jessy_james подставить имя нужного пользователя или вместо 665634 подставить id нужной статьи. Взять его можно из ссылки профиля:

Или ссылки на статью:

После запуска получаем такую картину:
./src/main.py -u jessy_james
[info]: Скачивается: C/C++ из Python (ctypes) на Android
[info]: Директория: 16 C C++ из Python (ctypes) на Android создана
[info]: Директория: picture создана
[info]: Статья: C C++ из Python (ctypes) на Android сохранена
[info]: Скачивается: Своя docking station для ноутбука
[info]: Директория: 15 Своя docking station для ноутбука создана
[info]: Директория: picture создана
[info]: Статья: Своя docking station для ноутбука сохранена
[info]: Скачивается: Tango Controls hdbpp-docker
[info]: Директория: 14 Tango Controls hdbpp-docker создана
[info]: Директория: picture создана
...
[info]: Скачивается: Игрушка ГАЗ-66 на пульте управления. Часть 2
[info]: Директория: 2 Игрушка ГАЗ-66 на пульте управления. Часть 2 создана
[info]: Директория: picture создана
[info]: Статья: Игрушка ГАЗ-66 на пульте управления. Часть 2 сохранена
[info]: Скачивается: Игрушка ГАЗ-66 на пульте управления. Часть 1
[info]: Директория: 1 Игрушка ГАЗ-66 на пульте управления. Часть 1 создана
[info]: Директория: picture создана
[info]: Статья: Игрушка ГАЗ-66 на пульте управления. Часть 1 сохраненаСтатьи скачиваются от последней написанной к первой. Нумерация будет в порядки написания или добавления в закладки.
Иерархия каталога будет такой:

Создается папка article, favorites или singles, далее папка с именем пользователя, далее папки с названиями статей. В папке со статьей будет два файла (.md и .html) и папка с картинками статьи.
Смотрим что получилось, берем содержимое полученного файла markdown и вставляем в редактор статей:
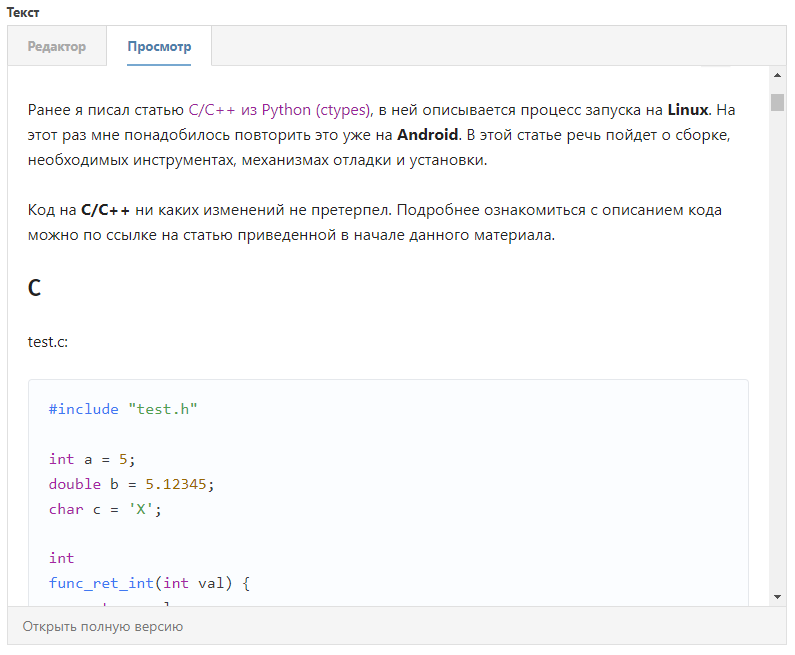
Почти работает как я хотел ;), есть некоторые проблемы с отображением изображений (исходник html отображает правильнее). Постараюсь их исправить.
Спасибо за внимание.
Ссылки
Комментарии (25)

Ploni
12.05.2022 00:51А вот чтоб еще и с комментами - можно такое?

Jessy_James Автор
12.05.2022 18:02+1Добавил, пока кривовато. Не придумал как их красиво сохранять (а главное вытащить).

kt97679
12.05.2022 07:39Можно попросить вас добавить возможность скачать только одну статью по айди?

dot22
12.05.2022 08:22+2Если нужна только одна статья именно в формате md и прямо сейчас, то можно использовать плагин (работает в хроме и опере (через прокладку) https://chrome.google.com/webstore/detail/markdownload-markdown-web/pcmpcfapbekmbjjkdalcgopdkipoggdi
А так - да, действительно было бы замечательно - иметь возможность скачивать не все статьи пользователя сразу, а только какую-то одну конкретную. Ну, и как выше уже писали - если бы еще вместе с комментариями - было бы еще лучше.Обсидиан - который работает с файлами в формате md, - в таком случае вообще можно было бы сделать что-то типа локальной базы знаний избранных статей с хабра - с поиском, тегами, пометками, графами и всякими другими плюшками.
kt97679
12.05.2022 10:22Прошу прощения, надо было точнее сформулировать вопрос. Я ищу решение для скачивания набора статей разных авторов. Хочу заархивировать статьи из своего трекера.
dot22
12.05.2022 13:15Хотелось бы уточнить по поводу трекера. Не совсем понимаю, что Вы имеете в виду?
Из Вашего комментария - "возможность скачать только одну статью по айди"
Как я понимаю, т.е. уже есть какой-то подготовленный список статей, которые Вам интересны, с url-ами, содержащими ID статьи?, как, например, обсуждаемая статья
https://habr.com/ru/post/665254/
Если есть список - почему бы не использовать специализированные инструменты, именно и предназначенные для скачивания файлов любого типа из интернета - первое, что приходит на ум - wget или curl.Если же интересует именно формат md, то после (или даже во время загрузки по пайпу) файлы в формате html уже локально можно переконвертировать в md (вроде как pandoc это умеет искаропки)
Или я опять делаю поспешные выводы?
kt97679
12.05.2022 19:24Можно попросить вас уточнить как вы предлагаете использовать wget? Спрашиваю потому, что если сделать
wget -r -np https://habr.com/ru/post/665254/, то скачиваются 2 файла: с содержимым статьи и с комментариями:$ find . -type f
./habr.com/ru/post/665254/index.html
./habr.com/ru/post/665254/comments/index.html
./habr.com/robots.txt
$
В результате я вижу 2 проблемы: как скачать прочие ресурсы, например картинки, не выкачивая весь хабр. И как склеить тело статьи с комментариями.
Jessy_James Автор
12.05.2022 14:32+1Добавил возможность скачивать свои закладки.
Скачиваем статьи пользователя:./src/main.py -u jessy_james
Скачиваем закладки пользователя:./src/main.py -f jessy_james
kuaniv
12.05.2022 16:58+3Спасибо! Отличный скрипт! Скачал уже 2 Гб статей.
Столкнулся с такой особенностью. Если заголовок статьи содержит, например, знак вопроса, то имя папки и файлов будут включать экранированный знак вопроса '/?'. Если эти файлы потом перенести в Win, то их имена не читаются. Можно добавить в скрипт игнорирование спецсимволов при создании файлов/папок?
Jessy_James Автор
12.05.2022 17:19+1Да, есть такая проблема. Не все спец. символы которые запрещены в использовании имен папок убираю. Поправлю в ближайшее время.
Jessy_James Автор
13.05.2022 20:42+1Убираю спец. символы, если какие не учел напишите, или поправьте и pull request мне.

AquariusStar
12.05.2022 23:19Хороший инструмент! Я обычно сохраняю в pdf. Но это не всегда удобно. Если есть анимированные картинки, то уже совсем грустно становится. Кстати, в некоторых статьях есть картинки с форматом jpeg и с форматом PNG. Вот jpeg почему-то портит картинку в браузере и VS Code. Только отдельным просмотрщиком можно смотреть. А вот PNG уже нормально. Есть ли возможность указать на принудительное сохранение картинок в нужном формате? А также сделать сохранение только конкретной статьи, а не всех?
Jessy_James Автор
13.05.2022 20:45Принудительный формат картинок не укажешь, картинка скачивается по ссылке которая указана в статье (Что автор поставил, то и будет.).

arboozof
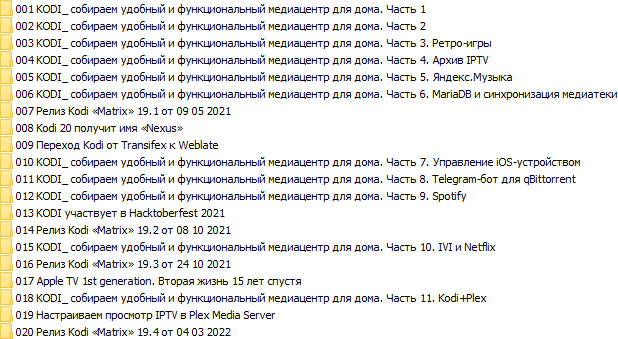
13.05.2022 14:08+1Есть предложение использовать в именовании каталогов 3-значную порядковую нумерацию, дополняя слева незначащими нулями (например, 001 — каталог с публикацией #1, 078 — каталог с публикацией #78). Дабы на выходе, при отображении каталогов в файловом менеджере, была сортировка, как вы и задумывали — от последней написанной к первой (хотя при загрузке своих публикаций я получил обратную сортировку, которая как мне кажется и правильная — от первой написанной к последней).

Jessy_James Автор
13.05.2022 16:26+1Я писал, что скачивается от последней статьи к первой. Нумерация же как раз шла от первой написанной к последней. Сейчас же из за многопоточности порядок скачивания как получится.
arboozof
13.05.2022 17:24+1В моем случае они скачались ровно по порядку от старой к новой, с соответствующей нумерацией. По трехзначной нумерации, эстетики ради, подумайте...
Jessy_James Автор
13.05.2022 23:01+1Добавил возможность скачивания одиночной статьи:
./src/main.py -s 665634
MentalBlood
Отличная идея
Если решите развивать, было бы круто добавить многопоточность и оформить в виде питоновского пакета (чтобы можно было
pip install habrArticleSrcDownloader)Jessy_James Автор
Спасибо. Многопоточность из головы выпала. Добавлю ваши замечания.
Jessy_James Автор
Многопоточность добавил, теперь все зависит от кол-ва ваших процессоров.