
Ускорение шифрования ГОСТ 28147–89
С развитием ИТ-технологий резко возросли объемы данных, передаваемых по глобальной сети Интернет, находящихся в сетевых хранилищах и обрабатываемых в «облаках». Часть этих данных конфиденциальна, поэтому необходимо обеспечить их защиту от несанкционированного доступа. Для защиты конфиденциальных данных традиционно используется шифрование, а при шифровании больших объемов используют алгоритмы симметричного шифрования, такие как широко известный блочный алгоритм – AES. Для соответствия российскому законодательству при шифровании таких сведений, как персональные данные, необходимо использовать отечественный алгоритм симметричного блочного шифрования ГОСТ 28147–89. Операция шифрования данных достаточно затратна и требует дополнительного времени на обработку данных, в результате чего снижается производительность и увеличиваются задержки.
 Для снижения этого негативного эффекта при защите данных необходимо увеличивать скорость шифрования. В основном алгоритмы шифрования реализуются программно, но для достижения больших скоростей применяют аппаратные способы. К сожалению, в современных процессорах архитектуры x86 аппаратное ускорение шифрования реализовано только для стандарта AES (набор инструкций AES-NI). Этот стандарт основывается на особой алгебраической структуре, и ускорить другие стандарты шифрования с помощью инструкций AES-NI можно, только если их структура совпадает с AES (например, Camellia).
Для снижения этого негативного эффекта при защите данных необходимо увеличивать скорость шифрования. В основном алгоритмы шифрования реализуются программно, но для достижения больших скоростей применяют аппаратные способы. К сожалению, в современных процессорах архитектуры x86 аппаратное ускорение шифрования реализовано только для стандарта AES (набор инструкций AES-NI). Этот стандарт основывается на особой алгебраической структуре, и ускорить другие стандарты шифрования с помощью инструкций AES-NI можно, только если их структура совпадает с AES (например, Camellia). При реализации ГОСТ 28147–89 нельзя задействовать инструкции AES-NI, но можно применить другие подходы в ускорении шифрования. Например, мультиблочное шифрование – один программный поток шифрования параллельно обрабатывает несколько блоков. Но распараллелить обработку единого массива данных (рис. 1) только в тех режимах шифрования ГОСТ 28147–89, где нет обратной связи между обрабатываемыми блоками (гаммирование, ECB). Для режимов, имеющих обратную связь между блоками (CFB, MAC), можно использовать параллельную обработку нескольких блоков от разных потоков шифрования (рис. 2). При таком подходе скорость шифрования ГОСТ 28147–89 можно измерять в режиме ECB без потери общности. При этом стоит отметить размер буфера для каждого такого потока шифрования – он не должен превышать 4 КБ (размер сектора на HDD). В приведенных ниже результатах мы ограничились размером в 512 байт, а каждый поток шифровался на своем ключе.
Ускорение ГОСТ 28147–89 на центральном процессоре (ЦП) с помощью SIMD-технологий
Современные процессоры архитектуры x86 (а также ARM, PowerPC и др.) содержат блок векторных вычислений для параллельной обработки нескольких потоков данных c помощью технологии SIMD (single instruction, multiple data). Этот блок ЦП можно эффективно задействовать для мультиблочного шифрования ГОСТ 28147–89. Наибольший эффект при этом достигается за счет аппаратной инструкции перемешивания данных PSHUFB (рис. 3), которая позволяет существенно ускорить нелинейное преобразование (далее S-box) в алгоритме. В сочетании с расширениями команд AVX (или AVX2) и возможностью процессоров архитектуры x86 выполнять несколько команд параллельно (out-of-order execution) мультиблочное шифрование дает высокую скорость даже для одного ядра процессора.

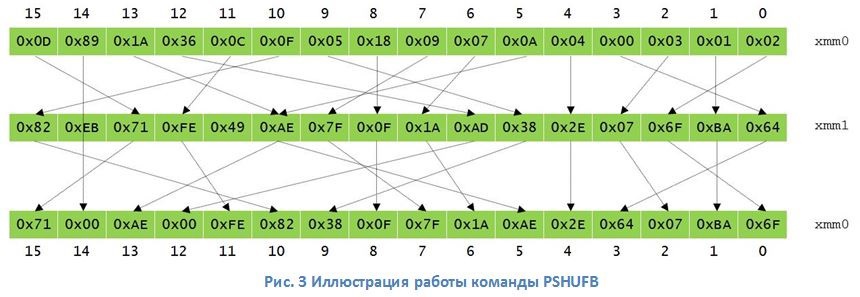
Ускорение ГОСТ 28147–89 на центральном процессоре (ЦП) на регистрах общего назначения
При реализации ГОСТ 28147–89 на регистрах общего назначения для операции S-box составляется предрасчетная таблица объемом 4 КБ (первым предложил Винокуров А.). Такой подход требует множество операций нелинейного обращения к памяти, и скорость выполнения такой реализации алгоритма шифрования зависит от подсистемы памяти ЦП. Для архитектуры Intel Sandy Bridge/Ivy Bridge производительность шифрования в этом случаи составляет 60 тактов/байт. В этой архитектуре присутствует 2 порта загрузки данных (LD – load data) в каждом ядре ЦП, что позволяет применить мультиблочное шифрование и, в этом случае, – шифровать 2 блока параллельно.

Ускорение ГОСТ 28147–89 на графическом процессоре (GPU)
Для дальнейшего ускорения шифрования по ГОСТ 28147–89 мы исследовали гетерогенные системы (CPU+GPU). Развитие архитектуры GPU привело к тому, что они по своим возможностям приближаются к ЦП, как по методам программирования, так и по аппаратной части. Но использование GPU как ускорителя шифрования сопряжено с рядом технических проблем. Как правило, графический ускоритель является периферийным устройством, которое подключается к CPU по шине передачи данных PCI Express. Это вносит в реализацию любого алгоритма c помощью технологии общих вычислений на графических ускорителях (GPGPU) дополнительные операции по копированию данных из памяти CPU в память GPU и обратно, но этот эффект можно уменьшить за счет конвейеризации обработки данных (рис. 5). Ядра в современных GPU по своей структуре похожи на блоки векторных вычислений в ЦП.

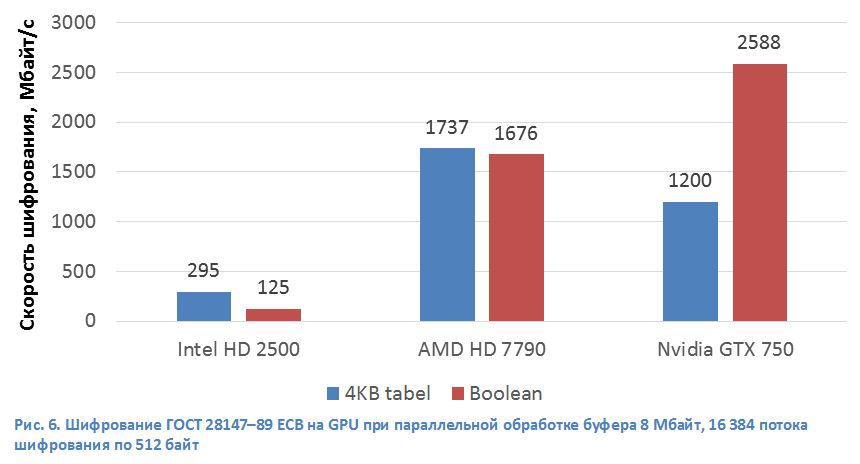
Заключение
По скоростным характеристикам шифрование ГОСТ 28147–89 приближается к AES и может стать ему хорошей альтернативой. Если комбинировать шифрование на CPU и GPU, можно достигнуть скорости шифрования на 1 узел в 53 Гбайт/с (платформа 2 CPU Intel Xeon E5-2697 v3 + 4 GPU Nvidia GeForce GTX 980). Кратко перечислим области, где могут быть востребованы такие скорости шифрования. Во-первых, для шифрования сетей стандарта 40 Гбит/с и 80 Гбит/с, что будет реализовано в следующих версиях АПКШ «Континент». Во-вторых, в распределенных сетевых дисковых хранилищах. В настоящий момент «Код Безопасности» разрабатывает проходной шифратор для протокола iSCSI. В-третьих, саму операцию шифрования можно продавать как услугу в облачных сервисах – клиент облака доплачивает за шифрование его данных или соединения. Можно пожертвовать высокой скоростью ради увеличения энергоэффективности и снижения себестоимости шифрующего оборудования для сетей стандарта 1 Гбит/с и 10 Гбит/с.
Комментарии (31)

sfrolov
16.04.2015 20:31+1Увеличение скорости шифрования может также подразумевать увеличение скорости дешифрования. Как по-вашему, этот алгоритм еще не устарел? Если еще у него запас по стойкости, связанной с увеличением скорости?

omegicus
16.04.2015 21:15+1Конечно актуально, атак на ГОСТ до сих пор нету (тех, которые можно реально реализовать, чисто теоретические только есть). Причем стоек он еще с 89-го года, тогда как намного более молодые, такие как AES уже по стойкости НЕ опережают ГОСТ — на тот же AES уже есть серъезнее атаки, чем только теоретические атаки на ГОСТ.
Единственный минус ГОСТа — как раз скорость, поэтому и статья актуальна.
MichaelBorisov
16.04.2015 22:05Я-то как раз слышал, что ГОСТ во многом привлекателен именно из-за скорости (по сравнению с конкурирующими шифрами). Что по этой причине его предпочитают некоторые буржуи. Ошибался? AES оптимизируется лучше?
omegicus
16.04.2015 22:14нет, однозначно ГОСТ медленный, его могли выбрать именно как раз из-за отсутствия вмешания служб США в его разработку.
Речь скорее всего идет о GostCrypt (форк трукрипта)?

darii
17.04.2015 00:19+2Все просто: в том же трукрипте по сравнению с каскадом типа «serpent-twofish» (или любых иных относительно экзотических блочных алгоритмов) ГОСТ действительно быстр, а чистый AES всех уделывает исключительно благодаря аппаратной поддержке aes-ni, которая сейчас встроена почти повсюду. По крайней мере, ни thinkpad, ни макбук без AES NI вот уже несколько лет купить очень затруднительно.
Вообще, к моему сожалению, на Хабре удивительно мало толковых статей про ГОСТ, а ведь учитывая политические события последних лет (я имею в виду конфронтацию России и США) алгоритм получается весьма перспективный, особенно если вы живете и ведете экономическую деятельность не в России.
Спасибо автору статьи за побужденный интерес — завтра же спрошу у нашего безопасника пару глупых вопросов, типа, какой рекомендуется размер ключа для шифрования документов «совершенно секретно» и какие алгоритмы ассиметричного шифрования применяются, например, в дипломатических миссиях РФ.omegicus
17.04.2015 01:28+1тут не соглашусь, опять же утверждаю ГОСТ медлителен (поэтому, одной из причин, видимо, сейчас разрабатывают аналогично Стрибогу (ГОСТ 34.11-2012) новый ГОСТ на замену 89-му).
Аппаратное ускорение имеет быть конечно, но вот у меня его нету (хотя на одном ноуте был — тестировал) — и ГОСТ проигрывает не только AES но и даже паре каскадов AES+Serpent, к примеру!!!
Одной из причин, кстати, почему при стандартизации выбрали AES, а не Twofish Шнаера или MARS от IBM как раз и было что AES даже переоптимизирован для софт и хард реализации. Но пострадала криптостойкость немного (а теперь видим что и много).
Лично я доверяю, конечно, только ГОСТ и очень жду выхода нового ГОСТа. А использую обычно ГОСТ+Twofish (на крайняк ГОСТ+Blowfish), хотя и медленно, но зато надежно. Наш ГОСТ + Брюс Шнаер = сила )
ezhik2k Автор
17.04.2015 12:27Каскадное шифрование – не всегда это хорошо. Яркий тому пример – 3DES.

mrxak
17.04.2015 03:51и какие алгоритмы ассиметричного шифрования применяются, например, в дипломатических миссиях РФ.
А почему вы думаете, что там ассиметричное? Для больших данных симметричное упомянутым ГОСТ-ом; а вот ключи для него уже генерируются ассиметричными алгоритмами и схемами на эллиптических кривых над полем Галуа. Все ГОСТы, кроме упомянутого 28147-89, как раз под это обновили к 2012-му. К тому же надо разделять то, что информация может идти от дипломатов в центр, а может выдаваться центром дипломатам в зависимости от их доступа. Вот ко второй задаче ещё спаривание Вейля (Weil pairing) или что-то подобное должно подходить. Впрочем, вряд ли это вам кто подробно расскажет.
ezhik2k Автор
17.04.2015 15:34Нет, AES не лучше оптимизируется. Просто за последние 10 лет AES получил аппаратную поддержку в различных микропроцессорах и стал стандартом де-факто для мира. Если подробно рассмотреть набор инструкций Intel AES-NI, окажется что для получения скорости шифрования >1 ГБ на ядро используется мультиблочная техника.
ezhik2k Автор
17.04.2015 13:21Посчитаем насколько ГОСТ 28147-89 медленней AES-256. Будем исходить из того, что оба алгоритма реализованы с помощью таблиц (T-table). При такой реализации алгоритмов, самой медленной операцией будет обращение в память. ГОСТ обрабатывает данные блоками по 64 бит, а AES по 128 бит. Кол-во раундов при обработке одного блока данных с помощью ГОСТ равно 32-м, а для AES-256 – 14-и. ГОСТ в 1 раунде 4 раза обращается к таблице, AES – 16. Посчитаем сколько обращений к памяти необходимо ГОСТ для обработки 128 бит информации: 2 блока x (32 раунда x 4 выборки из таблицы) = 256 обращений к памяти. Тоже самое рассчитаем для AES-256: 1 блок x (14 раундов x 16 выборок из таблицы) = 224 обращений к памяти. Получается, что AES-256 требует на 15% меньше обращений к памяти, чем ГОСТ 28147-89.

VenomBlood
17.04.2015 22:54Сравнение нелепое. Считать количество обращений к памяти и не учитывать кеш/специфику работы RAM == тыкать пальцем в потолок.



ishevchuk
17.04.2015 00:27+2С реализацией шифрования ГОСТа на FPGA, случайно, не сравнивали? По скорости/энергопотреблению?
ezhik2k Автор
17.04.2015 11:37Нет, не сравнивал, но скоро такая возможность появится – наша компания работаем в данном направлении. К сожалению, очень мало практических публикаций по реализации ГОСТ на FPGA. Или я что-то упустил? Если да – поделитесь информацией.
По энергопотреблению однозначно FPGA лучше. По скорости не все так однозначно. Частота FPGA ~1 ГГц. Через какую шину она будет взаимодействовать с ЦП? или будет все сама обрабатывать?ishevchuk
17.04.2015 18:01Зависит от того, как сделать. :)
Можно, например, с процом взаимодействовать через PCIe (как и GPU): заливать туда обьемы данных, FPGA шифрует и отдает обратно.
Если хочется Ethernet шифровать сразу, то можно Ethernet завести на FPGA и сразу пакетики шифровать/дешифровать. Либо даже совместить это и сделать свою 10G/40G сетевую карточку на FPGA [либо купить готовый кит, и написать под нее софт] с шифрованием.
На opencores.org есть две корки ГОСТа, можно их собрать под топовые чипы и посмотреть производительность. И если не устроить, то писать их самим :)
Ivan_83
17.04.2015 22:37Шифрованный эзернет мало где нужен/пригоден.
Городить свой IP + IPSec в железе — утомительно и излишне.
Гораздо практичнее делать как все нормальные люди — крипто акселератор в виде платы PCI-E или там USB свистка.
Это такое устройство, которому скармливают ключ, и льют в него данные а оно возвращает обратно зашифрованные/расшифрованные.
Такая штука универсальна и легко интегрируется и с дисковым шифрованием и с IPSec и с чем угодно в любой ОС.

dmitrmax
28.04.2015 22:12Раз у Вас целая компания этим занимается, то может быть вы в курсе, почему никто из отечественных лидеров индустрии не занимается стандартизацией ГОСТов в TLS? По крайней мере об этом в TLS WG нет ни слова за последние годы.
ezhik2k Автор
30.04.2015 12:44Стандартизацией ГОСТ-ов в TLS занимается Технический Комитет №26 (ТК26). В этот комитет входят лидеры индустрии ИБ – «ИнфоТеКС», «Крипто-Про», «Код Безопасности». На сайте комитета можно найти методические документы для использования российских криптографических алгоритмов в протоколе TLS.
dmitrmax
30.04.2015 13:21Стандартизацией TLS занимается TLS WG. ТК-26 стандартизует какой-то свой TLS с ГОСТом, блэкджеком и дамами, потому что в TLS WG об этом ни слуху, ни духу. А именно отсутствием работы c TLS WG объясняется полное отсутствие поддержи ГОСТов в известных реализациях TLS, отсутствия поддержки в браузерах и существование таких вот уродов. И использование ГОСТа никогда не станет массовым, пока его поддержка не будет прозрачной.
ezhik2k Автор
30.04.2015 14:37Не в прозрачности дело – стандарты и методические рекомендации открыты. Для включения российских алгоритмов в TLS, ТК26 взаимодействует с IANA, которая взаимодействует с IETF. Другое дело, почему ГОСТ алгоритмы для TLS не были внесены в реестр «TLS Cipher Suite». Скорее всего, это связанно с неудачной попыткой сертификации старых алгоритмов (ГОСТ 28147-89, ГОСТ 34.11-94, ГОСТ 34.10-2001) в ISO. Но ситуация может измениться с принятием нового стандарта на шифрование в дополнение к уже действующим стандартам ГОСТ 34.11-2012 и ГОСТ 34.10-2012.
dmitrmax
30.04.2015 14:59> Не в прозрачности дело
Под прозрачностью я имел ввиду прозрачность для юзера: чтобы для работы с ГОСТом не требовалось специальным образом собранных браузеров, целой тьмы плагинов и так далее. Именно так это выглядит сейчас. Сейчас юзеры Хрома начнут верещать, что у них перестали работать эти плагины, т.к. в 42-й версии гугл отключил по-умолчанию поддержку плагинов через API Mozilla. А скоро выпилит её совсем.
> методические рекомендации открыты
Ну на сайте ТК-26 они только на русском. Это не серьезно.
> ТК26 взаимодействует с IANA, которая взаимодействует с IETF
Черновику им. Чудова уже седьмой год. С тех пор никаких подвижек и даже попыток.
> ситуация может измениться с принятием нового стандарта на шифрование
Пока это даже у нас не стандарт.
На носу принятие нового браузерного API www.w3.org/TR/WebCryptoAPI. Про ГОСТ там тоже ничего не слышно. Хотя, казалось бы, это отличное решение для того, чтобы похоронить эту бешенную армию плагинов.
omegicus
19.04.2015 13:30Ой, проморгал, есть кандидат уже: ru.wikipedia.org/wiki/Kuznechik
УРРЯ ТОВАРИЩИ!) Надо пробовать

ALEX_k_s
21.04.2015 20:30Мне кажется на 750 видеокарте не поддерживается двунаправленная загрузка / выгрузка. Соответственно схема не подходит для все ГПУ =)
И я думаю вряд ли производительность ГПУ линейно масштабируется, там очень много факторов.
У самого есть возможность прогнать алгоритм на GTX Titan и Xeon E5 v2, если код конечно не секретен =) а еще интересно посмотреть на оптимальность кода на ГПУezhik2k Автор
24.04.2015 13:26Вы правы. В представленных «дешёвых» GPU от AMD и NVidia есть только один канал DMA. Эти GPU предназначены в первую очередь для отображения 3D картинки на мониторе, а с этой задачей прекрасно справляется и один канал DMA. По этому, предложенная схема на них не работает (соответственно и результаты ниже).
Но наличие двух каналов DMA еще не гарантирует успех – необходима поддержка со стороны драйверов. Тот же Intel HD 2500 использует шину Ring Bus, к которой подключаются все ядра CPU, но выигрыша в производительности это не дает. Скорее всего, в этом случаи виноваты драйвера.
Код является «коммерческой тайной».ALEX_k_s
24.04.2015 13:32самый новый драйвер от NVIDIA и CUDA 7.0 поддерживает данный механизм. Другое дело — что быстрее: вычисление или передача. Скорее всего вычисления пролетают быстро, тем самым алгоритм в хорошем случае должен сводиться к копированию и выгрузке данных. Еще хотел добавить:
если алгоритм использует мало данных или вообще сохраняет их только для выгрузки/загрузки, то можно вообще не использовать глобальную память, загружая данные прямо с ЦПУ через L2 в ядро. Также можно делать и с выгрузкой. Этот механизм называется UMA или как то так. В общем передаете указатель на память ЦПУ и обращаетесь к нему как к массиву в ядре. Тогда эти ваши стадии скорее всего не понадобятся.
Ivan_83
1. Таблица S бокс — это возможность тайминг атак
2. 4к — уходит в кеш проца
3. 7-10 мегабайт/сек на AVX, даже 24 мегабайта/сек с одного ядра — вообще очень мало!
Core Duo E8500, 8Gb DDR2-800, 1 поток, на регистрах общего назначения
# sector = 4kb -размер блока который скармливался за раз
3DES-CBC-192 = 22018189 bytes/sec
AES-CBC-128 = 104097143 bytes/sec
AES-CBC-256 = 81983833 bytes/sec
AES-XTS-128 = 78559346 bytes/sec
AES-XTS-256 = 66047200 bytes/sec
Blowfish-CBC-128 = 38635464 bytes/sec
Blowfish-CBC-256 = 38810555 bytes/sec
Camellia-CBC-128 = 92814510 bytes/sec
Camellia-CBC-256 = 75949489 bytes/sec
ChaCha8-XTS-256 = 199518722 bytes/sec
ChaCha12-XTS-256 = 179029849 bytes/sec
ChaCha20-XTS-256 = 149447317 bytes/sec
XChaCha8-XTS-256 = 195675728 bytes/sec
XChaCha12-XTS-256 = 175790196 bytes/sec
XChaCha20-XTS-256 = 147939263 bytes/sec
После некоторых оптимизаций кода:
AES-XTS-128 = 104088794 bytes/sec
AES-XTS-256 = 81625068 bytes/sec
ChaCha8-XTS-256 = 337336982 bytes/sec
ChaCha12-XTS-256 = 284740187 bytes/sec
ChaCha20-XTS-256 = 217326865 bytes/sec
XChaCha8-XTS-256 = 328424551 bytes/sec
XChaCha12-XTS-256 = 278579692 bytes/sec
XChaCha20-XTS-256 = 211660225 bytes/sec
4. Это вы под виндой GPGPU задействовали?
ezhik2k Автор
1. Возможны, но при условии, что злоумышленник имеет доступ к машине. При эксплуатации шифратора предполагается, что такой возможности нет
.
2. Согласен.
3. Давайте разберемся.
Для корректного сравнения скорости, необходимо учитывать частоту процессора (Xeon E5-2697 v3 @ 2,6 ГГц vs Core Duo E8500 @ 3,1 ГГц), а также позаботится об отключении технологий Intel — SpeedStep и Turbo Boost (нет в Core Duo E8500). Более-менее универсальной мерой производительности шифрования/сжатия является единица измерения «такт на байт» для одного ядра ЦП — эти данные для различных реализаций ГОСТ приведены в статье. Необходимо также учитывать, что скорость одного и того же кода на разных микроархитектурах ЦП может быть различна. Численные данные, приведённые в статье, характеризуют максимальную пропускную способность платформы с включённой технологией Intel Hyper-threading. Еще раз повторюсь, что эта технология «позволяет увеличить суммарную скорость платформы на 30 % при 50%-ном снижении скорости на один поток».
Касательно приведённых Вами данных, в частности относительно алгоритма AES — у вас либо ошибка или опечатка, и вот почему. В стандарте AES количество раундов при обработке блока данных зависит от длины ключа: 10 раундов для ключа 128 бит, 12 раундов для ключа 192 бит и 14 раундов для ключа 256 бит. Какой бы ни был у Вас процессор, при переходе от 128 бит к 256 бит необходимо будет выполнить на 40 % больше операций, что вызовет падение в скорости на 40%. Ваши данный для AES-xxx xxx 128 быстрее всего на 20% относительно AES-xxx xxx 256.
Да, ГОСТ отстает от AES-256 при реализации с помощью таблиц, но не намного – это я покажу далее.
4. Да.
В любом случаи, был бы Вам признателен, если вы проведете тестирование ГОСТ на своем процессоре (например реализации из OpenSSL) и выложите свои результаты здесь.
Ivan_83
3. Это не чистый бенчмаркинг шифрования, это было дисковое шифрование, поэтому 40% превратилось в 20%.
Но в целом порядок скорости всё ещё сохранился.
А так же гипертрединг позволяет тормознуть систему до 50% при некоторых условиях, поэтому его частенько выключают чтобы не мешался.
Ок. Но опенссл весьма специфичен в реализациях алгоритмов :)
4. Не очень оптимально, для продакшена, мягко говоря.
А латентность насколько возрастает при использовании GPGPU?