
Перед вами четветая статья-черновик будущей книги «Алгоритмы на кристалле».
В действительности по своему содержанию и стилю изложения ей следовало бы быть первой статьей, не считая оглавление книги и небольшой вводной части. Однако придумать сразу простой подход к изложению удается не всегда. По этой причине лежащий перед текст является во много самостоятельным, его можно читать почти независимо от предыдущих двух статей, обращаясь к ним только как к справочнику. Буду благодарен за любого рода отзвы, как со стороны новичков в этой областти так и тех, кто работает в ней давно — обратная связь поможет сделать финальную редакцию книги лучше.
Предыдущие черновики:
… Примерное оглавление.
… Вычислительная модель.
… Быстродействие логических схем.
Возможно, в вашем браузере с первого раза не будут правильно отображаться формулы. Если так, попробуйте перезагрузит страницу — на моем компьютере этот фокус работает.
Желаю приятного чтения.
Простой способ представить себе работу элементарной логической схемы
Логическая схема и ее компоненты
Логические схемы состоят всего из трех типов компонент: портов (входных и выходных), шин и логических блоков (функциональных и регистров). При графическом изображении логическим блокам соответствуют скругленные прямоугольники, портам — маленькие полукруги, а шинам — тонике, иногда разветвленные линии. Границы самой схемы обозначены прямоугольной рамкой.

(Схема "=" )
Логическая схема способны производить вычисления, при этом они оперирует двоичными словами: “данными”. Выходные порты (заполненные полукруги) нужны, чтобы отправлять данные, входные порты (белые полукруги) — чтобы их принимать, шины — чтобы передавать данные от выходных портов к входным. Функциональные логические блоки нужны, чтобы данные неким образом преобразовывать, а блоки-регистры — чтобы их временно запоминать.
Пути распространения данных в схеме неизменны: порты статично прикреплены к логическим блокам (внутренние порты) или внешней рамке (внешние порты), шины статично прикреплены к портам. Каждая шина и каждый порт способны работать с двоичными словами строго определённой длины, которая называется их размерностью. Размерности шины и всех прикрепленных к ней портов должны поэтому совпадать. Чтобы избежать неоднозначности в пересылаемых данных, к каждой шине разрешено прикреплять в точности один выходной порт. Места разветвления шин изображаются жирными точками, там, где точек нет — шины всего лишь пересекаются, не оказывая влияния на работу друг друга.
Такт, как эпоха
Процесс вычислений, производимых схемой, состоит из последовательности тактов. Неформально каждый такт удобно представлять себе как продолжительную временную эпоху. Логические схемы проектируются таким образом, чтобы в продолжение каждой эпохи каждый выходной порт смог отправить в прикрепленную к нему шину ровно одно двоичное слово, а каждый входной порт — ровно одно двоичное слово из прикрепленной к нему шины смог принять. Слово, которое на данном такте выходной порт отправит в шину, входной порт примет из шины, а сама шина передаст — будем также называть соответственно значением выходного порта, значением входного порта и значением шины в данный такт времени.
Процесс вычислений в схеме без регистров
По определению значение, которые функциональный блок на данном такте выставит на том или ином своем порту выхода, полностью определяется именем порта выхода, типом блока и значениями, которые на этом такте примут его входные порты. Например, функциональные блоки элементарного типа “+” реализуют сложение двух однобитных чисел: порту "

(рисунок однобитного +)
И так, пусть все логические блоки в схеме являются функциональными. Опишем работу такой схемы в один из тактов.
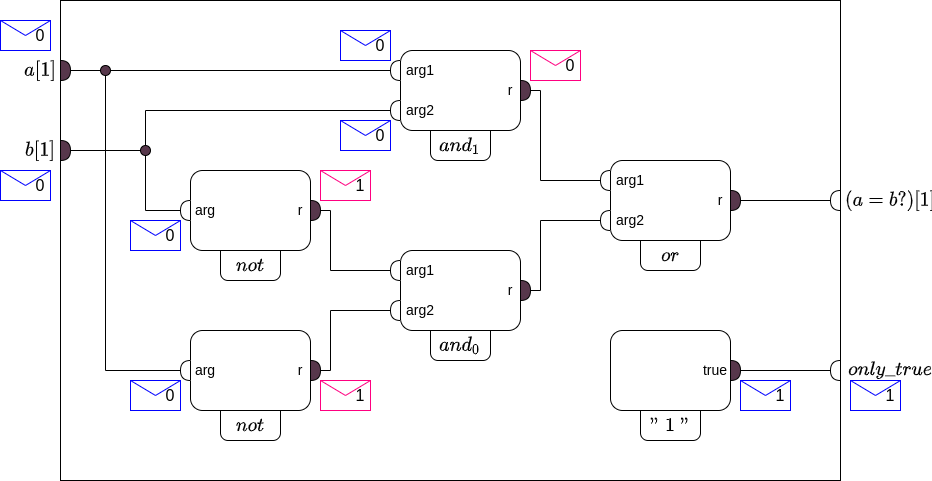
(Cхема равенства с аппендиксом из константы в продолжение одного такта. Начало).
О работе любой схемы мы будем предполагать, что в начале каждого такта значения ее внешних портов уже известны и остаются неизменными до начала следующего такта. Разумеется, известны и также останутся неизменными значения выходных портов всех блоков-констант. Если значение некоторого порта выхода когда-либо стало нам известным, мысленно представим, что затем это значение напечатано на воображаемых конвертах и разослано вдоль прикрепленной к этому порту шине ко всем портам входа, с которыми эта шина соединена.

(Продолжение: рассылка конвертов 1 этап).
Как только каждый входной порт некоторого функционального блока на текущем такте получит свой конверт, мы можем вычислить значения всех выходных портов уже у самого этого блока и тем самым продолжить рассылку конвертов.

(Продолжение: рассылка конвертов 2 этап).
Если в логической схеме нельзя совершить круг, переходя от одного функционального блока к другому функциональному блоку так, чтобы всякий раз при этом один из портов входа второго блока был бы соединен с одним из портов выхода первого, то такая схема называется функционально ациклической (есть в ней регистры, или нет — не важно). Из результатов статьи “Вычислительная модель” следует, что в функционально ациклических схемах (только такие мы и будем рассматриваться в оставшейся части книги) описанный выше процесс рассылки конвертов обязательно приведет к тому, что в итоге каждый входной порт схемы ровно один раз получит свой конверт, а для каждого внутреннего выходного порта, логический блок к которому тот прикреплен, ровно один раз вычислит его значение. Как только это произойдет, очередной такт можно считать завершенным.

(Рассылка конвертов. Конец: все порты получили значения).
Особенности поведения регистров
Элементарные регистры способны хранить в себе однобитные слова — значения регистра. Значения регистров меняются только при смене тактов. Слово, которое появится на единственном выходном порте "
Для регистра с одним единственным входным портом "
Чтобы значение регистра можно было сохранять несколько тактов подряд, в некоторые типы регистров добавлен порт "
Значение любого элементарного регистра в нулевой такт случайно.

(рисунок, поясняющий работу регистров)
Спецификация всех регистров, принятых в этой книге за элементарные, описаны в аксиомах E8-E11 статьи “Вычислительная модель”.
Смена тактов в элементарной схеме
Если в схеме есть регистры, то в начале каждого такта в качестве еще одного первоисточника данных к уже упоминавшимся внешним выходным портам и выходным портам блоков-констант добавляются выходные порты регистров. В остальном процесс вычислений, происходящий на схеме в течение такта почти такой же, что и описанный выше процесс вычислений на схеме без регистров. Единственным отличие будет то, что каждый раз между концом текущего такта и началом следующего все регистры определяют свое новое значение. Ниже приведен пример работы за несколько последовательных тактов простенькой схемы с регистром “пульсар”.



(рисунок, поясняющий работу пульсара в продолжение одного такта)
Замечание по поводу именования портов
Все внешние порты схемы наделяются собственными именами и никакой путаницы в их назывании не будет. В то же время мы неоднократно будем встречать схемы, в которых присутствуют сразу несколько блоков одного и того типа и у каждого из этих блоков есть порт с одним и тем же именем “
На этом наше короткое знакомство с основами теории логических схем закончено. Его объема, в принципе, должно быть достаточно для понимания всего излагаемого ниже материала. Более подробное и формализованное изложение общей теории читатель найдет в двух предыдущих статьях. По мере углубления в предмет их содержание станет полезным. Сейчас мы переходим к конкретным почти промышленным схемам.
Схема каскадного компаратора
Определение старшинства между двоичными словами
Для сравнения двоичных слов мы будем использовать лексикографический порядок. В лексикографическом порядке расставлены слова в словарях и справочниках. Применительно к двоичным словам он определяется следующим образом:
Пусть даны два m-битных слова:
Какое-то число начальных членов этих слов могут быть одинаковыми, то есть:
В следующем пераграфе мы докажем, что если каждое из слов
Абстрактное описание алгоритма сравнения
Само определение лексикографического порядка содержит в себе алгоритм его вычисления. Действительно, все что мы должны делать — это синхронно перебирать последовательности символов обоих слов до тех пор, пока не обнаружим позицию
В пошаговом виде, описанный алгоритм выглядит так:
- Ввести два булевых слова-состояния: первое — “просмотрев символы слов до позиции 0 включительно, установлено, что
” или коротко —
, и второе: “просмотрев символы слов до позиции 0 включительно, установлено, что
”, коротко —
. Обоим словам-состояниям присвоить значение “ложь”, перейти к 2)
- Проверить одинаковы ли символы
и
. Если они различны и
“0”- присвоить значение истина состоянию
, если они различны и
“0” — присвоить значение истина состоянию
. Перейти к циклическому повторению 3)-5)
- Если рассматриваемая позиция
в словах
и
— последняя, перейти к 7). Иначе в обоих словах перейти к позиции
, а в алгоритме к шагу 4)
- Ввести слова-состояния: слово
— “просмотрев слова вплоть до позиции
, установлено, что
”, и слово
— “просмотрев слова вплоть до позиции
, установлено, что
”. Обоим только что введенным словам-состояниям присвоить значения «ложь». Если хотя бы одно из слов-состояний предыдущей позиции
или
имеет значение «истина» (уже установлено какое из слов меньше), никаких действий над символами
и
не требуется. Просто копируем
в
,
в
. Снова переходим к 3). Иначе переходим к 5).
- Если мы здесь, значит анализ
ранее просмотренных позиций слов
и
не смог дать ответ, какое из слов меньше. Сравним текущие позиции
и
. Если они различны и
“0”- присвоить значение истина слову-состоянию
, если они различны и
“0” — присвоить значение истина состоянию
. Вернуться к циклическому повторению шага 3).
- Конец алгоритма. Мы просмотрели все m позиций. Логика алгоритма такова, что только одно из слов-состояний:
, или
, может в итоге иметь значение “истина”, тем самым отвечая на вопрос, какое из слов меньше. Если оба этих слова-состояния остались ложными, то слова
и
в точности совпадают.
Интерфейс схемы компаратора
Прежде чем строить схему какого-либо алгоритма, нужно определиться, в каком виде мы собираемся подавать исходные данные, а в каком виде — снимать результат. Компаратор, который мы построим ниже будет способен сравнивать два m-битных слова за один такт. Передаваться эти слова будут в качестве значений внешних выходных

(интерфейс компаратора)
С интерфейсом схемы мы определились, пора теперь разобраться со знаком вопроса.
Операционная ячейка схемы компаратора
Алгоритм сравнения, который был описан выше, так или иначе синхронно просматривает все позиций слов
В своей логической конструкции описанный выше алгоритм сравнения сводится к следующему:
Находясь над позицией
Если одно из этих состояний уже имеет значение “истина”, или же
Если же оба слова
Давайте теперь подробно разберем схемы ячейек-обработчиков.
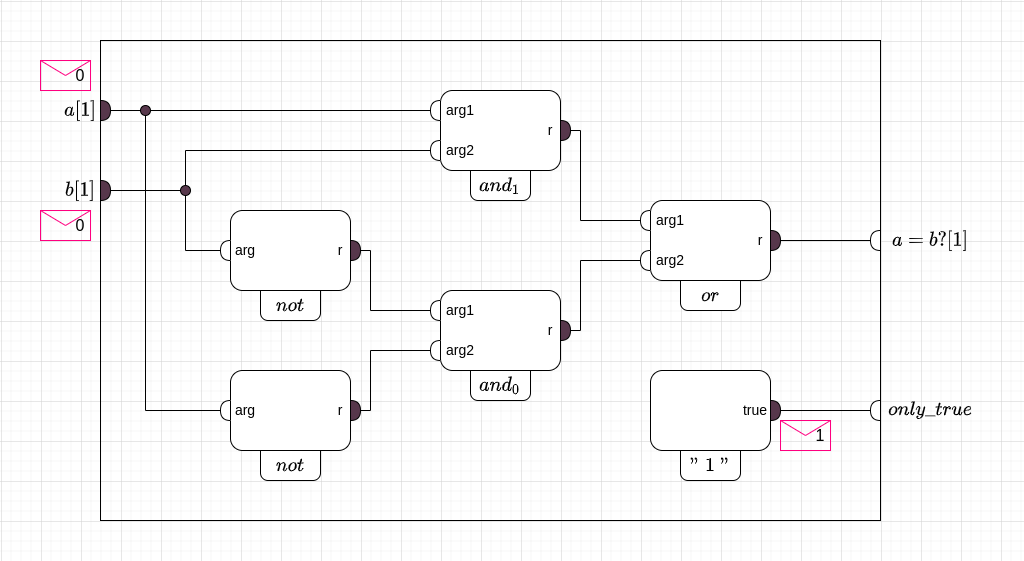
На рисунке … изображен обработчик пары первых символов слов

(Головная ячейка компаратора)
Плеяда блоков "
После того как порт "
Не трудно проверить, что такой способ придавать значения словам
И так, мы доказали, что приведенная схема обработчика двух самых первых символов слов

(Регулярная ячейка компаратора)
По сравнению с предыдущим рисунком здесь добавилась плеяда блоков в кирпичном прямоугольнике и блок типа “
При обработке всех позиций, кроме первой, для того, чтобы значения слов
- оба слова
и
должны иметь значение “ложь”;
- значения
, и
должны быть разными.
Второе условие, как и на предыдущем рисунке выполняет плеяда блоков с префиксом "
Блок "
Схема целиком
Давайте теперь объединим все наши наработки в одну схему. Чтобы результат занимал не очень много места перерисуем схемы ячеек в более компактное представление и ограничимся сравнением 3-битных слов. Проверьте самостоятельно, что это все те же самые ячейки-обработчики, которые мы рисовали выше.
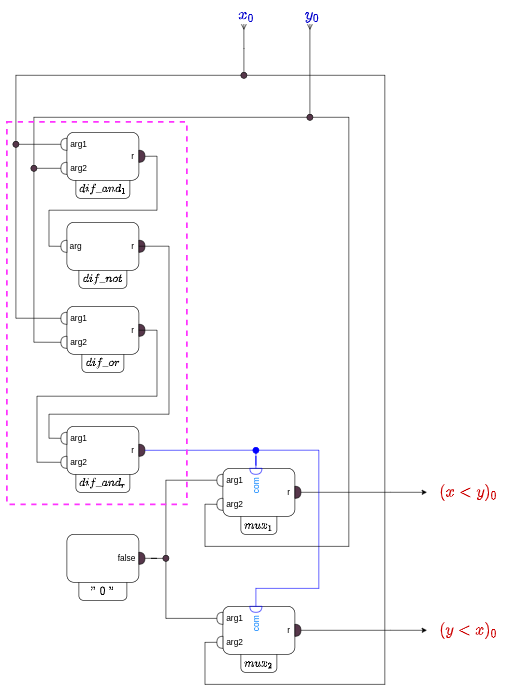
(компактное представление головного обработчика)
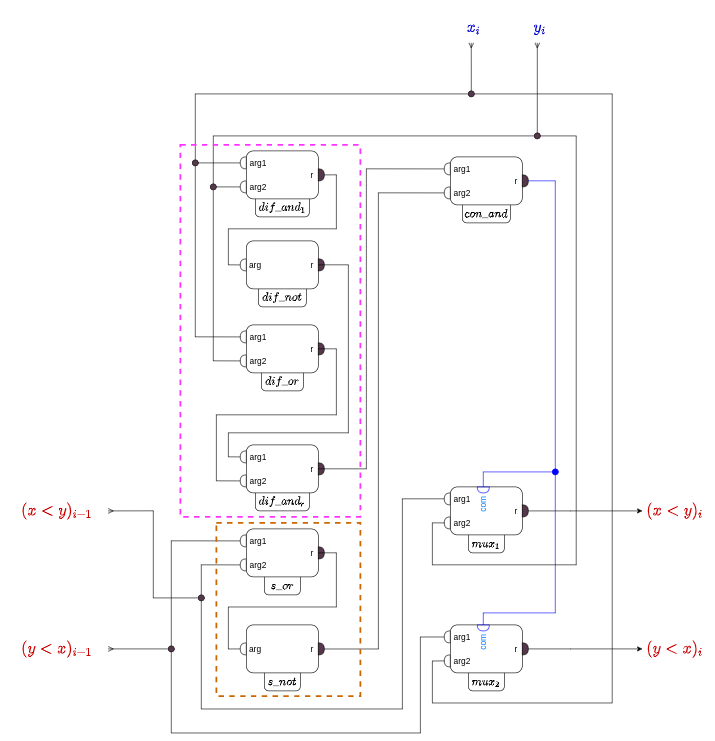
(компактное представление регулярного обработчика)
Остается соединить ячейки между собой и правильно подать на них позиции слов x и y (рис ...). Для разделения 3-битных слов x и y на последовательность их 1-битных символов в схеме используется два блока обратной конкатенации типа "

(схема целиком)
Двоичное представление натуральных чисел
Позиционное исчисление с основанием 2
Всякому двоичному слову
В этой книге при построении логических схем в основном будет использоваться именно двоичная система исчисления, поэтому часто мы не будем различать само число
Пусть
Чуть позже мы покажем, что значение
По поводу двоичного представления чисел естественно возникают два вопроса:
- Всякое ли натуральное число можно представить в двоичном виде?
- Если такое представление у некоторого натурального числа имеется, единственно ли оно?
Ответы на оба этих вопроса многим читателям покажутся очевидными, однако часто наше сознание путает знакомое с понятным. Ниже приведены рассуждения, дающие точный ответ на каждый из вопросов, но для читателя было бы хорошим упражнением попробовать прежде обдумать их самостоятельно.
Существование двоичного представления для любого натурального числа
При помощи математической индукции докажем, что у всякого натурального числа имеется двоично-степенное разложение.
Число 0 представимо так:
Число 1 тоже:
Предположим, что для всех натуральных чисел, меньших
Число n либо четное, либо нечетное.
Если
Если
И так, в обоих случаях индукционный шаг сделан и тем самым представимость всех натуральных в двоичном виде может считаться доказанной.
Разложение степеней двойки. Геометрическая интерпретация
Чтобы решить вопрос единственностью, в алгоритме прибавления/вычитания единицы и еще много где, нам понадобится одно замечательное тождество:
В принципе это тождество можно доказать, используя школьные знания о сумме членов геометрической прогрессии, но есть и более наглядный способ.
Пусть

(Слева от флажка
Если число карандашей в группе слева от флажка больше одного (то есть

(Слева от флажка
Будем перемещать флажок в середину остающегося от него по левую сторону группы карандашей вновь и вновь до тех пор, пока в ней не останется всего один карандаш. В этот момент справа число карандашей будет выражаться суммой

(Слева от флажка
Сравнение натуральных чисел в их двоичном представлении
Сейчас мы аккуратно докажем утверждение, которое применительно к десятичным числам воспринимается обычно как самоочевидное. Будем считать, что символ «0» меньше символа «1», тогда справедлива:
Лемма о сравнении двоичных чисел: Пусть
Лемму о сравнении можно переформулировать еще и так: если длины слов
Доказательство.
Пусть
Первоначальная задача теперь свелась к необходимости сравнить суммы
Предположим, что
При симметричном предположении, что что
Следствие (почти однозначность представления): Никакое натуральное число не может иметь двух различных двоичных представлений одной и той же длинны
Действительно, если два бинарных слова имеют одинаковую длину и различаются, то отыскав самую левую позицию, в которой их символы различны, мы обнаружим, что одно из слов представляет число строго меньшее по сравнению с числом, которое представляет оставшееся слово.
Конечно, отказавшись от требования равенства длин представлений, мы обнаружим, что утверждение о единственности перестает быть верным. Например, число “один” представляют двоичные слова “1”, “01”, “001” и так далее.
Упражнение: докажите, что у всякого натурального числа большего нуля существует в точности одно двоичное представление, первым символом которого является “1”.
Конкатенация двоичных представлений
В математике конкатенацией
Конкатенация — простое и очень удобное понятие. Любое изложение какой-либо теории, затрагивающее собой формальные слова, без этого термина становится крайне косноязычным.
На формальном языке математики точное определение конкатенации звучит следующим образом: пусть
Легко проверить, что операция конкатенации ассоциативна, то есть для любых слов
Для дальнейшего изложения нам также будет удобно вести еще несколько специальных определений.
Длину слова
Слово “
Слово “
Пустое слово “”, то есть слово, не содержащее ни одного символа, в математик по традиции обозначается греческой буквой
Очевидным образом:
для любого слова
для любых слов
В отношении того, как конкатенация двоичных слов влияет на величину представляемых этими словами чисел, верна следующая
Лемма о свойствах конкатенации двоичных чисел:
-
— любая цепочка нулей является двоичным представлением числа ноль;
-
(лемма о разложении степени двойки);
- для любого двоичного слова
:
(дописывание нулей слева к двоичному представлению, не меняет представляемого им числа);
- для любого двоичного слова
:
(дописывание к двоичному слову каждого нуля справа увеличивает представляемое им число в 2 раза);
- для любых двоичных слов
и
;
Ее доказательство элементарно и предоставляется читателю в качестве еще одного упражнения.
Арифметические действия над двоичными числами
Если двоичное слово x представляет натуральное число, то само это слово мы договорились назвать двоичным числом. Давайте теперь для каждой арифметической операции
в результате выполнения
Суммой
Произведением
Двоичное число
Деление с остатком и разность, когда она возможна, отношения равенства, отношение больше и другие имеют аналогичные определения.
Алгоритмы вычисления сумм, разностей, произведений и частных двоичных чисел почти дословно повторяют знакомые нам со школы алгоритмы выполнения операций “столбиком” над десятичными числами, а в некоторых моментах даже значительно проще них.
Каскадная схема для прибавления и вычитания из числа единицы
Преобразования двоичной записи числа, сопутствующие прибавлению и вычитанию из него единицы
Пусть
Проще всего прибавлять единицу к числам, оканчивающимся на 0. Легко сообразить, что, если
Другой сравнительно простой случай для прибавления единицы — это, когда двоичное число
Рассмотрим теперь произвольное двоичное число
где внутри вторых скобок стоит двоично-степенное разложение числа
Последняя цепочка равенств показывает, что в качестве
Утверждение предыдущего абзаца можно доказать и по-другому. Обратимся к лемме о конкатенации и напишем цепочку равенств:
Несмотря на длинный формальный вывод, алгоритм прибавления единицы к двоичному числу
!) Чтобы прибавить к двоичному числу x единицу нужно первый c справа ноль в слове x заменить на единицу, а все стоящие перед этим нулем единицы — на нули.
Пример:
Обсудим теперь как, меняются двоичные числа, когда из них единицу вычитают.
Во-первых, пока мы остаемся в рамках только натуральных чисел, нельзя вычесть единицу из двоичных чисел, представляющих число 0, то есть из двоичных слов, в состав которых не входит ни одной единицы.
В остальном вычитать единицу проще всего из слов, которые на единицу заканчивающихся: для двоичного слова
Следующий сравнительно простой случай для вычитания единицы — это слова вида
Осталось рассмотреть проблему вычитания единицы из таких двоичных чисел, которые оканчиваются на 0, но при этом не являются словами вида
Мы можем собрать все рассмотренные случаи для вычитания из числа единицы в один алгоритм с простой и короткой формулировкой:
!!) Чтобы вычесть из двоичного числа
Как вы сами видите, алгоритмы вычитания и прибавления к числу единицы очень похожи: каждый из них предписывает заменить на противоположные все символы слова
Алгоритм прибавления и вычитания единицы в абстрактном виде
И так, чтобы прибавить или вычесть единицу из двоичного числа
За изменения в каждом разряде
При таком способе организации алгоритма на ячейку
- Положить
. Ввести два однобитных слова-состояния
и
. Если на данном такте к слову
должна быть прибавлена единица, положить
“истина”,
“ложь”. Если единица должна быть отнята — положить
“ложь”,
“истина”. Перейти к шагу 2.
- Ввести два однобитных слова состояния:
, имеющего смысл — “идет прибавление единицы, разряд
должен быть преобразован”, и
, имеющего смысл — “идет вычитание единицы, разряд
должен быть преобразован”.
Присвоить словами
значение по умолчанию “ложь”. Если
“истина” и
, то исправить значение
на “истина”. Если
“истина” и
, то исправить значение
на “истина”.
Если хотя бы одно из слов-состоянийили
имеет значение истина, изменить символ в разряде
слова
на противоположный. Перейти к шагу 3.
- Если
— самый большой разряд в
, то алгоритм завершен. Значения слов состояний
и
в таком случае трактуются как “произошло переполнение в результате операции +1” и “производилось недопустимое вычитание 1 из нуля” соответственно.
Если— не последний разряд в
, то увеличить
на единицу и вернуться к шагу 2.
Интерфейс логической схемы прибавления/вычитания единицы
Ниже мы построим схему способную на каждом такте прибавлять или вычитать единицу к текущему

(интерфейс)
Перейдем теперь к внутренней архитектуре схемы.
Операционная ячейка
Схема операционной ячейки, представленная на рисунке …, разделена пунктирными прямоугольниками на две зоны: верхнюю — внутри кирпичного цвета прямоугольника, и нижнюю — внутри прямоугольника сиреневого цвета. Блоки нижней зоны отвечают за преобразование i-того разряда слова

Начнем с нижней. Слова-команды
Блок “
Переходим к верхней зоне. Сюда входит “генератор лжи” — “0” и два прямых мультиплексора: "
"
Рассмотрим работу мультиплексора “
Когда
В соответствии с описанным нами выше алгоритмом слово
Значением порта “
Анализ правильности установления мультиплексором “
Схема целиком
Чтобы получить полный чертеж схемы, реализующей прибавление/вычитание единицы из m-битного числа x, нам остается только соединить в каскад m описанных выше операционных ячеек и правильно подключить их к внешним портам. Как и в схеме компаратора, для разделения m-битного x на однобитные разряды мы применим блок обратной конкатенации

Примерный план следующей статьи.
Составные блоки как обозначения фрагментов схемы.
… Проблема неинформативного дублирования.
… Сравнение работы фрагмента схемы с работой блока.
… Блок клок, который ничего не делает, наглядное преобразование фрагмента в блок.
… Использование готовых схем в качестве составных блоков в неэлементарных схемах
(пример с мультиплексором, рекурсивное определение компаратора и схемы \pm 1)
....K-битные массивы регистров и мультиплексоров.
… Схема “часы”.
Упрощенный взгляд на латентность схемы.
… Взгляд на работу блока как на преобразователь данных.
… Задержки в самом длинном пути.
Прямое, обратное и обоюдонаправленное адресное дерево.
… Адресное дерево как обобщение многоходового мультиплексора (интерфейс).
....K-битные массивы регистров и мультиплексоров.
… Развернутый чертеж n-битного k-ходового дерева для k=8 и k=7.
… Рекурсивное определение. Глубина.
… Замечание об энергоэффективности.
… Однопортовая пользовательская RAM.
Простейшие стеки
… Цепочка сдвиговых регистров и цепочка регистров задержки.
… Цепочка с возможностью извлечения данных.
… Идеальный абстрактный стек и абстрактный стек конечной длины, интерфейс схемы.
… Интерфейс и реализация одной ячейки памяти простейшего стека.
… Схема целиком, рекурсивное определение.
… Устройства контроля опустошения и наполнения с использованием счётчика.
Каскадная очередь.
… Абстрактное определение идеальной очереди, очередь конечного объема.
… Идея реализации на основе стека.
… Контроль точки записи.
… Управление одной ячейкой памяти очереди.
… Схема целиком, рекурсивное определение.
Каскадный сумматор двух k-битных чисел.
… Алгоритм сложения столбиком для двоичных чисел.
… Интерфейс и реализация ячейки, обрабатывающий i-тый разряд.
… Интерфейс и реализация всего устройства.
… Рекурсивное определение, оценка глубины и объема.
… Двухтактный сумматор
Sergey_Kovalenko Автор
Нельзя ли починить время публикации? Опубликована в 18.49 где-то - на сайте отображается как опубликованная в 10.21. После устранения проблемы комментарий можно удалить.