
Успел не все, что запланировал. Текст бы еще надо хорошенько причесать, но раз обещал в среду, пока публикую что есть. В этой части в общих чертах описаны процессы, которые происходят в цифровых электрических схемах, а так же ограничения, которые накладывают законы реального мира на процесс вычислений. Главными результатами являются понятия латентности и глубины формальной логической схемы, а так же связь этих величин с предельной тактовой частотой материализованного вычислительного устройства.
Примерное оглавление будущей книги.
Предыдущая статья
Текст, конечно, получился объемным — не самая веселая часть предмета. Я спешил разобрать парочку интересных и использующихся на практике схем, но был вынужден отложить их до следующей статьи. В качестве залога на обложке вы видите одну из них. Если сравнивать содержание будущей книги с настольной игрой, то собственно игра начнется со следующей статьи, а эту и предыдущую стоит воспринимать как брошюру правил. Правила — быть может не самая интересная часть процесса, но не освоив их в достаточной мере, вам трудно будет эффективно и с пониманием играть.
Возможно, в вашем браузере с первого раза не будут правильно отображаться формулы. Если так, попробуйте перезагрузит страницу — на моем компьютере этот фокус работает.
Приятного чтения.
Некоторые исправления и замечания к предыдущей статье
Уже после того, как предыдущая часть была мной опубликована, я осознал, что некоторые выбранные мной термины и понятия не вполне удобны. Прийти к этому пониманию мне помогли в том числе и здоровая критика моих читателей, в частности пользователей СВЕТ_ТЬМЫ и karambaso. Я считаю, будет правильным внести небольшие правки прямо сейчас, тем более, что эти статьи являются черновиком и их предназначение как раз и состоит в том, чтобы в процессе своего написания улучшаться и становиться удобнее для восприятия читателем.
Логическая схема и диаграмма значений
Первая правка будет касаться самого понятия логической схемы. Изначально в понятие схемы была включена и ее конструкция и то, какие именно значения ее компоненты (шины, порты и блоки) принимают на каждом такте. Ожидаемо, в какой-то момент повествования пришлось говорить о конструкции отдельно от значений. Как назвать конструкцию? Скелетом или остовом схемы? Хорошо, а если есть похожая конструкция из логических блоков портов и шин, но элементам которой нельзя приписать на каждый такт значения таким образом, чтобы они удовлетворяли аксиомам схемы, тогда вся эта конструкция уже не скелет?
В общем поломав немного голову, я решил поступить так.
Впредь под термином логическая схема мы будем понимать любое множество правильно соединенных между собой портов, логических блоков и шин. Под правильностью соединения подразумевается соответствие всей конструкции аксиомам P1 — P3, B1 – B3 и до тех пор, пока мы говорим об элементарных схемах – аксиомам C*. Отдельно мы будем выделять логические схемы, удовлетворяющие конструкционной аксиоме A* и называть последние схемами без циклов функциональной зависимости, или коротко: функционально ациклическими схемами.
В свою очередь логическую схему (в ее новом понимании), вместе с приписанными на каждый такт значениями ее портам, шинам, и состояниям регистров, мы будем называть допустимой диаграммой значений, если и только если совокупность этих значений удовлетворяет всем оставшимся аксиомам, а именно: T, P4-P7, S1, S2, B4, B5, E1-E11. Таким образом выходит, что старое понятие логической схемы мы, по сути, приравняли новому понятию допустимой диаграммы значений.
С изменением названий терминов поменяется звучание теоремы о функциональной ацикличности. Новая ее формулировка ставится проще и звучит теперь так:
если некоторая (элементарная) логическая схема не содержит циклов функционального влияния, то для любых заданных на каждый такт значений ее внешних выходных портов и любых заданных на момент нулевого такта значениях состояний ее регистров метод прямого распространения данных позволяет построить ту единственную допустимую диаграмму этой схемы, для которой состояния регистров на нулевом и значения внешних выходных портов на каждом такте совпадают с заданными.
Пояснения, касающиеся понятия внешних входных и внешних выходных портов на схеме
Да, наверное, это сбивает столку. Если слышишь две фразы: «внешний выходной порт схемы» и «выходной порт логического блока», то интуитивно проводишь между ними параллель. Кажется очевидными, что назначение, которому служит внешний выходной порт на схеме, должно быть аналогично роли, которую играет выходной порт у логического блока.
Однако, это не так. Наши формальные определения с такой аналогией идут в разрез.
Мысленный ряд здесь должен быть другим. Он строится на предположении, что не все устройства, влияющие на поведение схемы, изображены на ней целиком. Если устройство изображено на схеме целиком, то все порты этого устройства имеют атрибут внутренних. Внешними же названы те порты, которые сами присутствуют на схеме, а вот устройства, которым они принадлежат, в эту схему непосредственно не включены.
Согласно этой точке зрения, дистанционно вынесенные на материнскую плату компьютера входные порты принтера, монитора, и аудиосистемы – являются для платы внешними входными, то есть физически присутствующими на ней входными портами тех устройств, которые сами размещены за ее пределами. С другой стороны, так же дистанционно размещенные на плате выходные порты мыши, клавиатуры и сканера – являются по отношению к плате внешними выходными портами.
Указанная интерпретация на первый взгляд противоречит тому обстоятельству, что разъемы на плате, куда подключаются кабели от принтера, монитора и аудиосистемы, по своему смыслу являются выходными портами самой материнской платы, рассматриваемой как единое устройство, а разъемы, куда подключаются клавиатура и мышь – ее входными портами.
В действительности между обеими трактовками никаких противоречий нет. Все зависит от выбранной точки зрения.
Если вы рассматриваете материнскую плату как обособленное цельное устройство, то расположенные на ней разъемы для клавиатуры и мыши имеют смысл входных портов, то есть тех, на которые должны быть поданы электрические импульсы в процессе работы, а разъемы для монитора и принтера – как выходные порты, поскольку последние сами являются источниками цифрового сигнала.
В то же время, если плату рассматривать «изнутри»: как собранную из отдельных устройств логическую схему, то «обратная» стороны разъема для клавиатуры будет выглядеть, как дистанционно вынесенный порт выхода (клавиатура порождает импульсы), а обратная сторона разъема для монитора – как типичный порт входа (на него нужно отправлять импульсы).
Из незначительного — изменилось графическое изображение портов: теперь полукруги, обозначающие внутренние порты, крепятся к своим блокам снаружи. Так больше места и кое-что еще, но об этом плюсе вы узнаете в следующей статье.
Замена термина «фронт распространения сигнала» на «фронт распространения данных»
Словосочетания «фронт сигнала» имеет устоявшееся значение в физике электрических цепей и электротехнике, особенно в контексте «передний фронт сигнала» и «задний фронт сигнала». Чтобы не сбивать с толку ненужными ассоциациями представителей этих профессий, впредь вместо использовавшегося в прошлой статье термина «фронт распространения сигнала» (параграф, посвященный методу прямого распространения данных), для названия того же понятия мы будем использовать термин «фронт распространения данных».
Далее. Немного изменен смысл и алгоритм построения фронтов распространения данных. Теперь каждый порт входа, если тот единственный порт выхода, с которым он соединен общей шиной, принадлежит фронту
Статическая дисциплина
Изменения там, где их нет.
Со стороны читателя может прозвучать обоснованный вопрос, почему «метод прямого распространения данных» получил именно такое название, ведь определяющая его процедура построения фронтов относится к одному единственного такту, а в продолжение любого такта значения всех элементов абстрактной схемы по определению остаются неизменными. Почему для описания статической картины значений были выбраны «динамические» термины “фронт” и “распространение”, повседневное значение которых неразрывно связанны с чем-то меняющимся и непостоянным. Ответы на эти вопросы на самом деле важны как для лучшего понимания самой теории, так и для осознания пределов ее применимости.
Вернемся к истокам. В самом начале было сказано, что прообразом абстрактных логических схем являются реально существующие электрические (или другого рода) логические схемы, в которых реальные физические устройства обмениваются и преобразуют настоящие электрические (или другого рода) импульсы. По сути вычислительные возможности именно этих реальных логических схем и являются настоящим объектом нашего изучения, а выстроенная в последствии теория – это всего лишь стандартный метод исследования.
Переход от непосредственно явления к его теории позволяет исследователю игнорировать все несущественные второстепенные черты явления и тем самым сконцентрировать свое внимание на главном. В рамках этой книги главной чертой цифровых электрических схем считается их способность производить символьные вычисления. Собственно вопросу эффективной организации таких вычислений и посвящена книга.
Конечно, деление черт на существенные и несущественные происходит всегда весьма условно и зачастую в погоне за простотой теории приходится жертвовать кое-чем действительно важным. Например, наша теория не отражает такие важные особенности работы микросхем, как конечность скорости распространения сигналов, временные задержки в обработке сигналов элементами схемы, размер схемы, ее предельную рабочую частоту, потребляемую мощность и характеристики тепловыделения. О каждой из этих особенностей мы еще будем говорить в этой книге, сейчас же нас особенно интересуют первые две.
Гидродинамическая аналогия
В рамках этого параграфа мы ненадолго выйдем за рамки теории и будем говорить не о формальных понятиях а об их значениях в реальном мире.
То, какое значение передается по проводу в цифровой электрической схеме: логический “ноль” или логическая ”единица” – (обычно) определяется по уровню напряжения в проводе. Изменения напряжения, как и все в этом мире, не происходят и не распространяются мгновенно. Чтобы описать, как происходят эти изменения, нам, вообще говоря, пришлось бы прибегнуть к науке об электричестве.
С моей стороны, однако, было бы неправильно предполагать у читателя этих знаний (да и сам я почти все забыл), поэтому с вашего позволения я прибегну пусть и не к совсем точной, но зато к наглядной и простой аналогии.
То, чем он является и то, как он со временем себя ведет, уровень напряжения в проводе во многом напоминает уровень воды в длинном оросительном канале.
Представьте, что канал изначально пуст, а на одном из его концов только что открылся шлюз, соединяющий канал с полноводным водохранилищем. Уровень воды в канале не станет высоким мгновенно: с открытием шлюза вдоль всей длины канала прокатится приливная волна. По мере того, как волна будет продвигаться все дальше, ее сила постепенно начнет ослабевать, поэтому, когда фронт волны в итоге ударится о стену в конце канала, уровень воды отнюдь не по все его длине достигнет отметки наполнения. Потребуется еще некоторое время, чтобы канал полностью наполнился водой.

Распространение приливной волны вдоль реки
Теперь представьте, что после того, как канал наполнен, шлюз, соединявший его с водохранилищем, перекрыли, но зато отрыли соседний шлюз, ведущий в бескрайние иссушенные солнцем поля. Процесс, сопровождавший наполнение канала, повторится с точностью до наоборот. По каналу прокатится теперь уже волна отлива. До тех пор, пока фронт отлива не достигнет дальнего конца канала, уровень воды там ничуть не изменится, а после – еще продолжительное время будет плавно падать, пока канал полностью не опорожнится.
Можно сделать вывод, что величина задержки времени между тем, как сработает шлюз и тем, как на противоположном конце канала уровень воды достигнет стабильного значения, зависит от главным образом длины канала, а также от отношения объема канала (емкости) к величине потока чрез шлюз. Почти то же самое утверждение будет верно и для однобитных шин (проводов) цифровой электрической схемы.
Выстраивая аналогию дальше, можно сказать, что функционирование каждого выходного порта вычислительного схемы подобно работе двух только что описанных шлюзов. Послать в шину “единицу” – это как открыть шлюз, соединяющий канал с водохранилищем, сохраняя при этом закрытым шлюз, ведущий в поля. Послать “ноль” – это как открыть шлюз в сторону поля, при закрытом шлюзе из водохранилища. Таким образом значения портов выхода – это либо роль шлюза “наполнения”, либо роль шлюза “опорожнения” для соединенной с портом шины.
Работу входных портов можно сравнить с работой механического поплавкового уровнемера с двумя главными значениями: “канал полон” и ” канал пуст”. Если напряжения в той точке провода, где расположен входной порт, выше некоторой отметки a, то этот порт приобретает логическое значение “1”, если же уровень напряжения в этой точке падает ниже, чем некоторая отметка b < a, то логическим значением будет “0”. Уровни напряжения, которые выше a, либо ниже b, условимся называть регулярными. Логическое значения порта входа в моменты, кода уровень напряжения находится где-то между b и a, считается не определенным.

Физический такт в отличие от формального – это некоторый довольно продолжительный отрезок времени, на протяжении которого напряжения в портах и шинах могут непрерывно меняться. Длина физического такта подбирается так, чтобы при любом сценарии вычислений к концу такта уровни напряжений на всех шинах и портах схемы успели бы прийти к какому-то окончательному регулярному значению, которые за тем уже бы не менялись, сколько этот такт не продлевай. То (регулярное) значение порта или шины, которое на текущем такте уже не будет больше меняться, мы назовем стабильным.
Вспомним, что функциональными в нашей теории мы назвали те (элементарные) логические блоки, у которых значения портов выхода на каждом такте однозначно определяется значениями их портов входа. Для физических устройств, которые реализуют блоки функционального типа, характерно то, что их работа вообще не привязана к физическим тактам: каждый раз, как только уровни напряжения на всех входных портах функционального блока достигают регулярных значений (а это может происходить неоднократно за один физический такт), почти сразу после этого каждый его выходной порт приобретает правильное с точки зрения логики этого блока значение. Поскольку значение порта выхода – это либо роль шлюза “наполнения”, либо роль шлюза “опорожнения” для соединенной с ним шины, то из сказанного мы можем сделать два вывода:
- если начиная в некоторый момент уровни напряжения на входных портах функционального блока достигли стабильных регулярных значений, то спустя некоторое время в проводах (однобитных шинах), с которыми соединены порты выхода этого блока, урони напряжения также достигнут стабильных регулярных значений (все каналы будут в конце концов либо наполнены либо опорожнены);
- если в продолжение некоторого обозримого будущего уровни напряжения на входных портах
функционального блока могут изменится, то вообще говоря нельзя гарантировать, что в этот период значения его выходных портов, а следовательно и уровни напряжения в присоединенных к ним проводах (однобитных шинах), не изменятся тоже.

(рисунок, объясняющий, почему в предыдущих предложениях так много “вообще говоря”).
Оговорка: “вообще говоря”, имевшая место в пункте 2) связана конечно с тем, что не во всех ситуациях изменение одного конкретного входного порта функционального блока должно сказаться на значениях его выходных портов. Все зависит от логической функции, которую реализует блок, его физического устройства и того, как меняются уровни напряжения на остальных его входных порта. Тем не менее от фразы “вообще говоря” можно избавится, если считать, что логика работы блока нам не известна. В таком случае мы действительно не сможем гарантировать стабильности значений на выходных портах функционального блока прежде, чем у нас появится гарантия стабилизировались напряжения на его портах входа.
Переходные процессы, происходящие в продолжение одного физического такта
Внутри аксиоматической теории значения шин и портов на протяжении каждого такта по определению остается неизменным. В некотором смысле формальный такт даже не “длится” – вместо этого он всего лишь “существует” подобно фотографии, запечатлевшей показания приборов в кабине самолета.
Как уже упоминалось, физический такт в отличие от формального – это продолжительный отрезок времени, длина которого подбирается так, чтобы уровни напряжений на всех шинах и портах схемы успели стабилизироваться на каком-нибудь из регулярных значений.
Собственно, с позиции символьных вычислений, нам интересны именно эти предельные стабильные значения, и совершенно не важно, как именно уровни напряжений в портах и шинах к ним пришли. По этой причине теория логических схем была создана нами так, чтобы в каждом из формальных тактов значения шин и портов оставались статичными, а от такта к такту менялись скачком. Для целей нашего исследования переходные процессы – это второстепенная черта, которой можно пренебречь. Тем не менее, чтобы создавать по-настоящему эффективные логические схемы, кое-какое представление о переходных процессах иметь все-таки необходимо.
К концу каждого физического такта уровни напряжения на всех портах и во всех шинах схемы приходят к стабильным регулярным значениям. Рассмотри мгновение, когда очередной такт завершился и только что начался следующий. Вполне возможно, что стабильные значения напряжений в портах и шинах в конце этого нового такта должны быть другими, нежели они были в конце предыдущего такта. Проследим в таком случае, где зарождаются и как распространяются изменения уровней электрического напряжения в компонентах схемы.
В рамках принятой нами упрощенной картины мира единственной причиной изменения уровня напряжения в проводе (однобитной шине) может быть только изменение режима работы соединенного с ней выходного порта (с «наполнить» на «опорожнить», или наоборот).
В самые первые мгновения нового такта такими портами не могут быть выходные порты функциональных блоков. Действительно, изменения по шинам распространяются не мгновенно, поэтому некоторое время уровень напряжения в тех точках шин, где к ним прикреплены входные порты любых, в том числе и функциональных блоков, будет оставаться неизменными. Раз некоторое время не будет меняться стабильное в прошлом значение входных портов, то в этот же период останутся неизменными режимы работы выходных портов любого из функциональных блоков.
И так, претендентами на роль затравок изменений напряжений в схеме остаются только внешние выходные порты и выходные порты регистров, другими словами, те порты, из них которых по определению состоит нулевой фронт распространения данных
Здесь может возникнуть догадка, что в этих же шинах, возмущенные первыми, уровни напряжения первыми и придут к стабильным значениям. Но это не совсем так. Не всегда будет верным и предположение, что следующие порты, которых коснутся изменения, обязательно должны принадлежать фронту
Однако некоторая чуть более аккуратно сформулированная мысль все же естественно связывает нумерацию фронтов и порядок, в котором происходит стабилизации напряжений в шинах. Чтобы избавится от частых оговорок, будем считать, что о каждом блоке схемы нам известно, является ли он функциональным или нет, но ничего более конкретного о внутренней логике его работы мы не знаем.
Пусть
Пусть теперь
Объединяя две последних цепочки рассуждений в одну, получаем следующее утверждение:
Если логика работы блоков остается для нас тайной, то мы не сможем гарантировать, что значения всех портов фронта
Латентность логической схемы
Главный вопрос и декомпозиция проблемы
Длительность одного такта трудно сделать меньше, чем время, за которое напряжения во всех шинах и портах схемы гарантированно смогут прийти к стабильным значениям. Последнюю величину назовем временем релаксации схемы. Получается, что чем меньше время релаксации, тем выше может быть сделана тактовая частота, то есть, выше достижимая вычислительная производительность схемы. Пусть перед нами стоит задача, пользуясь заранее определенными физическими блоками и известной технологией их соединения, спроектировать логическую схему, которая бы реализовывала некоторый алгоритм. Поскольку для одного и того же алгоритма существует, вообще говоря, много возможных схем его реализации (микроархитектурных решений), то естественным образом возникает вопрос:
Как выбор того или иного микроархитектурного решения влияет на максимально возможную тактовую частоту схемы, изготовленной в соответствии с этим решением?
Точно рассчитать время релаксации вычислительной схемы – задача не из просты. Ее решение требует симуляции или даже натурного эксперимента, а результат существенно зависит от технологии, выбранной для изготовления будущей схемы. Безусловно, рассуждая только на уровне абстрактных схем и логических блоков, точно определить время релаксации не получиться, однако кое-какие оценки асимптотического поведения его величины, так называемые O-большое оценки, – дать все-таки можно.
На время релаксации физической схемы влияют главным образом два обстоятельства. Первое из них – это то, что электрические сигналы в шинах распространяются с конечной скоростью, поэтому на преодоление пути от одного блока к другому им требуется некоторое время. Второе заключается в том, что и каждому блоку требуется некоторое время (время реакции, задержка блока), чтобы значения его выходных портов успели отреагировать на изменившиеся значения портов входа.
Разумно предположить, что если схема состоит из небольшого числа блоков и ее размер на кристалле поэтому мал, или в ней заведомо не велика протяженность самого длинного пути, по которому может пройти сигнал за один такт, то величина времени релаксации будет главным образом обусловлена задержками внутри отдельных блоков. Именно эти случаем мы сейчас и займемся, а о том, какой подход следует применять к большим схемам, поговорим позже.
Упрощенная модель релаксации
Пусть каждый такт – это длящийся отрезок времени, настолько продолжительный, что дальнейшее увеличение его длины не приведет ни к каким дополнительным изменениям значений портов и шин в этот период. Значения каждого порта или шины в каждый момент такта может быть либо определено и тогда являться неким двоичным словом, либо не определено. То определённое значение порта или шины, которое больше до конца такта не изменится, как раньше, будем называть стабильным.
Будем считать, что сигналы от порта к торту передаются мгновенно. Таким образом значение каждого выходного порта и всех входных портов, с которыми тот соединен общей шиной, одинаковы любой момент времени. В частности, все эти значения либо определены, либо – нет, и каждое из них стабильно тогда и только тогда, когда стабильны все остальные.
Далее, пусть для каждого функционального блока
Регистры отличаются от функциональных блоков тем, что значения, принимаемые на текущем такте их портами входа, никак не влияют на значения, которые примет в этот такт их порт выхода, однако первые должны определить то, каково будет внутреннее состояние регистра в следующий такт времени. В свою очередь стабильное значение порта выхода регистра на каждом такте должно совпадать со значением внутреннего состояния, в котором в тот момент находится регистр. Достижение равенства в обоих случаях может требовать времени, поэтому для каждого типа регистров определим задержку стабилизации состояния и задержку стабилизации данных.
Задержка стабилизации состояния регистра
Задержка стабилизации данных
Пусть имеется некоторая элементарная логическая схема без циклов функционального влияния. Будем отсчитывать время с того момента
Каждому внешнему выходному порту схемы по условию для этого понадобится дополнительно 0 единиц времени.
У блоков констант нет портов входа, поэтому даже на нулевом такте значение выходных портов блока-константы
Выходному порту любого из регистров, чтобы принять окончательное значение, понадобится время не большее, чем его задержка стабилизации данных
Стоит заметить, что внешние выходные порты, выходные порты блоков-констант и выходные порты регистров как раз составляют формально определенный нами фронт распространения данных
Рассмотрим на схеме любой функциональный блок
Примем число
Будем рассуждать по индукции. Моменты, когда каждый порт фронта
Каждый входной порт, принадлежащий фронту
Предположим, что для всех портов, принадлежащих фронтам
Пусть теперь
Поскольку логическая схема по условию не содержит циклов функциональной зависимости, то каждый ее порт содержится в одном из фронтов
Зачем нам вообще понадобилось вычислять оценку запаздывания портов?
Если мы использовать схему, как вычислительное устройство и для этого каждый такт специальным образом формируем значения внешних выходных портов схемы, то хотим, чтобы результаты расчетов, то есть значения внешних входных портов схемы, были на каждом такте корректны.
Чтобы на конкретном такте значения внешних входных портов схемы гарантированно приняли корректные значения, нам придется выждать время равное максимуму из оценок запаздывания, приписанных этим портам. Обозначим это время, как
Чтобы получать корректные данные на каждом из тактов, мы должны быть уверены, что все регистры схемы правильно меняют свои внутренние состояния. Пусть
Наибольшее из чисел
Поскольку процесс вычисления латентности схемы требует оперирования только со стационарными, не меняющимися на протяжении физического такта значениями, то мы можем поместить его внутрь той формальной аксиоматической теории логических схем, что была разработана нами ранее. Действительно, все, что для этого требуется – это назначить каждому функциональному типу элементарных блоков B формальную величину задержки (∆t)_B, а каждому типу регистров
Абстрактную логическую схему
Формальную задержку блоков прямого соответствия, реализация которых, как уже говорилось, не требует никаких физических устройств, чаще всего можно считать равной нулю. То же самое касается и блоков-констант (провод высокого и низкого напряжения). Фактические задержки в устройствах, реализующих остальные типы блоков, сильно зависят от технологии, но почти в любой из них будут иметь один порядок величины. Для O-большое оценок латентности схемы (а значит и предельной частоты ее работы) задержки всех блоков, кроме блоков прямого соответствия и блоков констант, удобно считать равной 1. Выбор каких-то других (ненулевых) значений на O-большое оценки все рано никак не повлияет.
Следующие два подраздела этого параграфа содержат несколько полезных результатов о вычислении запаздывания портов и величины латентности схемы. Их содержания также может рассматриваться с чисто формальной стороны.
Критический путь
Алгоритм, который мы использовали для приписывания портам логической схемы оценок запаздывания и отыскания латентности всей схемы целиком во многом похож на графовый алгоритм планирования порядка выполнения взаимозависимых работ на производстве (так называемые диаграммы Ганта). Нам будет полезно развить эту аналогию дальше.
Направленным графом
- Для каждого ребра должна существовать в точности одна вершина, которая служила бы ему началом.
- Для каждого ребра должна существовать в точности одна вершина, которая служила бы ему концом.
Самый маленький направленный граф с непустым множеством ребер состоит из всего одного ребра и всего одной вершины, которая служит ему и началом, и концом.

Направленная петля
Конечная последовательность ребер
Направленный путь, начало и конец которого совпадают, называется направленным циклом. Если в направленным графе нельзя построить ни одного направленного цикла, то такой граф называют (направленно) ациклическим. В ациклических графах ни один путь не может включать одно и то же ребро дважды.
Любое множество ребер
Пусть
В том случае, когда каждому ребру e направленного графа приписан некоторый действительнозначный вес
Пусть
Позже нам понадобится одна простенькая
Лемма 1 (об экстремальных свойствах путей с минимальной и максимальной длиной):
Пусть
!) любой начальный отрезок пути
!!) любой конечный отрезок пути
!!!) всякий фрагмент пути
Докажем !), доказательства остальных пунктов проводятся аналогично.
Пусть
Докажем от противного, что
Если это не так, то существует путь
получающийся объединением пути
На этом необходимое знакомство с теорий графов завершено и теперь мы снова возвращаемся к алгоритму оценки запаздываний портов логической схемы.
Согласно определению, данному в прошлой статье, порт p имеет непосредственное функциональное влияние на порт
Пусть
На самом деле для наших целей будет удобно немного расширить множество вершин такого графа и доопределить в нем некоторое количество дополнительных ребер.
Для каждой правильно построенная логической схемы
- Множество вершин
включает в себя все порты схемы
, а также еще две дополнительные вершины для каждого входящего в ее состав регистра
:
,
, одну дополнительную вершину
для каждого входящего в ее состав блока-константы
и одну дополнительную вершину
для каждого внешнего выходного порта
. Вершины
и
мы будем называть мнимым портом входа и мнимым портом выхода регистра
,
– мнимым входом блока-константы
,
— мнимым спутником внешнего выходного порта
(Называть дополнительные вершины мнимыми портами – это всего лишь удобная абстракция, на самой схеме
мнимых портов конечно нет).
- Если вершинами
и
графа
являются “настоящие” порты
и
схемы
, то по определению направленное ребро от
к
существует тогда и только тогда, когда
непосредственно функционально влияет на
.
- Пусть
– какой-то регистр в
, порты
– это все (настоящие) порты входа
,
— его единственный (настоящий) порт выхода. Единственным ребром с началом в вершине
является ребро с концом в
. Для всякого входного порта
регистра
в
существует единственное ребро, соединяющее
с
- Пусть
– блок-константа,
– его единственный (настоящий) порт выхода, в
существует единственное ребро с началом в
и концом в
.
- Пусть p — внешний выходной порт, а in(p) — его мнимый спутник, в
существует единственное ребро с началом в
и концом в
- Никаких других ребер в
нет.
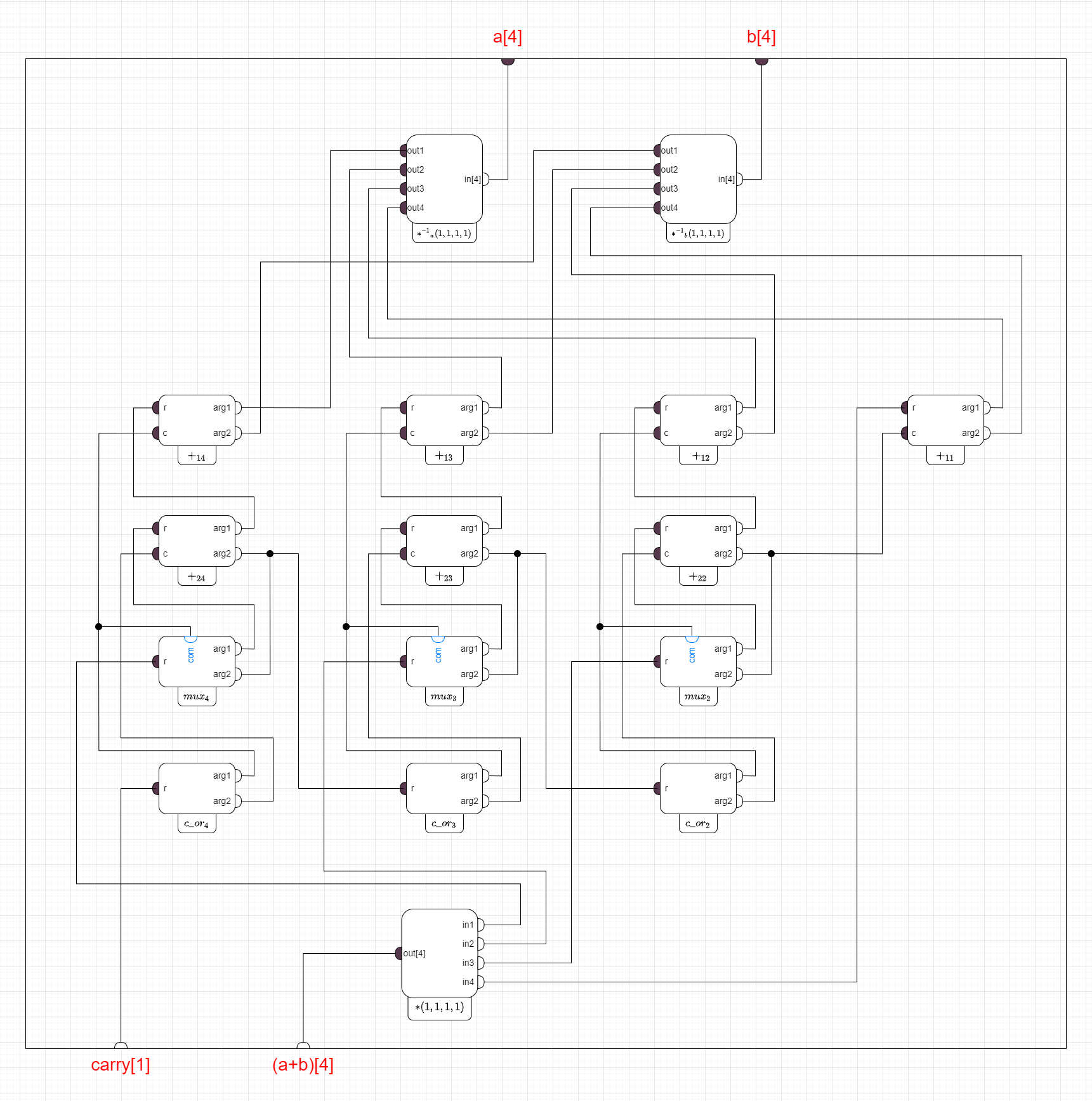
В качестве примера я еще раз привожу схему пульсара из прошлой статьи, а ниже — ассоциированный с ним граф.

(Схема «пульсар»)

(Граф, ассоциированный с «пульсаром»)
Попытайтесь самостоятельно доказать следующую простую
Лемма 2 (о свойствах путей в ассоциированном со схемой графе):
Пусть
!) Ассоциированный с ней граф
!!) Пусть
Пусть теперь
- Всякому ребру, проведенному от “настоящего” порта выхода к “настоящему” порту входа припишем вес 0 (задержки в шинах нет).
- Всякому ребру, проведенному от “настоящего” порта входа к “настоящему” порту выхода и поэтому соединяющему два порта одного и того же функционального логического блока
, припишем вес
.
- Всякому ребру, проведенному от мнимого порта
блока-константы
к его порту выхода, припишем вес
.
- Всякому ребру, проведенному от мнимого входного порта
регистра
к его “настоящему” порту выхода присвоим вес
.
- Всякому ребру, проведенному от некоторого “настоящего” входного порта регистра
к его мнимому порту выхода out® присвоим вес
.
- Всякому ребру, проведенному от мнимого спутника
к самому порту
, присвоим вес 0.
Читателю предоставляется возможность самостоятельно проверить, что приведенный список инструкций позволяет присвоить веса всем ребрам графа
Среди всех вершин
Связь определенного выше взвешенного графа
Теорема о критическом пути:
Пусть
!) Величина (формального) запаздывания любого порта
!!) Латентность схемы
Доказательство этой теоремы почти дословно повторяет рассуждения предыдущего подраздела.
Доказательство !).
Сначала нужно убедится, что !) справедливо для всех портов фронта
В каждый внешний порт выхода p ведет только одно ребро длины 0, началом которому служит мнимый спутник
В вершину, являющуюся портом выхода некоторого регистра
В вершину, являющуюся портом выхода некоторого блока-константы
По определению формальное запаздывание всякого входного порта
Если
И так, на все входные порты фронта
Такое может быть, только если
Пусть
Каждое ребро, которое ведет в выходной порт
Пусть
Дополним путь
Доказательство !) будет полностью завершено, если мы покажем, что ни один путь, соединяющий множество начальных портов
Предположим обратное: пусть
Полученное противоречие и тот факт, что в правильно составленной логической схеме без циклов функционального влияния каждый порт принадлежит какому-либо фронту распространения данных, полностью доказывают !).
Доказательство !!)
По определению латентность логической схемы с задержками равна максимуму среди запаздываний ее внешних портов входа и запаздываний входных портов каждого регистра R, увеличенных на
Не самая сложная задача. Пусть
Глубина схемы
Алгоритм, приведенный в предыдущем разделе, позволяет вычислить латентность схемы имея под рукою хотя бы карандаш и лист бумаги. Но в действительности, сравнить латентность двух схем “по порядку величины” можно чуть ли ни на глаз.
Ранее мы определили отношение непосредственного функционального влияния для портов логической схемы, теперь мы сделаем то же самое для целых ее блоков:
Функциональный блок
На некоторый блоки схемы непосредственно функционально могут влиять, вообще говоря, сразу несколько других ее блоков, при этом некоторые функциональные блоки могут влиять, вообще говоря, на несколько блоков сразу. Если в схеме нет циклов функционального влияния, то ни один блок не может непосредственно функционально влиять сам на себя.
Пусть
Выделим все цепочки функционально-зависимых блоков, у которых первый по порядку блок имеет по крайней мере один входной порт, соединенный общей шиной либо с внешним выходным портом, либо с выходным портом какого-нибудь регистра, либо с выходным портом какого-либо блока константы, а последний по порядку блок имеет по крайней мере один выходной порт, соединенный общей шиной либо с внешним входным портом, либо с одним из входных портов какого-нибудь регистра.
Среди выделенных цепочек найдем ту, в которых число
Теорема о сравнении латентности двух схем:
Пусть каждому блоку константе и каждому блоку прямого соответствия приписана нулевая задержка. Величинам задержки
Далее, пусть
Доказательство теоремы.
Латентность
Пусть
Путь
Заканчивается путь
Мысленно пройдемся по пути
Ребро
Ребро
Ребро
Блок
…
Продолжая следовать вдоль π до тех пор, пока не достигнем последнего ребра, мы обнаружим, что набираемая последовательность
Почти дословно повторяя приведенные рассуждения можно показать (сделайте это), что
Комментарии (35)

Khort
19.05.2022 08:43+1Я так понимаю, представленный материал есть не что иное как глубинная основа STA - static timing analysis. Проблема в том, что даже для основ изложено слишком математизированно. Конечно, если абстрагироваться от физики проводников и полупроводников, то выглядит вполне. Но вот если рассматривать вопрос более практично, то у DAG (directed acyclic graph или по русски направленный ацикличный орграф) появляются дополнительные ребра в виде setup/hold/recovery/removal check, прохождение по графу учитывает полярность сигнала и возможность его инверсии при прохождении вершин .. и т.д. - куча усложнений, притягивающих всю изложенную математику к практике. Материала на русском по этой тематике действительно мало. Лет 10 назад было много научных публикаций и даже диссеры в Зеленограде ... но до написания софта так дело и не дошло. Я в свое время учил это все (практическую часть STA, т.к. нужно было для работы) по скачанным лекциям MIT. И даже сделал небольшой пост здесь https://habr.com/ru/post/273849/ Собственно, именно по прикладной STA очень и очень не хватает публикаций, а в идеале учебника на русском. На уровне лекций MIT и даже глубже - языком математики, как вы и запостили. Для будущих инженеров, если страна все же сможет выбраться из под санкций.

Sergey_Kovalenko Автор
19.05.2022 08:51Я в физике слабоват, больше по алгоритмам работать как-то приходилось. Но если есть вербализованная потребность, давайте ее здесь продвинем и порекламируем - наверняка какой-нибудь поверхностный читатель моих статей окажется специалистом в озвученной Вами теме, который потом сможет и захочет о ней написать.
Khort
19.05.2022 10:35+2Ок, тогда наверное мне нужно уточнить. Поясню, что я имел ввиду под "физикой". Задержки ребер графа (банально RC проводов). Зависимость задержки вершин графа (элементов) от полярности сигнала: рассматриваем мы передний или задний фронт. Тип вершины (выхода элемента): инвертирующий или нет. Вот и все. Хотя это малое может сильно повлиять на выводы в ваше публикации. К примеру, кратчайший путь - вовсе не тот где меньше вершин в графе, а тот, где суммарные задержки (с учетом задержек ребер, полярностей сигнала на отрезках, и т.д.) меньше.
Ну и надо пояснить про дополнительные ребра графа, которые я выше обозвал как [setup/hold/recovery/removal check]. По русски их можно назвать контрольными ребрами, поскольку на них фактически сравниваются задержки прохождения графа разными путями (я об этом подробно писал по ссылке выше).Sergey_Kovalenko Автор
19.05.2022 11:01Хотя это малое может сильно повлиять на выводы в ваше публикации. К примеру, кратчайший путь - вовсе не тот где меньше вершин в графе, а тот, где суммарные задержки (с учетом задержек ребер, полярностей сигнала на отрезках, и т.д.) меньше
Подождите, но у меня кратчайший примерно так и считается: по сумме задержек, а не числу вершин. Я конечно не учитываю, что в разных ситуациях и на разных парах вход-выход одного и того же блока могут быть разные задержки отклика на изменения, но в целом - в статье именно тот подход, который Вы считаете правильным.
Khort
19.05.2022 11:25+2Хорошо. Значит не совсем верно понял, мои извинения.
Еще одно замечание. Важно считать не только кратчайший путь, но и самый длинный. Поскольку оценка всегда делается для обоих граней "окна" переходных процессов - верхней и нижней. Зачем - это уже надо вводить такие понятия как Setup, Hold, и метастабильность. И контрольные ребра графа, о которых я писал выше.Иии.. и еще одно совсем маленькое замечание. Дело в том, что в индустрии последние лет 10 используют статистические величины задержек. В простейшем случае для модели задержки используется распределение Гаусса - т.е. mean и sigma (для расчетов обычно используют 3 сигма), в некоторых случаях это распределение складывается из двух разных "половинок колокола" (почему - можно написать много текста), в еще более продвинутом случае ось колокола имеет наклон (тут скрыто еще больше текста). Соответственно все формулы расчета задержек превращаются в статистические, обычный "+" уже не работает. Надеюсь, кто нибудь когда нибудь запилит об этом пост .. для будущих инженеров. Что до вашей книги - наверное об этом стоит просто упомянуть вскользь.
Sergey_Kovalenko Автор
19.05.2022 11:55Теперь мои извинения: я проглядел слово "кратчайший". Я рассматривал именно самые длинный. А кратчайшие - это зачем? Чтобы регистры успевали правильно скопировать следующее значение что ли?
Khort
19.05.2022 11:58Повторюсь:
Поскольку оценка всегда делается для обоих граней "окна" переходных процессов - верхней и нижней. Зачем - это уже надо вводить такие понятия как Setup, Hold, и метастабильность. И контрольные ребра графа, о которых я писал выше.Sergey_Kovalenko Автор
19.05.2022 22:20О, это сильно выше моих познаний и лежит явно за пределом формализма схем из логических блоков.
Khort
20.05.2022 07:10Дело в том, что без этого никак. Задержки в одной лишь комбинационной логике интересны, но не практичны. На практике орграф потому и ацикличен, что один конец отрезка всегда входной клоковый порт схемы, а вторая точка всегда место разыва - пин данных триггерного элемента, у которого внутрення арка ( вершина графа) от пина данных рвется, и на графе заменяется контрольным ребром между этим пином данных и пином клока. Таким образом мы получаем два пути, которые можно сравнить по величине задержек - от клокового порта до пина данных триггера, и от клокового порта до пина клока этого триггера. А дальше эти два пути просто анализируются на предмет нижней и верхней грани разброса задержек (поиск максимума и минимума). Полученный результат сравнивается с контрольным ребром, который суть - характеристика триггера в виде допуска по этой верхней и нижней грани. Если результат удовлетворяет - схема работоспособна. В этом суть статического временного анализа, на пальцах. Как вы понимаете, на фоне изложенного, ваши выкладки выглядят очень не полно. Об этом я и писал
Sergey_Kovalenko Автор
20.05.2022 09:42Да, я примерно понимаю о чем вы говорите, но в свой книге хотел бы оградить читетеля от этих подробностей. Я исхожу из следующих предположений, поправьте меня, если ни не верны.
1)Без потери общности можно считать, что время удержания регистра больше его времени предустановки.
2)Удлиняя или укорачивая провода-ребра клокового дерева (шины по которым распостраняется клоковый сигнал) в принципе можно добится, чтобы ко всем регисрам фронт клокового сигнала пришел чуть ли не одновременно. Это не всегда обязательно и порю нет никакой необходимости заставлят все регистры особенно большой схемы срабатывать одновременно, но в принципе добиться можно.
3) Из 1 и 2 следует, что если перед приходом фронта тактового сигнала на регистры значения в шинах схемы, отличных от шин клока, уже стабилизировались, то смена значений регистров произойдет правильно (их остальные порты точно сохранят стабильные значения на протяжении времени удержания плюс времени задержки по пути до ближайшего выходного порта другого регистра).
4) из 1), 2), 3) следует, что (если схема маленькая и временем задерки в проводах можно пренебречь) длина такта может быть выбрана меньше чем длина критического пути, посчитанной по методике этой статьи, геде термином задерка стабилизации данных - назвоно время удержания, а термином задерка стабилизации значений регистра - время его предустановки.
Все требования пунктов 1)-4) не являются необходимыми, утверждается лишь их достаточность. Да если все пути от регистра к регистру в схеме долгие (большая задержка), то не обязательно требовать от регистра вообще хоть какого-то времени удержания. Можно еще в паре мест "подрезать" площадь и время минимального такта. Но это уже улучшения. Если кто-то принес схему, методикой этой статьи критический путь в которой оценивается как T, то профессионал схемотехник (или программа САПР) должны уметь заставить работоат эту схему на частоте не меньшей 1/T.Khort
20.05.2022 10:26+1Ответ -наверное да, можно так считать, хотя в общем случае это вовсе не обязательно. Суть в другом - анализ на установку и анализ на удержание - разные, не зависимые и не связанные между собой задачи. Но для каждого из этих анализов производится расчет верхней и нижней границы задержек, просто для анализа по установке: путь данных должен быть Макс, и путь клока Мин. А для анализа удержания - путь данных Мин, а путь клока -Макс.
К этому стремятся, но вы помните про вероятностные величины задержек? В реальности вы никогда не получите одновременного прихода клоков, вероятность этого около нулевая. И на практике расхождение прихода клока на разные триггеры может достигать даже величины в несколько периодов.
Но в целом соглашусь с вами - для фундаментальной публикации по математике, алгоритмы вычисления минимальной и максимальной задержки - минимальный и достаточный инструментарий. А как его использовать - уже вопрос практики. Точнее, можно добавить сюда всю ту физику, которая используется в реальных программах STA, и получится тоже очень даже фундаментальная публикация. Только, это уже будет иметь отношение не столько к математике, сколько к физике, алгоритмам, и численным методам. Я не уверен, что такой труд есть даже на английском. Только отдельные научные публикации, и все. Это та область знаний, на которой зарабатывают огромные деньги, к примеру одна лицензия синтезатора схем из их описания (Design Compiler) стоит $50к в год. Синтезатор работает, как не трудно догадаться, не просто как синтезатор и оптимизатор булевых функций (задача в общем то простая), а с упором на статический временной анализ во время синтеза. Алгоритмы работы подобных инструментов - охраняемая коммерческая тайна. Я так понимаю, в Зеленограде пытались что то свое создать, судя по публикациям. Но чем закончилось, не известно
Sergey_Kovalenko Автор
19.05.2022 12:23Перерисовал картинки в предыдущей статье, теперь не "вырви глаз". Заодно нашел несколько ошибок по невнимательности. Настоящую статью перечитаю и "причешу" через пару дней, когда мозг немного забудет ее текст.

karambaso
19.05.2022 13:45Математические тексты часто строятся с учётом облегчения поиска информации. Выглядит это так:
Моменты, к которым читатель может захотеть вернуться каким-либо способом выделяются.
Моменты, которые некритичны при повторном обращении к работе, так же выделяются с целью не отвлекать внимание читателя на выискивание точек их начала и окончания.
Обычно схема такая:
Определение:
Текст определения.
Теорема/Лемма:
Определение.
Доказательство:
Текст доказательства.
Конец доказательства.
--------
Обычно стимулом для переработки в таком стиле служил либо внутренний максимализм автора, либо строгий цензор/редактор. Если стимула нет, результат будет проще для автора, но хуже для читателя.
Так же было бы уместно указывать цель той или иной леммы/теоремы. Например - теорема о ХХХ нам понадобится для перехода от состояния, когда вы знаете УУУ к состоянию, когда мы сможем применить УУУ к задаче ZZZ доказательно, то есть полностью доказав путь от аксиом до решения ZZZ. Здесь про путь от аксиом можно сказать один раз, а вот применимость теорем стоит показывать каждый раз, иначе текст выглядит неравномерно, где-то на много абзацев описание аналогий с каналами, а где-то сухой текст теоремы и доказательства, без малейших дополнений.
Sergey_Kovalenko Автор
19.05.2022 13:59Да, я стараюсь примерно так и писать, но в первой редакции текста внимание слишком сильно сконцентрировано на логической структуре его содержания. Трудно на этом этапе хорошо позаботится о мета уровне (как это содержание воспринимается читателем). Возможно, мне стоит выкладывать статьи не сразу по готовности, а с некоторой задержкой, чтобы текс успел для меня забыться и сам смог взглянуть на него глазами читателя.
karambaso
19.05.2022 14:33сам смог взглянуть на него глазами читателя
Это можно, но разбиение на части с их выделением, это ведь просто алгоритм, про который очень наглядно видно - выполнен или не выполнен. То же и про пояснения, просто подчасть со своим алгоритмом.
Есть смысл потратить время на отработку такого алгоритма. Это одноразовое долговременное вложение, которое будет окупаться постоянно во всех статьях в будущем.

Tzimie
19.05.2022 21:51Меня всегда интересовало, а какая глубина схемы суммирования, скажем, 32 битных целых? Ведь там переносы разряда, и она будет не менее 32, что очень много? Или есть какие то трюки?
Sergey_Kovalenko Автор
19.05.2022 22:17Как я рад новым комментариям! С удовольствием отвечу на ваш вопрос.
Существует хитрый способ, и я его очень подробно разберу в следующей или послеследующей статье, который для любого k позволяет построить схему сложения двух произвольных k-битных чисел с глубиной O(log k) и при этом задействует O(k) элементарных блоков. Схема называется префиксным сумматором. Он асимптотически самый быстрый из известных.

Myclass
21.05.2022 00:32Не хочу вас обидеть, но моё мнение - вы перемешали всё в кучу. Такие вещи объясняются от простого к сложному. От логических вентелей, потом триггеров (flip flop), потом сумматоров, мульти- и демультиплекторов. Когда-то ALU. И его тоже - вначале на 2 битах, потом 4, 8. С 8-ми бытовом можно уже ALU с памятью соеденить, показать, как возникают инструкции (ISA) итд. Никому никогда в голову не придёт 'путать' выходной порт вентиля с выходом на монитор. Хотя разницы в них в принципе и нет.
Ида, я прочитал и вашу предыдущую статью. Простите меня, но так ни один айтишник, электротехник или ещё кто не выражается, как вы пишите там Вот ваши слова.
"О том единственном выходном порте, к которому присоединена шина, мы будем иногда говорить, что он является ее «началом» или, что он «стоит в ее начале». Обо всех соединенных с шиной входных портах мы будем говорить, как о «концах» этой шины. Из аксиом B2 и B3 следует, что у каждой шины есть по крайней мере один «конец» и в точности одно «начало»."
У шин нет ни начала ни конца. Если есть начало и конец, то это не шина, а интерфейс/соединение или что-то в этом роде. Брать в кавычки что-либо при описании таких тем, как эта - это просто уходить в дебри ненужных абстракций.
А вот эти ваши слова..
"..шинам будут соответствовать металлические проводящие дорожки." или там "..блочки, покрывающая плату затейливым узором." - это для детей книга? Тогда они всё остальное не поймут.И потом. Есть ГОСТ для описания логических вентилей. Вы-же изобритаете велосипед и этим усложняете то, что просто и понятно.Никто никогда раньше не перепутал у них, где вход, а где выход. Поэтому дополнительные рюшечки не нужны. Я представил, что в книге, где будут учить основам музыки будет использоваться не нотная грамота, а своя, никем невиданная. И у нот специальными полукругами будет указано, где у нот низ а где верх...ну для лучшего понимания...
Запаздывания отдельно взятых вентилей для разработчиков новых микропроцессоров может быть и интересны, но в современных схемах для общего ознакомления наличие такта объясняет всю суть работы и синхронизации всех составляющих. Запаздывания нужны инженерам, но которые не блочками разговаривают. И т.к вы используете свою схемо-рисовалку, то не думаю, что эта литература для будущих спецов Intel, AMD или на худой конец Байкала.
В математическую составляющую я так и не смог вникнуть, очень уж заумно. Аксиомы, доказательства в описание цифровых схем - это вообще считаю - перебор.
Теории придумывать не есть плохо. Но тут такое, что не понимаешь- для чего и кого всё это? Навыдуманно куча новых слов, уже всем понятные слова используются для обозначения новых интерпритаций и берутся в кавычки, итд. Вроде в комментариях к первой статье вы указывали,, что ваша книга для инженеров, чтобы они прокачали свою математическую базу, но забываете или игнорируете, что эта база уже существует и называется бинарная алгебра и все те элементы, которые уже напридуманы. Другой для описания или для выдумывания новых компонентов не надо.
Почитайте и посмотрите у VHDL или VERILOG. Там всё, что надо для современного инженера.
Sergey_Kovalenko Автор
21.05.2022 03:02Спасибо ра развернутый отзыв. Я всегда рад мнению профи.
От адекватных мнений мой дофамин не страдает, все в порядке, останется желание читать и писать ваше мнение - буду только благодарен.
Да, с математикой "немного" переборщил для формата популярных статей.
Да, есть некоторые проблемы с неудобгостью традиционой и пока что сыростью моей собственной терминологии. Со временем и в следующей редакции, наверное, с этми наладться.
Да, я собираюсь несколько изменить стиль изложения, разделив материал на популярный и "дополнения" с серьезной математикой.
Но,
Некоторые результаты я не смогу коротко и удобно сформулировать и тем более строго доказать в инженерной терминологии.
Например, мне не известно, где бы я смог увидеть теорему о связи глубины схемы и предельной тактовой частоты сигнала в той строгой и формулировке, в которой вы ее видили здесь. С другой стороны, я смежник, в теме недавно, есл вы накидаете ссылок - отдельное спасибо.
Понятие глуины должно входить в любой даже начальный курс дизайна логических схем на одном уровне с понятием такта. Писать схему на HDL, не понямая глубины - так можно и на 100 МГерц скатиться.
В следующей лекции я собираюсь доказать очень сильное утверждение: любая логическая схема глубины h некоторым алгоритмическим способом может быть превращена в конвейризованную схему глубины 1 с той же логикй работы и запаздыванием между данными на входе и выходе не больше O(h) тактов (данные скармливать можно каждый такт). Если k - число элементов в исходной схеме, то при достаточно реалистичных предположениях конвейризация потребует не больше 3k регистров задержки.
Насколько известен в профессиональной среде такой результат, можно ли какие-нибудь ссылки на литературу.
Лично мне в терминах условного "Харрис&Харрис" доказать его было бы необычайно тяжело.
Насчет Интела, Арм и прочих - а еси я вдруг что-то интересное опубликую и переступив через презрение к хабраюзеро эту писанину в Хуавей прочтут и применят. Думаю директор по развитию в Арм и Интел могут поменяться. Сценарий маловероятный, но и директора по развитию на дороге не валяются - думаю, какого-нибудь студента спровадят на посмотреть))).
О портрете пердполагаемого читателя будущей книги - здесь все куда сложнее. Мне бы очень хотелось, чтобы книга была понятна работающим инженерам, исследователям в области computer science и широкоу кругу абстрактных математиков. Как всем угодить - большой вопрос.Myclass
21.05.2022 10:32Ну с целью книги и читательской публикой надо определиться. Или книга - ради книги тогда не важно как и что. Если-же цель - какие-то конкретные люди - дети/начинающие/студенты/продвинутые/эксперты, то и языкобьяснения и глубина технической и математической составляющих должен быть подходящий. Это первое.
Теперь про связь глубины схемы и частоты такта. А с чего вы им исходите, что они взаимосвязаны? Ведь частота определяет общую скорость. Отдельные команды же для процессора требуют для их исполнения разное количество тактов. К чему это я? Да к тому, что если какой-то блок для инструкции будет реализован так, что потребуется глубина - не понял ваших понятий - скажу с потолка-100. То и количество тактов для её исполнения будет намного больше, чем например для суммирования двух целых чисел. Но если эта инструкция нужна, то все будут довольны. И будущие инженеры будут работать над тем, как это упростить и уменьшить количество требуемых тактов.
Принципиальное. Если для нового микропроцессора понадобится новая инструкция/команда, то всегда есть два пути для её реализации - эмулировать с помощью примитивных команд или строить для неё блок на логических вентилях. И то и другое сопоставить между собой - важная задача. Для этого есть много критериев - как часто будет использоваться, сложность в форме лог. вентилей их теплоотделение, величина итд.
Не совсем в курсе, сколько конкретно, но много инструкций у процессоров исполнены по принципу - снаружи CISC, внутри RISC, то есть очень многие из них компилируются на ходу и исполняются как куча примитивных. Это удобно, не требуется эл.схемы и можно даже годами позже перезалить, если в них где закралась ошибка, можно скалировать на отдельные ядра итд.
Поэтому ваши доказательную связь глубины схем с задержкой или с тактом - извините, не понял. Но желаю вам творческого успеха.
Sergey_Kovalenko Автор
21.05.2022 11:07Как делать микропроцессоры - это очень хорошо изученная прблема - там трудно что-то новое предложить. Сейчас время, когда появляется много специализированных схем, каждая из которых призвана решать узкий круг задач, но делает это очень хорошо. Видеокарты, матричные умножители, схемы для поточной обработки данных. Я видел реализации матричных умножителей от Гугл и Интел - без слез не взглянешь. Даже я могу лучше. Схему для АФАР, говорят, сложно сделать. TSMC вроде как для всех доступна, но не у всех получается алгоритмы быстро реализовать. Тут статья на хабре была интересная у @NVaLEX : https://habr.com/ru/users/NVaLEX/posts/ .
В общем, не все так просто.
За ваше внимание и слова поддержки я вам искренне благодарен.
Замечания попытаюсь учесть в будущих статьях, может к 5-6 все устаканится.Myclass
21.05.2022 11:19Спасибо, хорошая статья но и там стоит подтверждение моих слов...
Одной из причин, по которой не удалось реализовать открытую и совместную экосистему SoC, является высокая стоимость аппаратных сбоев. Аппаратная ошибка, обнаруженная в изготовленном оборудовании, может обойтись коммерческим компаниям в миллионы или миллиарды долларов в виде отзывов и потерянного дохода. Это отличается от индустрии программного обеспечения, где ошибка часто может быть исправлена на месте с помощью недорогого обновления программного обеспечения.
Практическое дело - это всегда не идеальный путь, а постоянный поиск компромиссов.
Sergey_Kovalenko Автор
21.05.2022 11:34Вцелом трудно с вами не согласиться, но компроми и упущение - это все разные щещи. Плохо скроенное платье из золотой ткани - так себе компромис.
Myclass
21.05.2022 11:46Как делать микропроцессоры - это очень хорошо изученная прблема - там трудно что-то новое прпредложить.
ну , не скажите - посмотрите на новые модели, например у того-же Apple - M1 Pro. Так там много чего нового инженеры напридумывали или наоптимировали.
Sergey_Kovalenko Автор
21.05.2022 11:57Я очень сильно подозреваю, что вам виднее))). Мое дело - более универсальные задачи, которые можно применить и там - и тут, и впроцессорах - и не только. Кончно на острие любой высокой технологии есть свои открытия и новшества. Моя цель - скорее не острие, а тупой и грузный кирпичь ближе к основанию.
Sergey_Kovalenko Автор
21.05.2022 10:24Про конвейризацию можно здесь посмотреть: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.134.9731&rep=rep1&type=pdf
Результат почти очевидный наверное для всякого математика, кто когда-нибудь работал с алгоритмами на графа. Я попытаюсь сделать текст доказательсва по возможности простым и самодостаточным, покажу, что утверждение теоремы можно распространить на любую схему (не только комбинационную), для чего потребуется не более чем h раз дублировать каждый регистр начальной схемы.
Имея такую теорему, дальше в своем повествовании я могу разбирать только однотактные неконвейризованные схемы - конвейризация и ее оптимальный способ будут гарантироваться теоремой. Однако эти результаты сложно рассказать не на языке теории графов.Myclass
21.05.2022 11:13А вас не смущает, что в работе ссылаются на свои и другие, которые из 80- и 90--х годов прошлого века?
Sergey_Kovalenko Автор
21.05.2022 11:23Почему должно смущать? Некоторые результаты получены давно и имеют вердикт: "дальше некуда" - от этого они не становятся менее полезными.
Yak52
При создании схем и диаграмм лучше придерживаться правила (что даже было раньше в ГОСТах): слева вход элемента, а справа – выход. Тогда не надо напрягаться, чтобы понять схему.
Sergey_Kovalenko Автор
Да, я слышал о таком правиле. Очень неудобное правило для тех, кто пытается объяснить работу арифметических блоков (разряды числа расположены так, что слева - старшие, а справа младшие, действия начинаются обычно с младших) и запоминающих устройств для двоичных слов, переданных как последовательность бит (первый символ для человека из Eвропы - самый левый, когда я попытаюсь "положить" первый символ переданной последовательности в стек, мне будет удобнее это сделать из потока направленного справа на лево). Так что, при всем моем уважении к традициям - лично мне в этой книге почти всегда будет удобно потоки пускать справа на лево.
fougasse
Тем не менее, в литературе, все-таки следуют «слева-направо» и никаких проблем с арифметикой не имеют.
Sergey_Kovalenko Автор
В другой литературе фокус сделан на другом, там для читателя удобно, чтобы мячик на киноэкране экране и потоки данных на схеме катились слева на право, но опять же, не для жителей Азии, например.
Myclass
Ну вы-же не только для жителей Азии книгу пишите. И уверен, что для глобального понимания схем они используют общие стандарты. С вашими примерами можно и иероглифы использовать или шумерские палочки итд. Но тогда, это усложняет понимание. Знаете - как в анекдоте - корм должен рыбе вкусный быть, а не рыбаку.
Sergey_Kovalenko Автор
Ну вот, еще один горячий спор о правостороннем и левостороннем движении. Давайте оставим пока дискуссию открытой.
Наверное, если бы я лет 20 видел только один вариант, то от инверсии потоков меня бы тоже коробило. Тем не менее для повествования удобно, чтобы потоки в каждой схеме шли так, как сподручней именно для этой схемы. Для большинства схем сподручнее с права налево (иначе последовательности приходится с конца нумеровать и арифметика вся шиворот-навыворот получается), но бывает и наоборот. Есть и такие схемы, естественное изображение которых требует направление потоков в противоположных направлениях (адресное дерево записи и чтения, например). Обещаю пока только, что внутри одной схемы будет поддерживаться однообразие и некоторая логика.
Myclass
Знаете, это ненужные никому настаивания на чем-то, что мы считаем удобным. Вы можете и структуру данных "дерево" тоже под вопрос поставить, ведь настоящие деревья ведь не корнем кверху растут. Но так вышло. И никому не мешает. Ну ладно, останемся так.