
Перед вами четвертая статья-черновик будущей книги «Алгоритмы на кристалле».
В действительности по своему содержанию и стилю изложения ей следовало бы быть первой статьей, не считая оглавление книги и небольшой вводной части. Однако придумать сразу простой подход к изложению удается не всегда. По этой причине лежащий перед вами текст является во много самостоятельным, его можно читать почти независимо от предыдущих двух статей, обращаясь к ним только как к справочнику. Буду благодарен за любого рода отзывы, как со стороны новичков в этой области так и тех, кто работает в ней давно — обратная связь поможет сделать финальную редакцию книги лучше.
Предыдущие черновики:
… Примерное оглавление.
… Вычислительная модель.
… Быстродействие логических схем.
Возможно, в вашем браузере с первого раза не будут правильно отображаться формулы. Если так, попробуйте перезагрузит страницу — на моем компьютере этот фокус работает.
Желаю приятного чтения.
Простой способ представить себе работу элементарной логической схемы
Логическая схема и ее компоненты
Логические схемы состоят всего из трех типов компонент: портов (входных и выходных), шин и логических блоков (функциональных и регистров). При графическом изображении логическим блокам соответствуют скругленные прямоугольники, портам — маленькие полукруги, а шинам — тонике, иногда разветвленные линии. Границы самой схемы обозначены прямоугольной рамкой.

(Схема "=" )
Логическая схема способны производить вычисления, при этом они оперирует двоичными словами: “данными”. Выходные порты (заполненные полукруги) нужны, чтобы отправлять данные, входные порты (белые полукруги) — чтобы их принимать, шины — чтобы передавать данные от выходных портов к входным. Функциональные логические блоки нужны, чтобы данные неким образом преобразовывать, а блоки-регистры — чтобы их временно запоминать.
Пути распространения данных в схеме неизменны: порты статично прикреплены к логическим блокам (внутренние порты) или внешней рамке (внешние порты), шины статично прикреплены к портам. Каждая шина и каждый порт способны работать с двоичными словами строго определённой длины, которая называется их размерностью. Размерности шины и всех прикрепленных к ней портов должны поэтому совпадать. Чтобы избежать неоднозначности в пересылаемых данных, к каждой шине разрешено прикреплять в точности один выходной порт. Места разветвления шин изображаются жирными точками, там, где точек нет — шины всего лишь пересекаются, не оказывая влияния на работу друг друга.
Такт, как эпоха
Процесс вычислений, производимых схемой, состоит из последовательности тактов. Неформально каждый такт удобно представлять себе как продолжительную временную эпоху. Логические схемы проектируются таким образом, чтобы в продолжение каждой эпохи каждый выходной порт смог отправить в прикрепленную к нему шину ровно одно двоичное слово, а каждый входной порт — ровно одно двоичное слово из прикрепленной к нему шины смог принять. Слово, которое на данном такте выходной порт отправит в шину, входной порт примет из шины, а сама шина передаст — будем также называть соответственно значением выходного порта, значением входного порта и значением шины в данный такт времени.
Процесс вычислений в схеме без регистров
По определению значение, которые функциональный блок на данном такте выставит на том или ином своем порту выхода, полностью определяется именем порта выхода, типом блока и значениями, которые на этом такте примут его входные порты. Например, функциональные блоки элементарного типа “+” реализуют сложение двух однобитных чисел: порту "

(рисунок однобитного +)
И так, пусть все логические блоки в схеме являются функциональными. Опишем работу такой схемы в один из тактов.
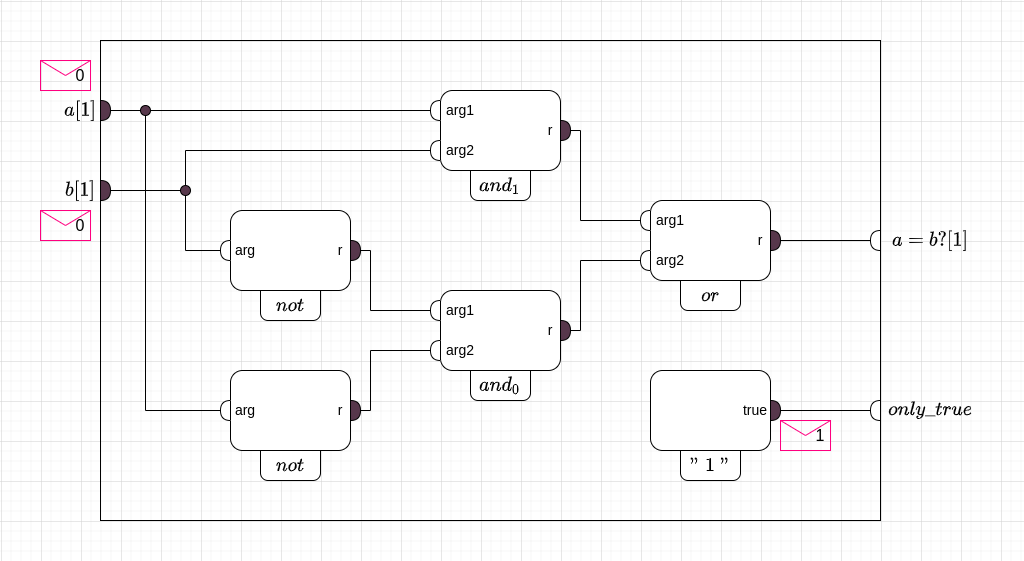
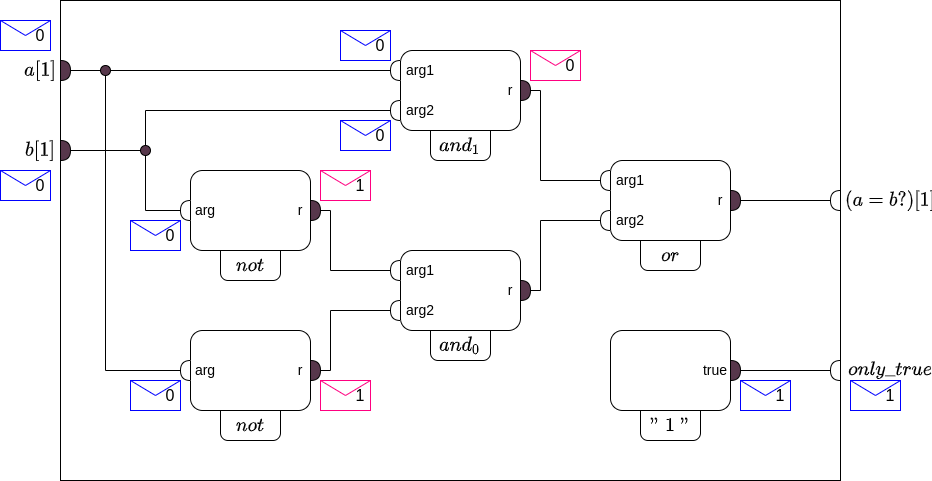
(Cхема равенства с аппендиксом из константы в продолжение одного такта. Начало).
О работе любой схемы мы будем предполагать, что в начале каждого такта значения ее внешних портов уже известны и остаются неизменными до начала следующего такта. Разумеется, известны и также останутся неизменными значения выходных портов всех блоков-констант. Если значение некоторого порта выхода когда-либо стало нам известным, мысленно представим, что затем это значение напечатано на воображаемых конвертах и разослано вдоль прикрепленной к этому порту шине ко всем портам входа, с которыми эта шина соединена.

(Продолжение: рассылка конвертов 1 этап).
Как только каждый входной порт некоторого функционального блока на текущем такте получит свой конверт, мы можем вычислить значения всех выходных портов уже у самого этого блока и тем самым продолжить рассылку конвертов.

(Продолжение: рассылка конвертов 2 этап).
Если в логической схеме нельзя совершить круг, переходя от одного функционального блока к другому функциональному блоку так, чтобы всякий раз при этом один из портов входа второго блока был бы соединен с одним из портов выхода первого, то такая схема называется функционально ациклической (есть в ней регистры, или нет — не важно). Из результатов статьи “Вычислительная модель” следует, что в функционально ациклических схемах (только такие мы и будем рассматриваться в оставшейся части книги) описанный выше процесс рассылки конвертов обязательно приведет к тому, что в итоге каждый входной порт схемы ровно один раз получит свой конверт, а для каждого внутреннего выходного порта, логический блок к которому тот прикреплен, ровно один раз вычислит его значение. Как только это произойдет, очередной такт можно считать завершенным.

(Рассылка конвертов. Конец: все порты получили значения).
Особенности поведения регистров
Элементарные регистры способны хранить в себе однобитные слова — значения регистра. Значения регистров меняются только при смене тактов. Слово, которое появится на единственном выходном порте "
Для регистра с одним единственным входным портом "
Чтобы значение регистра можно было сохранять несколько тактов подряд, в некоторые типы регистров добавлен порт "
Значение любого элементарного регистра в нулевой такт случайно.

(рисунок, поясняющий работу регистров)
Спецификация всех регистров, принятых в этой книге за элементарные, описаны в аксиомах E8-E11 статьи “Вычислительная модель”.
Смена тактов в элементарной схеме
Если в схеме есть регистры, то в начале каждого такта в качестве еще одного первоисточника данных к уже упоминавшимся внешним выходным портам и выходным портам блоков-констант добавляются выходные порты регистров. В остальном процесс вычислений, происходящий на схеме в течение такта почти такой же, что и описанный выше процесс вычислений на схеме без регистров. Единственным отличие будет то, что каждый раз между концом текущего такта и началом следующего все регистры определяют свое новое значение. Ниже приведен пример работы за несколько последовательных тактов простенькой схемы с регистром “пульсар”.



(рисунок, поясняющий работу пульсара в продолжение одного такта)
Замечание по поводу именования портов
Все внешние порты схемы наделяются собственными именами и никакой путаницы в их назывании не будет. В то же время мы неоднократно будем встречать схемы, в которых присутствуют сразу несколько блоков одного и того типа и у каждого из этих блоков есть порт с одним и тем же именем “
На этом наше короткое знакомство с основами теории логических схем закончено. Его объема, в принципе, должно быть достаточно для понимания всего излагаемого ниже материала. Более подробное и формализованное изложение общей теории читатель найдет в двух предыдущих статьях. По мере углубления в предмет их содержание станет полезным. Сейчас мы переходим к конкретным почти промышленным схемам.
Схема каскадного компаратора
Определение старшинства между двоичными словами
Для сравнения двоичных слов мы будем использовать лексикографический порядок. В лексикографическом порядке расставлены слова в словарях и справочниках. Применительно к двоичным словам он определяется следующим образом:
Пусть даны два m-битных слова:
Какое-то число начальных членов этих слов могут быть одинаковыми, то есть:
В следующем пераграфе мы докажем, что если каждое из слов
Абстрактное описание алгоритма сравнения
Само определение лексикографического порядка содержит в себе алгоритм его вычисления. Действительно, все что мы должны делать — это синхронно перебирать последовательности символов обоих слов до тех пор, пока не обнаружим позицию
В пошаговом виде, описанный алгоритм выглядит так:
- Ввести два булевых слова-состояния: первое — “просмотрев символы слов до позиции 0 включительно, установлено, что
” или коротко —
, и второе: “просмотрев символы слов до позиции 0 включительно, установлено, что
”, коротко —
. Обоим словам-состояниям присвоить значение “ложь”, перейти к 2)
- Проверить одинаковы ли символы
и
. Если они различны и
“0”- присвоить значение истина состоянию
, если они различны и
“0” — присвоить значение истина состоянию
. Перейти к циклическому повторению 3)-5)
- Если рассматриваемая позиция
в словах
и
— последняя, перейти к 7). Иначе в обоих словах перейти к позиции
, а в алгоритме к шагу 4)
- Ввести слова-состояния: слово
— “просмотрев слова вплоть до позиции
, установлено, что
”, и слово
— “просмотрев слова вплоть до позиции
, установлено, что
”. Обоим только что введенным словам-состояниям присвоить значения «ложь». Если хотя бы одно из слов-состояний предыдущей позиции
или
имеет значение «истина» (уже установлено какое из слов меньше), никаких действий над символами
и
не требуется. Просто копируем
в
,
в
. Снова переходим к 3). Иначе переходим к 5).
- Если мы здесь, значит анализ
ранее просмотренных позиций слов
и
не смог дать ответ, какое из слов меньше. Сравним текущие позиции
и
. Если они различны и
“0”- присвоить значение истина слову-состоянию
, если они различны и
“0” — присвоить значение истина состоянию
. Вернуться к циклическому повторению шага 3).
- Конец алгоритма. Мы просмотрели все m позиций. Логика алгоритма такова, что только одно из слов-состояний:
, или
, может в итоге иметь значение “истина”, тем самым отвечая на вопрос, какое из слов меньше. Если оба этих слова-состояния остались ложными, то слова
и
в точности совпадают.
Интерфейс схемы компаратора
Прежде чем строить схему какого-либо алгоритма, нужно определиться, в каком виде мы собираемся подавать исходные данные, а в каком виде — снимать результат. Компаратор, который мы построим ниже будет способен сравнивать два m-битных слова за один такт. Передаваться эти слова будут в качестве значений внешних выходных

(интерфейс компаратора)
С интерфейсом схемы мы определились, пора теперь разобраться со знаком вопроса.
Операционная ячейка схемы компаратора
Алгоритм сравнения, который был описан выше, так или иначе синхронно просматривает все позиций слов
В своей логической конструкции описанный выше алгоритм сравнения сводится к следующему:
Находясь над позицией
Если одно из этих состояний уже имеет значение “истина”, или же
Если же оба слова
Давайте теперь подробно разберем схемы ячейек-обработчиков.
На рисунке … изображен обработчик пары первых символов слов

(Головная ячейка компаратора)
Плеяда блоков "
После того как порт "
Не трудно проверить, что такой способ придавать значения словам
И так, мы доказали, что приведенная схема обработчика двух самых первых символов слов

(Регулярная ячейка компаратора)
По сравнению с предыдущим рисунком здесь добавилась плеяда блоков в кирпичном прямоугольнике и блок типа “
При обработке всех позиций, кроме первой, для того, чтобы значения слов
- оба слова
и
должны иметь значение “ложь”;
- значения
, и
должны быть разными.
Второе условие, как и на предыдущем рисунке выполняет плеяда блоков с префиксом "
Блок "
Схема целиком
Давайте теперь объединим все наши наработки в одну схему. Чтобы результат занимал не очень много места перерисуем схемы ячеек в более компактное представление и ограничимся сравнением 3-битных слов. Проверьте самостоятельно, что это все те же самые ячейки-обработчики, которые мы рисовали выше.
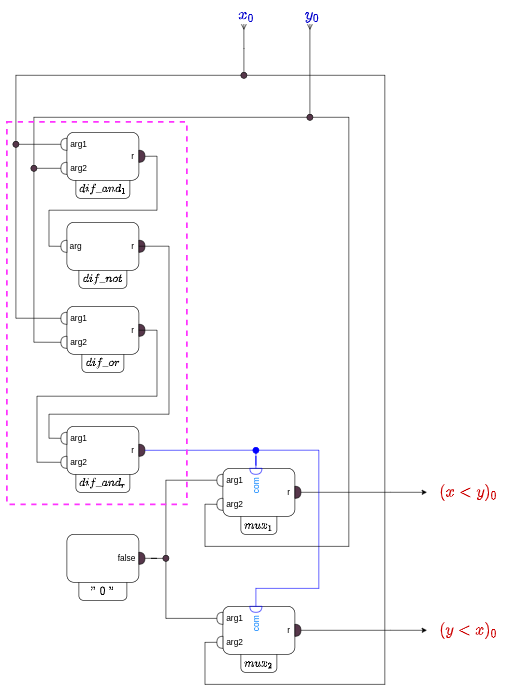
(компактное представление головного обработчика)
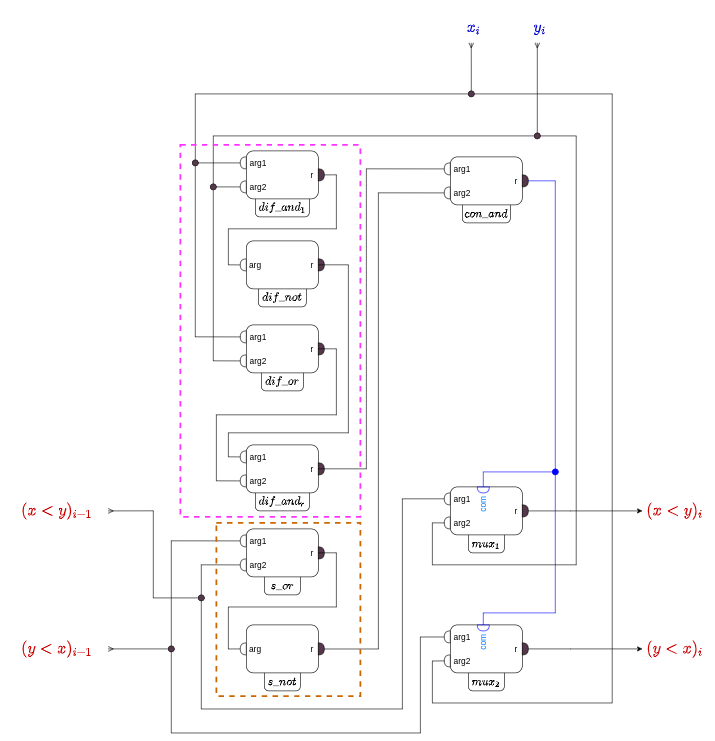
(компактное представление регулярного обработчика)
Остается соединить ячейки между собой и правильно подать на них позиции слов x и y (рис ...). Для разделения 3-битных слов x и y на последовательность их 1-битных символов в схеме используется два блока обратной конкатенации типа "

(схема целиком)
Двоичное представление натуральных чисел
Позиционное исчисление с основанием 2
Всякому двоичному слову
В этой книге при построении логических схем в основном будет использоваться именно двоичная система исчисления, поэтому часто мы не будем различать само число
Пусть
Чуть позже мы покажем, что значение
По поводу двоичного представления чисел естественно возникают два вопроса:
- Всякое ли натуральное число можно представить в двоичном виде?
- Если такое представление у некоторого натурального числа имеется, единственно ли оно?
Ответы на оба этих вопроса многим читателям покажутся очевидными, однако часто наше сознание путает знакомое с понятным. Ниже приведены рассуждения, дающие точный ответ на каждый из вопросов, но для читателя было бы хорошим упражнением попробовать прежде обдумать их самостоятельно.
Существование двоичного представления для любого натурального числа
При помощи математической индукции докажем, что у всякого натурального числа имеется двоично-степенное разложение.
Число 0 представимо так:
Число 1 тоже:
Предположим, что для всех натуральных чисел, меньших
Число n либо четное, либо нечетное.
Если
Если
И так, в обоих случаях индукционный шаг сделан и тем самым представимость всех натуральных в двоичном виде может считаться доказанной.
Разложение степеней двойки. Геометрическая интерпретация
Чтобы решить вопрос единственностью, в алгоритме прибавления/вычитания единицы и еще много где, нам понадобится одно замечательное тождество:
В принципе это тождество можно доказать, используя школьные знания о сумме членов геометрической прогрессии, но есть и более наглядный способ.
Пусть

(Слева от флажка
Если число карандашей в группе слева от флажка больше одного (то есть

(Слева от флажка
Будем перемещать флажок в середину остающегося от него по левую сторону группы карандашей вновь и вновь до тех пор, пока в ней не останется всего один карандаш. В этот момент справа число карандашей будет выражаться суммой

(Слева от флажка
Сравнение натуральных чисел в их двоичном представлении
Сейчас мы аккуратно докажем утверждение, которое применительно к десятичным числам воспринимается обычно как самоочевидное. Будем считать, что символ «0» меньше символа «1», тогда справедлива:
Лемма о сравнении двоичных чисел: Пусть
Лемму о сравнении можно переформулировать еще и так: если длины слов
Доказательство.
Пусть
Первоначальная задача теперь свелась к необходимости сравнить суммы
Предположим, что
При симметричном предположении, что что
Следствие (почти однозначность представления): Никакое натуральное число не может иметь двух различных двоичных представлений одной и той же длинны
Действительно, если два бинарных слова имеют одинаковую длину и различаются, то отыскав самую левую позицию, в которой их символы различны, мы обнаружим, что одно из слов представляет число строго меньшее по сравнению с числом, которое представляет оставшееся слово.
Конечно, отказавшись от требования равенства длин представлений, мы обнаружим, что утверждение о единственности перестает быть верным. Например, число “один” представляют двоичные слова “1”, “01”, “001” и так далее.
Упражнение: докажите, что у всякого натурального числа большего нуля существует в точности одно двоичное представление, первым символом которого является “1”.
Конкатенация двоичных представлений
В математике конкатенацией
Конкатенация — простое и очень удобное понятие. Любое изложение какой-либо теории, затрагивающее собой формальные слова, без этого термина становится крайне косноязычным.
На формальном языке математики точное определение конкатенации звучит следующим образом: пусть
Легко проверить, что операция конкатенации ассоциативна, то есть для любых слов
Для дальнейшего изложения нам также будет удобно вести еще несколько специальных определений.
Длину слова
Слово “
Слово “
Пустое слово “”, то есть слово, не содержащее ни одного символа, в математик по традиции обозначается греческой буквой
Очевидным образом:
для любого слова
для любых слов
В отношении того, как конкатенация двоичных слов влияет на величину представляемых этими словами чисел, верна следующая
Лемма о свойствах конкатенации двоичных чисел:
-
— любая цепочка нулей является двоичным представлением числа ноль;
-
(лемма о разложении степени двойки);
- для любого двоичного слова
:
(дописывание нулей слева к двоичному представлению, не меняет представляемого им числа);
- для любого двоичного слова
:
(дописывание к двоичному слову каждого нуля справа увеличивает представляемое им число в 2 раза);
- для любых двоичных слов
и
;
Ее доказательство элементарно и предоставляется читателю в качестве еще одного упражнения.
Арифметические действия над двоичными числами
Если двоичное слово x представляет натуральное число, то само это слово мы договорились назвать двоичным числом. Давайте теперь для каждой арифметической операции
в результате выполнения
Суммой
Произведением
Двоичное число
Деление с остатком и разность, когда она возможна, отношения равенства, отношение больше и другие имеют аналогичные определения.
Алгоритмы вычисления сумм, разностей, произведений и частных двоичных чисел почти дословно повторяют знакомые нам со школы алгоритмы выполнения операций “столбиком” над десятичными числами, а в некоторых моментах даже значительно проще них.
Каскадная схема для прибавления и вычитания из числа единицы
Преобразования двоичной записи числа, сопутствующие прибавлению и вычитанию из него единицы
Пусть
Проще всего прибавлять единицу к числам, оканчивающимся на 0. Легко сообразить, что, если
Другой сравнительно простой случай для прибавления единицы — это, когда двоичное число
Рассмотрим теперь произвольное двоичное число
где внутри вторых скобок стоит двоично-степенное разложение числа
Последняя цепочка равенств показывает, что в качестве
Утверждение предыдущего абзаца можно доказать и по-другому. Обратимся к лемме о конкатенации и напишем цепочку равенств:
Несмотря на длинный формальный вывод, алгоритм прибавления единицы к двоичному числу
!) Чтобы прибавить к двоичному числу x единицу нужно первый c справа ноль в слове x заменить на единицу, а все стоящие перед этим нулем единицы — на нули.
Пример:
Обсудим теперь как, меняются двоичные числа, когда из них единицу вычитают.
Во-первых, пока мы остаемся в рамках только натуральных чисел, нельзя вычесть единицу из двоичных чисел, представляющих число 0, то есть из двоичных слов, в состав которых не входит ни одной единицы.
В остальном вычитать единицу проще всего из слов, которые на единицу заканчивающихся: для двоичного слова
Следующий сравнительно простой случай для вычитания единицы — это слова вида
Осталось рассмотреть проблему вычитания единицы из таких двоичных чисел, которые оканчиваются на 0, но при этом не являются словами вида
Мы можем собрать все рассмотренные случаи для вычитания из числа единицы в один алгоритм с простой и короткой формулировкой:
!!) Чтобы вычесть из двоичного числа
Как вы сами видите, алгоритмы вычитания и прибавления к числу единицы очень похожи: каждый из них предписывает заменить на противоположные все символы слова
Алгоритм прибавления и вычитания единицы в абстрактном виде
И так, чтобы прибавить или вычесть единицу из двоичного числа
За изменения в каждом разряде
При таком способе организации алгоритма на ячейку
- Положить
. Ввести два однобитных слова-состояния
и
. Если на данном такте к слову
должна быть прибавлена единица, положить
“истина”,
“ложь”. Если единица должна быть отнята — положить
“ложь”,
“истина”. Перейти к шагу 2.
- Ввести два однобитных слова состояния:
, имеющего смысл — “идет прибавление единицы, разряд
должен быть преобразован”, и
, имеющего смысл — “идет вычитание единицы, разряд
должен быть преобразован”.
Присвоить словами
значение по умолчанию “ложь”. Если
“истина” и
, то исправить значение
на “истина”. Если
“истина” и
, то исправить значение
на “истина”.
Если хотя бы одно из слов-состоянийили
имеет значение истина, изменить символ в разряде
слова
на противоположный. Перейти к шагу 3.
- Если
— самый большой разряд в
, то алгоритм завершен. Значения слов состояний
и
в таком случае трактуются как “произошло переполнение в результате операции +1” и “производилось недопустимое вычитание 1 из нуля” соответственно.
Если— не последний разряд в
, то увеличить
на единицу и вернуться к шагу 2.
Интерфейс логической схемы прибавления/вычитания единицы
Ниже мы построим схему способную на каждом такте прибавлять или вычитать единицу к текущему

(интерфейс)
Перейдем теперь к внутренней архитектуре схемы.
Операционная ячейка
Схема операционной ячейки, представленная на рисунке …, разделена пунктирными прямоугольниками на две зоны: верхнюю — внутри кирпичного цвета прямоугольника, и нижнюю — внутри прямоугольника сиреневого цвета. Блоки нижней зоны отвечают за преобразование i-того разряда слова

Начнем с нижней. Слова-команды
Блок “
Переходим к верхней зоне. Сюда входит “генератор лжи” — “0” и два прямых мультиплексора: "
"
Рассмотрим работу мультиплексора “
Когда
В соответствии с описанным нами выше алгоритмом слово
Значением порта “
Анализ правильности установления мультиплексором “
Схема целиком
Чтобы получить полный чертеж схемы, реализующей прибавление/вычитание единицы из m-битного числа x, нам остается только соединить в каскад m описанных выше операционных ячеек и правильно подключить их к внешним портам. Как и в схеме компаратора, для разделения m-битного x на однобитные разряды мы применим блок обратной конкатенации

Примерный план следующей статьи.
Составные блоки как обозначения фрагментов схемы.
… Проблема неинформативного дублирования.
… Сравнение работы фрагмента схемы с работой блока.
… Блок клок, который ничего не делает, наглядное преобразование фрагмента в блок.
… Использование готовых схем в качестве составных блоков в неэлементарных схемах
(пример с мультиплексором, рекурсивное определение компаратора и схемы \pm 1)
....K-битные массивы регистров и мультиплексоров.
… Схема “часы”.
Упрощенный взгляд на латентность схемы.
… Взгляд на работу блока как на преобразователь данных.
… Задержки в самом длинном пути.
Прямое, обратное и обоюдонаправленное адресное дерево.
… Адресное дерево как обобщение многоходового мультиплексора (интерфейс).
....K-битные массивы регистров и мультиплексоров.
… Развернутый чертеж n-битного k-ходового дерева для k=8 и k=7.
… Рекурсивное определение. Глубина.
… Замечание об энергоэффективности.
… Однопортовая пользовательская RAM.
Простейшие стеки
… Цепочка сдвиговых регистров и цепочка регистров задержки.
… Цепочка с возможностью извлечения данных.
… Идеальный абстрактный стек и абстрактный стек конечной длины, интерфейс схемы.
… Интерфейс и реализация одной ячейки памяти простейшего стека.
… Схема целиком, рекурсивное определение.
… Устройства контроля опустошения и наполнения с использованием счётчика.
Каскадная очередь.
… Абстрактное определение идеальной очереди, очередь конечного объема.
… Идея реализации на основе стека.
… Контроль точки записи.
… Управление одной ячейкой памяти очереди.
… Схема целиком, рекурсивное определение.
Каскадный сумматор двух k-битных чисел.
… Алгоритм сложения столбиком для двоичных чисел.
… Интерфейс и реализация ячейки, обрабатывающий i-тый разряд.
… Интерфейс и реализация всего устройства.
… Рекурсивное определение, оценка глубины и объема.
… Двухтактный сумматор
Комментарии (30)

AlexanderS
02.06.2022 10:15Всё же с временными диаграммами было бы гораздо понятнее, чем с неканоническими изображениями элементов и словесным описанием.

Sergey_Kovalenko Автор
02.06.2022 10:36-1А если миллион разных сценариев, но все их можно коротко описать словами. У стека даже конечной длинны бесконечно много непериодических сценарием поведения на множестве тактов [0, infinity). Как описать их все с помощью временных диаграмм?
AlexanderS
02.06.2022 11:02Зачем описывать все? Нужно обеспечить начальное базовое понимание. А дальше человек может сам хоть во временной области рисовать, хоть схемой, хоть словами, хоть математическим эквивалентом. Тут… все зависит от того на кого статья ориентирована. Я, например, и так разберусь. А вот для новичков будет тяжело.
Sergey_Kovalenko Автор
02.06.2022 11:39Не находимся ли мы оба в плену профессионального искажения восприятия мира?). Если запросов на диаграммы будет много, я их обязательно включу. Для меня лично они так же непонятны и трудно воспринимаемы, как для кого-то непонятны словесные описания.

GarryC
02.06.2022 10:23+2Я, конечно, не "граммар наци", но количество ошибок в простых словах просто поражает. Ну а если еще и учесть упорное желание придерживаться своих "духовных" обозначений для инвертора и D-триггера, то вынужден признаться - всю статью "не осилил", предложенный "фристайл" явно не для меня.
Sergey_Kovalenko Автор
02.06.2022 10:44-1Принашу извинения за свои ошибки в словах.
В остальном: мир не постоянен - все меняется.

kmatveev
02.06.2022 13:52+1Полностью поддерживаю критику авторских графических обозначений для блоков:
Функциональность блока обозначается отдельным словом внизу, в отдельной рамке, да ещё и курсивом. На схемах ближе к концу статьи эти обозначения разглядеть невозможно. Обозначения в виде формы блока гораздо нагляднее
Подпись внизу у автора не только указывает на функциональность блока, но также является его идентификатором, при помощи нижнего индекса. Это ещё менее читаемо, не надо так. Базовый блок проще идентифицировать просто номером.
Подписи для входов и выходов базовых блоков в большинстве случаев можно опустить
Убивает то, что у автора для базовых блоков входные параметры незакрашенные, а выходные - закрашенные. А для схемы - наоборот.
Я так понимаю, что та рисовалка, где автор делает свои схемы, просто копипастит шаблон, а дальше автору лень.
Насчёт общего порядка изложения материала: автор сначала описывает, что схема составляется из блоков, затем зачем-то упоминает такты, потом описывает, как работает комбинаторно-логическая схема, потом вводит регистры, чтобы сразу после этого забыть про них и описать сложную комбинаторно-логическую (безрегистровую) схему. Я бы предложил тактирование и регистры убрать сильно на потом.
Sergey_Kovalenko Автор
02.06.2022 14:16Спасибо за критику. Буду думать как улучшить.
1)Да, внешняя форма неплохо кодирует тип блока, если вы собираетесь использовать только конечное число типов. Начиная со следующей статьи я буду с помощью кобинации старых определять все новые и новые типы блоков, как программисты в обычных языках программирования определяют новые функции. Если использовать для идентификации форму, то очень скоро придется рисовать звездочки и сердечки.
2) Я подумаю на этим.
3) Подписи портов логических блоков опустить не получится, если есть желание менять местоположение портов относительно иконки блока.
4)Насчет визуальной путанницы между входными/выходными портами схемы и ее блоков я дал подробное объяснение с начале статьи "Быстродействие элементарных схем", надеюсь, прочитав его, вы поймете мои мотивы и их логику.
Схема "пульсара" содержит регистр. Она приведена сразу после описания регистра, как типа логических блоков. Следующей по сложности схемой с регистром будут "часы", потом почти сразу стек и очередь. Но в общем соглашусь, тема регистров немного подвисла в воздухе. Мне надо было придупредить об этом в тексте.kmatveev
02.06.2022 17:01+1У вас какая-то непонятная принципиальность: или только внешняя форма, или только подписи. В стандартной системе отображения, на которую вам уже указывали, применяется внешняя форма для базовых блоков и прямоугольники для сложных блоков. Базовые блоки должны отображаться максимально просто и наглядно, чтобы восприниматься спинным мозгом. В математике, к примеру, для простейших операций применяются наглядные символы, а для синусов и логарифмов - имена
Аналогично предыдущему, я не утверждал, что для всех случаев нужно убрать подписи, а для тех, где назначение порта очевидно. Это так, например, для всех стандартных блоков. У вас же входные и выходные порты различаются цветом, так зачем на базовом блоке "not" ещё что-то подписывать?
Открыл предыдущую статью, охренел от её размера, на глаз не нашёл, где там это написано. Если логика "по проводкам сигнал идёт от чёрного к белому", то меня бы устроил такой ответ
Sergey_Kovalenko Автор
02.06.2022 17:21Вы спрашивали на кого рассчитана книга. Книга рассчитана не только на инженеров микроэлектроньщиков, интересующихся возможностью реализации в железе тех или иных алгоритмов. Она в том числе должна быть мостом "с другой стороны". Я год как математик помогал проектировать устройство на кристалле и мне очень трудно было поместить в свою картину мира все эти треугольнички и полумесяцы с черточкой. До сих пор не смог запомнить, что они означают. Да, наверное этот иероглифический язык удобен при работе на уровне аналоговых сигналов, так как напоминает инженеру физические чертежи схем. Однако зачем тащить весь этот рудимент к абстрактным математикам и людям, занимающимся теорией вычислений?
Насчет портов. Если меня кто нибудь научит, как в редакторе хабра ставить якоря - буду благодарен. Пока привожу выдержку полностью:Пояснения, касающиеся понятия внешних входных и внешних выходных портов на схеме
Да, наверное, это сбивает столку. Если слышишь две фразы: «внешний выходной порт схемы» и «выходной порт логического блока», то интуитивно проводишь между ними параллель. Кажется очевидными, что назначение, которому служит внешний выходной порт на схеме, должно быть аналогично роли, которую играет выходной порт у логического блока.
Однако, это не так. Наши формальные определения с такой аналогией идут в разрез.
Мысленный ряд здесь должен быть другим. Он строится на предположении, что не все устройства, влияющие на поведение схемы, изображены на ней целиком. Если устройство изображено на схеме целиком, то все порты этого устройства имеют атрибут внутренних. Внешними же названы те порты, которые сами присутствуют на схеме, а вот устройства, которым они принадлежат, в эту схему непосредственно не включены.
Согласно этой точке зрения, дистанционно вынесенные на материнскую плату компьютера входные порты принтера, монитора, и аудиосистемы – являются для платы внешними входными, то есть физически присутствующими на ней входными портами тех устройств, которые сами размещены за ее пределами. С другой стороны, так же дистанционно размещенные на плате выходные порты мыши, клавиатуры и сканера – являются по отношению к плате внешними выходными портами.
Указанная интерпретация на первый взгляд противоречит тому обстоятельству, что разъемы на плате, куда подключаются кабели от принтера, монитора и аудиосистемы, по своему смыслу являются выходными портами самой материнской платы, рассматриваемой как единое устройство, а разъемы, куда подключаются клавиатура и мышь – ее входными портами.
В действительности между обеими трактовками никаких противоречий нет. Все зависит от выбранной точки зрения.
Если вы рассматриваете материнскую плату как обособленное цельное устройство, то расположенные на ней разъемы для клавиатуры и мыши имеют смысл входных портов, то есть тех, на которые должны быть поданы электрические импульсы в процессе работы, а разъемы для монитора и принтера – как выходные порты, поскольку последние сами являются источниками цифрового сигнала.
В то же время, если плату рассматривать «изнутри»: как собранную из отдельных устройств логическую схему, то «обратная» стороны разъема для клавиатуры будет выглядеть, как дистанционно вынесенный порт выхода (клавиатура порождает импульсы), а обратная сторона разъема для монитора – как типичный порт входа (на него нужно отправлять импульсы).
kmatveev
02.06.2022 18:37Книга действительно рассчитана непонятно на кого, она плоха для всех. В ней нет ничего нового, значит не на электронщиков. Она плохо подходит для обучения, значит не на новичков. Для инженеров она слишком формалистична и непрактична. Если на математиков - нафига городить схемы вообще, достаточно сказать, что есть функции and, or, not, и всё, дальше достаточно любого математического формализма. Вы оправдываетесь, что вы математик, я верю плохо, как раз математикам свойственно делать всё максимально компактно и использовать иероглифы для выразительности.
Я правильно понял вашу логику: "Внешний порт платы обозначим вот так, потому что это внутренний порт для внешнего устройства"? Вы штаны случайно не наизнанку носите?
Sergey_Kovalenko Автор
02.06.2022 18:52Все мы хороши на словах пока дела не коснемся.
Уважающий себя джентльмен, когда он пишет, что у автора такой-то книги нет ничего нового, обычно приводит ссылки на те же самые главы или темы в других источниках. Вот примерное олавление книги, которую я собираюсь написать. Я буду только рад, если мою работу уже кто-то сделал до меня.
ermouth
02.06.2022 22:28https://eccc.weizmann.ac.il/resources/pdf/OBDD-Book.pdf
Понятно, что соответствие даже близко не 1:1, но имеет смысл хотя бы посмотреть на стиль и структуру. И на графический формализм, не подходящий явно ни под один стандарт, но всем понятный сразу.
http://www.ime.cas.cn/icac/learning/learning_3/201909/P020190909561648570397.pdf тут немного про другое, гораздо ближе к реализации, но кое-где с вашими предыдущими публикациями отчасти пересекается. Подача очень формальная местами, но, кажется, вам так нравится.
Эта книга может быть полезна в том смысле, что вы на свои примеры станете смотреть более критично и возможно перерисуете в общем-то стандартный XNOR, который у вас получился с несимметричными по задержке плечами. С тз логики всё ок, но в реальности так, вроде, никто не делает (пусть спецы поправят если я не прав).
Sergey_Kovalenko Автор
03.06.2022 00:10За книги конечно спасибо, но при беглом знакомстве с аннотацией мне показалось, что их тема к моей относится примерно так же как наука о цементе, кирпичах и напряжении в материалах относится к архитектурному проектированию, скажем, нового большого аэропорта. То есть да, технология строительства накладывает ограничение на способы решить задачу, которыми располагает архитекторское бюро, но не более чем.
ermouth
03.06.2022 06:30То есть да, технология строительства накладывает ограничение на способы решить задачу, которыми располагает архитекторское бюро, но не более чем.
Математика начинается с определений и формализмов. В других дисциплинах всё примерно так же.
Вы насколько всерьёз будете относиться к выкладкам человека, который напишет что-нибудь типа «абазначем за ℂ множество вещественных чисел»? А ваша работа пока именно так выглядит.
Sergey_Kovalenko Автор
03.06.2022 08:30Я долго живу и видел много разных людей. Если у человека есть мотивы ввести свои обозначения, он их объяснил и хотя бы примерно обозначил финальный результат, я буду его слушать.

Shmuma
03.06.2022 11:35+1Большое спасибо за интересный материал и что не бросаете писать!
Вы не планируете разбавлять абстрактные построения конкретными примерами кода с которыми можно было бы поэкспериментировать и поиграться? То есть пробросить мостик с теории к практическому применению.
С верилогом, наверное, много возни, но тоже не фатально. Например в известной книжке "Designing Video Game Hardware in Verilog" это решено через web-среду со всеми примерами.Да и на верилоге свет клином не сошелся, сейчас есть, например, migen, на котором можно было бы реализовать все примеры.
Sergey_Kovalenko Автор
03.06.2022 13:05Спасибо за добрые слова и снисходительность к моему мышлению позапрошлого века. Да было бы здорово поэкспериментировать, - правда я в делах написания непосредственно HDL-программ не сведущ как первокурсник. Думаю, в каких-то азах недолго разобраться: концепция мне ясна. Я анализировал как синтаксис, так и семантику Verilog и VHDL, когда продумывал свой упрощенный язык. У меня была мечта, что кто-то среди нынешних студентов поможет мне сделать эксперименты. Это было бы полезно для такого человека, я думаю, Плюс возможность получать консультации по реализации тех или иных алгоритмов. Если вы можете меня порекомендовать кому-нибудь, буду благодарен.
Книгу "Designing Video Game Hardware in Verilog" не видел, но обязательно посмотрю.

gochaorg
03.06.2022 23:21Предложение
Ввести понятие памяти, бита - это про rs и t триггеры и как строится ячейка памяти и из чего она состоит. Просто на одной булевой логике не уедешь, т.к. не понятно как эта логика может содержать вычисления. Тот же вопрос сумматора необходимо понятие бита переноса. Я может плохо смотрел, его не увидел по биты памяти.
Само понятие булевой логики, надо расширить, для взрослых читателей до вопросов физики и понятия фронта волны и устойчивой и не устойчивой системы, просто из самих логических высказываний не вытекает что в пределах логики есть память (бит информации)
Не плохо бы посвятить главу вопросу булевой логики при реализации ее в физике, те же диоды, транзисторы и т.д. в качестве примера физических воплощений привести примеры "домино" компьютер и компьютеры основанные на водных устройствах и та же машина Тюнинга в биологической клетке, не стандартные виды компьютеров это интересно. Можно отдельно разобрать логику "домино" компьютера, т.к. она на прямую не содержит И,ИЛИ,НЕ, но к ней сводиться через другие операции. Можно ещё вспомнить про компьютерные схемы из красной пыли/песка в Minecraft.
В последних главах не плохо бы разобрать заблуждения по поводу язык программирования - что они могут быть похожи на естественные языки. Пример , что язык sql, задумывался как дружественный язык для домохозяек
П.с. по мне книга должна быть интересной, с кучей примеров, если уж писать на широкую аудиторию, то нужны практические примеры, желательно такие, что бы и молодой читателей мог понять и применить (это вообще круто)
То же применение, это не обязательно только специализированные языки проектирования схем/ПЛИС или как их там... А те же симуляторы микро-схем, коих много, да хоть Minecraft.
Взять и предоставить ту же схему не в стандартном виде, а виде Minecraft блоков, потом в виде схемы пайки транзисторов или фотографии сборки схемы на монтажной плате
Можно ещё вспомнить, что многие схемы были готовы и печатались в отдельных журнал в период позднего СССР
Sergey_Kovalenko Автор
03.06.2022 23:341) Среди элементарных блоков присутствую однобитные регистры с/без портом "enable" и "reset" во всех комбинациях.
2) Об этом есть немного в предыдущей статье "быстродействие элементарных схем", но понятие бистабильности как таковое не затрагивается, поскольку намеренно выбран более высокий уровень абстракции.
3) Есть некоторая цель и лимит страниц средней книги. Не получится написать обо всем.
4) Формальные языки в этой книге всего лишь средство, не цель исследования.
gochaorg
03.06.2022 23:49Извините, прострел предыдущую статью по фронт сигнала там есть.
Sergey_Kovalenko Автор
03.06.2022 23:55Да извинятся в общем-то не за что. Спрашивайте - если смогу, постараюсь ответить.
ermouth
Простите, но совершенно невозможно же читать и смотреть, просто кровь из глаз.
Для логических вентилей существуют стандартные обозначения, которые в любой версии (ANSI, IEC, ГОСТ – на выбор) гораздо лучше ваших самопальных, которые сплошь визуальный мусор.
Двоичные числа не обозначают кавычками, их пишут как 11101₂. С другими обозначениями та же история. С читаемостью формул – та же.
UPD. Для примера – как нужно записывать доказательство существование двоичного представления https://math.stackexchange.com/a/1966217/647986, просто сравните читаемость.
Sergey_Kovalenko Автор
Со стандартами дело спорное - в книге будет не так много стандартных вентелей. В то же время, если кастомные по стилю окажуться сильно отличными от стандартных, глазу тоже нездобровать.
С читаемостью доказательств проблему признаю. Надо будет над ней поработать. Легко писать доказательство одному математику для другого, можно много деталей опускать. Здесь все таки обстоятельства другие и задача подачи материала во всех подробностях может трудней решаться.
В любом случае спасибо за внимание к статье и ваш отзыв - я пытаюсь учитывать отзывы к предыдущей статье, когда пишу следующую.
ermouth
Пока не было ни одного нестандартного, и я уверен на 100%, что и не будет, в логических вентилях что-то новое выдумать сложно.
Я не математик, но то, что в примере читаю без запинок, а то, что у вас... Вы же не в Труды Стекловки пишете, правда? )
Sergey_Kovalenko Автор
Я собираюсь комбинировать простые блоки в более сложные. Затем что получилось еще и еще раз. Для каждого кастомного блока свою иконку не придумаешь, а использовать для одних одно, для других другое - тоже не лучшее решение.
В идеологических спорах трудно найти "правильную" точку зрения.
karambaso
Здесь не идеология, здесь общепринятые стандарты. Вы предлагаете свои обозначения, но большинству учившихся по стандартам это не понравится.
Ну и до кучи - а почему бы не сократить подачу и не написать просто формулу для вашего устройства из примера? Отображение схемы на формулу объяснить очень просто, знаки "и", "или" можно даже на "*", "+" заменить, что бы максимально просто было. И краткость получится, не нужно отслеживать лабиринт из проводов на схеме.
ЗЫ. Вчера смотрел новые посты, ваш сначала был, потом исчез. Хотел написать комментарий, а вы "сбежали", вместе с текстом в черновики. Хотя в результате обнаружил возможность постоянно держаться в топе списка - прячем в черновики и выкладываем снова раз в несколько часов. Вы так намеренно делали? Или стесняетесь критики и прячетесь в черновиках? Стесняться не надо, ошибки нужно признавать и исправлять, а прятаться постоянно - выглядит не очень.
Sergey_Kovalenko Автор
С исчезновением статьи - это хабр немножко глючил, или я. Дело тенмое. Опубликовал в 18.49 в том виде, как вы ее видите, но время прошло как 10.21. Пришлось старую скрыть в черновики и перевыпустить из под нового шаблона. Плюсы и добавление избранное были утеряны, но зато статья не на ночь и утро, а сутки, как и должно провесит.
В обществе должна быть здоровая толика консерватизма. Другие работы и используемые в них стандарты нацелены на другие вопросы - там и язык удобным другой получается. Если бы я чертил низкоуровневую логику (не дальше сумматора), то предерживался гостов и исо и традицый. Но для моих целей это не удобно.
Ivanii
И очень не удобно читать схемы справа на лево, когда ничего не мешает сделать слева на право как читает почти весь мир?
Sergey_Kovalenko Автор
Внутри компаратора по каскаду ячеек сигнал распостраняется слева на право: во всех ячейках копаратора составляющие их элементарные блоки имею ориентацию слева на право.
Внутри схем каскадного сумматора, каскадного умножителя, каскадного счетсчика слова-команды относительно слов-аргументов распостраняютя справа налево. Ориентировать слева направо элементарные блоки в ячейках перечисленных схем было бы соблюдением правил ради соблюдения правил.
Я предпочитаю придерживаться логики и соображений удобства. Надеюсь, вскоре и вы полюбите фристайл.